
計算機原理(二)
1. 記憶體工作原理
CPU和記憶體是計算機中最重要的兩個元件,前面已經知道了CPU是如何工作的,上一篇也介紹了記憶體採用的DRAM的儲存原理。CPU工作需要知道指令或資料的記憶體地址,那麼這樣一個地址是如何和記憶體這樣一個硬體聯絡起來的呢?現在就看看記憶體到的是怎麼工作的。
1.1 DRAM晶片結構
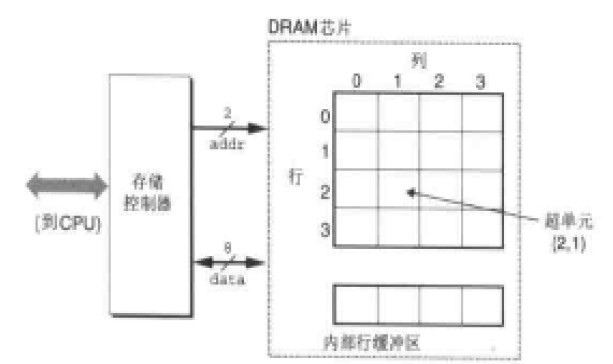
上圖是DRAM晶片一個單元的結構圖。一個單元被分為了N個超單元(可以叫做cell),每個單元由M個DRAM單元組成。我們知道一個DRAM單元可以存放1bit資料, 所以描述一個DRAM晶片可以儲存N*M位資料。上圖就是一個有16個超單元,每個單元8位的儲存模組,我們可以稱為16*8bit 的DRAM晶片。而超單元(2,1)我們可以通過如矩陣的方式訪問,比如 data = DRAM[2.1] 。這樣每個超單元都能有唯一的地址,這也是記憶體地址的基礎。
每個超單元的資訊通過地址線和資料線傳輸查詢和傳輸資料。如上圖有2根地址線和8根資料線連線到儲存控制器(注意這裡的儲存控制器和前面講的北橋的記憶體控制器不是一回事),儲存控制器電路一次可以傳送M位資料到DRAM晶片或從DRAM傳出M位資料。為了讀取或寫入【i,j】超單元的資料,儲存控制器需要通過地址線傳入行地址i 和列地址j。這裡我們把行地址稱為RAS(Row Access Strobe)請求, 列地址稱為(Column Access Strobe)請求。
但是我們發現地址線只有2為,也就是定址空間是0-3。而確定一個超單元至少需要4位地址線,那麼是怎麼實現的呢?
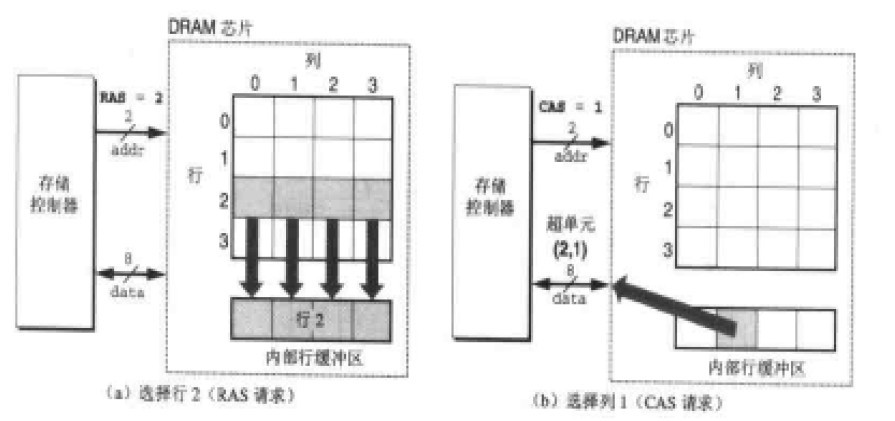
解決這個問題採用的是分時傳送地址碼的方法。看上圖我們可以發現在DRAM晶片內部有一個行緩衝區,實際上獲取一個cell的資料,是傳送了2次資料,第一次傳送RAS,將一行的資料放入行緩衝區,第二期傳送CAS,從行緩衝區中取得資料並通過資料線傳出。這些地址線和資料線在晶片上是以管腳(PIN)與控制電路相連的。將DRAM電路設計成二維矩陣而不是一位線性陣列是為了降低晶片上的管腳數量。入上圖如果使用線性陣列,需要4根地址管腳,而採用二維矩陣並使用RAS\CAS兩次請求的方式只需要2個地址管腳。但這樣的缺點是增加了訪問時間。
1.2 記憶體模組
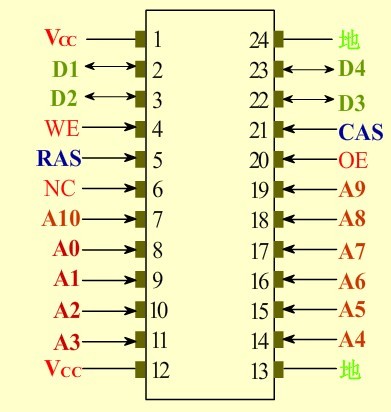
記憶體模組也就是我們常說的記憶體條。我們在購買記憶體是經常會聽到我這個記憶體採用的是什麼顆粒,如下左圖,我們看到記憶體PCB上的一塊塊的就是記憶體顆粒。也就是我們DRAM晶片。通過管腳和PCB連線。不同廠商,不同型別的記憶體可以的大小,管腳,效能,封裝都不一樣,但是原理都是一樣。這裡我們就不展開介紹了。而下有圖展示了一個1M*4bit的DRAM晶片的管腳圖。

對於一個記憶體顆粒來說,它的容量和字長是有限的,所以我們使用記憶體是會把多個顆粒組成記憶體模組來對記憶體進行字長和容量的擴充套件。目前的記憶體一般記憶體條上面會有多顆記憶體顆粒,比如一條64M的記憶體可能是由8個8M*8bit 的SDRAM記憶體顆粒組成。
1.2.1 字長位數擴充套件
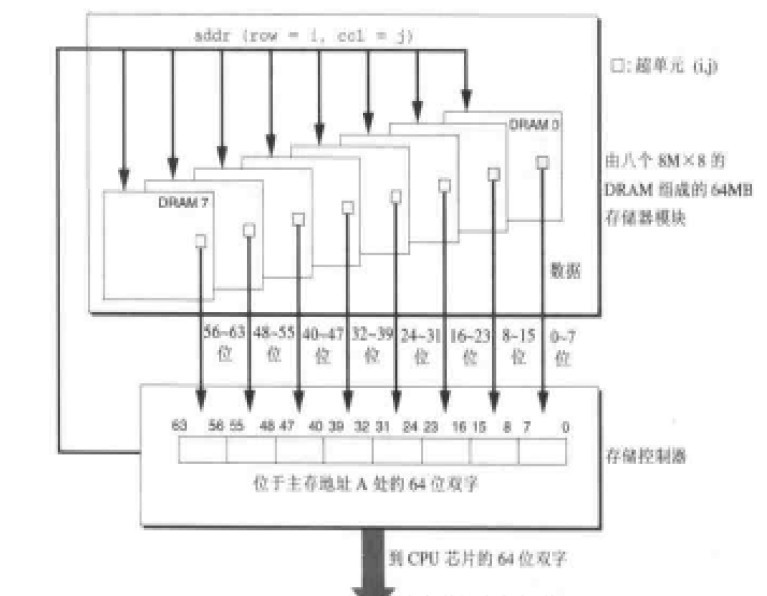
位擴充套件的方法很簡單,只需將多片RAM的相應地址端、讀/寫控制端 和片選訊號CS並接在一起,而各片RAM的I/O端並行輸出即可。 如上圖,我們採用了8個DRAM晶片分,別編號為0-7,每個超單元中儲存8位資料。在獲取add(row=i,col=j)地址的資料的時候,從每個DRAM晶片的【i, j】單元取出一個位元組的資料,這樣傳送到CPU的一共是8*8b = 64b的資料。我們通過8個8M*8b的記憶體顆粒擴充套件為了8M*64b的記憶體模組。
1.2.2 字儲存容量擴充套件
RAM的字擴充套件是利用譯碼器輸出控制各片RAM的片選訊號CS來實現的。RAM進行字擴充套件時必須增加地址線,而增加的地址線作為高位地址與譯碼器的輸入相連。同時各片RAM的相應地址端、讀/寫控制端 、相應I/O端應並接在一起使用。下圖是我們通過4個2M*8b的記憶體顆粒,將記憶體容量擴充套件到了8M,字長為8位。
最後,記憶體通過主機板上的記憶體插槽DIMM和記憶體匯流排相連線。對於不同記憶體比如SDRAM和DDR他們記憶體金手指的定義是不同的。這裡就不需要詳細介紹了。
2. 記憶體編址
前面我們知道了DRAM顆粒以及記憶體模組是如何擴充套件字長和容量的。一個記憶體可能是8位,也可能是64位,容量可能是1M,也可能是1G。那麼記憶體是如何編地的呢?和地址匯流排,計算機字長之間又有什麼關係呢?
2.1 字長
計算機在同一時間內處理的一組二進位制數稱為一個計算機的“字”,而這組二進位制數的位數就是“字長”。。通常稱處理字長為8位資料的CPU叫8位CPU,32位CPU就是在同一時間內處理字長為32位的二進位制資料。 所以這裡的字並不是我們理解的雙位元組(Word)而是和硬體相關的一個概念。一般來說計算機的資料線的位數和字長是相同的。這樣從記憶體獲取資料後,只需要一次就能把資料全部傳送給CPU。
2.2 地址匯流排
前面我們已經介紹過地址匯流排的功能。地址匯流排的數量決定了他最大的定址範圍。就目前來說一般地址匯流排先字長相同。比如32位計算機擁有32為資料線和32為地線,最大定址範圍是4G(0x00000000 ~ 0xFFFFFFFF)。當然也有例外,Intel的8086是16為字長的CPU,採用了16位資料線和20位資料線。
2.3 記憶體編址
從前面我們知道一個記憶體的大小和它晶片擴充套件方式有關。比如我們記憶體模組是採用 16M*8bit的記憶體顆粒,那麼我們使用4個顆粒進行位擴充套件,成為16M*32bit,使用4個顆粒進行字容量擴充套件變為64M*32bit。那麼我們記憶體模組使用了16個記憶體顆粒,實際大小是256MB。
我們需要對這個256M的記憶體進行編址以便CPU能夠使用它,通常我們多種編址方式:
- 按字編址: 對於這個256M記憶體來說,它的定址範圍是64M,而每個記憶體地址可以儲存32bit資料。
- 按半字編址:對於這個256M記憶體來說,它的定址範圍是128M,而每個記憶體地址可以儲存16bit資料。
- 按位元組編址:對於這個256M記憶體來說,它的定址範圍是256M,而每個記憶體地址可以儲存8bit資料。
對於我們現在的計算機來說,主要都是採用按位元組編址的方式。所以我們可以把記憶體簡單的看成一個線性陣列,陣列每個元素的大小為8bit,我們稱為一個儲存單元。這一點很重要,因為後面討論的所有問題記憶體都是以按位元組編址的方式。 這也是為什麼對於32位計算機來說,能使用的最多容量的記憶體為4GB。如果我們按字編地址,能使用的最大記憶體容量就是16GB了。
於是很容易想到一個問題,為什麼我們要採用位元組編址的方式呢?關於這個問題,我在網上基本沒有找到答案,甚至都找不到問這個問題的。所以這裡沒法給出答案,為什麼為什麼呢? 麻煩知道的朋友告訴我哈。
另一方面的問題是,記憶體編址方式和DRAM晶片是否有關呢? 我認為還是有一定關係。比如我DRAM的晶片是8M*8bit,那麼晶片最小的儲存單位就是8bit,那麼我們記憶體編址就不能按照半個位元組來編址。否則記憶體取出8bit,根本不知道你要那4bit傳給CPU。也有一種說法是現在的DRAM晶片cell都是8bit,所以採用按位元組編址。另一方面應該也和資料匯流排位寬有關。
3. 記憶體資料
前面我們知道了,記憶體是按位元組編址,每個地址的儲存單元可以存放8bit的資料。我們也知道CPU通過記憶體地址獲取一條指令和資料,而他們存在儲存單元中。現在就有一個問題。我們的資料和指令不可能剛好是8bit,如果小於8位,沒什麼問題,頂多是浪費幾位(或許按位元組編址是為了節省記憶體空間考慮)。但是當資料或指令的長度大於8bit呢?因為這種情況是很容易出現的,比如一個16bit的Int資料在記憶體是如何儲存的呢?
3.1 記憶體資料存放
其實一個簡單的辦法就是使用多個儲存單元來存放資料或指令。比如Int16使用2個記憶體單元,而Int32使用4個記憶體單元。當讀取資料時,一次讀取多個記憶體單元。於是這裡又出現2個問題:
- 多個儲存單元儲存的順序?
- 如何確定要讀幾個記憶體單元?
3.1.1 大端和小端儲存
- Little-Endian 就是低位位元組排放在記憶體的低地址端,高位位元組排放在記憶體的高地址端。
- Big-Endian 就是高位位元組排放在記憶體的低地址端,低位位元組排放在記憶體的高地址端。
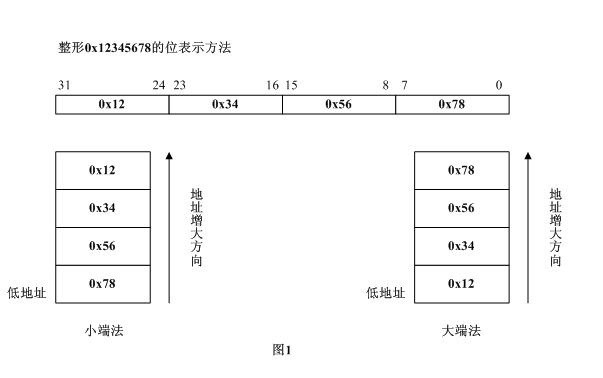
需要說明的是,計算機採用大端還是小端儲存是CPU來決定的, 我們常用的X86體系的CPU採用小端,一下ARM體系的CPU也是用小端,但有一些CPU卻採用大端比如PowerPC、Sun。判斷CPU採用哪種方式很簡單:
[cpp] view plain copy print?- bool IsBigEndian()
- {
- int vlaue = 0x1234;
- char lowAdd = *(char *)&value;
- if( lowAdd == 0x12)
- {
- return true;
- }
- return false;
- }
- bool IsBigEndian()
- {
- int vlaue = 0x1234;
- char lowAdd = *(char *)&value;
- if( lowAdd == 0x12)
- {
- returntrue;
- }
- returnfalse;
- }
既然不同計算機儲存的方式不同,那麼在不同計算機之間互動就可能需要進行大小端的轉換。這一點我們在Socket程式設計中可以看到。這裡就不介紹了,對以我們單一CPU來說我們可以不需要管這個轉換的問題,另外我們目前個人PC都是採用小端方式,所以我們後面預設都是這種方式。
3.1.2 CPU指令
前面我們多次提到了指令的概念,也知道指令是0和1組成的,而彙編程式碼提高了機器碼的可讀性。為什麼突然在這裡介紹CPU指令呢? 主要是解釋上面的第二個問題,當我讀取一個數據或指令時,我怎麼知道需要讀取多少個記憶體單元。
3.1.2.1 CPU指令格式
首先我們來看看CPU指令的格式,我們知道CPU質量主要就是告訴CPU做什麼事情,所以一條CPU指令一般包含操作碼(OP)和操作
| 操作碼欄位 | 地址碼欄位 |
根據一條指令中有幾個運算元地址,可將該指令稱為幾運算元指令或幾地址指令。
| 操作碼 | A1 | A2 | A3 |
三地址指令: (A1) OP (A2) --> A3
| 操作碼 | A1 | A2 |
二地址指令: (A1) OP (A2) --> A1
| 操作碼 | A1 |
一地址指令: (AC) OP (A) --> AC
| 操作碼 |
零地址指令
A1為被運算元地址,也稱源運算元地址; A2為運算元地址,也稱終點運算元地址; A3為存放結果的地址。 同樣,A1,A2,A3以是記憶體中的單元地址,也可以是運算器中通用暫存器的地址。所以就有一個定址的問題。關於指令定址後面會介紹。
CPU指令設計是十分複雜的,因為在計算機中都是0和1儲存,那計算機如何區分一條指令中的運算元和操作碼呢?如何保證指令不會重複呢?這個不是我們討論的重點,有興趣的可以看看計算機體系結構的書,裡面都會有介紹。從上圖來看我們知道CPU的指令長度是變長的。所以CPU並不能確定一條指令需要佔用幾個記憶體單元,那麼CPU又是如何確定一條指令是否讀取完了呢?
3.1.2.2 指令的獲取
現在的CPU多數採用可變長指令系統。關鍵是指令的第一位元組。 當CPU讀指令時,並不是一下把整個指令讀近來,而是先讀入指令的第一個位元組。指令譯碼器分析這個位元組,就知道這是幾字節指令。接著順序讀入後面的位元組。每讀一個位元組,程式計數器PC加一。整個指令讀入後,PC就指向下一指令(等於為讀下一指令做好了準備)。
Sample1:
[plain] view plain copy print?- MOV AL,00 機器碼是1011 0000 0000 0000
- MOV AL,00 機器碼是1011 0000 0000 0000
機器碼是16位在記憶體中佔用2個位元組:
【00000000】 <- 0x0002
【10110000】 <- 0x0001
比如上面這條MOV彙編指令,把立即數00存入AL暫存器。而CPU獲取指令過程如下:
- 從程式計數器獲取當前指令的地址0x0001。
- 儲存控制器從0x0001中讀出整個位元組,傳送給CPU。PC+1 = 0X0002.
- CPU識別出【10110000】表示:操作是MOV AL,並且A2是一個立即數長度為一個位元組,所以整個指令的字長為2位元組。
- CPU從地址0x0002取出指令的最後一個位元組
- CPU將立即數00存入AL暫存器。
這裡的疑問應該是在第3步,CPU是怎麼知道是MOV AL 立即數的操作呢?我們在看下面一個列子。
Sample2:
[plain] view plain copy print?- MOV AL,[0000] 機器碼是1010 0000 0000 0000 0000 0000
- MOV AL,[0000] 機器碼是1010 0000 0000 0000 0000 0000
這裡同樣是一條MOV的彙編指令,整個指令需要佔用3個位元組。
【00000000】 <-0x0003
【00000000】 <- 0x0002
【10100000】 <- 0x0001
我們可以比較一下2條指令第一個位元組的區別,發現這裡的MOV AL是1010 0000,而不是Sample1中的1011 000。CPU讀取了第一個位元組後識別出,操作是MOV AL [D16],表示是一個暫存器間接定址,A3操作是存放的是一個16位就是地址偏移量(為什麼是16位,後面文章會介紹),CPU就判定這條指令長度3個位元組。於是從記憶體0x0002~0x0003讀出指令的後2個位元組,進行定址找到真正的資料記憶體地址,再次通過CPU讀入,並完成操作。
從上面我們可以看出一個指令會根據不同的定址格式,有不同的機器碼與之對應。而每個機器碼對應的指令的長度都是在CPU設計時就規定好了。8086採用變長指令,指令長度是1-6個位元組,後面可以新增8位或16位的偏移量或立即數。 下面的指令格式相比上面2個就更加複雜。

- 第一個位元組的高6位是操作碼,W表示傳說的資料是字(W=1)還是位元組(W=0),D表示資料傳輸方向D=0資料從暫存器傳出,D=1資料傳入暫存器。
- 第二個位元組中REG表示暫存器號,3位可以表示8種暫存器,根據第一位元組的W,可以表示是8位還是16位暫存器。表3-1中列出了8086暫存器編碼表
- 第二個位元組中的MOD和R/M指定了運算元的定址方式,表3-2列出了8086的編碼
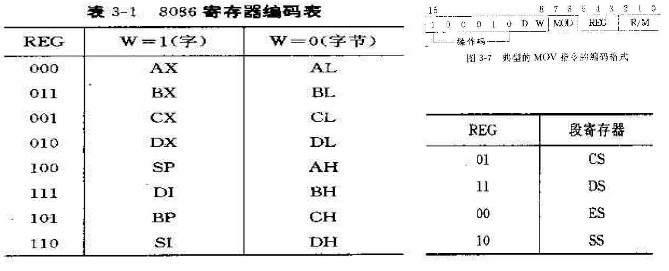
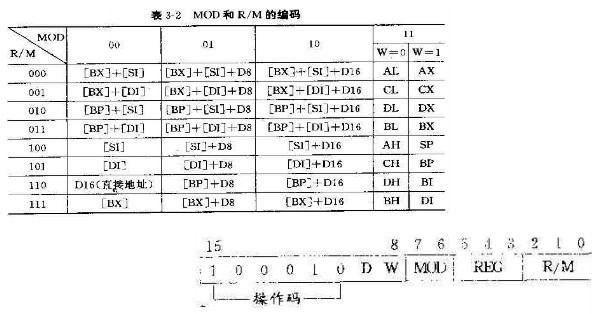
這裡沒必要也無法更詳細介紹CPU指令的,只需要知道,CPU指令中已經定義了指令的長度,不會出現混亂讀取記憶體單元的現象。有興趣的可以檢視引用中的連線。
3.1.3 記憶體資料
3.1.3.1 記憶體資料的操作
從上面我們可以知道,運算元可以是立即數,可以存放在暫存器,也可以存放在記憶體。對於第一個例子,指令已經說明,操作時是一個位元組,於是CPU可以從下一個記憶體地址讀取操作時,而對於第二個列子,運算元只是地址偏移,所以當CPU獲得這個資料後,需要轉換成實際的記憶體地址,在進行一次記憶體訪問,把資料讀入到暫存器中。這裡就出現我們前面提到的問題,這個資料我們要讀幾個儲存單元呢?
[cpp] view plain copy print?- MyClass cla;
- 008C3EC9 lea ecx,[cla]
- 008C3ECC call MyClass::MyClass (08C1050h)
- 008C3ED1 mov dword ptr [ebp-4],0
- cla.num5 = 500;
- 008C3ED8 mov dword ptr [ebp-6Ch],1F4h
- int b1 = MyClass::num1;
- 008C3EDF mov dword ptr [b1],64h
- int b2 = MyClass::num2;
- 008C3EE6 mov dword ptr [b2],0C8h
- int b3 = MyClass::num3;
- 008C3EF0 mov eax,dword ptr ds:[008C9008h]
- 008C3EF5 mov dword ptr [b3],eax
- int b4 = cla.num4;
- 008C3EFB mov eax,dword ptr [cla]
- 008C3EFE mov dword ptr [b4],eax
- int b5 = cla.num5;
- 008C3F04 mov eax,dword ptr [ebp-6Ch]
- 008C3F07 mov dword ptr [b5],eax
- MyClass cla;
- 008C3EC9 lea ecx,[cla]
- 008C3ECC call MyClass::MyClass (08C1050h)
- 008C3ED1 mov dword ptr [ebp-4],0
- cla.num5 = 500;
- 008C3ED8 mov dword ptr [ebp-6Ch],1F4h
- int b1 = MyClass::num1;
- 008C3EDF mov dword ptr [b1],64h
- int b2 = MyClass::num2;
- 008C3EE6 mov dword ptr [b2],0C8h
- int b3 = MyClass::num3;
- 008C3EF0 mov eax,dword ptr ds:[008C9008h]
- 008C3EF5 mov dword ptr [b3],eax
- int b4 = cla.num4;
- 008C3EFB mov eax,dword ptr [cla]
-
相關推薦
計算機原理(二)
1. 記憶體工作原理 CPU和記憶體是計算機中最重要的兩個元件,前面已經知道了CPU是如何工作的,上一篇也介紹了記憶體採用的DRAM的儲存原理。CPU工作需要知道指令或資料的記憶體地址,那麼這樣一個地址是如何和記憶體這樣一個硬體聯絡起來的呢?現在就看看記憶體到的是怎
計算機組成原理(二)之系統匯流排
在這個系列文章的第一講,漫談計算機組成原理(一)之程式執行的過程 中說過,現代計算機是從馮若伊曼計算機發展起來的。其組成部分有儲存器、運算器、控制器、輸入裝置、輸出裝置,在現代計算機中,人們將運算器與控制器封裝起來成為CPU(中央處理
計算機組成原理(二) 定點數乘法
定點數的乘法: 1.原碼一位乘 (1) A = – 0.1101 B = 0.1011 (2) 2.原碼二位乘 每次用乘數的2位判斷原部分積是否加或如何加被乘數 兩位乘數共有四種狀態,對應四種狀態如
漫談計算機組成原理(二)之系統匯流排
在這個系列文章的第一講,漫談計算機組成原理(一)之程式執行的過程 中說過,現代計算機是從馮若伊曼計算機發展起來的。其組成部分有儲存器、運算器、控制器、輸入裝置、輸出裝置,在現代計算機中,人們將運算器與控制器封裝起來成為CPU(中央處理單元)。計算機的各種部
重學計算機組成原理(二)- 制定學習路線,攀登“效能”之巔
0 學習路線的知識點概括 學習計算機組成原理,就是學習計算機是如何協調執行的 計算機組成原理的英文叫Computer Organization Organization 意"組織機構"。 該組織機構能夠進行各種計算、控制、讀取輸入,進行輸出,達成各種強大的功能。 把整個計算機組成原理的知識點拆分成了
【SpringMVC架構】SpringMVC入門實例,解析工作原理(二)
rip 業務邏輯層 popu 輸入 implement override article hide -i 上篇博文,我們簡單的介紹了什麽是SpringMVC。這篇博文。我們搭建一個簡單SpringMVC的環境,使用非註解形式實現一個HelloWorld實
計算機作業(二)衡陽汽車工程學院
計算機 汽車 img blog images 學院 http 技術分享 es2017 計算機作業(二)衡陽汽車工程學院
QR 編碼原理(二)
bit 選擇 www. nbsp char 混合 示例 mode 匹配 編碼就是把常見的數字、字符等轉換成QR碼的方法。說具體的編碼之前,先說一下QR碼的最大容量問題。 一、最大容量 QR碼的最大容量取決於選擇的版本、糾錯級別和編碼模式(Mode:數字、字符、多字節字符等)
計算機概念(二)
blog 十六進制 數位 負數 -s 如果 之間 從後往前 art 數字和計算: 數字:抽象數學系統的一個單位,服從算術法則。 自然數:0或通過在0上重復加1得到的數。 負數: 小於0的數,是在相應的正數前加上符號 整數:自然數、自然數的負數或0. 有理
瀏覽器工作原理(二):瀏覽器渲染過程概述
sync 結構 dom end 繪制 fault 異步加載 步驟 targe 參考:https://segmentfault.com/a/1190000012925872#articleHeader4 瀏覽器器內核拿到內容後,渲染大概可以劃分成以下幾個步驟: 解析html
GCC編譯器原理(二)------編譯原理一:ELF文件
過程 外部文件 初始 cati tor 保護功能 編譯原理 外部 comm 二、ELF 文件介紹 2.1 可執行文件格式綜述 相對於其它文件類型,可執行文件可能是一個操作系統中最重要的文件類型,因為它們是完成操作的真正執行者。可執行文件的大小、運行速度、資源占用情況
JVM原理(二)類載入機制與GC演算法
一. 類的載入機制 過程 將.class的二進位制資料讀入記憶體,放入方法區中 在堆中建立一個java.lang.Class物件,封裝類在方法區中的資料結構,並提供訪問方法區資料結構的介面 類的生命週期 類的載入過程
計算機視覺(二):直方圖均衡
一、灰度空間的直方圖均衡 1.直方圖 2.變換函式應滿足條件 3.變換函式 4.直方圖均衡 二、彩色空間的直方圖均衡
spring原始碼學習之路---IOC實現原理(二)
上一章我們已經初步認識了BeanFactory和BeanDefinition,一個是IOC的核心工廠介面,一個是IOC的bean定義介面,上章提到說我們無法讓BeanFactory持有一個Map package org.springframework.beans.factory.supp
IP原理(二)
硬體型別:16bit欄位,定義執行ARP的物理網路的型別 協議型別:16bit欄位,定義傳送方提供的高階協議型別ARP可用於任何高層協議 硬體長度:8bit欄位,定義以位元組位單位的實體地址長度,如乙太網該值為6 協議長度:8bit欄位,定義以位元組為單位的邏輯地址長度,如IPV4該值為
計算機視覺(二)
xtra roc 分類 match open 提取 水平 histogram svm 濾波和邊緣檢測 1. 空間濾波和頻域濾波 線性濾波和非線性濾波 滑動濾波: blur 和 boxfilter、高斯濾波器是真正的低通濾波器、與boxfilter相比沒有振鈴現象
SurfaceFlinger原理(二):Vsync事件的處理
SurfaceFlinger內部有兩個EventThread,一個負責app端對Vsync訊號的監聽處理,一個負責SurfaceFlinger對Vsync訊號的監聽處理。SurfaceFlinger內部維持了一個MessageQueue,當SurfaceFlinger端的
現代通訊原理(二):到底什麼是通訊系統?
不知你有沒有想過什麼樣的系統稱之為通訊系統呢?我們常說現代意義上的通訊系統就是用光或者電訊號來傳輸資訊的系統。那麼我們家裡的用來傳輸電能的市電系統算不算通訊系統?我們用來照明的燈光是不是通訊系統呢? 我們來想想,通訊系統為什麼會產生。是因為對於接收端來說
Apache Kafka入門教程輕鬆學-第四章 Kafka核心元件和流程-設計-原理(二)協調器(消費者和組協調器)
本入門教程,涵蓋Kafka核心內容,通過例項和大量圖表,幫助學習者理解,任何問題歡迎留言。 目錄: 上一節介紹了kafka工作的核心元件--控制器。本節將介紹消費者密切相關的元件--協調器。它負責消費者的出入組工作。大家可以回想一下kafka核心概念中關於吃蘋果的場景,如