
flume +kafka+SparkStreaming日誌監控平臺
流程圖
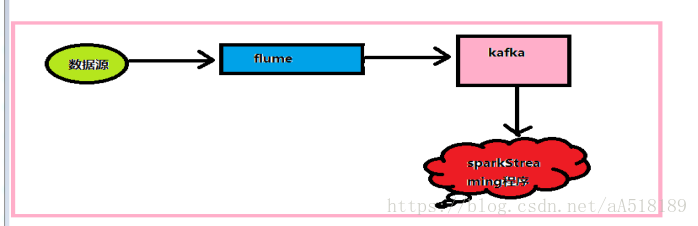
採集方案
#agentsection producer.sources= s1 producer.channels= c1 producer.sinks= k1 #配置資料來源 producer.sources.s1.type=exec #配置需要監控的日誌輸出檔案或目錄 producer.sources.s1.command=tail -F -n+1 /root/a.log #配置資料通道 producer.channels.c1.type=memory producer.channels.c1.capacity=10000 producer.channels.c1.transactionCapacity=100 #配置資料來源輸出 #設定Kafka接收器,此處最坑,注意版本,此處為Flume 1.6.0的輸出槽型別 producer.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink #設定Kafka的broker地址和埠號 producer.sinks.k1.brokerList=192.168.204.10:9092 #設定Kafka的Topic producer.sinks.k1.topic=test #設定序列化方式 producer.sinks.k1.serializer.class=kafka.serializer.StringEncoder #將三者級聯 producer.sources.s1.channels=c1 |
啟動kafka和zk和flume
建立消費者
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
啟動flume
bin/flume-ng agent -n producer -c conf -f conf/myconf.conf -Dflume.root.logger=INFO,console
向flume採集的目標檔案傳送資料:
While true;do echo "我愛你" >> a.log ;sleep 0.5 done;
sparkstreaming消費資料:
packagespark_kafka import org.apache.spark.streaming._ import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe object Kafka_consumer { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("kafka_wordcount").setMaster("local[*]") val ssc = new StreamingContext(conf,Seconds(2)) val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "wangzhihua1:9092,wangzhihua2:9092,wangzhua3:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "use_a_separate_group_id_for_each_stream", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) val messages: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, PreferConsistent, Subscribe[String, String](Array("test"), kafkaParams) ) val rs: DStream[(String, Int)] = messages.map(t => { (t.value(), 1) }) val fianlRs= rs.reduceByKey(_+_) fianlRs.print() ssc.start() ssc.awaitTermination() } }
相關推薦
flume +kafka+SparkStreaming日誌監控平臺
流程圖 採集方案#agentsectionproducer.sources= s1producer.channels= c1producer.sinks= k1#配置資料來源producer.sourc
Flume+Kafka+Sparkstreaming日誌分析
最近要做一個日誌實時分析的應用,採用了flume+kafka+sparkstreaming框架,先搞了一個測試Demo,本文沒有分析其架構原理。 簡介:flume是一個分散式,高可靠,可用的海量日誌聚合系統,kafka是一高吞吐量的分散式釋出訂閱系統,s
日誌監控平臺搭建 關於flume Kafka Elk
最近需要搭建一套日誌監控平臺,參考了新浪與美團的一些東西.現在實錄一下搭建與優化調整的過程 目前把這幾件放在一起的文件還不夠多,其中相當一部分因為elk的升級配置也已經不能用了,更多的是單機版的配置,完全沒有參考性. 優化的部分將等待專案與新平臺正式上線在另一篇文章
SparkStreaming(14):log4j日誌-flume-kafka-SparkStreaming的整合
一、功能實現 模擬log4j的日誌生產,將日誌輸出到flume伺服器。然後,通過flume將日誌資訊輸出到kafka,進而Streaming可以從kafka獲得日誌,並且進行簡單的處理。 二、步驟 1.目的: 使用log4j將日誌輸按照一定格式輸出,並且傳遞給flume伺服器特定埠接
使用Flume+Kafka+SparkStreaming進行實時日誌分析
每個公司想要進行資料分析或資料探勘,收集日誌、ETL都是第一步的,今天就講一下如何實時地(準實時,每分鐘分析一次)收集日誌,處理日誌,把處理後的記錄存入Hive中,並附上完整實戰程式碼 1. 整體架構 思考一下,正常情況下我們會如何收集並分析日誌呢?
ELK日誌監控平臺
elasticsearch分布環境的搭 logstash基本應用和實戰 Redis+EL應用 ELK 應用 一 elk 開源日誌分析平臺介紹 1 介紹 elasticsearch 是一個開源分布式搜索引擎,它的特點是:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格接口
Flume+Kafka+SparkStreaming+Hbase+可視化(一)
日誌導入 ash channels style 導入 com system ase spark 一、前置準備: Linux命令基礎 Scala、Python其中一門 Hadoop、Spark、Flume、Kafka、Hbase基礎知識 二、分布式日誌收集框架Flume
基於flume+kafka+storm日誌收集系統搭建
基於flume+kafka+storm日誌收集系統搭建 1. 環境 192.168.0.2 hadoop1 192.168.0.3 hadoop2 192.168.0.4 hadoop3 已經
Flume+Kafka+SparkStreaming整合
目錄 1. Flume介紹 Flume是Cloudera提供的一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的日誌收集系統,支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受
ELK 日誌監控平臺環境搭建及使用說明
1. ELK概述 ELK,也就是Elasticsearch、Logstash、Kibana三者的結合,是一套開源的分散式日誌管理方案. Elasticsearch:負責日誌儲存、檢索和分析 LogStash:負責日誌的收集、處理 Kibana:負責日
SpringBoot+Logback+Sentry(日誌監控平臺)
相關地址: 官網:https://getsentry.com/welcome/ github:https://github.com/getsentry/sentry 安裝手冊:https://docs.getsentry.com/hosted/quickstart/
Kafka的web 監控平臺
1. 下載KafkaOffsetMonitor-assembly-0.2.0.jar 2. 建立/data/server/flink-web-monitor目錄,將jar包放在該目錄下,同時建立ka
微服務海量日誌監控平臺
前面幾章蜻蜓點水的介紹了elasticsearch、apm相關的內容。本片主要介紹怎麼使用ELK Stack幫助我們打造一個支撐起日產TB級的日誌監控系統 背景 在企業級的微服務環境中,跑著成百上千個服務都算是比較小的規模了。在生產環境上,日誌扮演著很重要的角色,排查異常需要日誌,效能優化需要日誌,業務排查需
Flume+Kafka雙劍合璧玩轉大資料平臺日誌採集
概述 大資料平臺每天會產生大量的日誌,處理這些日誌需要特定的日誌系統。 一般而言,這些系統需要具有以下特徵: 構建應用系統和分析系統的橋樑,並將它們之間的關聯解耦; 支援近實時的線上分析系統和類似於Hadoop之類的離線分析系統; 具有高可擴充套件性。即:當資料量增加時,可以通過增加節點
基於 Flume+Kafka+Spark Streaming 實現實時監控輸出日誌的報警系統
運用場景:我們機器上每天或者定期都要跑很多工,很多時候任務出現錯誤不能及時發現,導致發現的時候任務已經掛了很久了。 解決方法:基於 Flume+Kafka+Spark Streaming 的框架對這些任務的輸出日誌進行實時監控,當檢測到日誌出現Error的資訊就傳送郵件給
ELK搭建實時日誌分析平臺(elk+kafka+metricbeat)-搭建說明
elk搭建實時日誌分析平臺數據流向:metricbeat->kafka->logstash->elasticsearch->kibana.應用分布:主機應用備註192.168.30.121java version "1.8.0_144"zookeeper-3.4.10.tar.gzka
ELK搭建實時日誌分析平臺(elk+kafka+metricbeat)-KAFKA搭建
kafka搭建(elk+kafka+metricbeat)一、kafka搭建建立elk目錄:mkdir /usr/loca/elk安裝zookeeper:192.168.30.121:192.168.30.122:192.168.30.123:3. kafka安裝: a. 192.168.30.121
ELK實時日誌分析平臺(elk+kafka+metricbeat)-logstash(四)
elk-logstash搭建1. 安裝並測試: 2. 添加配置: 3. 啟動檢查:本文出自 “linux” 博客,請務必保留此出處http://1054054.blog.51cto.com/1044054/1968431ELK實時日誌分析平臺(elk+kafka+metricbeat)-logs
Flume+Kafka+Zookeeper搭建大數據日誌采集框架
flume+kafka+zookeeper1. JDK的安裝 參考jdk的安裝,此處略。2. 安裝Zookeeper 參考我的Zookeeper安裝教程中的“完全分布式”部分。3. 安裝Kafka 參考我的Kafka安裝教程中的“完全分布式搭建”部分。4. 安裝Flume 參考
ELK+Filebeat+Kafka+ZooKeeper 構建海量日誌分析平臺
width 上進 實驗環境 cal host 轉發 lis write oot ELK+Filebeat+Kafka+ZooKeeper 構建海量日誌分析平臺 參考:http://www.tuicool.com/articles/R77fieA 我在做ELK日誌平臺開始之初