
深度學習框架Keras使用心得
最近幾個月為了寫小論文,題目是關於用深度學習做人臉檢索的,所以需要選擇一款合適的深度學習框架,caffe我學完以後感覺使用不是很方便,之後有人向我推薦了Keras,其簡單的風格吸引了我,之後的四個月我都一直在使用Keras框架,由於我用的時候,tensorflow的相關教程還不是很多,所以後端我使用theano。這次的心得主要分成兩篇,第一篇是聊聊開始使用keras容易遇到的坑,第二篇會在我論文發了之後,連同程式碼和一些更細節的東西一起發出來,我也會在結尾放出一些自己收集的CNN和tensorflow的相關教程,就這樣。
本文由淺入深聊一聊我在這個過程中遇到的一些問題:
1、Keras輸出的loss,val這些值如何儲存到文字中去:
Keras中的fit函式會返回一個History物件,它的History.history屬性會把之前的那些值全儲存在裡面,如果有驗證集的話,也包含了驗證集的這些指標變化情況,具體寫法:
hist=model.fit(train_set_x,train_set_y,batch_size=256,shuffle=True,nb_epoch=nb_epoch,validation_split=0.1)
with open('log_sgd_big_32.txt','w') as f:
f.write(str(hist.history))我覺得儲存之前的loss,val這些值還是比較重要的,在之後的調參過程中有時候還是需要之前loss的結果作為參考的,特別是你自己添加了一些自己的loss的情況下,但是這樣的寫法會使整個文字的取名比較亂,所以其實可以考慮使用Aetros的外掛,
2、關於訓練集,驗證集和測試集:
其實一開始我也沒搞清楚這個問題,拿著測試集當驗證集用,其實驗證集是從訓練集中抽取出來用於調參的,而測試集是和訓練集無交集的,用於測試所選引數用於該模型的效果的,這個還是不要弄錯了。。。在Keras中,驗證集的劃分只要在fit函式裡設定validation_split的值就好了,這個對應了取訓練集中百分之幾的資料出來當做驗證集。但由於shuffle是在validation _split之後執行的,所以如果一開始訓練集沒有shuffle的話,有可能使驗證集全是負樣本。測試集的使用只要在evaluate函式裡設定就好了。
print model.evaluate(test_set_x,test_set_y ,batch_size=256)這裡注意evaluate和fit函式的預設batch_size都是32,自己記得修改。
3、關於優化方法使用的問題:
開始總會糾結哪個優化方法好用,但是最好的辦法就是試,無數次嘗試後不難發現,Sgd的這種學習率非自適應的優化方法,調整學習率和初始化的方法會使它的結果有很大不同,但是由於收斂確實不快,總感覺不是很方便,我覺得之前一直使用Sgd的原因一方面是因為優化方法不多,其次是用Sgd都能有這麼好的結果,說明你網路該有多好啊。其他的Adam,Adade,RMSprop結果都差不多,Nadam因為是adam的動量新增的版本,在收斂效果上會更出色。所以如果對結果不滿意的話,就把這些方法換著來一遍吧。
有很多初學者人會好奇怎麼使sgd的學習率動態的變化,其實Keras裡有個反饋函式叫LearningRateScheduler,具體使用如下:
def step_decay(epoch):
initial_lrate = 0.01
drop = 0.5
epochs_drop = 10.0
lrate = initial_lrate * math.pow(drop,math.floor((1+epoch)/epochs_drop))
return lrate
lrate = LearningRateScheduler(step_decay)
sgd = SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False)
model.fit(train_set_x, train_set_y, validation_split=0.1, nb_epoch=200, batch_size=256, callbacks=[lrate])上面程式碼是使學習率指數下降,具體如下圖:
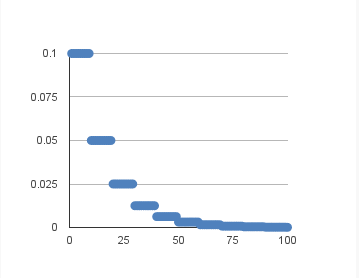
當然也可以直接在sgd宣告函式中修改引數來直接修改學習率,學習率變化如下圖:
sgd = SGD(lr=learning_rate, decay=learning_rate/nb_epoch, momentum=0.9, nesterov=True)4、關於過擬合問題的討論:
我現在所知道的解決方法大致只有兩種,第一種就是新增dropout層,dropout的原理我就不多說了,主要說一些它的用法,dropout可以放在很多類層的後面,用來抑制過擬合現象,常見的可以直接放在Dense層後面,對於在Convolutional和Maxpooling層中dropout應該放置在Convolutional和Maxpooling之間,還是Maxpooling後面的說法,我的建議是試!這兩種放置方法我都見過,但是孰優孰劣我也不好說,但是大部分見到的都是放在Convolutional和Maxpooling之間。關於Dropout引數的選擇,這也是隻能不斷去試,但是我發現一個問題,在Dropout設定0.5以上時,會有驗證集精度普遍高於訓練集精度的現象發生,但是對驗證集精度並沒有太大影響,相反結果卻不錯,我的解釋是Dropout相當於Ensemble,dropout過大相當於多個模型的結合,一些差模型會拉低訓練集的精度。當然,這也只是我的猜測,大家有好的解釋,不妨留言討論一下。
當然還有第二種就是使用引數正則化,也就是在一些層的宣告中加入L1或L2正則化係數,正則化的原理什麼的我就不細說了,具體看程式碼:
C1 = Convolution2D(20, 4, 4, border_mode='valid', init='he_uniform', activation='relu',W_regularizer=l2(regularizer_params))其中W_regularizer=l2(regularizer_params)就是用於設定正則化的係數,這個對於過擬合有著不錯的效果,在一定程度上提升了模型的泛化能力。
5、Batchnormalization層的放置問題:
BN層是真的吊,簡直神器,除了會使網路搭建的時間和每個epoch的時間延長一點之外,但是關於這個問題我看到了無數的說法,對於卷積和池化層的放法,又說放中間的,也有說池化層後面的,對於dropout層,有說放在它後面的,也有說放在它前面的,對於這個問題我的說法還是試!雖然麻煩。。。但是DL本來不就是一個偏工程性的學科嗎。。。還有一點是需要注意的,就是BN層的引數問題,我一開始也沒有注意到,仔細看BN層的引數:
keras.layers.normalization.BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one')mode:整數,指定規範化的模式,取0或1
0:按特徵規範化,輸入的各個特徵圖將獨立被規範化。規範化的軸由引數axis指定。注意,如果輸入是形如(samples,channels,rows,cols)的4D影象張量,則應設定規範化的軸為1,即沿著通道軸規範化。輸入格式是‘tf’同理。
1:按樣本規範化,該模式預設輸入為2D
我們大都使用的都是mode=0也就是按特徵規範化,對於放置在卷積和池化之間或之後的4D張量,需要設定axis=1,而Dense層之後的BN層則直接使用預設值就好了。
總結
這次暫時先寫這麼多,這次寫的比較淺,還有很多拓展的東西都下次再寫了,下面給大家附上一些不錯的資料吧~
相關推薦
深度學習框架Keras使用心得
最近幾個月為了寫小論文,題目是關於用深度學習做人臉檢索的,所以需要選擇一款合適的深度學習框架,caffe我學完以後感覺使用不是很方便,之後有人向我推薦了Keras,其簡單的風格吸引了我,之後的四個月我都一直在使用Keras框架,由於我用的時候,tensorflo
Ubuntu 搭建深度學習框架 keras
all bash VC 使用 learning 是否 技術 ESS image 深度學習框架Keras是基於Tensorflow的所以,安裝keras需要安裝Tensorflow: 1. 安裝教程主要參考於兩個博客的教程: https://www.cnblogs.c
深度學習框架Keras安裝
orf 語言 mage 版本 win color install Beginner inner 本文主要參考:https://blog.csdn.net/qingzhuochenfu/article/details/51187603 前提:Keras是Python語
深度學習框架---keras的層次示意圖---方便直觀理解---適用sklearn模型的展示
感覺keras確實比其他框架舒服一點,但是前期理解keras層的時候可能有點小問題,keras的層使用了原始神經網路層的概念,即先有上層的輸出聚合,聚合後在進入啟用函式。我的環境是python3.5+tensorflow+keras+graphviz+pydot_ng+pydotplus 其中
DeepLearning tutorial(6)易用的深度學習框架Keras簡介
之前我一直在使用Theano,前面五篇Deeplearning相關的文章也是學習Theano的一些筆記,當時已經覺得Theano用起來略顯麻煩,有時想實現一個新的結構,就要花很多時間去程式設計,所以想過將程式碼模組化,方便重複使用,但因為實在太忙沒有時間去做。最近發現了一個叫做
基於Theano的深度學習框架keras及配合SVM訓練模型
https://blog.csdn.net/a819825294/article/details/51334397 1.介紹 Keras是基於Theano的一個深度學習框架,它的設計參考了Torch,用Python語言編寫,是一個高度模組化的神經網路庫,支援GPU和CPU。keras官方文件地址 地址 2.
深度學習框架Keras學習系列(一):線性代數基礎與numpy使用(Linear Algebra Basis and Numpy)
又開一個新坑~~ 因為確實很有必要好好地趁著這個熱潮來研究一下深度學習,畢竟現在深度學習因為其效果突出,熱潮保持高漲不退,上面的政策方面現在也在向人工智慧領域傾斜,但是也有無數一知半解的人跟風吹捧,於是希望藉此教程,讓自己和讀者一起藉助keras,從上到下逐漸
基於Theano的深度學習框架keras及配合SVM訓練模型 (非常好的思路:DL+DM)
1.介紹 Keras是基於Theano的一個深度學習框架,它的設計參考了Torch,用Python語言編寫,是一個高度模組化的神經網路庫,支援GPU和CPU。keras官方文件地址 地址 2.流程 先使用CNN進行訓練,利用Theano函式將CNN全連線層的值取出來,給SVM進行訓練 3.結果示例 因
[深度學習框架] Keras上使用CNN進行mnist分類
# coding: utf-8 import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential
深度學習框架-Keras基礎入門系列-覃秉豐-專題視訊課程
深度學習框架-Keras基礎入門系列—1817人已學習 課程介紹 Keras是一種高度模組化,使用簡單上手快,合適深度學習初學者使用的深度學習框架。Keras由純Python編寫而成並以
深度學習框架keras平臺搭建(關鍵字:windows、非GPU、離線安裝)
當下,人工智慧越來越受到人們的關注,而這很大程度上都歸功於深度學習的迅猛發展。人工智慧和不同產業之間的成功跨界對傳統產業產生著深刻的影響。 最近,我也開始不斷接觸深度學習,之前也看了很多文章介紹,對深度學習的歷史發展以及相關理論知識也有大致瞭解。 但常言道:紙上得來終覺淺,
深度學習框架keras安裝(後端基於Tensorflow/theano)
1、安裝python3、tensorflow、numpy、scipy 安裝python3及開發工具 sudo apt-get install python3 sudo apt-get install python-setuptools 安裝pip
Linux系統下深度學習框架Keras的搭建
關於計算機的硬體配置說明 推薦配置 如果您是高校學生或者高階研究人員,並且實驗室或者個人資金充沛,建議您採用如下配置: 主機板:X99型號或Z170型號CPU: i7-5830K或i7-6700K 及其以上高階型號記憶體:品牌記憶體,總容量32G以上,根據主機板組成4
如何在基於tensorflow的深度學習框架keras中指定GPU記憶體使用大小
set_gpu.py import os import tensorflow as tf import keras.backend.tensorflow_backend as KTF def get_session(gpu_fraction=0.3): '''As
深度學習框架keras模組安裝
安裝環境:Win10(64位) python3.61. Keras 介紹 Keras(http://keras.io/)是一個基於Theano或TensorFlow作為後端的深度學習框架,它的設計參考了Torch,用Python語言編寫,是一個高度模組化的神經網
【深度學習框架Keras】一個二分類的例子
一、這個IMDB資料集包含了50000條電影評論,其中25000條用於訓練,另外25000條用於測試。其label只包含0或1,其中0表示負面評價,1表示正面評價 from keras.datasets import imdb (train_data,tr
如何在基於tensorflow的深度學習框架keras中指定GPU
import os os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"]="0,1" 使
深度學習框架keras中遇到的問題
1、在window系統中,使用keras的cifar10.load_data(),自動下載cifar10檔案,存放路徑為C:\\Users\\xinjian-wxf\\.keras\\datasets\
[深度學習框架] Keras上使用神經網路進行mnist分類
# coding: utf-8 import numpy as np from keras.datasets import mnist from keras.utils import np_utils
DeepLearning tutorial(7)深度學習框架Keras的使用-進階
上一篇文章總結了Keras的基本使用方法,相信用過的同學都會覺得不可思議,太簡潔了。十多天前,我在github上發現這個框架的時候,關注Keras的人還比較少,這兩天無論是github還是微薄,都看到越來越多的人關注和使用Keras。所以這篇文章就簡單地再介