
Hbase資料結構+基本語法
全棧工程師開發手冊 (作者:欒鵬)
HBase中的表一般有這樣的特點:
1 大:一個表可以有上億行,上百萬列
2 面向列:面向列(族)的儲存和許可權控制,列(族)獨立檢索。
3 稀疏:對於為空(null)的列,並不佔用儲存空間,因此,表可以設計的非常稀疏。
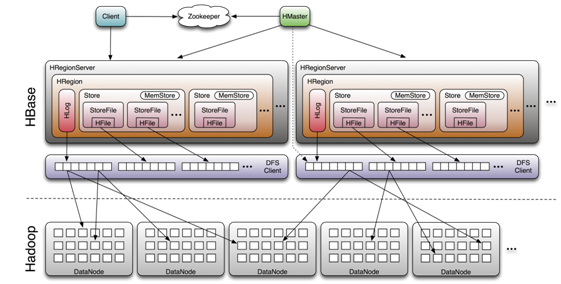
下面一幅圖是Hbase在Hadoop Ecosystem中的位置。
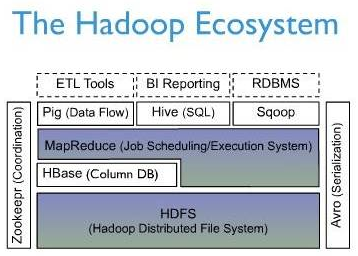
邏輯檢視
HBase以表的形式儲存資料。表有行和列組成。列劃分為若干個列族(row family)
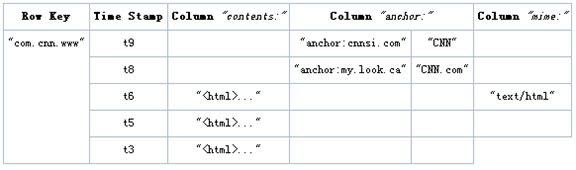
Row Key
與nosql資料庫們一樣,row key是用來檢索記錄的主鍵。訪問hbase table中的行,只有三種方式:
- 1通過單個row key訪問
- 2 通過row key的range
- 3 全表掃描
Row key行鍵 (Row key)可以是任意字串(最大長度是 64KB,實際應用中長度一般為 10-100bytes),在hbase內部,row key儲存為位元組陣列。
儲存時,資料按照Row key的字典序(byte order)排序儲存。設計key時,要充分排序儲存這個特性,將經常一起讀取的行儲存放到一起。(位置相關性)
注意:
字典序對int排序的結果是:
1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,…,9,91,92,93,94,95,96,97,98,99。要保持整形的自然序,行鍵必須用0作左填充。
行的一次讀寫是原子操作 (不論一次讀寫多少列)。這個設計決策能夠使使用者很容易的理解程式在對同一個行進行併發更新操作時的行為。
列族
hbase表中的每個列,都歸屬與某個列族。列族是表的chema的一部分(而列不是),必須在使用表之前定義。列名都以列族作為字首。例如courses:history,courses:math都屬於courses 這個列族。
訪 問控制、磁碟和記憶體的使用統計都是在列族層面進行的。實際應用中,列族上的控制權限能幫助我們管理不同型別的應用:我們允許一些應用可以新增新的基本數 據、一些應用可以讀取基本資料並建立繼承的列族、一些應用則只允許瀏覽資料(甚至可能因為隱私的原因不能瀏覽所有資料)。
時間戳
HBase 中通過row和columns確定的為一個存貯單元稱為cell。每個 cell都儲存著同一份資料的多個版本。版本通過時間戳來索引。時間戳的型別是 64位整型。時間戳可以由hbase(在資料寫入時自動 )賦值,此時時間戳是精確到毫秒的當前系統時間。時間戳也可以由客戶顯式賦值。如果應用程式要避免資料版本衝突,就必須自己生成具有唯一性的時間戳。每個 cell中,不同版本的資料按照時間倒序排序,即最新的資料排在最前面。
為了避免資料存在過多版本造成的的管理 (包括存貯和索引)負擔,hbase提供了兩種資料版本回收方式。一是儲存資料的最後n個版本,二是儲存最近一段時間內的版本(比如最近七天)。使用者可以針對每個列族進行設定。
Cell
由{row key, column(= + ), version} 唯一確定的單元。cell中的資料是沒有型別的,全部是位元組碼形式存貯。
物理儲存
1 已經提到過,Table中的所有行都按照row key的字典序排列。
2 Table 在行的方向上分割為多個Hregion。
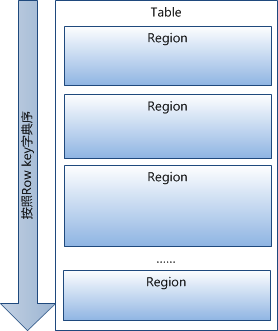
3 region按大小分割的,每個表一開始只有一個region,隨著資料不斷插入表,region不斷增大,當增大到一個閥值的時候,Hregion就會等分會兩個新的Hregion。當table中的行不斷增多,就會有越來越多的Hregion。
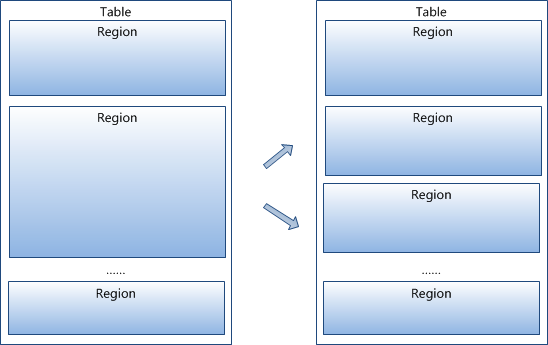
4 HRegion是Hbase中分散式儲存和負載均衡的最小單元。最小單元就表示不同的Hregion可以分佈在不同的HRegion server上。但一個Hregion是不會拆分到多個server上的。
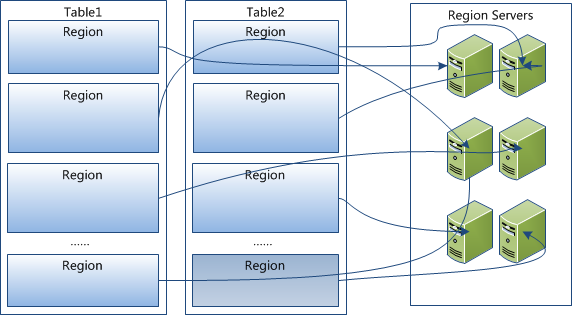
5 HRegion雖然是分散式儲存的最小單元,但並不是儲存的最小單元。
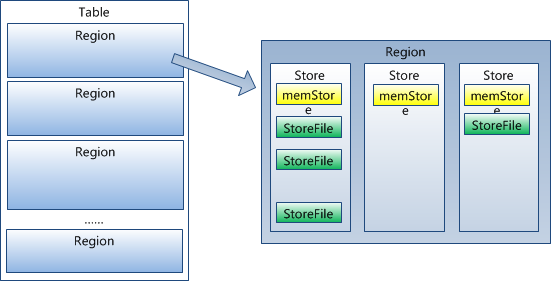
事實上,HRegion由一個或者多個Store組成,每個store儲存一個columns family。
每個Strore又由一個memStore和0至多個StoreFile組成。如圖:
StoreFile以HFile格式儲存在HDFS上。
HFile的格式為:
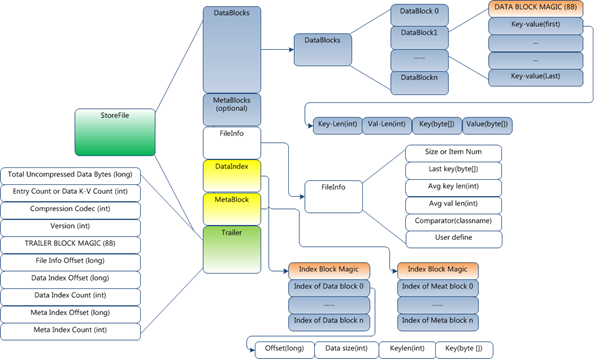
HFile分為六個部分:
Data Block 段–儲存表中的資料,這部分可以被壓縮
Meta Block 段 (可選的)–儲存使用者自定義的kv對,可以被壓縮。
File Info 段–Hfile的元資訊,不被壓縮,使用者也可以在這一部分新增自己的元資訊。
Data Block Index 段–Data Block的索引。每條索引的key是被索引的block的第一條記錄的key。
Meta Block Index段 (可選的)–Meta Block的索引。
Trailer– 這一段是定長的。儲存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer儲存了每個段的起始位置(段的Magic Number用來做安全check),然後,DataBlock Index會被讀取到記憶體中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從記憶體中找到key所在的block,通過一次磁碟io將整個 block讀取到記憶體中,再找到需要的key。DataBlock Index採用LRU機制淘汰。
HFile的Data Block,Meta Block通常採用壓縮方式儲存,壓縮之後可以大大減少網路IO和磁碟IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮。
目標Hfile的壓縮支援兩種方式:Gzip,Lzo。
shell
進入hbase shell console
$HBASE_HOME/bin/hbase shell
如果有kerberos認證,需要事先使用相應的keytab進行一下認證(使用kinit命令),認證成功之後再使用hbase shell進入可以使用whoami命令可檢視當前使用者
hbase(main)> whoami
表的管理
1)檢視有哪些表
hbase(main)> list
使用exists 命令驗證表是否被刪除。
hbase(main)> exists 'test'
Table test does not exist
2)建立表
# 語法:create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
# 例如:建立表t1,有兩個column family:f1,f2,且版本數均為2
hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
3)刪除表
分兩步:首先disable,然後drop
例如:刪除表t1
hbase(main)> disable 't1'
hbase(main)> drop 't1'
4)查看錶的結構
# 語法:describe <table>
# 例如:查看錶t1的結構
hbase(main)> describe 't1'
5)修改表結構
修改表結構必須先disable
新增列族
# 語法:alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
# 例如:修改表t1的cf的TTL為180天
hbase(main)> disable 't1'
hbase(main)> alter 't1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> alter 't1','body1','meta1'
hbase(main)> enable 't1'
刪除列族
hbase> alter 'table name', 'delete' => 'column family'
許可權管理
1)分配許可權
# 語法 : grant <user> <permissions> <table> <column family> <column qualifier> 引數後面用逗號分隔
# 許可權用五個字母表示: "RWXCA".
# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
# 例如,給使用者'luanpeng'分配對錶t1有讀寫的許可權,
hbase(main)> grant 'luanpeng','RW','t1'
2)檢視許可權
# 語法:user_permission <table>
# 例如,查看錶t1的許可權列表
hbase(main)> user_permission 't1'
3)收回許可權
# 與分配許可權類似,語法:revoke <user> <table> <column family> <column qualifier>
# 例如,收回luanpeng使用者在表t1上的許可權
hbase(main)> revoke 'luanpeng','t1'
表資料的增刪改查
1)新增資料
# 語法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
# 例如:給表t1的新增一行記錄:rowkey是rowkey001,family name是f1,column name是col1,value是value01,timestamp:系統預設
hbase(main)> put 't1','rowkey001','f1:col1','value01'
用法比較單一。
2)查詢資料
a)查詢某行記錄
# 語法:get <table>,<rowkey>,[<family:column>,....]
# 例如:查詢表t1,rowkey001中的f1下的col1的值
hbase(main)> get 't1','rowkey001', 'f1:col1'
# 或者:
hbase(main)> get 't1','rowkey001', {COLUMN=>'f1:col1'}
# 查詢表t1,rowke002中的f1下的所有列值
hbase(main)> get 't1','rowkey001'
b)掃描表
# 語法:scan <table>, {COLUMNS => [ <family:column>,.... ], LIMIT => num}
# 另外,還可以新增STARTROW、TIMERANGE和FITLER等高階功能
# 例如:掃描表t1的前5條資料
hbase(main)> scan 't1',{LIMIT=>5}
c)查詢表中的資料行數
# 語法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
# INTERVAL設定多少行顯示一次及對應的rowkey,預設1000;CACHE每次去取的快取區大小,預設是10,調整該引數可提高查詢速度
# 例如,查詢表t1中的行數,每100條顯示一次,快取區為500
hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}
3)刪除資料
a )刪除行中的某個列值
# 語法:delete <table>, <rowkey>, <family:column> , <timestamp>,必須指定列名
# 例如:刪除表t1,rowkey001中的f1:col1的資料
hbase(main)> delete 't1','rowkey001','f1:col1'
注:將刪除改行f1:col1列所有版本的資料
b )刪除行
# 語法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,刪除整行資料
# 例如:刪除表t1,rowk001的資料
hbase(main)> deleteall 't1','rowkey001'
c)刪除表中的所有資料
# 語法: truncate <table>
# 其具體過程是:disable table -> drop table -> create table
# 例如:刪除表t1的所有資料
hbase(main)> truncate 't1'
Region管理
1)移動region
# 語法:move 'encodeRegionName', 'ServerName'
# encodeRegionName指的regioName後面的編碼,ServerName指的是master-status的Region Servers列表
# 示例
hbase(main)>move '4343995a58be8e5bbc739af1e91cd72d', 'db-41.xxx.xxx.org,60020,1390274516739'
2)開啟/關閉region
# 語法:balance_switch true|false
hbase(main)> balance_switch
3)手動split
# 語法:split 'regionName', 'splitKey'
4)手動觸發major compaction
#語法:
#Compact all regions in a table:
#hbase> major_compact 't1'
#Compact an entire region:
#hbase> major_compact 'r1'
#Compact a single column family within a region:
#hbase> major_compact 'r1', 'c1'
#Compact a single column family within a table:
#hbase> major_compact 't1', 'c1'
配置管理及節點重啟
1)修改hdfs配置
hdfs配置位置:/etc/hadoop/conf
# 同步hdfs配置
cat /home/hadoop/slaves|xargs -i -t scp /etc/hadoop/conf/hdfs-site.xml [email protected]{}:/etc/hadoop/conf/hdfs-site.xml
#關閉:
cat /home/hadoop/slaves|xargs -i -t ssh [email protected]{} "sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf stop datanode"
#啟動:
cat /home/hadoop/slaves|xargs -i -t ssh [email protected]{} "sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf start datanode"
2)修改hbase配置
hbase配置位置:/home/hadoop/hbase
# 同步hbase配置
cat /home/hadoop/hbase/conf/regionservers|xargs -i -t scp /home/hadoop/hbase/conf/hbase-site.xml [email protected]{}:/home/hadoop/hbase/conf/hbase-site.xml
# graceful重啟
cd ~/hbase
bin/graceful_stop.sh --restart --reload --debug inspurXXX.xxx.xxx.org
hbase shell 指令碼
編寫一個文字檔案hbasedemo.txt:
disable 'table1'
drop 'table1'
create 'table1', 'column_family1','column_family2'
list 'table1'
put 'table1', 'row_key1', 'column_family1:col1', 'value1'
put 'table1', 'row_key2', 'column_family1:col2', 'value2'
put 'table1', 'row_key3', 'column_family2:col3', 'value3'
put 'table1', 'row_key4', 'column_family2:col4', 'value4'
scan 'table1'
scan 'table1',{LIMIT=>5}
get 'table1', 'row_key1'
get 'table1','row_key1', 'column_family1:col1'
count 'table1'
disable 'table1'
alter 'table1',NAME=>'column_family3'
alter 'table1','delete'=>'column_family3'
enable 'table1'
describe 'table1'
grant 'root','RW','table1'
user_permission 'table1'
delete 'table1','row_key1','column_family1:col1'
deleteall 'table1','row_key1'
truncate 'table1'
在HBase shell中執行這個指令碼
hbase shell hbasedemo.txt
需要注意的是,如果編寫的txt檔案中沒有exit這條命令的話,當指令碼執行完成後,會停留在hbase shell的介面中,如果有exit命令的話,就會退出到系統shell中。
相關推薦
Hbase資料結構+基本語法
全棧工程師開發手冊 (作者:欒鵬) HBase中的表一般有這樣的特點: 1 大:一個表可以有上億行,上百萬列 2 面向列:面向列(族)的儲存和許可權控制,列(族)獨立檢索。 3 稀疏:對於為空(null)的列,並不佔用儲存空間,因此,表可以設計的非常稀疏。
HBase資料結構與基本語法詳解
HBase中的表一般有這樣的特點: 1 大:一個表可以有上億行,上百萬列 2 面向列:面向列(族)的儲存和許可權控制,列(族)獨立檢索。 3 稀疏:對於為空(null)的列,並不佔用儲存空間,因此,表可以設計的非常稀疏。 邏輯檢視 HBase以表的形式儲存資料。表有行和列組成。列劃分為若干個列
資料結構作業1-資料結構基本概念
1-1 抽象資料型別中基本操作的定義與具體實現有關。 (1分) [ ] T [x] F 1-2 若用連結串列來表示一個線性表,則表中元素的地址一定是連續的。 (1分) [ ] T [x] F 2-1 在決定選取何種儲存結構時,一般不考慮()。 (2分) [ ] A.
java資料結構基本框架
二.樹。 1.樹的內部類 設一個內部類Node<E>,作用是將節點抽象化。 (1)屬性:節點中包含E element,Node<E> leftChild,Node<E> rightChild(或Node<E>nextSibling); (2)構造方法:兩
05.資料的基本語法 Record
00.操作表中的資料,對資料進行增,刪,改,查 01. 增,向表中新增資料,紀錄 輸入命令: insert employee values(null,'liu','male','[e
資料結構--基本資料結構
1.基本資料型別區分如下: 2.線性表: 2.1順序表: 元素在記憶體之中,是連續順序儲存的,在記憶體中劃分的是一塊連續的區域 &n
資料結構淺析(一):資料結構基本概念
轉載自https://m.meiwen.com.cn/subject/kzgvhttx.html 首先會有個疑問,什麼是資料結構呢? 資料結構(data structure),可以概括為是互相之間存在一種或多種特定關係的資料元素的集合。 開篇配圖
HBase資料結構
一、NameSpace 名稱空間是類似於關係資料庫系統中的資料庫的概念,他其實是表的邏輯分組。這種抽象為多租戶相關功能奠定了基礎。 名稱空間包含以下四點 (1) 配額管理- 限制名稱空間可以使用的資源量(即區域,表)。 (2) 許可權管理 - 為租戶提供另一級別的安
《傳智播客-資料結構》01 資料結構基本概念 2018/10/14
1.資料結構概念 1.1 資料結構的起源 資料結構主要用於研究非數值計算程式問題中的操作物件以及它們之間的關係,不是研究複雜的演算法 1.2基本概念 資料--程式的操作物件,用於描述客觀事物(int a ,int b) 資料的特點: 1、可輸入到計算機內 2、可
資料結構-基本概念學習筆記
1.1 資料(資訊的載體); 資料元素(資料的基本單位,由若干資料項組成); 資料物件(相同性質的資料元素的集合); 資料型別(原子、結構、抽象); 抽象資料型別(ADT,通常有資料物件,資料關係,基本操作來表示); 資料結構(
第一章作業1-資料結構基本概念
一、判斷題 1、若用連結串列來表示一個線性表,則表中元素的地址一定是連續的 F 鏈式儲存結構的地址不需要連續 2、資料的邏輯結構是指資料的各資料項之間的邏輯關係 F 資料的邏輯結構是指資料的各資料元素之間的邏輯關係 3、抽象資料型別中基
資料結構---基本資料結構---連結串列---雙向連結串列
1、動態集合 2、每個元素都是一個物件,每個物件中都有一個關鍵字key和兩個指標pre、next,物件中還可以包含其他 衛星資料; 3、若一個元素為x,x.pre=NIL,則該元素為連結串列的第一個元素,稱為 連結串列的頭; 若一個元素為x,x.next=NIL,則
1.資料結構-基本概念
資料:資訊的載體,是計算機程式加工的原料 資料元素:資料的基本單位,一般來說,能獨立、完整地描述問題世界的一切實體都是資料元素 資料結構:相互之間存在一定關係的資料元素的集合。資料結構又分為邏輯結構和儲存結構。 邏輯結構:資料元素之間的關聯方式、鄰接關係,有以下4中邏輯
資料結構專題——那些難以理解的資料結構基本概念
不知有沒有人和博主一樣,在上大學的時候最頭疼的一門課就是資料結構與演算法了,其中枯燥的概念、冗長的虛擬碼都讓博主昏昏欲睡。 尤其是嚴大媽在《資料結構》中開篇講述的資料結構、資料型別與抽象資料型別的概念,讓博主完美地將這三個概念混淆了很久(這裡沒有黑嚴大媽的意思
HBase資料結構(讀書筆記 )
背景: 最近在做一些跟大資料相關的東西,涉及到資料的儲存和分析,考慮各個方面,選擇使用HBase進行儲存,使用原生Java API進行資料分析,之後會陸續寫一系列來說明最近做的東西,給像我這樣未
資料結構基本定義 C/ C++
轉:http://blog.csdn.net/xinianbuxiu/article/details/53166608 一、何為資料結構: 資料結構是一門研究非數值計算的程式設計問題中的操作物件,以及它們之間的關係和操作等相關問題的學科。 基本概念與術語: 資料
Lua 基本語法 資料結構
Lua 程式程式碼保持到一個以 lua 結尾的檔案 print("Hello World!") 註釋 單行註釋 -- 多行註釋 --[[ 多行註釋 多行註釋 --]] 標示符 標示符以一個字母 A 到 Z 或 a 到 z 或下劃線 _ 開頭後加上0個或多個字母,
Lua 基本語法 資料結構
Lua 程式程式碼保持到一個以 lua 結尾的檔案 print("Hello World!") 註釋 單行註釋 -- 多行註釋 --[[ 多行註釋 多行註釋 --]] 標示符 標示符以一個字母 A 到 Z 或 a 到 z 或下劃線 _ 開頭後加上0個或多
數據結構-列表基本語法
pri times 實現 但是 ted src 一次 開始 元素 Python 列表基本語法 1) python列表是python 內置的數據結構對象之一, 相當於數組 2) 列表是用"[]"包含,內有任意的數據對象,每一個數據對象 以 , 分割,每個數據對像稱之為元素
Python基本語法之資料型別
Python資料型別 基本資料型別 資料型別 說明 Numbers int 有符號整型 long 長整型[也可以代表八