
組函式及分組統計
分組函式
SQL中常用的分組函式
Count(): 計數
Max():求最大值
Min():求最小值
Avg():求平均值
Sum():求和
-- 統計emp表中的人數 select count(*) from emp; -- 統計獲得獎金的人數 select count(comm) from emp; -- 求所有僱員的最低工資 select min(sal) from emp; -- 求所有僱員的最高工資 select max(sal) from emp; -- 求部門編號為20的僱員的平均工資和總工資 select avg(sal),sum(sal) from emp where deptno = 20;
分組統計查詢
語法格式
SELECT {DISTINCT}*|查詢列1 別名1,查詢列2 別名2……
FORM 表名稱1 別名1,表名稱2 別名2,……
{WHERE 條件表示式}
{GROUP BY 分組條件}
{ORDERBY 排序欄位 ASC|DESC,排序欄位 ASC|DESC,……}-- 統計出每個部門的人數
select deptno,count(empno) from emp group by deptno;
-- 求出每個部門的平均工資
select deptno, avg(sal) from emp group by deptno;統計每個部門的最高工資,以及獲得最高工資的僱員姓名
如果寫成
SELECT ename,max(sal)
FROM emp
GROUP BY deptno
Oracle會提示第 1 行出現錯誤:
ORA-00979: 不是 GROUP BY 表示式
以上程式碼在執行過程中出現錯誤,是因為:
1. 如果程式中使用了分組函式,則在以下兩種情況下可以正常查詢結果:
程式中存在了GROUP BY,並指定了分組條件,這樣可以將分組條件一起查詢出來
如果不使用GROUP BY,則只能單獨地使用分組函式
2.使用分組函式時,查詢結果列不能出現分組函式和分組條件之外的欄位
綜上所述,我們在進行分組統計查詢時有遵循這樣一條規律:
出現在欄位列表中的欄位,如果沒有出現在組函式中,就必定出現在GROUP BY 語句的後面
-- 統計出每個部門的最高工資,及最高工資的僱員姓名
select deptno, ename,sal from emp where sal in(select max(sal) from emp group by deptno);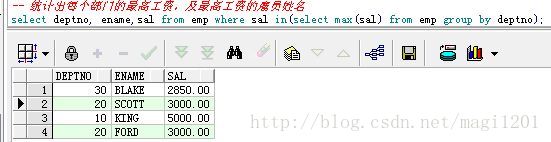
-- 查詢出每個部門的部門名稱,及每個部門的僱員人數
select d.dname, count(e.empno)
from emp e, dept d
where e.deptno = d.deptno
group by d.dname求出平均工資大於2000的部門編號和平均工資
初學者很容易錯誤地寫成將工資大於2000的條件寫在where的後面
SELECT deptno,avg(sal) FROM emp WHERE avg(sal)>2000 GROUP BYdeptno<span style="font-family:SimSun;"></span>系統出現如下錯誤提示:
ORA-00934: 此處不允許使用分組函式
-- 求出平均工資大於2000的部門編號和平均工資
select e.deptno, avg(sal)
from emp e, dept d
where e.deptno = d.deptno
having avg(sal) > 2000
group by e.deptno;規則:WHERE 只能對單條記錄限制(過濾),having是對分組進行過濾
分組函式只能在分組中使用,不能在WHERE語句之中出現,如果要指定分組條件,則只能通過第二種條件的指令:HAVING
-- 顯示非銷售人員工作名稱以及從事同一工作僱員的月工資總和,並且要滿足從事同一工作的僱員的月工資合計大於$5000,輸出結果按月工資合計升序排列
select e.job, sum(e.sal) sum_sal
from emp e
where e.job <> 'SALESMAN'
group by e.job
having sum(e.sal) > 5000
order by sum_sal;分組的簡單原則:
只要一列上存在重複內容才有可能考慮到用分組查詢
注意:
分組函式可以巢狀使用,但是在組函式巢狀使用的時候不能再出現分組條件的列名
例:求平均工資最高的部門編號、部門名稱、部門平均工資
第一步:
select deptno, avg(sal) from emp group by deptno;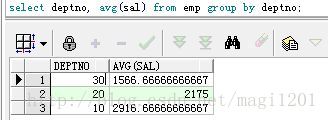
第二步:
select deptno, max(avg(sal)) from emp group by deptno;第三步:去掉查詢結果中的deptno列
select max(avg(sal)) from emp group by deptno;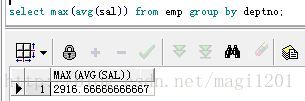
逐步完成後:
select d.deptno, d.dname, t.avg_sal
from dept d,
(select deptno,avg(sal) avg_sal
from emp
group by deptno having avg(sal)=
(select max(avg(sal)) from emp group by deptno)
) t
where t.deptno=d.deptno;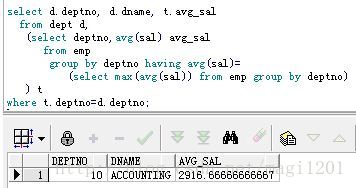
相關推薦
組函式及分組統計
分組函式 SQL中常用的分組函式 Count(): 計數 Max():求最大值 Min():求最小值 Avg():求平均值 Sum():求和 -- 統計
Numpy 內建函式及基本統計功能
a=np.arange(6) np.cos(a) np.exp(a) np.sqrt(a) 基本統計功能 a=np.random.randint(1,5,6) a.sum() a.mean()平均值 a.std()方差 a.min()最小值 a.max()
Pandas分組統計函式:groupby、pivot_table及crosstab
利用python的pandas庫進行資料分組分析十分便捷,其中應用最多的方法包括:groupby、pivot_table及crosstab,以下分別進行介紹。 0、樣例資料 df = DataFrame({'key1':['a','a','b','b','a
Oracle 分組統計,抽取每組前十
order by 編號 用戶名 ldb In 行業 partition like ber /**2018年6月14日 潮州ORACEL 統計2017年用電量,按行業分類抽取用電量前十*/select * from (select t.yhbh 用戶編號,
SQL的聚合函式、分組、子查詢及組合查詢用法
聚合函式: SQL中提供的聚合函式可以用來統計、求和、求最值等等。 分類: –COUNT:統計行數量 –SUM:獲取單個列的合計值 –AVG:計算某個列的平均值 –MAX:計算列的最大值 –MIN:計算列的最小值 首先,建立資料表如下:
python序列之元組概念及相關函式總結(一)
元組是序列的一種,元組是不可變序列(不能修改,替換),但可進行查詢,增添;元組的建立語法很簡單:用逗號分隔一些值,用圓括號括起來,元組就建立了。 1.先來一個簡單的元組:(圓括號也可以不帶) tou
ORACLE:分組統計函式(COUNT()、SUM()、AVG()、MAX()、MIN())的使用
知識點: 統計函式: COUNT()、SUM()、MIN()、MAX()、AVG() 這些統計函式是允許和其它函式巢狀的 例:統計出企業員工的平均僱傭年限 以上的幾個操作函式,在表中沒有資料的時候,只要COUNT()函式會返回結果,其它都是Null
mongodb aggregate按日期分組統計及spring mongo實現
如需轉載請註明出處: mongodb aggregate按日期分組統計及spring mongo實現 實現的需求 傳入毫秒級開始時間戳和結束的時間戳,根據當前狀態currentStatus.status和當前狀態時間currentStatus.datetime進行按日統計,缺少數
第一章 統計學習方法概論 —— 第1~3節 統計學習及監督學習的簡介、損失函式及風險函式的公式化表達
關於統計學習方法的知識,參考書《統計學習方法》,李航著,清華大學出版社。 所有章節的符號表示、公式表示都是統一化的。 第一章 統計學習方法概論 第一節 統計學習 一、概念 所謂統計學習,指的是基於已知資料構建統計模型,從而對未知資料進行預測。 二、分類 監督學習(super
MYSQL基礎上機練習題(二)對資料指定列查詢、條件查詢、查詢結果排序、聚集函式查詢、分組統計查詢
實驗目標:1.掌握指定列或全部列查詢2.掌握按條件查詢3.掌握對查詢結果排序4.掌握使用聚集函式的查詢5.掌握分組統計查詢一、請完成書中實驗7.1,並完成以下問題。1.查詢所有學生的姓名及其出生年份回答以下問題:SQL語句請截圖① 觀察查詢的資料,若年齡不為空是否能求出出生年
mysql 分組統計 組內按時間倒序
類如 有一個帖子的回覆表,posts( id , tid , subject , message , dateline ) , id 為 自動增長欄位, tid為該回復的主題帖子的id(外來鍵關聯), subject 為回覆標題, message 為回覆內容, dateline 為回覆時間,用UNIX 時
大資料實戰:基於Spark SQL統計分析函式求分組TopN
做大資料分析時,經常遇到求分組TopN的問題,如:求每一學科成績前5的學生;求今日頭條各個領域指數Top 30%的頭條號等等。Spark SQL提供了四個排名相關的統計分析函式: dense_rank() 返回分割槽內每一行的排名,排名是連續的。 rank() 返回分割槽
R語言︱資料分組統計函式族——apply族用法與心得
每每以為攀得眾山小,可、每每又切實來到起點,大牛們,緩緩腳步來俺筆記葩分享一下吧,please~———————————————————————————筆者寄語:apply族功能強大,實用,可以代替很多迴
sql:分組統計時的查詢及效率
一張user表 裡面有id、國籍、出生日期等欄位 現在要統計各個國家成年的人有多少、未成年的人有多少 結果如下圖所示 第一種寫法: SELECT gjname, (select count(0) from criminal_base_info where g
C++呼叫 python 函式及返回值的處理【元組,字串...】
http://www.cnblogs.com/DxSoft/archive/2011/04/01/2002676.html Python 指令碼 py_test.py : #coding:utf-8 def get_int( ): a = 10 b =
SQL語句聚合函式、分組、子查詢及組合查詢
執行列、行計數(count): 標準格式 SELECT COUNT(<計數規範>) FROM <表名> 其中,計數規範包括: - * :計數所有選擇的行,包括NULL值; - ALL 列名:計數指定列的所有非空值行,如果不寫,預設為ALL; - DISTINCT 列名:計數
jdk1.8新特性 分組統計及格式化
package com.lixy.practice; import java.util.*; import java.util.stream.Collectors; import java.util.stream.IntStream; /** * Created
SQL中的分組和組函式
組函式是將一組作為整體計算,每組記錄返回一個結果 avg([distinct|all]expr):計算多行expr平均值,其中expr可以是變數、常量或者資料列 count(distinct|all
Oracle分組統計,rollup函式使用示例
要查詢的表結構以及測試資料如下:rollup_test_tableyyyyMMcum_user(累計使用者)new_user(新使用者)2018/1862018/286分組統計並計算新使用者佔比的查詢sql:select nvl(yyyyMM,'總計') yyyyMM
SQL腳本去重分組統計
數據 values name var logs 記錄 寫入 varchar 分享 需求:首先有一張表記錄學生姓名、科目和成績,然後模擬插入幾條數據,腳本如下: create table score ( Name nvarchar(20),--姓名