
機器學習--判別式模型與生成式模型
一、引言
本材料參考Andrew Ng大神的機器學習課程 http://cs229.stanford.edu
在上一篇有監督學習迴歸模型中,我們利用訓練集直接對條件概率p(y|x;θ)建模,例如logistic迴歸就利用hθ(x) = g(θTx)對p(y|x;θ)建模(其中g(z)是sigmoid函式)。假設現在有一個分類問題,要根據一些動物的特徵來區分大象(y = 1)和狗(y = 0)。給定這樣的一種資料集,迴歸模型比如logistic迴歸會試圖找到一條直線也就是決策邊界,來區分大象與狗這兩類,然後對於新來的樣本,迴歸模型會根據這個新樣本的特徵計算這個樣本會落在決策邊界的哪一邊,從而得到相應的分類結果。
現在我們考慮另外一種建模方式:首先,根據訓練集中的大象樣本,我們可以建立大象模型,根據訓練集中的狗樣本,我們可以建立狗模型。然後,對於新來的動物樣本,我們可以讓它與大象模型匹配看概率有多少,與狗模型匹配看概率有多少,哪一個概率大就是那個分類。
判別式模型(Discriminative Model)是直接對條件概率p(y|x;θ)建模。常見的判別式模型有 線性迴歸模型、線性判別分析、支援向量機SVM、神經網路等。
生成式模型(Generative Model)則會對x和y的聯合分佈p(x,y)建模,然後通過貝葉斯公式來求得p(yi|x),然後選取使得p(yi|x)最大的yi,即:

常見的生成式模型有 隱馬爾可夫模型HMM、樸素貝葉斯模型、高斯混合模型GMM、LDA等。
二、高斯判別分析 Gaussian Discriminant Analysis
高斯判別分析GDA是一種生成式模型,在GDA中,假設p(x|y)滿足多值正態分佈。多值正態分佈介紹如下:
2.1 多值正態分佈 multivariate normal distribution
一個n維的多值正態分佈可以表示為多變數高斯分佈,其引數為均值向量![]() ,協方差矩陣
,協方差矩陣![]() ,其概率密度表示為:
,其概率密度表示為:
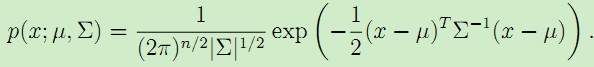
當均值向量為2維時概率密度的直觀表示:
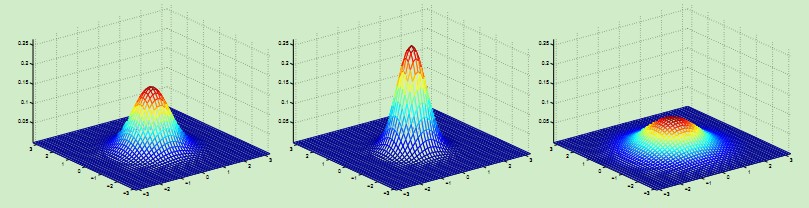
左邊的圖表示均值為0,協方差矩陣∑ = I;中間的圖表示均值為0,協方差矩陣∑ = 0.6I;右邊的圖表示均值為0,協方差矩陣∑ = 2I。可以觀察到,協方差矩陣越大,概率分佈越扁平;協方差矩陣越小,概率分佈越高尖。
2.2 高斯判別分析模型
如果有一個分類問題,其訓練集的輸入特徵x是隨機的連續值,就可以利用高斯判別分析。可以假設p(x|y)滿足多值正態分佈,即:
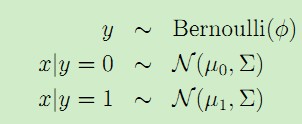
該模型的概率分佈公式為:
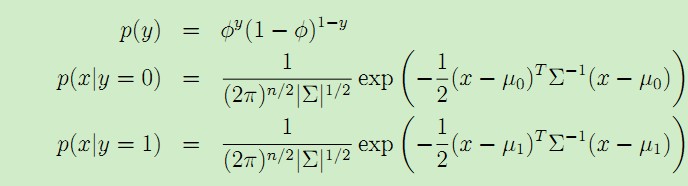
模型中的引數為Φ,Σ,μ0和μ1。於是似然函式(x和y的聯合分佈)為:

其中Φ是y = 1的概率,Σ是協方差矩陣,μ0是y = 0對應的特徵向量x的均值 , μ1是y = 1對應的特徵向量x的均值,於是得到它們的計算公式如下:
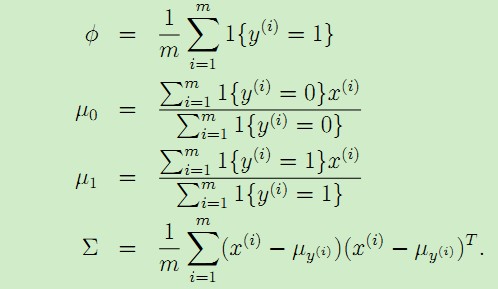
於是這樣就可以對p(x,y)建模,從而得到概率p(y = 0|x)與p(y = 1|x),從而得到分類標籤。其結果如下圖所示:
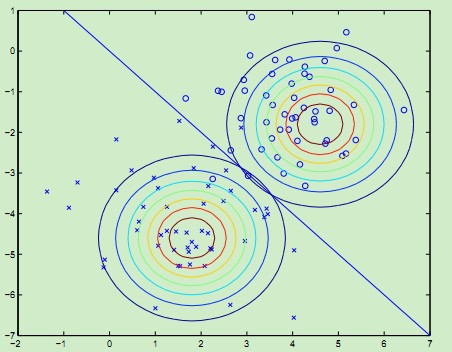
三、樸素貝葉斯模型
在高斯判別分析GDA中,特徵向量x是連續實數值,如果特徵向量x是離散值,可以利用樸素貝葉斯模型。
3.1 垃圾郵件分類
假設我們有一個已被標記為是否是垃圾郵件的資料集,要建立一個垃圾郵件分類器。用一種簡單的方式來描述郵件的特徵,有一本詞典,如果郵件包含詞典中的第i個詞,則設xi = 1,如果沒有這個詞,則設xi = 0,最後會形成這樣的特徵向量x:

這個特徵向量表示郵件包含單詞"a"和單詞"buy",但是不包含單詞"aardvark,"aardwolf","zygmurgy"。特徵向量x的維數等於字典的大小。假設字典中有5000個單詞,那麼特徵向量x就為5000維的包含0/1的向量,如果我們建立多項式分佈模型,那麼有25000中輸出結果,這就意味著有接近25000個引數,這麼多的引數,要建模很困難。
因此為了建模p(x|y),必須做出強約束假設,這裡假設對於給定的y,特徵x是條件獨立的,這個假設條件稱為樸素貝葉斯假設,得到的模型稱為樸素貝葉斯模型。比如,如果y= 1表示垃圾郵件,其中包含單詞200 "buy",以及單詞300 "price",那麼我們假設此時單詞200 "buy" x200、單詞300"price"x300 是條件獨立的,可以表示為p(x200|y) = p(x200|y,x300)。注意,這個假設與x200與x300獨立是不同的,x200與x300獨立可以寫作:p(x200) = p(x200|x300);這個假設是對於給定的y,x200與x300是條件獨立的。
因此,利用上述假設,根據鏈式法則得到:
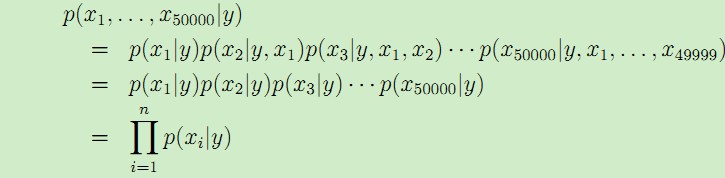
該模型有3個引數:
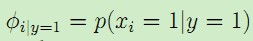 ,
, 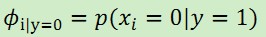 ,
, 
那麼。根據生成式模型的規則,我們要使聯合概率最大:

根據這3個引數意義,可以得到它們各自的計算公式:
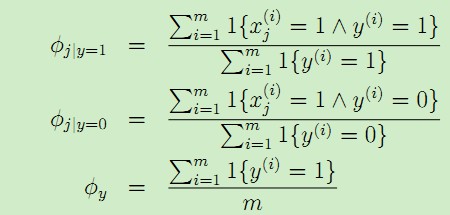
這樣就得到了樸素貝葉斯模型的完整模型。對於新來的郵件特徵向量x,可以計算:

實際上只要比較分子就行了,分母對於y = 0和y = 1是一樣的,這時只要比較p(y = 0|x)與p(y = 1|x)哪個大就可以確定郵件是否是垃圾郵件。
3.2 拉普拉斯平滑
樸素貝葉斯模型可以在大部分情況下工作良好。但是該模型有一個缺點:對資料稀疏問題敏感。
比如在郵件分類中,對於低年級的研究生,NIPS顯得太過於高大上,郵件中可能沒有出現過,現在新來了一個郵件"NIPS call for papers",假設NIPS這個詞在詞典中的位置為35000,然而NIPS這個詞從來沒有在訓練資料中出現過,這是第一次出現NIPS,於是算概率時:
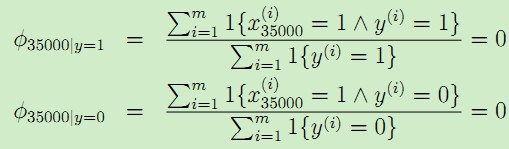
由於NIPS從未在垃圾郵件和正常郵件中出現過,所以結果只能是0了。於是最後的後驗概率:
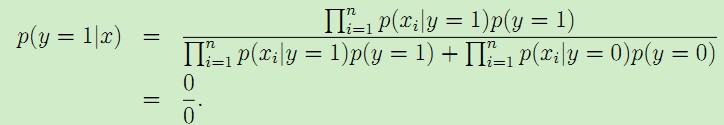
對於這樣的情況,我們可以採用拉普拉斯平滑,對於未出現的特徵,我們賦予一個小的值而不是0。具體平滑方法為:
假設離散隨機變數取值為{1,2,···,k},原來的估計公式為:

使用拉普拉斯平滑後,新的估計公式為:
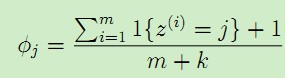
即每個k值出現次數加1,分母總的加k,類似於NLP中的平滑,具體參考宗成慶老師的《統計自然語言處理》一書。
對於上述的樸素貝葉斯模型,引數計算公式改為:
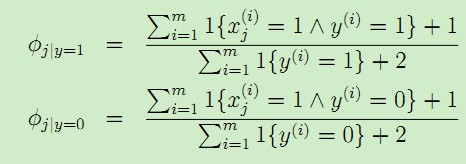
相關推薦
機器學習--判別式模型與生成式模型
一、引言 本材料參考Andrew Ng大神的機器學習課程 http://cs229.stanford.edu 在上一篇有監督學習迴歸模型中,我們利用訓練集直接對條件概率p(y|x;θ)建模,例如logistic迴歸就利用hθ(x) = g(θTx)對p(y|x;θ)建模(其中g(z)是sigmoi
判別式模型與生成式模型(二)
一、引言 本材料參考Andrew Ng大神的機器學習課程 http://cs229.stanford.edu 在上一篇有監督學習迴歸模型中,我們利用訓練集直接對條件概率p(y|x;θ)建模,例如logistic迴歸就利用hθ(x) = g(θTx)對p(y|x;θ)建模(其中g(z)是sigmoid
機器學習之判別式模型和生成式模型
https://www.cnblogs.com/nolonely/p/6435213.html 判別式模型(Discriminative Model)是直接對條件概率p(y|x;θ)建模。常見的判別式模型有線性迴歸模型、線性判別分析、支援向量機SVM、神經網路、boosting
機器學習與深度學習系列連載: 第一部分 機器學習(五) 生成概率模型(Generative Model)
生成概率模型(Generative Model) 1.概率分佈 我們還是從分類問題說起: 當我們把問題問題看做是一個迴歸問題, 分類是class 1 的時候結果是1 分類為class 2的時候結果是-1; 測試的時候,結果接近1的是class1
判別式與生成式模型的區別
判別式模型與生成式模型的區別 產生式模型(Generative Model)與判別式模型(Discrimitive Model)是分類器常遇到的概念,它們的區別在於: 對於輸入x,類別標籤y: 產生式模型估計它們的聯合概率分佈P(x,y) 判別式模型估計條件概率分佈P(y|x) 產生式模型可以根據貝葉
BAT面試題9:談談判別式模型和生成式模型?
BAT面試題9:談談判別式模型和生成式模型? https://mp.weixin.qq.com/s/X7zWJCMN7gbCwqskIIpLcw 判別方法:由資料直接學習決策函式 Y = f(X),或者由條件分佈概率 P(Y|X)作為預測模型,即判別模型。 生成
判別式模型 vs. 生成式模型
1. 簡介 生成式模型(generative model)會對\(x\)和\(y\)的聯合分佈\(p(x,y)\)進行建模,然後通過貝葉斯公式來求得\(p(y|x)\), 最後選取使得\(p(y|x)\)最大的\(y_i\). 具體地, \(y_{*}=arg \max_{y_i}p(y_i|x)=ar
什麼是判別式模型和生成式模型
判別式模型(Discriminative Model):直接對條件概率p(y|x)進行建模,常見判別模型有:線性迴歸、決策樹、支援向量機SVM、k近鄰、神經網路等;生成式模型(Generative Model):對聯合分佈概率p(x,y)進行建模,常見生成式模型有:隱馬爾可夫
機器學習引數設定與預訓練模型設定
使用tensorlayer時,出現了大量相關的引數設定,通用的引數設定如下:task = 'dcgan' flags = tf.app.flags flags.DEFINE_string('task','dcgan','this task name') flags.DEFIN
機器學習_生成式模型與判別式模型
從概率分佈的角度看待模型。 給個例子感覺一下: 如果我想知道一個人A說的是哪個國家的語言,我應該怎麼辦呢? 生成式模型 我把每個國家的語言都學一遍,這樣我就能很容易知道A說的是哪國語言,並且C、D說的是哪國的我也可以知道,進一步我還能自己講不同國家語言。
機器學習小問題 -- 生成式模型與判別式模型
本篇博文總結最近學習到的生成式模型與判別式模型的知識。 1. 簡介 就像之前在總結分類和聚類時說的一樣,機器學習基本在做的事情就是在分類、打標籤,我們的模型也就像一個個分類機器(個人看法,歡迎指正)。而這麼多的模型,可以分為兩類:生成式模型與判別式模型。 對於一個分類器
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之二(作者簡介)
AR aca rtu href beijing cert school start ica Brief Introduction of the AuthorChief Architect at 2Wave Technology Inc. (a startup company
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之一(簡介)
價值 新書 The aar 生成 syn TE keras 第一章 A Gentle Introduction to Probabilistic Modeling and Density Estimation in Machine LearningAndA Detailed
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之五(第3章 之 EM算法)
ado vpd dea bee OS deb -o blog Oz 機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之五(第3章 之 EM算法)
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之六(第3章 之 VI/VB算法)
dac term http 51cto -s mage 18C watermark BE ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之七(第4章 之 梯度估算)
.com 概率 roc 生成 詳解 time 學習 style BE ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?機器學習中的概率模型和概率密度估計方法及V
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之八(第4章 之 AEVB和VAE)
RM mes 9.png size mar evb DC 機器 DG ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之九(第5章 總結)
ces mark TP 生成 機器 分享 png ffffff images ? ?機器學習中的概率模型和概率密度估計方法及VAE生成式模型詳解之九(第5章 總結)
機器學習中的概率模型和概率密度估計方法 及 VAE生成式模型詳解(之二)
簡介 非監督機器學習(Unsupervised Machine Learning)中的資料分佈密度估計(Density Estimation)、樣本取樣(Sampling)與生成(Generation,或Synthesis,即合成)等幾類任務具有重要的應用價值,這從近
機器學習引數模型與非引數模型/生成模型與判別模型
2018-03-31更新:生成模型與判別模型引數模型:根據預先設計的規則,例如方差損失最小,進行學習,引數模型例子:迴歸(線性迴歸、邏輯迴歸)模型;最好可以看一下或者直接進行一下相關的推導;根據規則,擁有少部分資料就可以;非引數模型:不需要事先假設規則,直接挖掘潛在資料中的規