
常用SparkRDD容易混淆的運算元區別(Scala版本)
常用SparkRDD容易混淆的運算元區別
1.map與flatMap的區別
# 初始化資料
val rdd1 = sc.parallelize(Array("hello world","i love you"))- map
# map運算元
rdd1.map(_.split(" ")).collect
# map運算元結果輸出
res0: Array[Array[String]] = Array(Array(hello, world), Array(i, love, you))- flatMap
# flatMap運算元
rdd1.flatMap(_.split(" " flatMap是將資料先進行map轉化,在通過flattern對map結果進行’壓平’。也就是將map轉化的2個Array壓平處理。
flatMap的效率要優於map
2.map與mapPartitions的區別
map是對rdd中的每一個元素進行操作。
mapPartitions(foreachPartition)則是對rdd中的每個分割槽的迭代器進行操作。
如果在map過程中需要頻繁建立額外的物件(例如將rdd中的資料通過jdbc寫入資料庫,map需要為每個元素建立一個連結而mapPartition為每個partition建立一個連結),則mapPartitions效率比map高的多
- map示例
# 初始化資料,設定3個分割槽
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9),3)
rdd.map(x=>{println(x);x*2}).collect輸出結果:
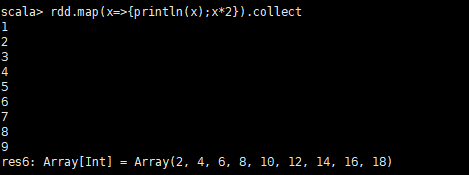
- mapPartitions示例
rdd.mapPartitions(x=>{println("-----------");for(i<-x)yield i*2}).collect輸出結果:

通過對比,我們可以發現,mapPartitions在每個分割槽只會呼叫一次。而map每次都會被呼叫。所以在特定的場景mapPartitions效率比map高的多
3.mapPartitionsWithIndex示例
- mapPartitionsWithIndex
類似於mapPartitions,但取兩個引數。
第一個引數是分割槽的索引(index),第二個引數是通過這個分割槽中的所有項的迭代器(iterator)。
輸出是一個迭代器,它包含在應用函式編碼的任何轉換之後的專案列表。
# 初始化資料
val rdd = sc.makeRDD(1 to 10, 3)
# mapPartitionsWithIndex方法是呼叫,傳入一個函式,函式引數1為index,引數2為iterator
rdd.mapPartitionsWithIndex((index, iter) => iter.map((index, _))).foreach(println)輸出結果:
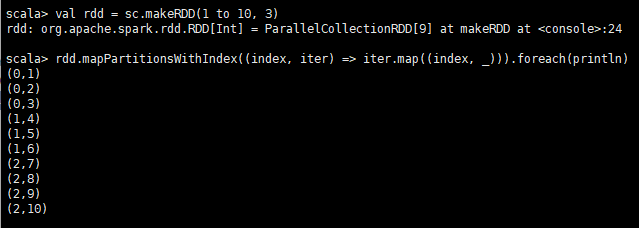
4.mapValues與flatMapValues
- mapValues
# 初始化rdd
val rdd = sc.makeRDD(List("hello spark", "hello java", "hello python", "hello r","hello scala"), 2)
rdd.map(x => (x.length % 3, x)).mapValues(x => x.split(" ")).collect()輸出結果:

- flatMapValues
# 初始化rdd
val rdd = sc.makeRDD(List("hello spark", "hello java", "hello python", "hello r","hello scala"), 2)
rdd.map(x => (x.length % 3, x)).flatMapValues(x => x.split(" ")).collect()輸出結果:

flatMapValues是把map中的value進行過函式操作後,再將資料結構壓平。
5.coalesce、repartition與partitionBy
- coalesece
該函式用於將RDD進行重分割槽,使用HashPartitioner進行分割槽。
接受2個引數,第一個引數為重分割槽的數目,第二個為是否進行shuffle,預設為false;
val rdd1 = sc.parallelize(1 to 12,3)
println(rdd1.partitions.length) //輸出結果 3
val rdd2 = rdd1.coalesce(2)
println(rdd2.partitions.length) // 輸出結果 2
//如果重分割槽的數目大於原來的分割槽數,那麼必須指定shuffle引數為true,//否則,分割槽數不變
val rdd3 = rdd1.coalesce(4)
println(rdd3.partitions.length) // 輸出結果 3
val rdd4 = rdd1.coalesce(4,true)
println(rdd4.partitions.length) // 輸出結果 4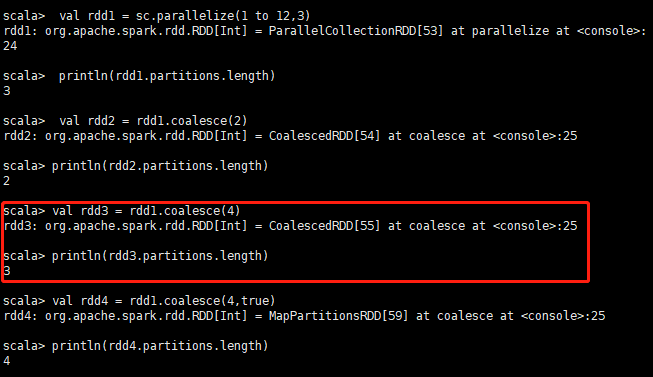
- repartition
該函式其實就是coalesce函式第二個引數為true的實現
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}示例:
val rdd1 = sc.parallelize(1 to 12,3)
val rdd5 = rdd1.repartition(4)
println(rdd5.partitions.length) // 輸出結果 4
- partitionBy
partitionBy:表示重新分割槽,不是僅僅是設定分割槽數
var rdd1 = sc.makeRDD(Array((1, "A"), (2, "B"), (3, "C"), (4, "D")), 2)
rdd1.mapPartitionsWithIndex { (index, iter) => for (i <- iter) yield (index, i) }.foreach(println)
# 重新設定分割槽
var rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2.mapPartitionsWithIndex { (index, iter) => for (i <- iter) yield (index, i) }.foreach(println)結果如圖:4.13圖
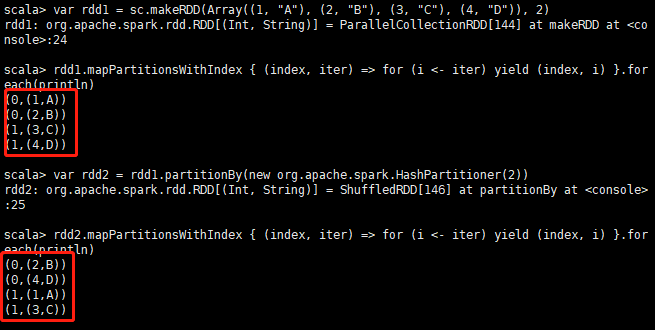
6.union、distinct、intersection、subtract
- union
求並集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
rdd1.union(rdd2).collect
# 輸出結果,這個結果不會去重
res52: Array[Int] = Array(5, 6, 4, 3, 1, 2, 3, 4)- distinct
去重
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
val rdd3 = rdd1.union(rdd2)
rdd3.distinct.collect
# 輸出結果,結果去重
res53: Array[Int] = Array(4, 6, 2, 1, 3, 5)- intersection
求交集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
rdd1.intersection(rdd2).collect
# 輸出結果:
res54: Array[Int] = Array(4, 3)- subtract
求差集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
rdd1.subtract(rdd2).collect
# 輸出結果
res55: Array[Int] = Array(5, 6)
rdd2.subtract(rdd1).collect
# 輸出結果
res56: Array[Int] = Array(1, 2)- subtractByKey
subtractByKey和基本轉換操作中的subtract類似,只不過這裡是針對K的
val rdd1 = sc.makeRDD(Array(("A", "1"), ("B", "2"), ("B", "3"), ("C", "3")), 2)
val rdd2 = sc.makeRDD(Array(("A", "a"), ("C", "c"), ("D", "d")), 2)
rdd1.subtractByKey(rdd2).collect
# 輸出結果:因為rdd2的key中有A,C,所以差集就是B
res57: Array[(String, String)] = Array((B,2), (B,3))
rdd2.subtractByKey(rdd1).collect
# 輸出結果:
res58: Array[(String, String)] = Array((D,d))7.groupByKey、reduceByKey、foldByKey、aggregateByKey
- groupByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
//求並集
val rdd3 = rdd1 union rdd2
rdd3.groupByKey().collect
# 輸出結果:
res89: Array[(String, Iterable[Int])] = Array((tom,CompactBuffer(1, 3)), (jerry,CompactBuffer(3, 2)), (shuke,CompactBuffer(1, 2)), (kitty,CompactBuffer(2, 5)))
rdd3.groupByKey().map(t=>(t._1,t._2.sum)).collect
# 輸出結果:
res90: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))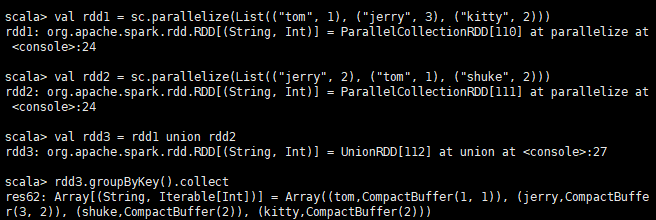
- reduceByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
//按key進行聚合
rdd3.reduceByKey(_ + _).collect
# 輸出結果:
res91: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))groupByKey和reduceByKey都可以通過key來進行聚合。不同的是2者,聚合的過程是不一樣的。
reduceByKey現在map過程中先進行聚合,再到reduce端聚合,減少資料太大帶來的壓力,減小RPC過程中的傳輸壓力。
groupByKey是直接在reduce端進行聚合的,所以效率比reduceByKey低。
推薦使用reduceByKey,因為效率比groupByKey高
- foldByKey
該函式用於RDD[K,V]根據K將V做摺疊、合併處理,其中的引數zeroValue表示先根據對映函式將zeroValue應用於V,進行初始化V,再將對映函式應用於初始化後的V.
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
rdd3.foldByKey(0)(_ + _).collect
# 輸出結果:
res84: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))foldByKey和reduceByKey的功能是相似的,都是在map端先進行聚合,再到reduce聚合。不同的是flodByKey需要傳入一個引數。該引數是計算的初始值。
- aggregateByKey
aggregateByKey函式對PairRDD中相同Key的值進行聚合操作,在聚合過程中同樣使用了一箇中立的初始值。
def aggregateByKey[U](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U)(implicit arg0: ClassTag[U]): RDD[(K, U)]
def aggregateByKey[U](zeroValue: U, numPartitions: Int)(seqOp: (U, V) => U, combOp: (U, U) => U)(implicit arg0: ClassTag[U]): RDD[(K, U)]
def aggregateByKey[U](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U)(implicit arg0: ClassTag[U]): RDD[(K, U)]示例:
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
# aggregateByKey(0)(math.max(_,_),_+_)
# (0):0是傳入的初始值
# math.max(_,_):是一個函式,表示傳入的資料與初始值比較,取最小值
# _+_:和reduceByKey中一樣,表示`(x,y)=>x+y`這樣的函式
rdd3.aggregateByKey(0)(math.max(_,_),_+_).collect
# 輸出結果:
res93: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))aggregateByKey會先在本節點內先聚合,然後再聚合所有節點的結果。
8.zip函式與zipPartitions函式
- zip函式
zip函式用於將兩個RDD組合成Key/Value形式的RDD
var rdd1 = sc.makeRDD(1 to 5, 2)
var rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
rdd1.zip(rdd2).foreach(println)
# 輸出結果:
(1,A)
(2,B)
(3,C)
(4,D)
(5,E)
rdd2.zip(rdd1).foreach(println)
# 輸出結果:
(A,1)
(B,2)
(C,3)
(D,4)
(E,5)這裡需要注意的是:
1.如果兩個RDD分割槽數不同,則丟擲異常:Can’t zip RDDs with unequal numbers of partitions
2.如果兩個RDD的元素個數不同,則丟擲異常:Can only zip RDDs with same number of elements in each partition
- zipPartitions函式
zipPartitions函式將多個RDD按照partition組合成為新的RDD。
該函式需要組合的RDD具有相同的分割槽數,但對於每個分割槽內的元素數量沒有要求。
2個RDD進行zipPartitions操作
var rdd1 = sc.makeRDD(1 to 5, 2)
var rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
rdd1.zipPartitions(rdd2) {
(rdd1Iter, rdd2Iter) => {
var result = List[String]()
while (rdd1Iter.hasNext && rdd2Iter.hasNext) {
result ::= (rdd1Iter.next() + "_" + rdd2Iter.next())
}
result.iterator
}
}.foreach(println)
# 輸出結果:
2_B
1_A
5_E
4_D
3_C
3個RDD進行zipPartitions操作
var rdd1 = sc.makeRDD(1 to 5, 2)
var rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
var rdd3 = sc.makeRDD(Seq("a", "b", "c", "d", "e"), 2)
var rdd4 = rdd1.zipPartitions(rdd2, rdd3) {
(rdd1Iter, rdd2Iter, rdd3Iter) =>
{
var result = List[String]()
while (rdd1Iter.hasNext && rdd2Iter.hasNext && rdd3Iter.hasNext) {
result ::= (rdd1Iter.next() + "_" + rdd2Iter.next() + "_" + rdd3Iter.next())
}
result.iterator
}
}
rdd4.foreach(println)
# 輸出結果:
2_B_b
1_A_a
5_E_e
4_D_d
3_C_c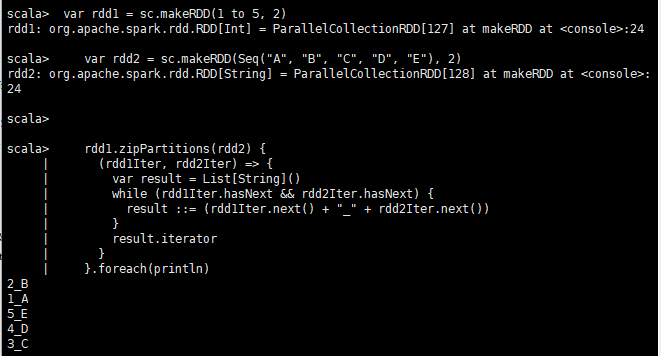
9.zipWithIndex函式與zipWithUniqueId函式
- zipWithIndex函式
該函式將RDD中的元素和這個元素在RDD中的ID(索引號)組合成鍵/值對。
va rdd2 = sc.makeRDD(Seq("A", "B", "R", "D", "F"), 2)
rdd2.zipWithIndex().foreach(println)
# 輸出結果:
(A,0)
(B,1)
(R,2)
(D,3)
(F,4)- zipWithUniqueId函式
該函式將RDD中元素和一個唯一ID組合成鍵/值對,
該唯一ID生成演算法如下:
每個分割槽中第一個元素的唯一ID值為:該分割槽索引號
每個分割槽中第N個元素的唯一ID值為:(前一個元素的唯一ID值) + (該RDD總的分割槽數)
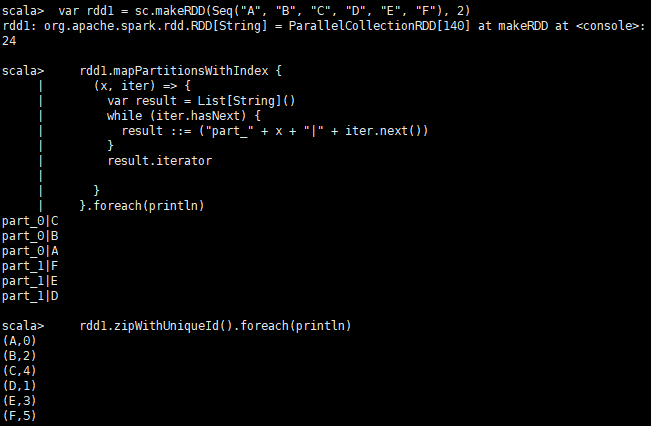
var rdd1 = sc.makeRDD(Seq("A", "B", "C", "D", "E", "F"), 2)
rdd1.mapPartitionsWithIndex {
(x, iter) => {
var result = List[String]()
while (iter.hasNext) {
result ::= ("part_" + x + "|" + iter.next())
}
result.iterator
}
}.foreach(println)
rdd1.zipWithUniqueId().foreach(println)結果如圖:
相關推薦
常用SparkRDD容易混淆的運算元區別(Scala版本)
常用SparkRDD容易混淆的運算元區別 1.map與flatMap的區別 # 初始化資料 val rdd1 = sc.parallelize(Array("hello world","i love you")) map # map運算元 r
spark中各種transformation運算元操作(scala版)
package cn.spark.study.core import org.apache.spark.SparkConf import org.apache.spark.SparkContext
Spark中的各種action運算元操作(scala版)
這裡直接貼程式碼了,action的介紹都在java那裡。 package cn.spark.study.core import org.apache.spark.SparkConf import org.apache.spark.SparkContext
常用對照表的參考_chapter-two(Content-Type)
接下來 adding 網頁服務器 發送請求 不一致 行修改 用戶信息 官網 頁面 HTTP狀態碼詳解 狀態碼含義 100 客戶端應當繼續發送請求。這個臨時響應是用來通知客戶端它的部分請求已經被服務器接收,且仍未被拒絕。客戶端應當繼續發送請求的剩余部
PHP常用內置函數記憶(持更)
會話控制 time 個數 array 函數 pat world set 運算 <?php /** * 會話控制 */ //開啟session session_start(); //創建session $_SESSION[‘name‘] = ‘admin‘; /
spark HelloWorld程序(scala版)
special hide dst tproxy top targe 提取 main read 使用本地模式,不需要安裝spark,引入相關JAR包即可: <dependency> <groupId>or
一些常用的正則表達式(from web)
常用 15位 rom 整數 使用 手機號 如果 逗號 之間 一、校驗數字的表達式數字:^[0-9]*$n位的數字:^\d{n}$至少n位的數字:^\d{n,}$m-n位的數字:^\d{m,n}$零和非零開頭的數字:^(0|[1-9][0-9]*)$非零開頭的最多帶兩位小
TYPE=MyISAM 與 ENGINE=MyISAM 的區別(摘要版)
不必要 內存 非默認 type eat create 兼容 實現 默認 TYPE=MyISAM 和 ENGINE=MyISAM 都是設置數據庫存儲引擎的語句 (老版本的MySQL使用TYPE而不是ENGINE(例如,TYPE = MYISAM)。 MySQL 5.1為向下
基於編輯距離來判斷詞語相似度方法(scala版)
使用 ref ray 只需要 art 算法 位置 spark else 詞語相似性比較,最容易想到的就是編輯距離,也叫做Levenshtein Distance算法。在Python中是有現成的模塊可以幫助做這個的,不過代碼也很簡單,我這邊就用scala實現了一版。 編輯
滲透日記20180125--每日點滴--URL中?和#的區別(關於SSRF)以及mysql的secure-file-priv
mysq www. transport post 這樣的 pan .com 並不是 aaa 零,緒論 20180125日,忙! 瞎比比總結一下,來滿足這是個日記的樣子。 1、今天談的並不是什麽技術【當然也不是沒有技術(都很基礎)】而是瞎幾把扯。 一、關於一種SSRF的檢測繞
數據分析、數據挖掘、機器學習、神經網絡、深度學習和人工智能概念區別(入門級別)
新的 簡單 什麽 nbsp 駕駛 exce 小白 數學 未來 數據分析, 就是對數據進行分析, 得出一些結論性的內容, 用於決策。 分析什麽哪? 根據分析現狀、 分析原因、 預測未來。 分析現狀和分析原因, 需要結合業務才能解釋清楚。 用到的技術比較簡單, 最簡單的數據分析
用maven來創建scala和java項目代碼環境(圖文詳解)(Intellij IDEA(Ultimate版本)、Intellij IDEA(Community版本)和Scala IDEA for Eclipse皆適用)(博主推薦)
搭建 ava XML .com 自動 ado ima 強烈 mapred 為什麽要寫這篇博客? 首先,對於spark項目,強烈建議搭建,用Intellij IDEA(Ultimate版本),如果你還有另所愛好嘗試Scala IDEA for Eclipse,有時間自己去
線程和進程有什麽區別(簡單介紹)
復雜 解決 創建 兩種 多線程編程 none 用戶界面 queue cpu調度 簡單介紹 一、線程的基本概念 線程是進程中執行運算的最小單位,是進程中的一個實體,是被系統獨立調度和分派的基本單位,線程自己不擁有系統資源,只擁有一點在運行中必不可少的資源,但它可與同屬一個
自己常用的linux系統優化shell(Centos6 64)
you end confd pci ctrl+ table ctrl update yun 優化內容包括 內核(文章末尾註釋掉了,看個人需求) ssh 時間同步 yum源 #!/bin/bash#update time 20180824#versio
Ctrl、Alt、Shift常用的電腦快捷鍵大全(收藏級)
cfb 日常 分享 atp 大全 工作 pst 技術 mage 日常工作中,天天都要和電腦打交道,所以掌握一些快捷鍵是很有必要的,今天來給大家分享一波Ctrl、Alt、Shift常用的電腦快捷鍵大全,有需要的可以收藏起來備用。 Ctrl、Alt、Shift常
GET和POST兩種請求方法的區別(RFC翻譯)
GET和POST方法是HTTP協議規定的。查了HTTP1.1的RFC,原文的專業性極強。下面是白話翻譯,歡迎補充和指錯。 GET方法就是檢索(以實體的形式)由請求uri所指定的資源。如果請求的uri指向資料產生的過程,應該把產生的資料應作為實體在響應中返回而不是源文字,除非原始檔指向輸出過
Spring(概念篇):Spring、SpringMVC、SpringBoot以及SpringCloud的概念、關係與區別(詳解)
Spring與Spring MVC Spring Spring是一個一站式的輕量級的Java開發框架 Spring是一個一站式的輕量級的Java開發框架,核心是控制反轉(IOC)和麵向切面(AOP),針對於開發的WEB層(SpringMVC)、業務層(IOC)、持久層(jdbc Te
常量指標與指標常量的區別(轉帖)
三個名詞雖然非常繞嘴,不過說的非常準確。用中國話的語義分析就可以很方便地把三個概念區分開。 一) 常量指標。 常量是形容詞,指標是名詞,以指標為中心的一個偏正結構短語。這樣看,常量指標本質是指標,常量修飾它,表示這個指標乃是一個指向常量的指標(變數)。 指標指向的物件是常量,那麼這個物件
Java 覆寫和過載定義與區別 (面試題)
覆寫和過載 方法的覆蓋(Overriding)和過載(Overloading)是Java多型性的不同表現。覆蓋(也可以叫重寫,覆寫)是父類與子類之間多型性的一種表現,而過載是一個類中多型性的一種表現。 (一)覆寫: 1.方法的覆寫(****重點,Java核心) 定義:子類定義
gonna,gotta,wanna的區別(參考牛津)
1.原型 gonna的原型是going to gotta的原型是(have) got to wanna的原型是want to 2.意義 gonna表示“將要”的意思 gotta表示“必須”、“要”等意思 wanna表示“想要做某事”的意思 3.用法 gonna前面