
PyTorch學習筆記(3)—CPU和GPU上載入模型
前言
有一些現實的問題是這樣的:當我們在GPU叢集或者伺服器上訓練模型的時候,有時候需要將模型取回,在本地測試一下。這個時候就需要PyTorch將模型轉換為cpu的版本,因為PyTorch針對不同的系統和cuda有不同的版本。因此無法直接將GPU訓練出的模型直接用於CPU來做inference,需要進行一些簡單的變化。
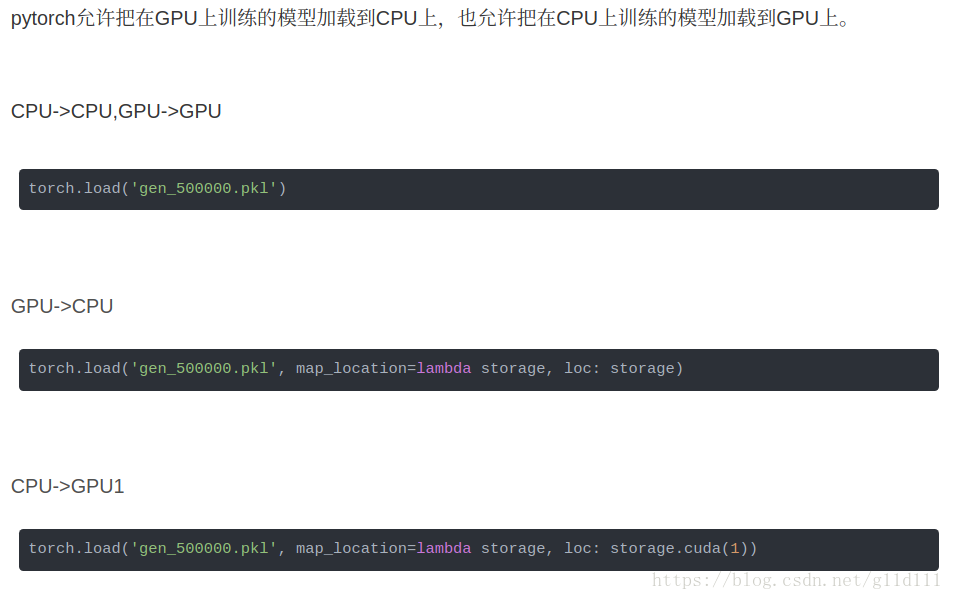
pytorch允許把在GPU上訓練的模型載入到CPU上,也允許把在CPU上訓練的模型載入到GPU上。
相關推薦
PyTorch學習筆記(3)—CPU和GPU上載入模型
前言 有一些現實的問題是這樣的:當我們在GPU叢集或者伺服器上訓練模型的時候,有時候需要將模型取回,在本地測試一下。這個時候就需要PyTorch將模型轉換為cpu的版本,因為PyTorch針對不同的系統和cuda有不同的版本。因此無法直接將GPU訓練出的
[PyTorch 學習筆記] 3.3 池化層、線性層和啟用函式層
> 本章程式碼:[https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/nn_layers_others.py](https://github.com/zhangxiann/PyTorch_Practice/blob/mas
Shader 入門筆記(二) CPU和GPU之間的通信
draw drawcall 進行 時間 包含 spa 入門 光柵 著色器 渲染流水線的起點是CPU,即應用階段。 1)把數據加載到顯存中 2)設置渲染狀態,通俗說這些狀態定義了場景中的網格是怎樣被渲染的。 3)調用DrawCall,一個命令,CPU通知GPU。(
取模 乘法和除法運算在CPU和GPU上的效率
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
mybatis學習筆記(3)—資料庫和bean名稱不一樣處理方案
之前寫的mybatis物件的bean物件和資料庫的物件名稱是對應的,然而再實際開發的過程有很多不一一對應的情況。就需要解決。 bean物件: package com.test.bean; /* * javabean 物件 */ public class order { pr
《introduction to information retrieval》資訊檢索學習筆記3 詞典和容錯式檢索
第3章 詞典和容錯式檢索 3.1 用於詞典的搜尋結構 給定一個反向索引和一個查詢,我們的第一個任務是確定每個查詢詞是否存在於詞彙表中,如果是,則返回指向相應倒排記錄表的指標。涉及在資料結構中定位詞項。 資料結構:字典(dictionary ) 兩個解決方案:雜湊
GPU 學習筆記(一)::CPU與GPU的資料互傳
開始接觸GPU,讀了一部分GPGPU::Basic Math Tutorial 整理了前一部分CPU與GPU互傳資料的程式碼,記錄如下: #include <stdio.h> #include <stdlib.h> #include <
零基礎深度學習筆記3——Win7-Tensorflow-GPU安裝
之前已經在另一臺電腦上安裝好了CPU版本的TF, 以為GPU版本的步驟什麼的應該也不難,沒想到還是有些坑要填。 清單: 系統:WIN7 python:3.5版本 CUDA:8.0 Cudnn:v6.0(這裡版本的選擇很重要!!!) Tensorflow:1.3 下面說下
python學習筆記3--dict和set
字典物件 和其他許多語言一樣(如java的map,JavaScript的物件),python也有字典物件(dictionary)。字典物件的一個特徵就是以鍵值對(key-value)的方式儲存資料。 python dict的建立方式為一對花括號包上鍵值對s。如:studen
keras學習筆記3——Merge、GPU呼叫、快速開始及常見問題
1. Merge層 Merge層主要是用來合併多個model的,例子如下: from keras.layers import Merge,Dense from keras.models import Sequential first_model=Sequ
[PyTorch 學習筆記] 3.1 模型建立步驟與 nn.Module
> 本章程式碼:[https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/module_containers.py](https://github.com/zhangxiann/PyTorch_Practice/blob/ma
PyTorch學習筆記(10)——上取樣和PixelShuffle
去年曾經使用過FCN(全卷積神經網路)及其派生Unet,再加上在愛奇藝的時候做過一些超解析度重建的內容,其中用到了畢業於帝國理工的華人博士Shi Wenzhe(在Twitter任職)發表的PixelShuffle《Real-Time Single Image and Video
吳恩達-深度學習-課程筆記-3: Python和向量化( Week 2 )
有時 指數 檢查 都是 效果 很快 -1 tro str 1 向量化( Vectorization ) 在邏輯回歸中,以計算z為例,z = w的轉置和x進行內積運算再加上b,你可以用for循環來實現。 但是在python中z可以調用numpy的方法,直接一句z = np.d
OpenCV學習筆記3:圖像模糊作用和方法
希望 ont 去模糊 image title name 聽說 但是 意義 一、意義和作用: 圖像的模糊處理就是將圖片處理的更加模糊,如下圖,左側是原圖,右側是經過處理之後的圖片。 從主觀意願上說,我們希望看到清晰的圖像,而不是模糊的圖像。所以很多時候我們聽說還有一種專門進
.net core學習筆記《sdk和runtime區別及使用CLI在Ubuntu上快速搭建Console,WebApi,MVC三大應用模型》
img 裝包 new 來看 tin console bubuko file 接下來 一、需要安裝的軟件 1、虛擬機安裝Ubuntu系統(本人用的是vmware-14.1.12和buntu-18.04) 2、Xshell或 Putty(連接ssh服務) 3、FileZilla
Python 3 學習筆記之——錯誤和異常
參考 箭頭 cto last image 直接 cep 分享 一行 1. 語法錯誤 Python 的語法錯誤被稱為解析錯,語法分析器會指出出錯的代碼行,並且在最先找到的錯誤的位置標記一個小小的箭頭。 >>> while True File "&l
C++的終端輸入和輸出(C++學習筆記 3)
C++和C的輸入輸出方面的不同 在C中輸入和輸出,常使用函式scanf和printf。 C++除了可以照常使用這兩個函式進行輸入和輸出外,還增加了標準輸入流物件cin(念 see-in)和標準輸出流物件cout(念 see-out) scanf("%d",i); printf
誰說菜鳥不會資料分析(工具篇)----- 學習筆記3(資料展現和日報月報自動化)
1、資料視覺化的意義 互動性:使用者能夠方便地通過互動介面實現資料的管理、計算與預測 多維性:可從資料的多個屬性或變數對資料進行切片、鑽取、旋轉等,以此剖析資料,從而能多角度、多方面分析資料 可視性:資料可用影象、二維圖形、三維圖形和動畫等方式來展現,並可對其模式和相互關係進行
Arduino 入門學習筆記3 程式結構和常用函式
Arduino 的程式可以劃分為三個主要部分:結構、變數(變數與常量)、函式。 函式 1、setup() 當Arduino開始的時候被呼叫。用它來初始化變數,設定引腳執行模式,啟動庫檔案等。setup函式只執行一次,每次上電或者被重置時候呼叫。 int buttonPin
PyTorch學習筆記(9)——nn.Conv2d和其中的padding策略
一. Caffe、Tensorflow的padding策略 在之前的轉載過的一篇文章——《tensorflow ckpt檔案轉caffemodel時遇到的坑》提到過,caffe的padding方式和tensorflow的padding方式有很大的區別,輸出無法