
大資料案例——Hive、MySQL、HBase資料互導
一、Hive預操作
1、建立臨時表user_action
hive> create table dblab.user_action(id STRING,uid STRING, item_id STRING, behavior_type STRING, item_category STRING, date DATE, province STRING) COMMENT 'Welcome to xmu dblab! ' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;2、將small_user表中的資料插入到user_action(執行時間:10秒左右)
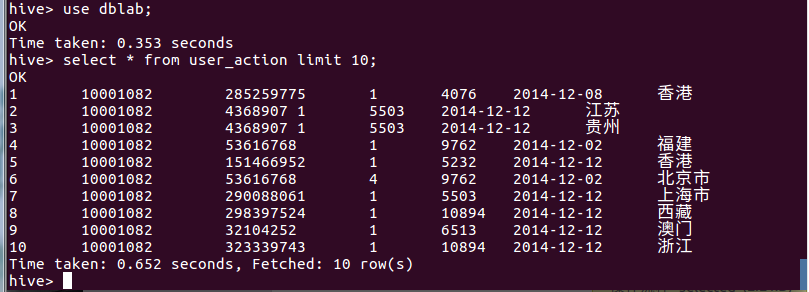
hive> INSERT OVERWRITE TABLE dblab.user_action select * from dblab.small_user;查詢命令是否成功插入。select * from user_action limit 10;
二、使用Sqoop將資料從Hive匯入MySQL
1、啟動hadoop叢集、MySQL服務
start-all.sh
service mysql start2、將前面生成的臨時表資料從 HDFS 匯入到 MySQL 中,步驟如下:(1)~(4)操作都是在 MySQL 互動客戶端執行。
(1)登入 MySQL,回車並輸入密碼
mysql –u hive –p (2)建立資料庫
mysql> show databases; #顯示所有資料庫
mysql> create database dblab; #建立dblab資料庫
mysql> use dblab; #使用資料庫注意:檢視資料庫的編碼show variables like "char%";,請確認當前編碼為utf8,否則無法匯入中文,請參考Ubuntu安裝MySQL及常用操作修改編碼。
(3)建立表,並設定其編碼為utf-8
mysql> CREATE TABLE `dblab`.`user_action` 提示:語句中的引號是反引號`,不是單引號’。
建立成功後,退出 MySQL。
(4)匯入資料(執行時間:20秒左右)
cd /usr/local/sqoop #進入 sqoop 安裝主目錄
bin/sqoop export --connect jdbc:mysql://localhost:3306/dblab --username hive --password hive --table user_action --export-dir '/user/hive/warehouse/dblab.db/user_action' --fields-terminated-by '\t'; #匯入命令注意:IP 部分需要使用 HadoopMaster 節點對應的 IP 地址。
欄位解釋:
bin/sqoop export ##表示資料從 hive 複製到 mysql 中
--connect jdbc:mysql://localhost:3306/dblab
--username hive #mysql登陸使用者名稱
--password hive #登入密碼
--table user_action #mysql 中的表,即將被匯入的表名稱
--export-dir '/user/hive/warehouse/dblab.db/user_action ' #hive 中被匯出的檔案
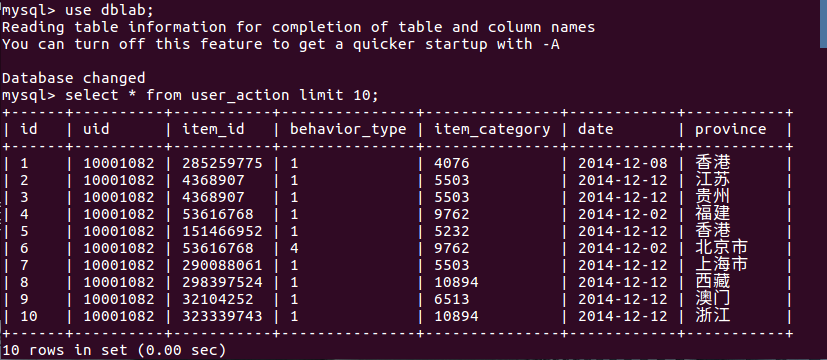
--fields-terminated-by '\t' #hive 中被匯出的檔案欄位的分隔符3、檢視MySQL中user_action表資料。
三、使用Sqoop將資料從MySQL匯入HBase
1、啟動hadoop叢集、MySQL服務、HBase服務
start-all.sh
service mysql start
start-hbase.sh2、登陸HBase shell
hbase shell3、建立表user_action
hbase> create 'user_action', { NAME => 'f1', VERSIONS => 5}4、匯入資料(執行時間:30秒左右)
sqoop import --connect jdbc:mysql://localhost:3306/dblab --username hive --password hive --table user_action --hbase-table user_action --column-family f1 --hbase-row-key id --hbase-create-table -m 1注意:IP部分改為本機IP地址或localhost。同時,HBase只支援十六進位制儲存中文。
欄位解釋:
bin/sqoop import --connect jdbc:mysql://localhost:3306/dblab
--username hive
--password hive
--table user_action
--hbase-table user_action #HBase中表名稱
--column-family f1 #列簇名稱
--hbase-row-key id #HBase 行鍵
--hbase-create-table #是否在不存在情況下建立表
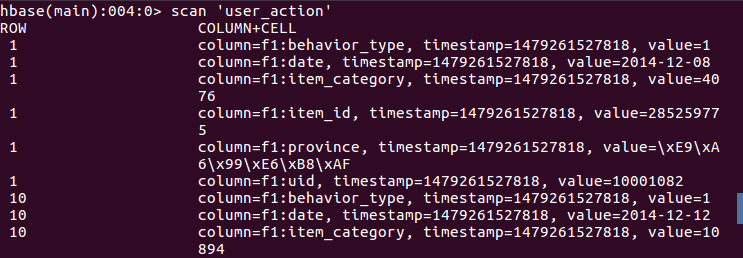
-m 1 #啟動 Map 數量5、檢視HBase中user_action表資料
四、HBase Java API訪問統計資料
1、啟動hadoop叢集、HBase服務
start-all.sh
start-hbase.sh2、資料準備
將之前的 user_action 資料從 HDFS 複製到本地。
cd ~/dblab
hdfs dfs -get /user/hive/warehouse/dblab.db/user_action . #將HDFS上的user_action資料複製到本地當前目前,注意'.'表示當前目錄
cd user_action
cat 00000* > user_action.output #將00000*檔案複製一份重新命名為user_action.output,*表示萬用字元
head user_action.output #檢視user_action.output前10行3、Eclipse編寫ImportHBase程式,並打包成可執行jar包,命名為ImportHBase.jar,儲存至~/dblab/。java程式碼附在文末。
4、資料匯入(執行時間:2分鐘左右)
使用 Java 程式將資料從本地匯入 HBase 中,匯入前請先清空user_action表truncate 'user_action':
hadoop jar ~/dblab/ImportHBase.jar com.dblab.hbase.HBaseImportTest /home/dblab/dblab/user_action/user_action.output欄位解釋:
hadoop jar #hadoop jar包執行方式
~/ImportHBase.jar #jar包的路徑
com.dblab.hbase.HBaseImportTest #主函式入口
/home/dblab/dblab/user_action/user_action.output #main方法接收的引數args5、檢視HBase中user_action表資料
附錄:ImportHBase.java
package com.dblab.hbase;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseImportTest extends Thread {
public Configuration config;
public HTable table;
public HBaseAdmin admin;
public HBaseImportTest() {
config = HBaseConfiguration.create();
// config.set("hbase.master", "master:60000");
// config.set("hbase.zookeeper.quorum", "master");
try {
table = new HTable(config, Bytes.toBytes("user_action"));
admin = new HBaseAdmin(config);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) { //第一個引數是該jar所使用的類,第二個引數是路徑
throw new Exception("You must set input path!");
}
String fileName = args[args.length-1]; //輸入的檔案路徑是最後一個引數
HBaseImportTest test = new HBaseImportTest();
test.importLocalFileToHBase(fileName);
}
public void importLocalFileToHBase(String fileName) {
long st = System.currentTimeMillis();
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(
fileName)));
String line = null;
int count = 0;
while ((line = br.readLine()) != null) {
count++;
put(line);
if (count % 10000 == 0)
System.out.println(count);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
table.flushCommits();
table.close(); // must close the client
} catch (IOException e) {
e.printStackTrace();
}
}
long en2 = System.currentTimeMillis();
System.out.println("Total Time: " + (en2 - st) + " ms");
}
@SuppressWarnings("deprecation")
public void put(String line) throws IOException {
String[] arr = line.split("\t", -1);
String[] column = {"id","uid","item_id","behavior_type","item_category","date","province"};
if (arr.length == 7) {
Put put = new Put(Bytes.toBytes(arr[0]));// rowkey
for(int i=1;i<arr.length;i++){
put.add(Bytes.toBytes("f1"), Bytes.toBytes(column[i]),Bytes.toBytes(arr[i]));
}
table.put(put); // put to server
}
}
public void get(String rowkey, String columnFamily, String column,
int versions) throws IOException {
long st = System.currentTimeMillis();
Get get = new Get(Bytes.toBytes(rowkey));
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
Scan scanner = new Scan(get);
scanner.setMaxVersions(versions);
ResultScanner rsScanner = table.getScanner(scanner);
for (Result result : rsScanner) {
final List<KeyValue> list = result.list();
for (final KeyValue kv : list) {
System.out.println(Bytes.toStringBinary(kv.getValue()) + "\t"
+ kv.getTimestamp()); // mid + time
}
}
rsScanner.close();
long en2 = System.currentTimeMillis();
System.out.println("Total Time: " + (en2 - st) + " ms");
}
}相關推薦
使用DataX將Hive與MySQL中的表互導
DataX DataX 是阿里巴巴集團內被廣泛使用的離線資料同步工具/平臺,實現包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(
大資料案例——Hive、MySQL、HBase資料互導
一、Hive預操作 1、建立臨時表user_action hive> create table dblab.user_action(id STRING,uid STRING, item_id STRING, behavior_type ST
用Hive、Impala查詢Hbase資料
近期有專案需要向Hbase寫入資料,為了測試資料寫入是否正常,常用Hbase shell查詢資料,但是用起來比較麻煩,看到Clouder官網有關於使用Impala查詢Hbase的操作說明,做了簡單的嘗試,記錄如下,供大家參考。 環境: CDH 5.10.2、Impala
2、mysql的一般資料型別
int:整形 double/float:浮點型 char:char(10) 固定長度字元竄 Varchar:varchar(10) 可變長度字元竄 text:大文字型別 blob:位元組型別,多用於儲存圖片 date:日期格式,為yyy-MM-dd time:時間型別,格
從零開始學視覺化資料分析師就業課程(Excel、 MySQL、Power BI、Tableau、python、R)
課程目錄: 第1章: 資料分析師先導篇 任務1: 資料分析的概念 任務2: 資料分析的作用 任務3: 資料分析六部曲 任務4: 資料分析六部曲2 任務5: 資料分析的三大誤區 任務6: 資料分析師的發展和職業要求 任務7: 資料分析師的基本素質 第2章: Ex
《MySQL必知必會》學習筆記(三)、MySQL中的資料運算
本文主要介紹MySQL中的算術運算、常用的資料處理函式和聚集函式。 利用的資料表均來自《MySQL必知必會》中提供的資料表。 1、MySQL中的算術運算 MySQL中的算術操作符主要有加(+)減(-)乘(*)除(/)四種。 舉例如下: SELE
《MySQL必知必會》學習筆記(二)、MySQL資料庫中資料的檢索與搜尋
一、對檢索結果排序 1.1 簡單排序 在MySQL中使用ORDER BY子句對檢索出的資料進行排序,而且預設為遞增排序。若想以遞減方式排序,需要在排列資料後面加上DESC關鍵字。利用《MySQL必知必會》中的資料表,實驗如下: SELE
HBase、MongoDB、MySQL、Oracle、Redis--nosql資料庫與關係資料庫對比
HBase vs. MongoDB vs. MySQL vs. Oracle vs. Redis,三大主流開源 NoSQL 資料庫的 PK 兩大主流傳統 SQL 資料庫 類別 HBase MongoDB MySQL Oracle Redis 描述 基於 Ap
利用Flume將MySQL表資料準實時抽取到HDFS、MySQL、Kafka
軟體版本號 jdk1.8、apache-flume-1.6.0-bin、kafka_2.8.0-0.8.0、zookeeper-3.4.5叢集環境安裝請先測試; 參考以下作者資訊,特此感謝;http://blog.csdn.net/wzy0623/article/detail
scrapy爬取資料儲存csv、mysql、mongodb、json
目錄 前言 Items Pipelines 前言 用Scrapy進行資料的儲存進行一個常用的方法進行解析 Items item 是我們儲存資料的容器,其類似於 python 中的字典。使用 item 的好處在於: Item 提供了額外保護機制來避免拼寫錯誤導致
wampServer(windows、apache、mysql、php)
list mysql 配置 allow error del 默認 virtual listen wampServer(windows/apche/mysql/php)集成環境 在線狀態:區域網內可以訪問 離線狀態:本地設備可以訪問 自擬定網站根目錄: Apache -- h
Ubuntu搭建 Apache、MySQL、PHP環境
分享 管理員 mysq ima 表示 ubunt ets .cn image 以Ubuntu 16.04為例: 1、安裝MysSQL 打開命令行輸入 :sudo apt-get install mysql-server 輸入管理員密碼 選擇Y 在安裝的中間會出現輸
05006_Linux的jdk、mysql、tomcat安裝
命令 fig ref 不支持 啟動 軟件包 默認 mysql 文件 1、軟件包下載鏈接:軟件包下載 密碼:advk 2、安裝JDK (1)查看當前Linux系統是否已經安裝java,輸入 rpm -qa | grep java ; (2)卸載兩個openJDK
Sqlserver、Mysql、Oracle各自的默認端口號
edr drive mic odin word host base nco mysql mysql 默認端口號為:3306URL:jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=
centos7重啟apache、nginx、mysql、php-fpm命令
httpd stop 啟動 sta fpm start res gin SQ apache 啟動 systemctl start httpd 停止 systemctl stop httpd 重啟 systemctl restart httpd mysql 啟動 system
查看Linux 、Nginx、 MySQL 、 PHP 版本的方法
style tps HR version light gda targe true pac 參考:查看Linux 、Apache 、 MySQL 、 PHP 版本的方法 1.查看Linux版本: uname -a; more /etc/issue; cat /proc/ve
Spring配置JDBC連接Orcale、MySql、sqlserver
使用 SQ pos pri pre ace apache 數據源 value 閱讀指南:本文章主要講述如何在Spring框架中配置JDBC連接方式連接Oracle、Mysql、SqlServer。 原理如下: 一、導包 連接oracle11g所需的jar包:ojdbc6.j
KVM虛擬化、MySQL、Nginx、RabbitMQ、Redis組件安裝指導
mysql字符集 eas www cat listen copy 測試 arc remove 1 檢查服務器的配置信息 1.1 檢查服務器的CPU信息 [root@localhost iso]#cat /proc/cpuinfo | grep na
Linux安裝java jdk、mysql、tomcat
ref app 1.0 重置密碼 esc 啟動mysql TP mar des 安裝javajdk 1.8 檢查是否安裝 rpm -qa | grep jdk rpm方式安裝 下載java1.8 jdk http://download.oracle.com/otn-pub/
LAMP架構介紹、MySQL、MariaDB介紹、MySQL安裝
LinuxLAMP架構介紹 LAMP是一個簡寫,包含了4個東西:linux、apache(httpd)、mysql、php linux操作系統、apache提供wb服務的軟件、mysql存儲數據的軟件、php腳本語言 LAMP的工作原理 瀏覽器向服務器發送http請求,服務器 (Apache) 接受請求,由