
百度搜索高階指令教程

寫在前面
最近正在學習SEO相關的知識,對於從事SEO的開發人員來說學會一些高階搜尋指令是很有必要的,對於非專業人員來說,會一些高階搜尋指令對你在茫茫網際網路上尋找到你想要的資訊也是很有幫助的,如果不想使用指令也可以使用百度高階搜尋,高階搜尋地址:http://www.baidu.com/gaoji/advanced.html
原文連結:http://www.zhaochao.net/index.php/2016/03/06/16/
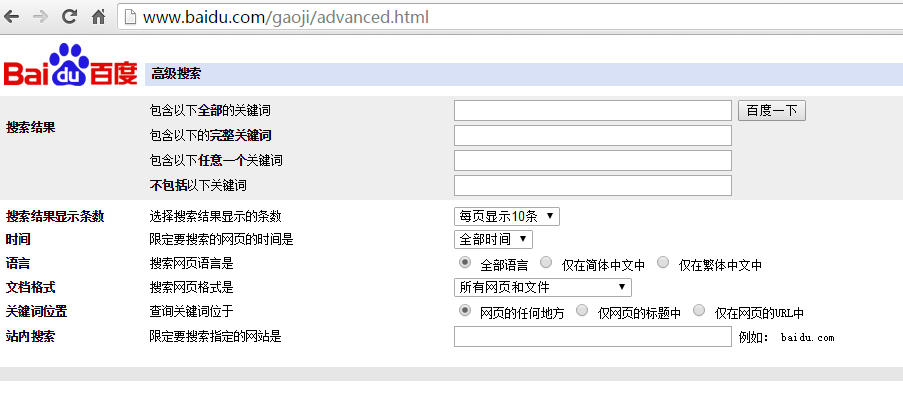
本高階搜尋指令就是從以上頁面中總結出來的,由於能力有限,有不足之處請大神補充,歡迎吐槽!對於不同的搜尋引擎指令可能會有所不同,本指令只在百度搜索引擎中測試過,其它搜尋引擎大部分應該也是適用的,歡迎測試。
#完全匹配指令雙引號
| 12 | "西湖好山好水" |
比如在百度搜索 “西湖好山好水”, 首先這個詞可以分解成 西湖、好山、好水、好山好水、西湖好山好水 對於百度搜索引擎來說只要是出現上面五個任意詞的內容都有可能出現在結果中,如果加上雙引號就是告訴百度,這個詞是一個完整的詞,不需要再分詞的,所以結果中只會出現如西湖好山好水相關的內容。
多個關鍵字組合
| 12 | (杭州|西湖) |
如果想搜尋多個關鍵詞可以使用“|”指令,比如我想搜尋結果中有“西湖”或者“杭州”則可以在百度中輸入 (西湖 | 杭州)
排除關鍵詞 減號
| 12 | (杭州|西湖)-(團購) |
當我們搜尋杭州西湖時,可能會出現很多團購廣告,我們不想看到有團購的內容,則可以用“-”來排除含有團購的內容
值得注意的是-號前要有個空格,-號後面不要空格
關鍵字在標題中
| 12 | title:((杭州|西湖)-(團購)) |
title|intitle這個比較好理解,就是搜尋的關鍵詞在網頁的標題中出現了
關鍵字在URL中
| 12 | inurl:((杭州|西湖)-(團購)) |
inurl 這個和title比較像,就是搜尋的關鍵詞在網頁的url出現了
站內搜尋
| 12 | site:(zjol.com.cn)title:((杭州|西湖)-(團購)) |
想指定某個網站,只看這個網站的內容
檔案搜尋
| 12 | filetype:doc site:(baidu.com)title:((杭州|西湖)-(團購)) |
filetype:doc|filetype:pdf|filetype:xls|filetype:ppt|filetype:rtf可以限定要搜尋的檔案格式
組合搜尋
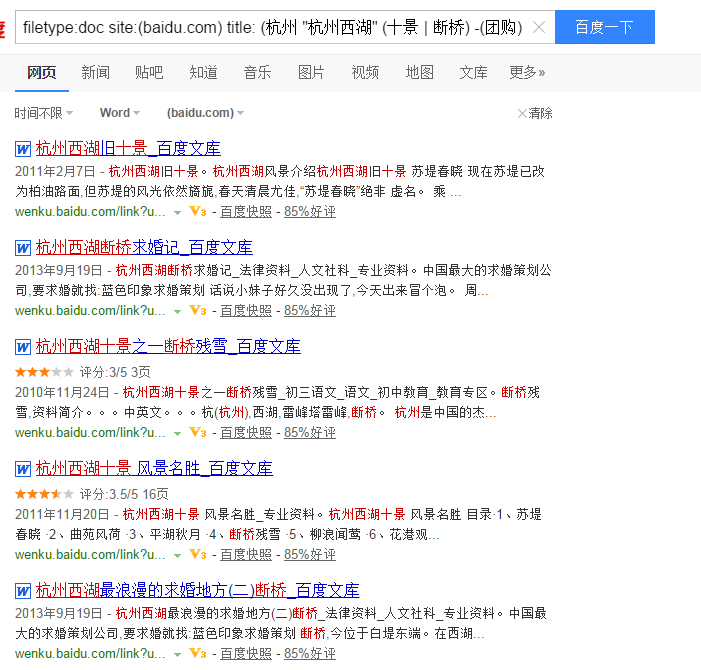
| 12 | filetype:doc site:(baidu.com)title:(杭州"杭州西湖"(十景|斷橋)-(團購)) |
以上所有命令都可以組合搜尋
相關推薦
百度搜索高階指令教程
寫在前面最近正在學習SEO相關的知識,對於從事SEO的開發人員來說學會一些高階搜尋指令是很有必要的,對於非專業人員來說,會一些高階搜尋指令對你在茫茫網際網路上尋找到你想要的資訊也是很有幫助的,如果不想使用指令也可以使用百度高階搜尋,高階搜尋地址:http://www.baid
百度搜索高階搜尋指令和引數
最近聽了一節關於搜尋網路資源的課程,感覺打開了一扇新世界的大門,第一次瞭解到了關於百度搜索的一些騷操作(可能是敝人太過孤陋寡聞,讓各位見笑了~),在這裡記錄一下一些常用的搜尋指令和引數,對這方面沒有過了解的小夥伴可以漲波姿勢。 intitle 搜尋範
百度搜索高階命令
高階搜尋 問題一: 如何在指定站點內搜尋 關鍵字: 指定站點內 解決:在關鍵字後 +site: 站點 舉例: 注意:中間有空格,網址不要加上 http 的使用。 問題二:
百度搜索高階語法技巧
一般常用的指令如下: 1. 查詢網頁收錄:site: 如 site:csdn.net 注意不好包含協議,如http、或者https。 2. 查詢 特定站點 伊思諾 site:csdn.net 3. 要求URL中包含特定字元,如blog的指令如下 伊思諾 inurl:bl
百度搜索引擎的搜尋高階語法及應用
百度搜索高階語法及應用 把搜尋範圍限定在網頁標題中 —— intitle -網頁標題通常是對網頁內容提綱挈領式的歸納。把查詢內容範圍限定在網頁標題中,有時能獲得良好的效果。 -應用示例:新
C# 百度搜索結果xpath分析
als 接收數據 har rim resp inner ets webclient containe using System; using System.Collections.Generic; using System.IO; using System.Linq; u
Python實驗:百度搜索關鍵字自動打開相關URL
python實驗:百度搜索關鍵字自動打開相關url#! python # coding: utf-8 # python實現百度搜索關鍵字,並依次用瀏覽器打開前五個搜索結果 ## ##Beautiful Soup 是一個模塊,用於從HTML 頁面中提取信息(用於這個目的時,它比正則表達式好很多)。Beautif
python實現百度搜索
python 爬蟲 mechanize 瀏覽器 利用Python mechanize模塊模擬瀏覽器實現百度搜索# -*- coding:utf-8 -*- import mechanize import sys reload(sys) sys.setdefaultencoding(‘utf8‘
百度搜索建議API
建議 amp nbsp api cti 函數 等價 回調函數 自定義函數 1.直接返回json數據 http://suggestion.baidu.com/?wd=關鍵詞&action=opensearch 2.json數據當做回調函數的參數傳回來http://
python爬取百度搜索圖片
知乎 需要 with 異常 mage 不足 request height adr 在之前通過爬取貼吧圖片有了一點經驗,先根據之前經驗再次爬取百度搜索界面圖片 廢話不說,先上代碼 #!/usr/bin/env python # -*- coding: utf-8 -*- #
python爬取百度搜索結果ur匯總
百度搜索 sta attr amp end rom range 百度 篩選 寫了兩篇之後,我覺得關於爬蟲,重點還是分析過程 分析些什麽呢: 1)首先明確自己要爬取的目標 比如這次我們需要爬取的是使用百度搜索之後所有出來的url結果 2)分析手動進行的獲取目標的過程,以便
我的第一個自動化腳本(python)----百度搜索
expect style 目錄 .exe nbsp com 自動 其他人 其他 這是一個純小白胡說八道的個人總結,如果有人看到什麽不對的,歡迎批評指正 博客園開通了很久,一直不知道該怎麽去寫,總覺得自己要寫的東西都是別人已經寫過的,我再去寫就是在重復之前人所說,今天去面試和
高仿百度搜索引擎
ucc return 回調函數 else 上下 about inpu click eat 這是百度搜索 HTML <!DOCTYPE html> <html lang="en"> <head> <meta charset=
python實現簡單的百度搜索
python 百度 爬蟲#!/usr/bin/python # coding=utf-8 import urllib import urllib2 #實現百度關鍵字查詢的小例子 #定義基礎url url = "http://www.baidu.com/s?" #定義請求頭信息 headers = {"U
js仿百度搜索框
eat ucc txt tex text str jquer nbsp erro 1.js仿百度搜索框 <!DOCTYPE html> <html> <head> <meta charset="utf-8">
百度搜索將推出“驚雷算法”打擊網站刷點擊作弊行為
百度搜索 驚雷算法百度站長平臺11月剛改版為百度搜索資源平臺,各位站長應該還記得“閃電算法”吧?上個月的閃電讓各位站長吃的消嗎?而今天,就在今天淩晨百度搜索資源平臺發布新的算法預告“驚雷算法”! 公告原文如下:百度搜索推出驚雷算法 嚴厲打擊刷點擊作弊行為發布日期:2017-11-20 00:00:00百度搜索
Ruby用百度搜索爬蟲
https each span 分享圖片 百度 .get get請求 puts 分享 Ruby用百度搜索爬蟲 博主ruby學得斷斷續續,打算寫一個有點用的小程序娛樂一下,打算用ruby通過百度通道爬取網絡信息。 第三方庫準備 mechanize:比較方便地處理網絡請求,類
【專家專欄】淺談百度搜索排序
百度搜索排序站長圈經常聊的話題中,怎麽提升百度排序一定是排名TOP3的問題,那百度排序的原理是什麽,該怎麽提升,今天給大家分享一下經驗心得。關於排序這件事兒對於像百度搜索來說,並沒有排序這一說法,搜索引擎認為排序是在特定的關鍵詞下網站內容的位置,而關鍵詞是由用戶搜索產生,如果一個關鍵詞沒有被搜索,也就意味著這
利用百度搜索結果爬取郵箱
.... sheet pro 編輯部 pic exception exc gecko 正則表達 幫同學做一個關於爬取教授郵箱的任務,在百度搜索中輸入教授的名字+長江學者+郵箱,爬取並篩選每個教授的郵箱,最後把郵箱信息寫入到Excel表中:--爬取結果爭取率大概在50%-60
Alfred 3 如何設置默認搜索引擎(以百度搜索為例)
今天 alfred width city search left 屏幕 由於 -o 今天,由於收到UDACITY的微信新聞,關於使用Alfred 工具的介紹,所以一時興起,決定再把Alfred研究一下,以後再慢慢適應使用Alfred,結果花了近2個小時才總算把Alfred默