
python3爬蟲(二)-使用beautiful soup 讀取網頁
Beautiful Soup簡介
簡單來說,Beautiful Soup是python的一個庫,最主要的功能是從網頁抓取資料。官方解釋如下:
Beautiful Soup提供一些簡單的、python式的函式用來處理導航、搜尋、修改分析樹等功能。它是一個工具箱,通過解析文件為使用者提供需要抓取的資料,因為簡單,所以不需要多少程式碼就可以寫出一個完整的應用程式。
Beautiful Soup自動將輸入文件轉換為Unicode編碼,輸出文件轉換為utf-8編碼。你不需要考慮編碼方式,除非文件沒有指定一個編碼方式,這時,Beautiful Soup就不能自動識別編碼方式了。然後,你僅僅需要說明一下原始編碼方式就可以了。
Beautiful Soup已成為和lxml、html6lib一樣出色的python直譯器,為使用者靈活地提供不同的解析策略或強勁的速度。
Beautiful Soup四大物件
Beautiful Soup將複雜HTML文件轉換成一個複雜的樹形結構,每個節點都是Python物件,所有物件可以歸納為4種:
Tag
NavigableString
BeautifulSoup
Comment
建立Beautiful Soup物件
from bs4 import BeautifulSoup
from urllib import request
html = request.urlopen("https://movie.douban.com/" - Tag
Tag通俗點講就是HTML中的一個個標籤,下面我們來感受一下怎樣用 Beautiful Soup 來方便地獲取 Tags。
我們可以利用 soup加標籤名輕鬆地獲取這些標籤的內容,是不是感覺比正則表示式方便多了?不過有一點是,它查詢的是在所有內容中的第一個符合要求的標籤
print(bs.title)<title>
豆瓣電影
</title>print(bs.head)只寫一部分返回
<head print(bs.a)
#<a class="nav-login" href="https://www.douban.com/accounts/login?source=movie" rel="nofollow">登入</a>
print(bs.p)
<p class="appintro-title">豆瓣</p>對於Tag,有兩個重要的屬性:name和attr
name
soup 物件本身比較特殊,它的 name 即為 [document],對於其他內部標籤,輸出的值便為標籤本身的名稱。
print(bs.name)
print(bs.title.name)
#[document]
#titleattrs
print(bs.a.attrs)
{'class': ['nav-login'], 'href': 'https://www.douban.com/accounts/login?source=movie', 'rel': ['nofollow']}在這裡,我們把 a 標籤的所有屬性列印輸出了出來,得到的型別是一個字典。
如果我們想要單獨獲取某個屬性,可以這樣,例如我們獲取a標籤的class叫什麼,兩個等價的方法如下:
print(bs.a['class'])
print(bs.a.get('class'))
['nav-login']- NavigableString
既然我們已經得到了標籤的內容,那麼問題來了,我們要想獲取標籤內部的文字怎麼辦呢?很簡單,用 .string 即可,例如
print(bs.a.string)
登入BeautifulSoup
BeautifulSoup 物件表示的是一個文件的全部內容.大部分時候,可以把它當作 Tag 物件,是一個特殊的 Tag,我們可以分別獲取它的型別,名稱,以及屬性
Comment
Comment物件是一個特殊型別的NavigableString物件,其實輸出的內容仍然不包括註釋符號,但是如果不好好處理它,可能會對我們的文字處理造成意想不到的麻煩。
from bs4 import element
if type(soup.li.string) == element.Comment:
print(soup.li.string)上面的程式碼中,我們首先判斷了它的型別,是否為 Comment 型別,然後再進行其他操作,如列印輸出。
遍歷文件數
- 直接子節點(不包含孫節點)
contents:
tag的content屬性可以將tag的子節點以列表的方式輸出:
輸出方式為列表,我們可以用列表索引來獲取它的某一個元素:

print(bs.body.contents[1])
#<script type="text/javascript">var _body_start = new Date();</script>children
它返回的不是一個 list,不過我們可以通過遍歷獲取所有子節點,它是一個 list 生成器物件:

利用列表解析

- 搜尋文件樹
find_all(name, attrs, recursive, text, limit, **kwargs):find_all() 方法搜尋當前tag的所有tag子節點,並判斷是否符合過濾器的條件。
1) name引數:
name 引數可以查詢所有名字為 name 的tag,字串物件會被自動忽略掉。
傳遞字元:
最簡單的過濾器是字串,在搜尋方法中傳入一個字串引數,Beautiful Soup會查詢與字串完整匹配的內容,下面的例子用於查詢文件中所有的標籤:

傳遞正則表示式:
如果傳入正則表示式作為引數,Beautiful Soup會通過正則表示式的 match() 來匹配內容.下面例子中找出所有以b開頭的標籤,這表示body和b標籤都應該被找到

傳遞列表:
如果傳入列表引數,Beautiful Soup會將與列表中任一元素匹配的內容返回,下面程式碼找到文件中所有title標籤和b標籤:
print(bs.find_all(['title','b']))
[<title>
豆瓣電影
</title>]傳遞True:
True 可以匹配任何值,下面程式碼查詢到所有的tag,但是不會返回字串節點:
for tag in bs.find_all(True):
print(tag.name)

上述圖片均只取一部分
2)attrs引數
我們可以通過 find_all() 方法的 attrs 引數定義一個字典引數來搜尋包含特殊屬性的tag。
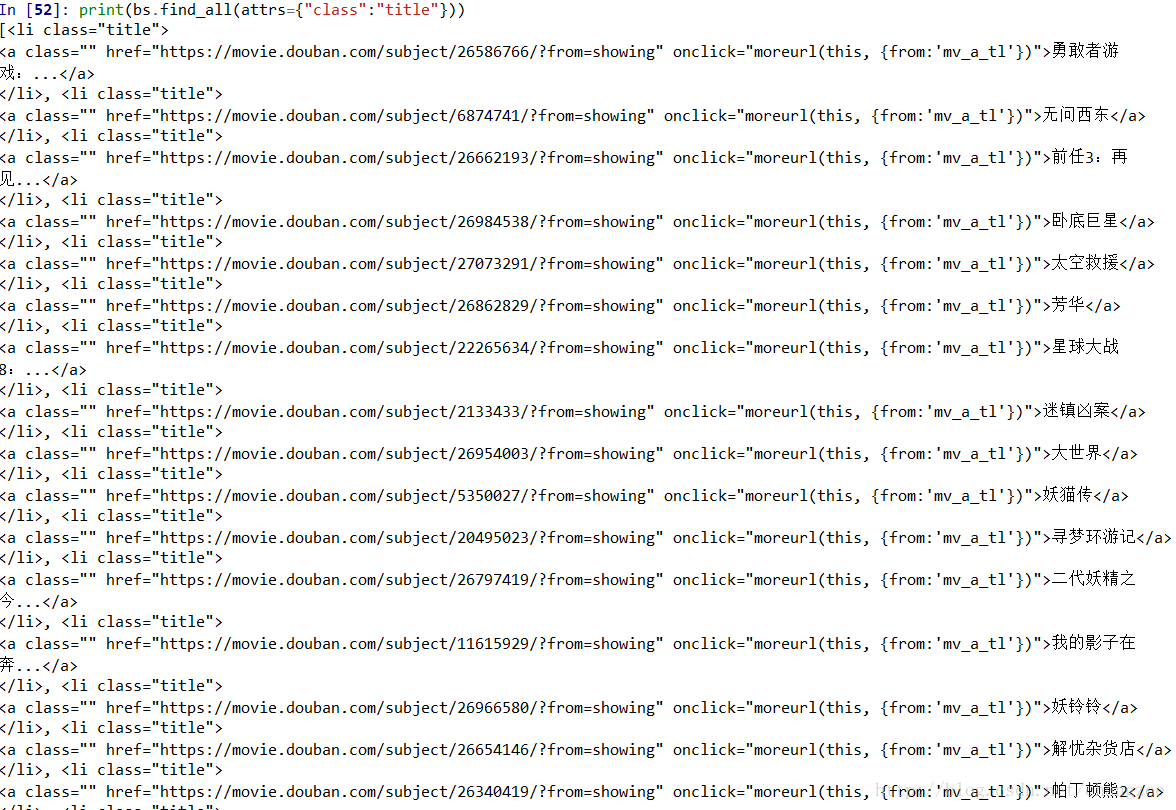
print(bs.find_all(attrs={"class":"title"}))
3)recursive引數
呼叫tag的 find_all() 方法時,Beautiful Soup會檢索當前tag的所有子孫節點,如果只想搜尋tag的直接子節點,可以使用引數 recursive=False。
4)text引數
通過 text 引數可以搜搜文件中的字串內容,與 name 引數的可選值一樣, text 引數接受字串 , 正則表示式 , 列表, True
print(bs.find_all(text="機器之血"))
['機器之血']5)limit引數
find_all() 方法返回全部的搜尋結構,如果文件樹很大那麼搜尋會很慢.如果我們不需要全部結果,可以使用 limit 引數限制返回結果的數量.效果與SQL中的limit關鍵字類似,當搜尋到的結果數量達到 limit 的限制時,就停止搜尋返回結果。
print(bs.find_all('a',limit=5))
[<a class="nav-login" href="https://www.douban.com/accounts/login?source=movie" rel="nofollow">登入</a>, <a class="nav-register" href="https://www.douban.com/accounts/register?source=movie" rel="nofollow">註冊</a>, <a class="lnk-doubanapp" href="https://www.douban.com/doubanapp/app?channel=top-nav">下載豆瓣客戶端</a>, <a href="https://www.douban.com/doubanapp/redirect?channel=top-nav&direct_dl=1&download=iOS">iPhone</a>, <a class="download-android" href="https://www.douban.com/doubanapp/redirect?channel=top-nav&direct_dl=1&download=Android">Android</a>]結果只返回了5個,因為我們限制了返回數量:
- 6)kwargs引數
如果傳入 class 引數,Beautiful Soup 會搜尋每個 class 屬性為 title 的 tag 。kwargs 接收字串,正則表示式

基於bs4庫的HTML內容遍歷方法
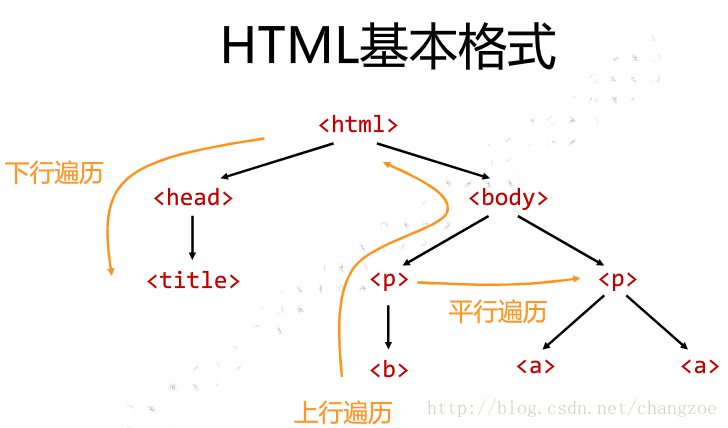
平行遍歷
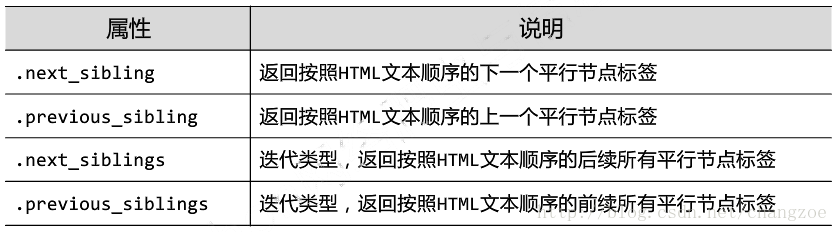
上行遍歷

下行遍歷

由find_all()擴充套件的七個方法
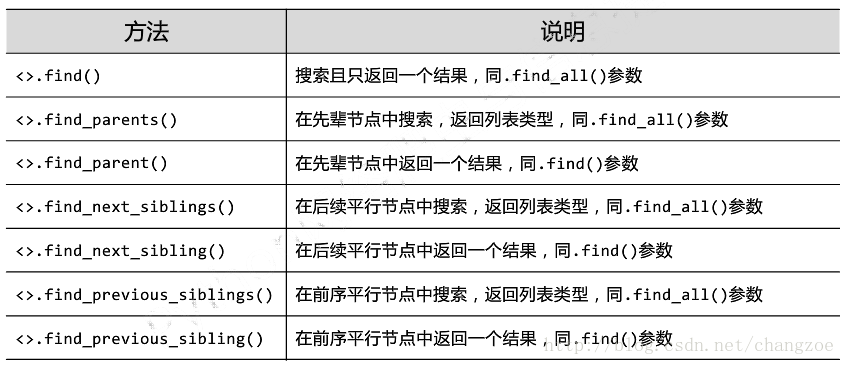
#傳遞一個ID,定位到導航欄
rev_bar = bs.find(id="reviews")
#遍歷導航欄的後繼
for d in rev_bar.descendants:
print(d)
#到導航欄的最後一個後繼,使用.previous_siblings來遍歷導航元素的鄰居
for s in d.previous_siblings:
print(s)
參考文件
相關推薦
python3爬蟲(二)-使用beautiful soup 讀取網頁
Beautiful Soup簡介 簡單來說,Beautiful Soup是python的一個庫,最主要的功能是從網頁抓取資料。官方解釋如下: Beautiful Soup提供一些簡單的、python式的函式用來處理導航、搜尋、修改分析樹等功能。它是一個工
爬蟲學習筆記(五) Beautiful Soup使用
內容 BE 是否 ini n-n 修改 過濾 性能測試 刪除 上篇博客說了正則表達式,但是正則學起來比較費勁,寫的時候也不好寫,這次說下Beautiful Soup怎麽用,這個模塊是用來解析html的,它操作很簡單,用起來比較方便,比正則學習起來簡單多了。 這是第三方模塊需
Python3使用selenium庫簡單爬蟲(二)
使用selenium爬取豆瓣圖書top250書籍資訊 1、上一篇文章Python3使用selenium庫簡單爬蟲(一)通過元素的id、name、class_name定位元素,這次使用xpath定位元素 (1)使用xpath定位元素的幾種表示方法: * 匹
Python3.7 爬蟲(二)使用 Urllib2 與 BeautifulSoup4 抓取解析網頁
開篇 上一篇中我們通過原生的 re 模組已經完成了網頁的解析,對於熟悉正則表示式的童鞋來說很好上手,但是對於萌新來說,還是有一定難度以及複雜度的,那麼這裡我們就來使用第三方解析包來解析獲取到的網頁吧。 BeautifulSoup 官方的 Beaut
Python開發簡單爬蟲(二)---爬取百度百科頁面數據
class 實例 實例代碼 編碼 mat 分享 aik logs title 一、開發爬蟲的步驟 1.確定目標抓取策略: 打開目標頁面,通過右鍵審查元素確定網頁的url格式、數據格式、和網頁編碼形式。 ①先看url的格式, F12觀察一下鏈接的形式;② 再看目標文本信息的
Python3安裝(二)
python安裝 amd64 10.8 官方 解釋器 .py 環境變量 能夠 windows 因為Python是跨平臺的,它可以運行在Windows、Mac和各種Linux/Unix系統上。在Windows上寫Python程序,放到Linux上也是能夠運行的。 要開始學習P
Python學習之路 (三)爬蟲(二)
版權 特殊 機器人 zhang col 取出 log arch robots 通用爬蟲和聚焦爬蟲 根據使用場景,網絡爬蟲可分為 通用爬蟲 和 聚焦爬蟲 兩種. 通用爬蟲 通用網絡爬蟲 是 捜索引擎抓取系統(Baidu、Google、Yahoo等)的重要組成部分。主要目
爬蟲(二):Urllib庫詳解
lib lwp ces lin 設置 內置 col http測試 url 什麽是Urllib: python內置的HTTP請求庫 urllib.request : 請求模塊 urllib.error : 異常處理模塊 urllib.parse: url解析模塊 urllib
Python爬蟲(二)網絡爬蟲的尺寸與約束
.cn 哪些 com 尺寸 網頁 inf robot robots 搜索 Infi-chu: http://www.cnblogs.com/Infi-chu/ 一、網絡爬蟲的尺寸: 1.小規模,數據量小,爬取速度不敏感,Requests庫,爬取網頁 2.中規模,數據
Python3爬蟲(四)請求庫的使用requests
with open decode python3 url -c highlight pos pen req Infi-chu: http://www.cnblogs.com/Infi-chu/ 一、基本用法: 1. 安裝: pip install requests 2
Python3爬蟲(八) 數據存儲之TXT、JSON、CSV
-c pytho IT light json read 信息 不包含 exc Infi-chu: http://www.cnblogs.com/Infi-chu/ TXT文本存儲 TXT文本存儲,方便,簡單,幾乎適用於任何平臺。但是不利於檢索。 1.舉例: 使用reque
Python3爬蟲(九) 數據存儲之關系型數據庫MySQL
如果 except ror 故障 cit -c sqlit 鏈接庫 port Infi-chu: http://www.cnblogs.com/Infi-chu/ 關系型數據庫關系型數據庫是基於關系模型的數據庫,而關系模型是通過二維表來保存的,所以關系型數據庫的存儲方式就
基於C#.NET的高端智能化網絡爬蟲(二)(攻破攜程網)
nbsp net article 智能 tail 攜程網 .net 網絡爬蟲 準備工作 轉:https://www.toutiao.com/i6304492725462893058/ https://blog.csdn.net/hjkl950217/article/det
Python從零開始寫爬蟲(二)BeautifulSoup庫使用
Beautiful Soup 是一個可以從HTML或XML檔案中提取資料的Python庫, BeautifulSoup在解析的時候是依賴於解析器的,它除了支援Python標準庫中的HTML解析器,還支援一些第三方的解析器比如lxml等。可以從其官網得到更詳細的資訊:http://beau
爬蟲(二):Lucene
搜尋引擎: * 什麼是搜尋引擎 * 搜尋引擎基本執行原理 * 原始資料庫做搜尋有什麼弊端 * 倒排索引(敲黑板) lucene lucene相關的概念 lucene和solr的關係 lucene入門程式(寫入索引的操作程式碼)
自學Python爬蟲(二)Requests庫的使用
前言 Urllib和requests庫都是python3中傳送請求的庫,但是比較而言,Requests庫更加強大和易用,所以學習python3就不要學習urllib了,2020年python2的庫就不再更新,所以我們學習python3更有意義! 例項引入 import requ
爬蟲(二)
scrapy 一.什麼是Scrapy? Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架,非常出名,非常強悍。所謂的框架就是一個已經被集成了各種功能(高效能非同步下載,佇列,分散式,解析,持久化等)的具有很強通用性的專案模板。對於框架的學習,重點是要學習其
Python爬蟲(二):爬蟲獲取資料儲存到檔案
接上一篇文章:Python爬蟲(一):編寫簡單爬蟲之新手入門 前言: 上一篇文章,我爬取到了豆瓣官網的頁面程式碼,我在想怎樣讓爬取到的頁面顯示出來呀,爬到的資料是html頁面程式碼,不如將爬取到的程式碼儲存到一個檔案中,檔案命名為html格式,那直接開啟這個檔案就可以在瀏覽器上看到爬取資料的
python3教程(二):下載安裝python
python程式碼可以在任意系統上執行,mac、windows、linux都可以。 因為某些原因(qiong),所以沒有用過mac,但是記得mac應該是自帶python的,如果是2.x版本則下載個3.7版本即可。 如果你是linux使用者,linux上也是自帶python,直接輸入pyt
python爬蟲(二)----正則表示式
正則表示式 本部落格主要講正則表示式在爬蟲網頁解析中的作用 需要的是python的re模組 python版本:3.x (一) 正則表示式的基本知識 1 匹配字元 常見匹配模式—匹配字元 模式 描述