
自定義Hive Sql Job分析工具
前言
我們都知道,在大資料領域,Hive的出現幫我降低了許多使用Hadoop書寫方式的學習成本.使用使用者可以使用類似Sql的語法規則寫明查詢語句,從hive表資料中查詢目標資料.最為重要的是這些sql語句會最終轉化為map reduce作業進行處理.這也是Hive最強大的地方.可以簡單的理解為Hive就是依託在Hadoop上的1個殼.但是這裡有一點點小小的不同,不是每段hive查詢sql語句與最後生成的job一一對應,如果你的這段sql是一個大sql,他在轉化掉之後,會衍生出許多小job,這些小job是獨立存在執行的,以不同的job名稱進行區別,但是也會保留公共的job名稱.所以一個問題來了,對於超級長的hive sql語句,我想檢視到底是哪段子sql花費了我大量的執行時間,在JobHistory上只有每個子Job的執行時間,沒有子Job對應的sql語句,一旦這個功能有了之後,就會幫助我們迅速的定位到問題所在.
Hive子Job中的Sql
OK,帶著上述的目標,我們要想分析出到底哪段子sql所衍生的job執行時間更長,就要先知道這些sql到底在存在與哪裡.在前面的描述中,已經提到了,Hive是依託於Hadoop,自然Hive提交的job資訊也是儲存在Hadoop的HDFS上的.在聯想一下JobHistory中的各個檔案型別.你應該會發現帶有下面字尾的檔案存在.
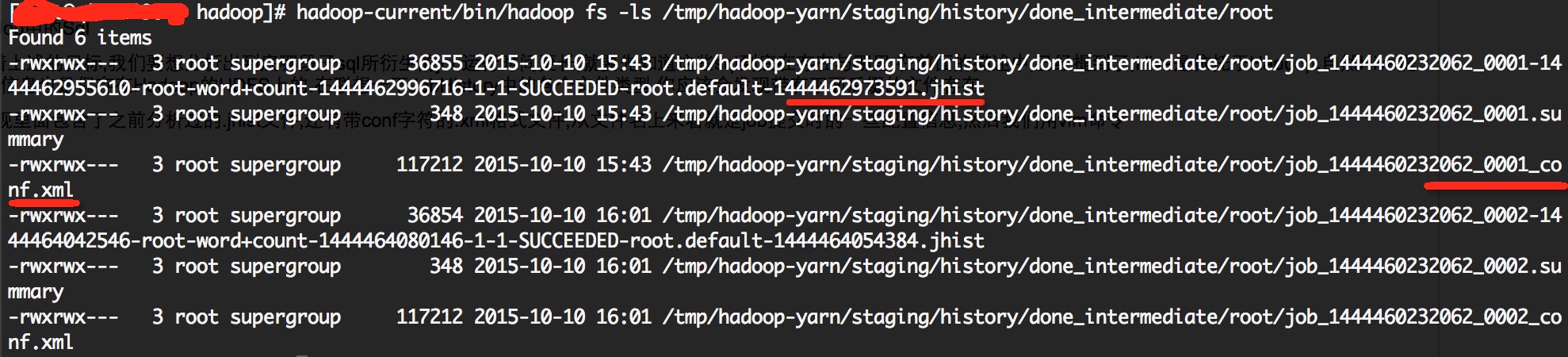
我們發現裡面包含了之前分析過的.jhist檔案,還有帶conf字元的.xml格式檔案,從檔名上來看就是job提交時的一些配置資訊,然後我們用vim命令查閱conf.xml字尾的檔案,看看裡面是不是有我們想要的hive qury string 這樣的屬性
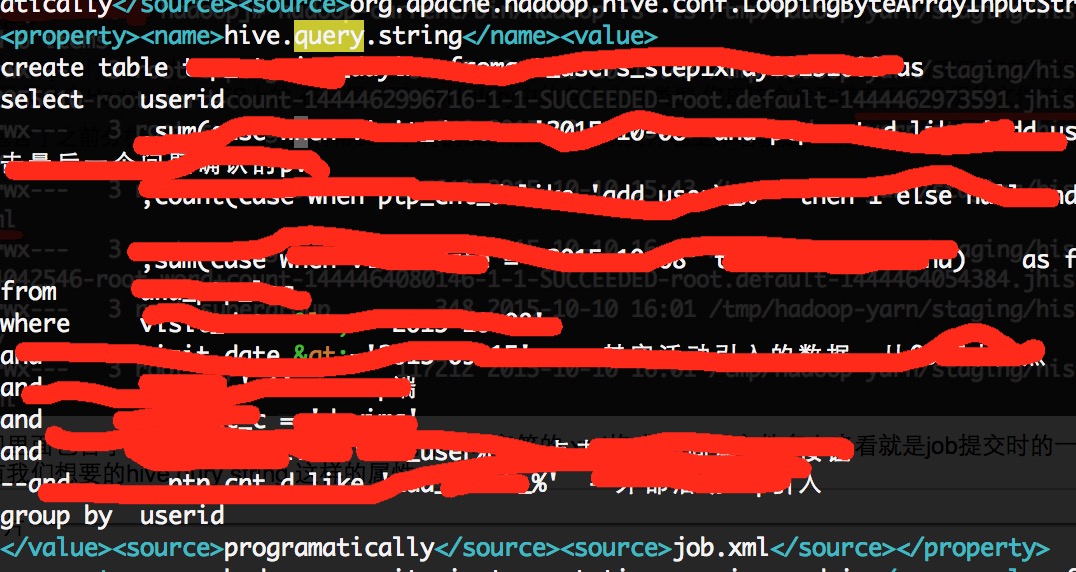
OK,目標算是找到了,這的確就是我們想要的屬性.說明這樣的資訊的確是存在的,後面的操作就是怎麼去解析這段有用的資訊了.
程式工具分析Hive Sql Job
知道了目標資料來源,我們能想到的最簡單快速的方法就是逐行解析檔案,做做文字匹配,篩選關鍵資訊.這些程式碼誰都會寫,首先要傳入一個HDFS目錄地址,這個是在JobHistory的儲存目錄上加上一個具體日期目錄,這段解析程式在文章的末尾會加上.下面列舉在除錯分析程式時遇到的一些問題,這個還是比較有用的.
1.hive sql中的中文導致解析出現亂碼
這個又是非常討厭的java解析出現亂碼的原因,因為考慮到sql中存在中文註釋,而Hadoop在存中文的時候都是用utf8的編碼方式,所以讀出檔案資料後進行一次轉utf-8編碼方式的處理,就是下面所示程式碼.
...
fileSystem = path.getFileSystem(new Configuration());
in = fileSystem.open(path);
InputStreamReader isr;
BufferedReader br;
isr = new InputStreamReader(in, "UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
...2.單執行緒解析檔案速度過慢
之前在測試環境中做檔案解析看不出真實效果,檔案一下解析就OK了,但是到真實環境中,多達幾萬個job檔案,程式馬上就吃不消了,算上解析檔案,再把結果寫入mysql,耗時達到60多分鐘,後面改成了多執行緒的方式,後來開到10個執行緒去跑,速度才快了許多.
3.結果資料寫入MySql過慢
後來處理速度是上去了,但是寫入sql速度過慢,比如說,我有一次測試,開10個執行緒區解析,花了8分鐘就解析好了幾萬個檔案資料,但是插入資料庫花了20分鐘左右,而且量也就幾萬條語句.後來改成了批處理的方式,效果並沒有什麼大的改變,這個慢的問題具體並沒有被解決掉,懷疑可能是因有些語句中存在超長的hive sql語句導致的.
主工具程式碼
package org.apache.hadoop.mapreduce.v2.hs.tool.sqlanalyse;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileContext;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.UnsupportedFileSystemException;
import org.apache.hadoop.io.IOUtils;
public class HiveSqlAnalyseTool {
private int threadNum;
private String dirType;
private String jobHistoryPath;
private FileContext doneDirFc;
private Path doneDirPrefixPath;
private LinkedList<FileStatus> fileStatusList;
private HashMap<String, String[]> dataInfos;
private DbClient dbClient;
public HiveSqlAnalyseTool(String dirType, String jobHistoryPath,
int threadNum) {
this.threadNum = threadNum;
this.dirType = dirType;
this.jobHistoryPath = jobHistoryPath;
this.dataInfos = new HashMap<String, String[]>();
this.fileStatusList = new LinkedList<FileStatus>();
this.dbClient = new DbClient(BaseValues.DB_URL,
BaseValues.DB_USER_NAME, BaseValues.DB_PASSWORD,
BaseValues.DB_HIVE_SQL_STAT_TABLE_NAME);
try {
doneDirPrefixPath = FileContext.getFileContext(new Configuration())
.makeQualified(new Path(this.jobHistoryPath));
doneDirFc = FileContext.getFileContext(doneDirPrefixPath.toUri());
} catch (UnsupportedFileSystemException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void readJobInfoFiles() {
List<FileStatus> files;
files = new ArrayList<FileStatus>();
try {
files = scanDirectory(doneDirPrefixPath, doneDirFc, files);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (files != null) {
for (FileStatus fs : files) {
// parseFileInfo(fs);
}
System.out.println("files num is " + files.size());
System.out
.println("fileStatusList size is" + fileStatusList.size());
ParseThread[] threads;
threads = new ParseThread[threadNum];
for (int i = 0; i < threadNum; i++) {
System.out.println("thread " + i + "start run");
threads[i] = new ParseThread(this, fileStatusList, dataInfos);
threads[i].start();
}
for (int i = 0; i < threadNum; i++) {
System.out.println("thread " + i + "join run");
try {
if (threads[i] != null) {
threads[i].join();
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} else {
System.out.println("files is null");
}
printStatDatas();
}
protected List<FileStatus> scanDirectory(Path path, FileContext fc,
List<FileStatus> jhStatusList) throws IOException {
path = fc.makeQualified(path);
System.out.println("dir path is " + path.getName());
try {
RemoteIterator<FileStatus> fileStatusIter = fc.listStatus(path);
while (fileStatusIter.hasNext()) {
FileStatus fileStatus = fileStatusIter.next();
Path filePath = fileStatus.getPath();
if (fileStatus.isFile()) {
jhStatusList.add(fileStatus);
fileStatusList.add(fileStatus);
} else if (fileStatus.isDirectory()) {
scanDirectory(filePath, fc, jhStatusList);
}
}
} catch (FileNotFoundException fe) {
System.out.println("Error while scanning directory " + path);
}
return jhStatusList;
}
private void parseFileInfo(FileStatus fs) {
String resultStr;
String str;
String username;
String fileType;
String jobId;
String jobName;
String hiveSql;
int startPos;
int endPos;
int hiveSqlFlag;
long launchTime;
long finishTime;
int mapTaskNum;
int reduceTaskNum;
String xmlNameFlag;
String launchTimeFlag;
String finishTimeFlag;
String launchMapFlag;
String launchReduceFlag;
Path path;
FileSystem fileSystem;
InputStream in;
resultStr = "";
fileType = "";
hiveSql = "";
jobId = "";
jobName = "";
username = "";
hiveSqlFlag = 0;
launchTime = 0;
finishTime = 0;
mapTaskNum = 0;
reduceTaskNum = 0;
xmlNameFlag = "<value>";
launchTimeFlag = "\"launchTime\":";
finishTimeFlag = "\"finishTime\":";
launchMapFlag = "\"Launched map tasks\"";
launchReduceFlag = "\"Launched reduce tasks\"";
path = fs.getPath();
str = path.getName();
if (str.endsWith(".xml")) {
fileType = "config";
endPos = str.lastIndexOf("_");
jobId = str.substring(0, endPos);
} else if (str.endsWith(".jhist")) {
fileType = "info";
endPos = str.indexOf("-");
jobId = str.substring(0, endPos);
} else {
return;
}
try {
fileSystem = path.getFileSystem(new Configuration());
in = fileSystem.open(path);
InputStreamReader isr;
BufferedReader br;
isr = new InputStreamReader(in, "UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
if (str.contains("mapreduce.job.user.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
username = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("mapreduce.job.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
jobName = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("hive.query.string")) {
hiveSqlFlag = 1;
hiveSql = str;
} else if (hiveSqlFlag == 1) {
hiveSql += str;
if (str.contains("</value>")) {
startPos = hiveSql.indexOf(xmlNameFlag);
endPos = hiveSql.indexOf("</value>");
hiveSql = hiveSql.substring(
startPos + xmlNameFlag.length(), endPos);
hiveSqlFlag = 0;
}
} else if (str.startsWith("{\"type\":\"JOB_INITED\"")) {
startPos = str.indexOf(launchTimeFlag);
str = str.substring(startPos + launchTimeFlag.length());
endPos = str.indexOf(",");
launchTime = Long.parseLong(str.substring(0, endPos));
} else if (str.startsWith("{\"type\":\"JOB_FINISHED\"")) {
mapTaskNum = parseTaskNum(launchMapFlag, str);
reduceTaskNum = parseTaskNum(launchReduceFlag, str);
startPos = str.indexOf(finishTimeFlag);
str = str.substring(startPos + finishTimeFlag.length());
endPos = str.indexOf(",");
finishTime = Long.parseLong(str.substring(0, endPos));
}
}
System.out.println("jobId is " + jobId);
System.out.println("jobName is " + jobName);
System.out.println("username is " + username);
System.out.println("map task num is " + mapTaskNum);
System.out.println("reduce task num is " + reduceTaskNum);
System.out.println("launchTime is " + launchTime);
System.out.println("finishTime is " + finishTime);
System.out.println("hive query sql is " + hiveSql);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (fileType.equals("config")) {
insertConfParseData(jobId, jobName, username, hiveSql);
} else if (fileType.equals("info")) {
insertJobInfoParseData(jobId, launchTime, finishTime, mapTaskNum,
reduceTaskNum);
}
}
private void insertConfParseData(String jobId, String jobName,
String username, String sql) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBNAME] = jobName;
array[BaseValues.DB_COLUMN_HIVE_SQL_USERNAME] = username;
array[BaseValues.DB_COLUMN_HIVE_SQL_HIVE_SQL] = sql;
dataInfos.put(jobId, array);
}
private void insertJobInfoParseData(String jobId, long launchTime,
long finishedTime, int mapTaskNum, int reduceTaskNum) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_START_TIME] = String
.valueOf(launchTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_FINISH_TIME] = String
.valueOf(finishedTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_MAP_TASK_NUM] = String
.valueOf(mapTaskNum);
array[BaseValues.DB_COLUMN_HIVE_SQL_REDUCE_TASK_NUM] = String
.valueOf(reduceTaskNum);
dataInfos.put(jobId, array);
}
private int parseTaskNum(String flag, String jobStr) {
int taskNum;
int startPos;
int endPos;
String tmpStr;
taskNum = 0;
tmpStr = jobStr;
startPos = tmpStr.indexOf(flag);
if (startPos == -1) {
return 0;
}
tmpStr = tmpStr.substring(startPos + flag.length());
endPos = tmpStr.indexOf("}");
tmpStr = tmpStr.substring(0, endPos);
taskNum = Integer.parseInt(tmpStr.split(":")[1]);
return taskNum;
}
private void printStatDatas() {
String jobId;
String jobInfo;
String[] infos;
if (dbClient != null) {
dbClient.createConnection();
}
if (dataInfos != null) {
System.out.println("map data size is" + dataInfos.size());
if (dbClient != null && dirType.equals("dateTimeDir")) {
dbClient.insertDataBatch(dataInfos);
}
}
/*for (Entry<String, String[]> entry : this.dataInfos.entrySet()) {
jobId = entry.getKey();
infos = entry.getValue();
jobInfo = String
.format("jobId is %s, jobName:%s, usrname:%s, launchTime:%s, finishTime:%s, mapTaskNum:%s, reduceTaskNum:%s, querySql:%s",
jobId, infos[1], infos[2], infos[3], infos[4],
infos[5], infos[6], infos[7]);
// System.out.println("job detail info " + jobInfo);
if (dbClient != null && dirType.equals("dateTimeDir")) {
dbClient.insertHiveSqlStatData(infos);
}
}*/
if (dbClient != null) {
dbClient.closeConnection();
}
}
public synchronized FileStatus getOneFile() {
FileStatus fs;
fs = null;
if (fileStatusList != null & fileStatusList.size() > 0) {
fs = fileStatusList.poll();
}
return fs;
}
public synchronized void addDataToMap(String jobId, String[] values) {
if (dataInfos != null) {
dataInfos.put(jobId, values);
}
}
}
解析執行緒程式碼ParseThread.java:
package org.apache.hadoop.mapreduce.v2.hs.tool.sqlanalyse;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.LinkedList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ParseThread extends Thread{
private HiveSqlAnalyseTool tool;
private LinkedList<FileStatus> fileStatus;
private HashMap<String, String[]> dataInfos;
public ParseThread(HiveSqlAnalyseTool tool, LinkedList<FileStatus> fileStatus, HashMap<String, String[]> dataInfos){
this.tool = tool;
this.fileStatus = fileStatus;
this.dataInfos = dataInfos;
}
@Override
public void run() {
FileStatus fs;
while(fileStatus != null && !fileStatus.isEmpty()){
fs = tool.getOneFile();
parseFileInfo(fs);
}
super.run();
}
private void parseFileInfo(FileStatus fs) {
String str;
String username;
String fileType;
String jobId;
String jobName;
String hiveSql;
int startPos;
int endPos;
int hiveSqlFlag;
long launchTime;
long finishTime;
int mapTaskNum;
int reduceTaskNum;
String xmlNameFlag;
String launchTimeFlag;
String finishTimeFlag;
String launchMapFlag;
String launchReduceFlag;
Path path;
FileSystem fileSystem;
InputStream in;
fileType = "";
hiveSql = "";
jobId = "";
jobName = "";
username = "";
hiveSqlFlag = 0;
launchTime = 0;
finishTime = 0;
mapTaskNum = 0;
reduceTaskNum = 0;
xmlNameFlag = "<value>";
launchTimeFlag = "\"launchTime\":";
finishTimeFlag = "\"finishTime\":";
launchMapFlag = "\"Launched map tasks\"";
launchReduceFlag = "\"Launched reduce tasks\"";
path = fs.getPath();
str = path.getName();
if (str.endsWith(".xml")) {
fileType = "config";
endPos = str.lastIndexOf("_");
jobId = str.substring(0, endPos);
} else if (str.endsWith(".jhist")) {
fileType = "info";
endPos = str.indexOf("-");
jobId = str.substring(0, endPos);
}else{
return;
}
try {
fileSystem = path.getFileSystem(new Configuration());
in = fileSystem.open(path);
InputStreamReader isr;
BufferedReader br;
isr = new InputStreamReader(in, "UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
if (str.contains("mapreduce.job.user.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
username = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("mapreduce.job.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
jobName = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("hive.query.string")) {
hiveSqlFlag = 1;
hiveSql = str;
} else if (hiveSqlFlag == 1) {
hiveSql += str;
if (str.contains("</value>")) {
startPos = hiveSql.indexOf(xmlNameFlag);
endPos = hiveSql.indexOf("</value>");
hiveSql = hiveSql.substring(
startPos + xmlNameFlag.length(), endPos);
hiveSqlFlag = 0;
}
} else if (str.startsWith("{\"type\":\"JOB_INITED\"")) {
startPos = str.indexOf(launchTimeFlag);
str = str.substring(startPos + launchTimeFlag.length());
endPos = str.indexOf(",");
launchTime = Long.parseLong(str.substring(0, endPos));
} else if (str.startsWith("{\"type\":\"JOB_FINISHED\"")) {
mapTaskNum = parseTaskNum(launchMapFlag, str);
reduceTaskNum = parseTaskNum(launchReduceFlag, str);
startPos = str.indexOf(finishTimeFlag);
str = str.substring(startPos + finishTimeFlag.length());
endPos = str.indexOf(",");
finishTime = Long.parseLong(str.substring(0, endPos));
}
}
/*System.out.println("jobId is " + jobId);
System.out.println("jobName is " + jobName);
System.out.println("username is " + username);
System.out.println("map task num is " + mapTaskNum);
System.out.println("reduce task num is " + reduceTaskNum);
System.out.println("launchTime is " + launchTime);
System.out.println("finishTime is " + finishTime);
System.out.println("hive query sql is " + hiveSql);*/
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (fileType.equals("config")) {
insertConfParseData(jobId, jobName, username, hiveSql);
} else if (fileType.equals("info")) {
insertJobInfoParseData(jobId, launchTime, finishTime, mapTaskNum,
reduceTaskNum);
}
}
private void insertConfParseData(String jobId, String jobName,
String username, String sql) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBNAME] = jobName;
array[BaseValues.DB_COLUMN_HIVE_SQL_USERNAME] = username;
array[BaseValues.DB_COLUMN_HIVE_SQL_HIVE_SQL] = sql;
tool.addDataToMap(jobId, array);
}
private void insertJobInfoParseData(String jobId, long launchTime,
long finishedTime, int mapTaskNum, int reduceTaskNum) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_START_TIME] = String
.valueOf(launchTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_FINISH_TIME] = String
.valueOf(finishedTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_MAP_TASK_NUM] = String
.valueOf(mapTaskNum);
array[BaseValues.DB_COLUMN_HIVE_SQL_REDUCE_TASK_NUM] = String
.valueOf(reduceTaskNum);
tool.addDataToMap(jobId, array);
}
private int parseTaskNum(String flag, String jobStr) {
int taskNum;
int startPos;
int endPos;
String tmpStr;
taskNum = 0;
tmpStr = jobStr;
startPos = tmpStr.indexOf(flag);
if(startPos == -1){
return 0;
}
tmpStr = tmpStr.substring(startPos + flag.length());
endPos = tmpStr.indexOf("}");
tmpStr = tmpStr.substring(0, endPos);
taskNum = Integer.parseInt(tmpStr.split(":")[1]);
return taskNum;
}
}
相關推薦
自定義Hive Sql Job分析工具
前言我們都知道,在大資料領域,Hive的出現幫我降低了許多使用Hadoop書寫方式的學習成本.使用使用者可以使用類似Sql的語法規則寫明查詢語句,從hive表資料中查詢目標資料.最為重要的是這些sql語句會最終轉化為map reduce作業進行處理.這也是Hive最強大的地方
hive中使用自定義函式(UDF)實現分析函式row_number的功能
1. hive0.10及之前的版本沒有row_number這個函式,假設我們現在出現如下業務場景,現在我們在hdfs上有個log日誌檔案,為了方便敘述,該檔案只有2個欄位,第一個是使用者的id,第二個是當天登入的timestamp,現在我們需要求每個使用者最早登入的那條記錄(
Hive自定義UDF函式--常用的工具類
註冊函式:將自定義函式打成jar包,上傳hdfs$hive>create function formattime as 'com.air.udf.FormatTimeUDF' using jar 'hdfs://mycluster/user/centos/air-hiv
在 Windows Server Container 中運行 Azure Storage Emulator(二):使用自定義的 SQL Server Instance
manage span contain target ros 結果 images 兩種方法 ini 上一章,我們解決了 Azure Storage Emulator 自定義監聽地址的問題,這遠遠不夠,因為在我們 DEV/QA 環境有各自的 SQL Server Inst
自定義的jdbc連接工具類JDBCUtils【java 工具類】
tco 成功 val update red source dex imp 添加 JDBCUtils 類: 1. 創建私有的屬性*(連接數據庫必要的四個變量):dreiver url user password 2. 將構造函數私有化 3.將註冊驅動寫入靜態代碼塊
HanLP用戶自定義詞典源碼分析
自然語言 insert 理解 是否 issues 規則 tro combine 兩個 HanLP用戶自定義詞典源碼分析 1. 官方文檔及參考鏈接 關於詞典問題Issue,首先參考:FAQ 自定義詞典其實是基於規則的分詞,它的用法參考這個issue 如果有些數量詞、字母詞需
AXI-Lite總線及其自定義IP核使用分析總結
定義 ip核 create 自定義 valid 圖片 打開 pro man ZYNQ的優勢在於通過高效的接口總線組成了ARM+FPGA的架構。我認為兩者是互為底層的,當進行算法驗證時,ARM端現有的硬件控制器和庫函數可以很方便地連接外設,而不像FPGA設計那樣完全寫出接
Netty實現自定義協議和原始碼分析
本篇 主要講的是自定義協議是如何實現的,以及自定義協議中會出現的問題和Netty是如何支援的。 分為4個部分 |– 粘包 拆包 資料包不全 和解決方案 |– 程式碼實現 |– ByteToMessageDecoder的原始碼分析 |– 過程流程圖 粘包
DIAView 自定義曲線 SQL Server資料庫互動
首先來看下執行效果: 具體的實現步驟如下 步驟一:新建一個視窗,並設計視窗內容如下圖所示,分別使用到的控制元件:標籤、按鈕、日期、自定義曲線 步驟二:建立“變數字典” 第三步:新建“變數群組記錄” ,右擊“變數群組記錄”,單擊“新建歷史群組記錄”,如下圖紅色框框
自定義Hive檔案和記錄格式(十)
create table 語句中預設的是stored as textfile 練習了store as sequencefile,省空間,提升i/o效能 PIG中輸入輸出分隔符預設是製表符\t,而到了hive中
iOS商品詳情、ffmpeg播放器、指示器集錦、自定義圓弧選單、實用工具等原始碼
iOS精選原始碼 電商商品詳情 Swift.兩種方式實現tableViewCell拖拽功能 ffmpeg+openGL播放器 微信聊天表情雨、表情下落、表情動畫 iOS指示器集錦 彈窗增加 pickerView 可互動、無限個數、支援回
衣服尺碼自定義排序sql
轉載請註明出處 select SizeCup as Size ,OrderQty from VW_CM1_SizeBreakdowm where So_NO [email protected]_No and [email protect
Springboot學習05-自定義錯誤頁面完整分析
Springboot學習06-自定義錯誤頁面完整分析 前言 接著上一篇部落格,繼續分析Springboot錯誤頁面問題 正文 1-自定義瀏覽器錯誤頁面(只要將自己的錯誤頁面放在指定的路徑下即可) 1-1-Springboot錯誤頁面匹配機制(以
EasyNVR智慧雲終端接入AI視訊智慧分析功能,使用者可自定義接入自己的分析演算法
視訊分析的需求 人工智慧的發展和在行業中的作用就不用多說了,已經到了勢在必行的一個程度了,尤其是對於流媒體音視訊行業來說,這基本上是人工智慧重中之重的領域,視訊人工智慧,也就是視訊視覺分析的應用方式大體上可以分為兩種: 中心計算:所有視訊影象資料都以圖片或者視訊編碼流的形
SQL case when then end根據某列資料內容在新列顯示自定義內容 SQL利用Case When Then多條件判斷SQL 語句
select ID,Username,namer=(case when(score<='50') then '實習' when(score>'50' and score<='500' ) then
sublime自定義補全關鍵字 匯出工具
sublime是指令碼開發編輯器中比較方便的,我做Lua開發也是用sublime來做編輯器的。 sublime的自動補全功能也還行, 但是對於全域性的函式不會自動輸出,那麼是否可以設定自動補全的關鍵字呢? 我在網上找了很久沒有找到,沒有找到解決的辦法, 只找到了
mybatis自定義動態sql傳入物件
現在有一需求,要求頁面顯示懸賞列表,要求該懸賞未過期,沒有人接受以及附帶分頁查詢。 這裡我們很容易能得到滿足該需求的sql語句: select * from bounty where DeadTime > nowtime AND s
自定義型別介面卡的Gson工具類
在android開發以及javaEE的開發過程中,我們需要解析json,下面我為大家提供一個已經封裝好的工具類,在使用過程中,完全不需要再對gson作處理。一行程式碼即可以實現轉換 public final class JsonUtil { priv
自定義ckeditor編輯器的工具樣式
//字型. config.font_names = ‘宋體;楷體_GB2312;新宋體;黑體;隸書;幼圓;微軟雅黑;Arial; Comic Sans MS;Courier New;Tahoma;Times New Roman;Verdana;’ ; //工具按
自定義HIVE-UDF函式
一 新建JAVA專案 並新增 hive-exec-2.1.0.jar 和hadoop-common-2.7.3.jar hive-exec-2.1.0.jar 在HIVE安裝目錄的lib目錄下 hadoop-common-2.7.3.jar在hadoop