
也談OpenStack中的虛擬機器HA
OpenStack是一個旨在為公共及私有云的建設與管理提供軟體的開源專案。它的社群擁有超過130家企業及1350位開發者,這些機構與個人都將OpenStack作為基礎設施即服務(IaaS)資源的通用前端。OpenStack專案的首要任務是簡化雲的部署過程併為其帶來良好的可擴充套件性。做為雲端計算IAAS層事實標準,OpenStack廣泛的應用與各行各業。到目前為止OpenStack社群並沒有一個完整的虛擬機器HA解決方案。起初社群認為虛擬機器的HA不是雲平臺層次的特性,不應該在雲平臺層面來實現,虛擬機器的HA應該通過應用層面的HA來實現。但是很多應用不是預設做了應用層面的HA,OpenStack又缺少這樣一個重要的特性。所以很多公司針對虛擬機器的HA提出了自己的解決方案。最近社群也開始關注虛擬機器的HA的是實現。這篇文章針對OpenStack中的虛擬機器HA的進展和幾個公司的虛擬機器HA實現進行介紹。最後在結合各種方案的優點的基礎上,介紹了一個虛擬機器的HA的實現方案。
一、OpenStack中虛擬機器HA的歷史和現狀
OpenStack中虛擬機器的HA的最初討論可以見這篇文章, 作為Nova專案的重要貢獻者,他的文章對虛擬機器的HA的實現有著廣泛的影響。這篇文章也給出了虛擬機器HA實現的基本思路,解決這個問題需要一些關鍵的部件:
監控(Monitoring)- 系統檢測到虛擬化層的故障
隔離(或是圍欄,Fencing) - 系統隔離故障計算節點
恢復(Recovery) - 從故障的虛擬化上恢復虛擬機器
下邊是OpenStack中針對虛擬機器HA的一些解決方案;
1. Nova中的支援
Nova已經具備了一些HA的功能。
1) 在nova中提供了Evacuate命令來實現,將VM從失敗的Compute節點在目標節點上rebuild。這一功能的實現需要依賴源節點和目標節點間有共享儲存。
2) 在VM的HA當中,對於Compute節點是否故障的判斷需要非常的精細,目前在Openstack中每個nova-compute服務啟動時都會啟動一個定時器,定期的將心跳寫入到資料庫中,這樣可以從控制節點方便的知道Compute節點的狀態。
但是Openstack僅僅擁有這些功能還不足以完成對VM HA功能的完美支援。
1) 只是通過nova-compute服務來確定Compute節點的狀態時不可靠的,例如僅僅是nova-compute服務失效,或者網路閃斷時,也會造成心跳的過期,從而對是否進行HA不能進行準確的判斷。因此需要通過其他方式來確保準確獲得節點的狀態。最主要是OpenStack的最佳實踐部署,通常是管理、業務和儲存網段是單獨的網段,這時Nova Service的服務狀態只能反映出管理網段的狀態,不能反映出儲存和業務網段的nova-compute節點的狀態。
2) Openstack沒有對VM進行加鎖,因此在進行Evacuate命令時,會出現腦裂(同一個disk啟動多個VM的情況)。
3) 對於需要保護的虛擬機器需要提供一個列表,用來表明哪些VM是用來保護的。目前的Evacuate命令會獎失敗主機上的所有虛擬機器無差別進行rebuild這樣的實現也是不太合理的。
2. neutron+VRRP
為了防止防止arp欺騙,Neutron是不允許一個port上邊繫結多個IP地址的。Neutron在Havana Release增加了一個 “Allowed-Address-Pairs”的功能,允許虛擬機器的一個port繫結附加的IP作為浮動IP。這樣在虛擬機器中可以安裝VRRP實現軟體,比Keepalived等,浮動IP配置為額外增加的IP,多個虛擬機器繫結的port都繫結這個額外的浮動IP,兩個虛擬機器通過VRRP可以選出一個主對外提供服務。
這個方案首先配置複雜,需要在Neutron中為需要參與HA的port繫結額外的IP,還要在虛擬機器中配置VRRP支援軟體,配置複雜。這個方案不能算是一個完整的方案,相當於為應用層的HA實現方案做了一個Neutron中的支援功能。具體參考這篇文章。
3. Heat Restarter
Heat的HA特性是OpenStack多模組配合實現的,其中涉及到Nova,Ceilometer,Heat-cfn-api,Heat-cloudwatch,Heat-cfntools等。
Nova->提供虛擬機器
Ceilometer->傳送告警
Heat-cfntools->監控虛擬機器狀態
當虛擬機器上的應用程序down了,首先通過重啟應用程序嘗試解決,如果解決不了,重啟或者重建虛擬機器,如果還是解決不了,重建整個stack。從這一點上來看Heat HA的功能要比單純的虛擬機器HA的功能強大很多。
但是對於普通的Web無狀態應用,通過OS::Heat::HARestarter刪除原有虛擬機器,然後重新建立也許適合的,但是如果是資料庫之類的有狀態應用呢?怎麼保證原有資料庫中資料的不丟失,後端卷虛擬機器?那又怎麼保證使用原來的fixed-ip?
正式由於HARestarter是通過刪除原有虛擬機器的方式和虛擬機器的一些依賴資源,Openstack社群已經在Kilo版本廢棄了HARestarter。
4. OpenStack中的虛擬機器HA方案的設想
二、各大公司的實現方案
1. Masakari
Masakari 是日本NTT公司提供的一套虛擬HA方案。 Masakari支援虛擬機器程序,虛擬化程序和計算節點程序的監控。通過shell指令碼監控虛擬機器程序,Nova-compute服務和計算節點狀態。
虛擬機器程序掛了->通過虛擬機器的API關閉和啟動虛擬機器。
虛擬化程序掛了->通過Nova-compute API設定Nova-compute服務為down狀態。
Nova-compute程序掛了->疏散計算節點上的虛擬機器。
Masakari的架構:
masakari-controller : 這個HA服務的控制器。
masakari-instancemonitor : 檢測虛擬機器程序是否掛掉了。
masakari-processmonitor : 檢測Nova-compute是否掛了。
masakari-hostmonitor : 檢測計算節點是否掛了。
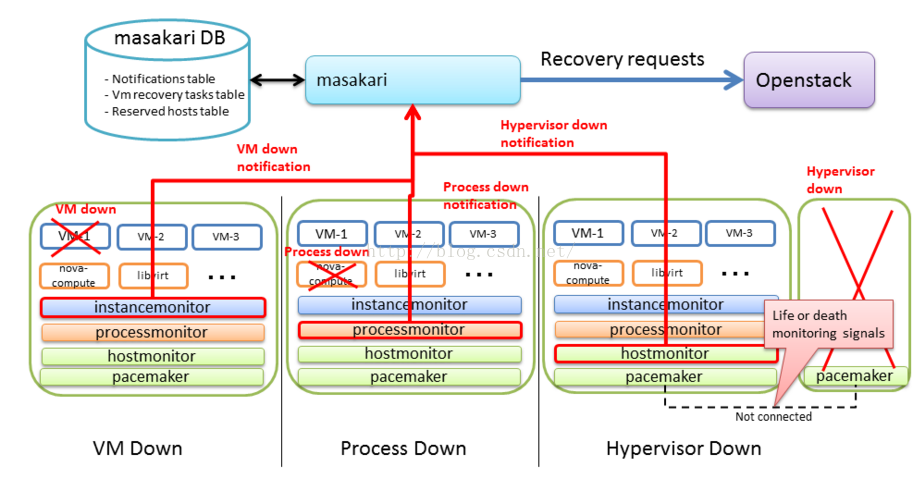
該方案可取之處在於:對於虛擬機器HA的解決方案中考慮了三個不同層次的故障。但是沒有考慮虛擬機器腦裂和計算節點的隔離,對於通常的OpenStack部署,都會存在管理、業務和儲存三個網段的狀態,簡單的通過一個網段去監控計算節點的狀態是不夠的。
2. Redhat 方案
部署方式如下:
使用 Pacemaker 叢集作為控制平面
將計算節點做為 Partial members 加入到 Pacemaker 叢集中,受其管理和監控。這時候,其數目不受 Corosync 叢集內節點總數的限制。
HA 實現細節:
Pacemaker通過pacemaker_remote按照順序(neutron-ovs-agent -> ceilometer-compute ->nova-compute) 來啟動計算節點上的各種服務。前面的服務啟動失敗,後面的服務不會被啟動。
Pacemaker 監控和每個計算節點上的 pacemaker_remote 的連線,來檢查該節點是否處於活動狀態。發現它不可以連線的話,啟動恢復(recovery)過程。
Pacemaker 監控每個服務的狀態,如果狀態失效,該服務會被重啟。重啟失敗則觸發防護行為(fencing action);當所有服務都被啟動後,虛機的網路會被恢復,因此,網路只會短時間受影響。
當一個節點失效時,恢復(recovery)過程會被觸發,Pacemaker 會依次:
1) 執行nova service-disable
2) 將該節點關機
3) 等待 nova 發現該節點失效了
4) 將該節點開機
5) 如果節點啟動成功,執行novaservice-enable
6) 如果節點啟動失敗,則執行 novaevacuate把該節點上的虛機移到別的可用計算節點上。
其中:
l 步驟(1)和 (5)是可選的,其主要目的是防止 nova-scheduler 將新的虛機分配到該節點。
l 步驟(2)保證機器肯定會關機。
l 步驟(3)中目前 nova 需要等待一段較長的超時時間才能判斷節點 down 了。Liberty 中有個 Blueprint 來新增一個 Nova API 將節點狀態直接設定為 down。
l 其餘一些前提條件:
l 虛機必須部署在 cinder-volume 或者共享的臨時儲存比如 RBD 或者 NFS 上,這樣虛機evaculation 將不會造成資料丟失。
l 如果虛機不使用共享儲存,則必須週期性地建立虛機的快照並儲存到 Glance 中。在虛機損壞後,可以從 Glance 快照上恢復。但是,這可能會導致狀態或者資料丟失。
l 控制和計算節點需要安裝 RHEL7.1+
l 計算節點需要有防護機制,比如 IPMI,硬體狗等
具體參考這裡。
3. 海雲捷迅的方案
海雲捷迅的分散式健康檢查方案是我比較認同的一種監控計算節點是否掛掉的方案,考慮了管理、業務和儲存三個網段的監控。同時支援應用層的自定義監控方式。具體參考這裡。
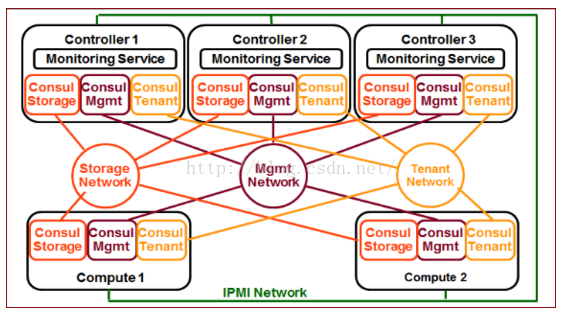
該方案引入了consul監控工具,通過consul叢集在管理、業務和儲存三個網段監控計算節點的狀態,根據不同的組合情況,做出不同的處理方式。我認為是對虛擬機器HA方案中的監控部分的深入和精細的控制,可以做到虛擬機器的精準恢復,有效的防止虛擬機器腦裂情況。
四、總結
鑑於各個公司都在為OpenStack做虛擬機器的HA方案,社群也開始考慮實現虛擬機器的HA方案,可以參考這裡。
整合各家方案的優點,儘可能的處理各種虛擬機器的異常情況,保證雲上應用的高可用。構想的如下的虛擬機器HA方案,
服務框架:借鑑https://github.com/gryf/mistral-evacuate這個工作的思想,虛擬機器HA的服務框架應該是一個相對通用的框架,用來處理各種使用者的不同應用場景。一個通用框架,要能處理不同的使用者場景,服務框架還是要有一定的抽象和通用性。這裡是HA服務的服務處理流程。
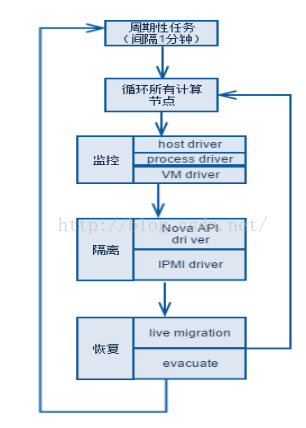
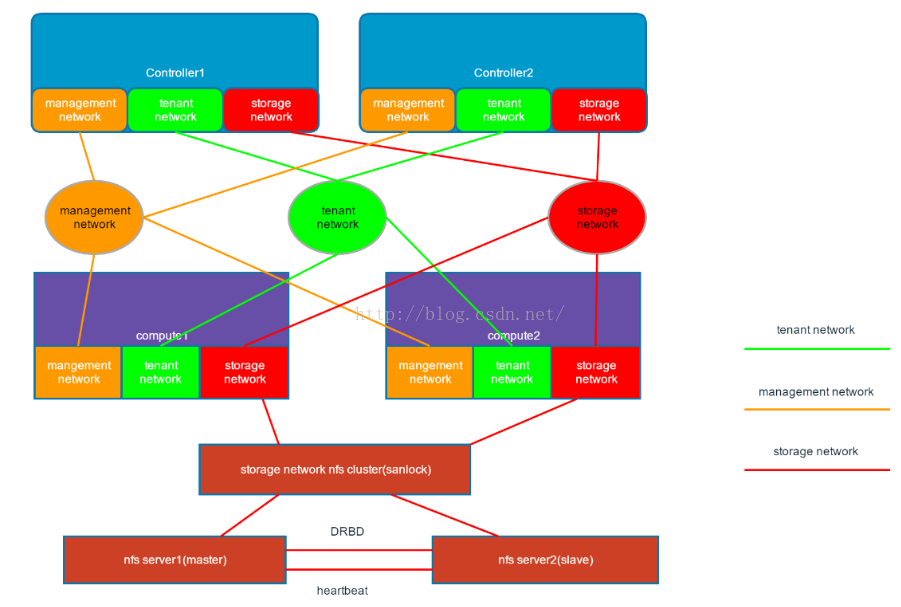
由於隔離和恢復部分基本沒有太多的選擇,各個公司的虛擬機器HA方案中基本差異都在於監控部分,如何做到精細的監控計算節點的狀態。鑑於OpenStack環境基本都是管理、業務和儲存網三網分開的部署方式,所以我覺得上邊海雲捷迅的分散式健康檢查方式是比較實用的一種監控方式,再加上Ovirt 中的虛擬機器磁碟加鎖機制。我認為可以比較好的解決虛擬機器HA的問題。參考下圖:
虛擬機器HA看似一個簡單的需求,但是從上邊的各種實現方式來看,都有著各自的有點和缺點。所以這個問題其實還是挺複雜。歡迎大家就這個問題和我交流。
三、參考文件
Openstack相關技術交流請加群:314889201
相關推薦
也談OpenStack中的虛擬機器HA
OpenStack是一個旨在為公共及私有云的建設與管理提供軟體的開源專案。它的社群擁有超過130家企業及1350位開發者,這些機構與個人都將OpenStack作為基礎設施即服務(IaaS)資源的通用前端。OpenStack專案的首要任務是簡化雲的部署過程併為其帶來良好的可擴
Openstack中虛擬機器一些效能評價指標
當我們搭建了一個虛擬化雲平臺(比如openstack)後,我們總是想要不遺餘力的提高虛擬機器的效能。這就需要有一些基準指標。最近research了一些benchmark和測試工具用於描述虛機的效能,以便為以後performance tunning提供依據。目前主要關注ope
openstack中 虛擬機器例項的備份 與 恢復
openstack中,虛擬機器例項一般是放在nova/instances目錄底下. 該目錄的典型結構如下所示: [email protected]:~# ls /opt/stack/nova/instances/ _base instance-0000001
openstack中虛擬機器CPU與記憶體佈局設計(一)
最近在整理Openstack的一些設計,發現網上找到的一些資料都比較零碎,而官方的設計文件非常詳細,但都是英文讀起來略吃力,乾脆花點功夫做點翻譯好了。 ---------------------------------------------
openstack中虛擬機器怎麼與物理機通訊
How-to-connection-ns-outside 環境配置 網路介面 vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 TYPE=Ethernet ONBOOT=yes NM_CONTROLLED
[zz]OpenStack中虛擬機器的監控
整個方案的基本思想是由host負責執行程式,採集資料,額外一臺伺服器作為server收集每臺host的資料進行分析。本文涉及的程式程式碼均可以從Github上下載,虛擬化使用kvm,使用libvirt作為C API。 AD: 本文涉及的程式程式碼均可以從我的github
VMware中虛擬機器上linux與windows之間複製貼上
說在前面 裝完CentOS 感覺桌面解析度太小,需要裝 VMware Tools。 解壓安裝包 解壓安裝包 將此檔案複製到/tmp檔案下進行解壓 解壓縮安裝程式。 執行編譯操作 執行安裝程式並以 root 使用者身份配置 VMware Tools
navicat連線本地VMware Workstation Pro中虛擬機器(ubuntu 16)中的mysql資料庫失敗
1.檢視虛擬機器ip 2.以管理員身份開啟命令列視窗,出現下圖說明虛擬機器允許外部訪問 ping 192.168.31.128 3.telnet用於遠端管理連線主機,檢視虛擬主機是否可以被遠端連線 telnet 192.168
關於openstack下虛擬機器埠開放的問題
首先交代下背景:由於想比較openstack下各種熱遷移方法的效能,我開放了將要遷移的例項的8000埠,然後執行一個腳步程式,從遠端不斷請求訪問這個例項,與此同時進行熱遷移,記錄遷移時間及效率。然而,在開放埠後,遠端並不能訪問該例項。 此時,將宿主節點的防火牆重新關閉:
OpenStack 啟動虛擬機器 Booting from Hard Disk
問題 OpenStack 啟動虛擬機器 Booting from Hard Disk…GRUB 環境 OpenStack RUNNING IN vSphere 6.0.0 VM 開啟了 CPU 虛擬化支援。 [[email prote
你建立的OpenStack高效能虛擬機器能實現“零損耗”麼?
使用預設引數建立的虛擬機器,虛擬機器的VCPU在物理CPU不同核心之間動態排程,另外,由於Linux還可能會將軟中斷,記憶體交換等程序排程到虛擬機器正在使用的物理核心上,這些因素導致這些虛擬機器相對於物理機的計算效能可能會產生較大的抖動,不能滿足一些對計算SLA要求很嚴格的業務,比如,很多金融業務就要求99.
windows中虛擬機器和windows之間互通性,並實現上傳檔案
一 測試連結是否ping通 筆記文件見百度網盤:大資料資料/windows與上安裝虛擬機器....doc; 因為安裝虛擬機器的時候,windows和vmare選擇的通訊方式為NAT方式,現在測試是否能ping通 虛擬機器的ip:192.168.59.128 Windo
Vmware workstation中虛擬機器提示獲取所有權解決方法和原理
由於虛擬機器在異常狀態下關閉主機,會提示似乎正在使用中,如果確定是在使用請獲取所有權,或者取消,無論是取消還是獲取都會關閉視窗並不會開啟虛擬機器。 經過百度發現,刪除虛擬機器目錄下面的lck資料夾即可開啟。 操作的原理是 這個lck檔案是虛擬機器的磁
虛擬機器棧-----執行緒中虛擬機器棧
虛擬機器棧 棧幀 1.1定義 棧幀(stack frame)是用於支援虛擬機器進行方法呼叫和方法執行的資料結構,它是虛擬機器執行時資料區中的虛擬機器棧的棧元素。棧幀儲存了方法的區域性變量表、運算元棧、動態連線和方法返回地址等資訊。 每
VMware中虛擬機器無法使用命令列獲取ip地址問題解決方案
問題描述: VMware中配置好的CentOS7虛擬機器前一天還可以使用ip addr獲取ip地址等資訊,第二天便無法獲取。且重新配置虛擬機器時,網路分配顯示無法使用 問題原因: 大概是win
淺談openstack中鑑權模組keystone
由於工作需要對於研究openstack中鑑權部分已有大半年,從G版本到現在的havana,期待著Icehouse,雖然期間也零零碎碎的接觸過別的模組,但是始終keystone才是我的主場,下面廢話也不多說,進入正題。 keystone中最容易讓人迷惑的不是每
ESXi 6.0 中虛擬機器拷貝(克隆)
情況一: 擁有一臺配置好的虛擬機器,想通過clone方式複製多臺虛擬機器來進行模糊測試,但是vSphere Client 6.0沒有提供克隆虛擬機器功能(可能收費版擁有吧)。 解決方法:(通過OVF模板方式部署) 在VMware vSphere Clie
openstack建立虛擬機器流程,從介面任務發起,到nova等元件處理,到虛機建立完成
1.客戶端使用自己的使用者名稱密碼請求認證。 2.keystone通過查詢在keystone的資料庫user表中儲存了user的相關資訊,包括password加密後的hash值,並返回一個token_id(令牌),和serviceCatalog(一些服務的endpoint地址,cinder、glance-ap
真正能在windows下編譯的linux 0.11,不是在Cygwin,也不是在虛擬機器裡!
一、簡介 這就是能在windows環境下直接編譯的Linux 0.11了,不是在Cygwin,也不是在虛擬機器裡,而是使用MinGW gcc,這是GNU gcc在Windows下的移植版本.在oldlinux上的論壇看見有許多人在問怎樣在Windows下直接編譯,最佳答
OpenStack啟動虛擬機器時Nova內部工作流程
Spawn instance 接下來是由虛擬化驅動器執行的虛擬機器生成程序。這個case中使用libvirt,下面要看的程式碼在virt/libvirt_conn.py 啟動一個虛擬機器首先要做的是建立libvirt xml檔案。使用to_xml()方法來獲取xml內容。