
Hadoop1中Task執行過程
當我們編寫一個Mapreduce的作業時候,只需要實現map()和reduce()兩個函式就可以。
其中map階段大概可以劃分 read 、map、collect、spill和combine五個階段 。reduce階段可以劃分shuffle、merge、sort、reduce和write五個階段。
一個應用程式被劃分成map和reduce兩個計算階段,它們分別有一個或者多個map task或者reduce task組成。其中,每個map task 處理輸入資料集合中的一片資料(InputSplit),並將產生的若干個資料片段寫到本地磁碟上,而reduce task則從每個map task 上遠端拷貝相應的資料片段,經分組聚集和歸約後,將結果寫入到hdfs上作為最終結果,總體來看,map task與 reduce task之間的資料採用了pull模型。為了能夠容錯,map task將中間計算結果存放到本地磁碟中,而reduce task則通過http請求從各個map task端拖取相應的輸入資料。為了更好的支援大量reduce task併發從map task 端拷貝資料,hadoop採用了jetty server作為http server處理併發資料讀請求。
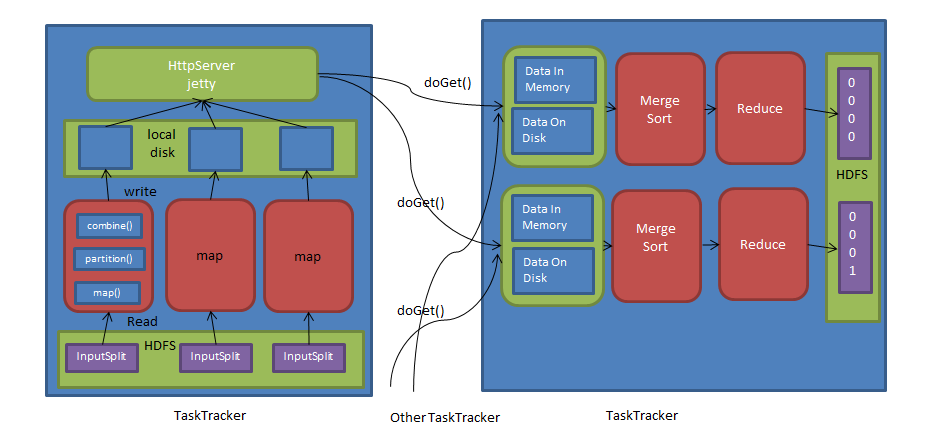
對於map task而言,它的執行過程概述為:首先,通過使用者提交的inputformat將對應的inputsplit解析成一系列key/value,並依此交給使用者編寫的map()函式處理;接著按照指定的partitioner對資料分片,以確定每個key/value將交給哪個reduce task處理;之後將資料交給使用者定義的combiner進行一次本地規約(如果使用者沒有定義直接跳過);最後將處理結果儲存到本地磁碟上。
對於reduce task而言,由於它的輸入資料來自各個map task,因此首先需要通過http 請求從各個已經執行完成的map task上拷貝對應的資料分片,待所有資料拷貝完成後,在以key為關鍵字對所有資料進行排序,通過排序,key相同的記錄聚集到一起形成若干分組,然後將每組資料交給使用者編寫的reduce()函式處理,並將資料結果直接寫到hdfs上作為最終輸出結果。
IFile儲存格式
考慮到map task的輸出檔案需要寫到本地磁碟上並被reduce task遠端拷貝,為儘可能減少資料量以避免不必要的磁碟和網路開銷,hadoop內部實現了支援行壓縮的資料儲存格式:IFile。
Map task中間輸出結果和reduce task遠端拷貝結果被存放在IFile格式的磁碟檔案或者記憶體中。為了儘可能減少map task寫入磁碟資料量和跨網路傳輸資料量,IFile支援按行壓縮資料記錄,當前hadoop提供了Zlib(預設壓縮方式)、BZip2等壓縮演算法。如果使用者想啟用資料壓縮功能,則需為作業新增以下兩個配置選項。
mapred.compress.map.output:是否支援中間輸出結果壓縮,預設是false。
mapred.map.output.compression.codec:壓縮器(預設是基於Zlib演算法的壓縮器DefaultCodec)。任何一個壓縮器需要實現CompressionCodec介面提供壓縮輸出流和解壓輸入流
一旦啟用了壓縮機制,hadoop會為每條記錄的key和value值進行壓縮。IFile定義的檔案格式非常簡單,整個檔案順次儲存資料記錄,每條資料記錄格式為:<key-len,value-len,key,value>
排序
排序是mapreduce框架中最重要的操作之一,map task和reduce task均會對資料進行排序,該操作屬於hadoop預設行為,任何應用程式中的資料均會被排序,而不管邏輯上是否需要。
對於map task,它會將處理的結果暫時放在一個緩衝區中,當緩衝區使用率達到一定閥值後,再對緩衝區的資料進行一次排序,並將這些有序資料以IFile檔案形式寫到磁碟上,而當資料處理完畢後,它會對磁碟上所有的檔案進行一次合併,以將這些檔案合併成一個大的有序檔案。
對於reduce task而言,它從每個map task上遠端拷貝相應的資料檔案,如果檔案大小超過一定閥值,則放到磁碟上,否則放到記憶體中。如果磁碟上檔案數目達到一定閥值,則進行一次合併以生成一個更大檔案。如果記憶體中檔案大小或者數目超過一定閥值,則進行一次合併後將資料寫到磁碟中。當所有資料拷貝完畢後,reduce task統一對記憶體和磁碟上的所有資料進行一次合併。
快速排序:快速排序是應用最廣泛的排序之一,它的基本思想是,選擇序列中的一個元素作為樞軸,將小於樞軸的元素放在左邊,將大於樞軸的元素放在右邊,針對左右兩個子序列重複此過程,直到序列為空或者只剩下一個元素。
樞軸選擇:樞軸選擇的好壞影響快速排序的效能,而最壞的情況是劃分過程中使用產生兩個極端不對稱的子序列(一個長度為1,另一個長度為n-1),此時排序演算法複雜度將增為O(N*N)。減少出現劃分嚴重不對稱的可能性,hadoop將序列的首尾和中間元素中的中位數作為樞軸。
子序列劃分方法:hadoop使用了兩個索引i和j分別從左右兩端進行掃描序列,並讓索引i掃描到大於等於樞軸的元素停止,索引j掃描到小於等於樞軸的元素停止,然後交換兩個元素,重複這個過程直到兩個索引相遇。
對相同元素的優化:在每次劃分子序列時,將與軸樞軸相同的元素集中存放到中間位置,讓它們不在參與後續遞迴處理,即將序列劃分成三部分:小於樞軸、等於樞軸、大於樞軸。
減少遞迴次數:當子序列中元素數目小於13時,直接使用插入排序演算法,不再繼續遞迴。
優先佇列:
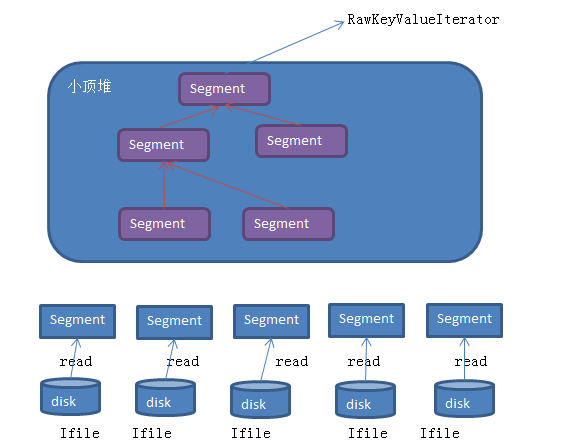
檔案歸併有類merger完成,它要求待排序物件需要是segment例項化物件。segment是對磁碟和記憶體中的IFile格式檔案的抽象。它具有類似於迭代器的功能,可迭代器讀取IFile檔案中的key/value。
merger採用了多輪遞迴合併的方式,每輪選取最小的前io.sort.factor(預設是10)個檔案進行合併,並將產生的檔案重新加入待合併列表中,知道剩下的檔案數目小於io.sort.factor個,此時,它會返回指向由這些檔案組成的小頂堆的迭代器。
merger採用了小頂堆實現,進而可將檔案合併過程看作一個不斷建堆的過程,
建堆->取堆頂元素->重新建堆->取堆頂元素…..
Reporter
所有task需週期性向tasktracker彙報最新進度和計數器值,而這正是有reporter元件實現的,在map/reduce task中,taskreporter類實現了Reporter介面,並且以現場形式啟動,TaskReporter彙報的資訊中包含兩部分:任務執行進度和任務計數器值。
任務執行進度:
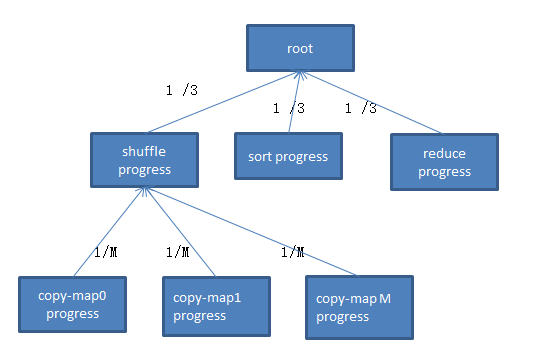
任務執行進度資訊被封裝到類Progress中,且每個progress例項以樹的形式存在。hadoop採用了簡單的線性模型計算每個階段的進度值:如果一個大階段可被分解成若干個子階段,則可將大階段看作一棵樹的父節點,而子階段可看作父節點對應的子節點,且大階段的進度值可被均攤到各個子階段中;如果一個階段不可再分解,則該階段進度值可表示成已讀取資料量的比例。
對於map task而言,它作為一個大階段不可再分解,為了簡便,我們直接將已讀取資料量佔總資料量的比例作為任務當前執行進度值
對於 reducetask 而言,我們可將其分解成三個階段:shuffle、sort和reduce,每個階段佔任務總進度的1/3,考慮到在shuffle階段,reduce task需要從M(M 為map task 數目)個map task上讀取一片資料,因此,可被分解成M個階段,每個階段佔shuffle進度的1/M,可以看圖所示
對於TaskReporter執行緒而言,它並不會總是每隔一段時間彙報進度和計數器值,而是僅當發現以下兩種情況之一時才會彙報:
1、任務執行進度發生變化
2、任務的某個計數器值發生變化
在某個時間間隔內,如果任務執行進度和計數器值均未發生變化,則task只會簡單地通過呼叫RPC函式ping探測taskTracker認為它處於懸掛狀態,直接將其殺掉,為了防止某條記錄因處理時間過長導致被殺,使用者可採用以下兩種方式:
1、每隔一段時間呼叫一次TaskReporter.progress()函式,以告訴Tasktracker自己仍然活著,
2、增大任務超時引數mapred.task.timeout(預設是10min)對應的值
任務計數器
任務計數器(counter)是hadoop提供的,用於實現跟蹤任務執行進度的全域性計數功能,使用者可在自己的應用程式中新增計數器,任務計數器有2部分組成<name.value>,其中name表示計數器的名稱,value表示計數器值(long型別)。計數器通常以組為單位管理,hadoop規定一個作業最多包含120個計數器(可通過引數mapreduce.job.counters.limit設定),50個計數器組。
對於同一個任務而言,所有任務包含的計數器相同,每個任務更新自己的計數器值,然後彙報給Tasktracker,並由Tasktracker通過心跳彙報給jobtracker,最後由jobtracker以作業為單位對所有計數器進行累加,作業的計數器分為兩類,Mapreduce內建計數器和使用者自定義計數器
1、mapreduce內建計數器
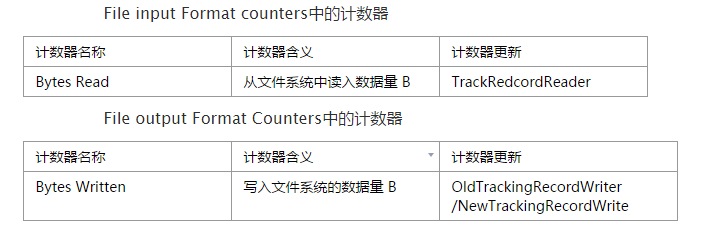
mapreduce框架內部為每個任務添加了三個計數器組,分別位於File input Format counters,File output Format Counters和map-reduce Framework中,他們包含的計數器為
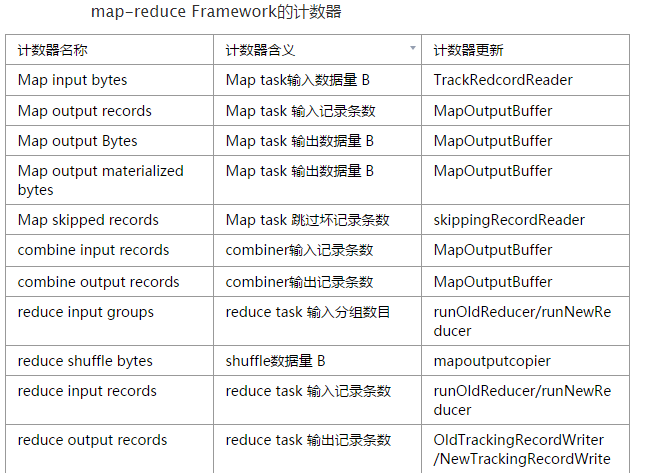
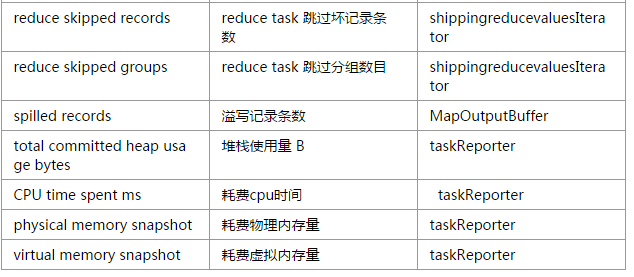
使用者自定義計數器
不同的程式設計介面,定義計數器的方式不同,其中主要介紹一下java的
hadoop為java應用程式提供了兩種訪問和使用計數器的方式:使用列舉型別和字串型別,如果採用列舉型別,則計數器預設名稱是列舉型別的java完全限定類名,這使得計數器名稱的可讀性很差,為此,hadoop提供了基於資源捆綁修改計數器顯示名稱的方法:以java列舉型別為名稱建立一個屬性檔案,在該屬性檔案中,“counterGroupName”屬性“欄位型別.name”,屬性值即為該計數器的顯示名稱。比如類task中定義了大量表示計數器的列舉型別,而這些計數器的顯示名稱被統一放到同目錄下的屬性檔案task_counter.properties中,
counterGroupName=map-reduce framework
Map_INPUT_RECORDS.name=map input records
...如果採用字串型別,則使用者可以直接在計數器API中指定計數器組,計數器名稱和計數器值。基於列舉型別的字串型別的計數器PAI如下
public abstract void incrCounter(Enum<?> key,long amount);
public abstract void incrCounter(String group,String counter,long amout);相關推薦
Hadoop1中Task執行過程
當我們編寫一個Mapreduce的作業時候,只需要實現map()和reduce()兩個函式就可以。 其中map階段大概可以劃分 read 、map、collect、spill和combine五個階段 。reduce階段可以劃分shuffle、merge、so
php嵌入到html中的執行過程
兩種 js代碼 瀏覽器 php代碼 技術 處理 htm img 解析 1. php嵌入到html中的執行過程? 當php功能模塊在處理一個php文件時,它只關心php代碼(使用php標簽包含的代碼),對於非php代碼,它會原樣輸出; 例如右圖代碼: php功
計算機指令在CPU中的執行過程(圖文版)
為了瞭解指令的大概流程,下面以加法指令做以說明(引用《計算機原理》)。 指令形式: ADD EA 該指令一個隱含的運算元存在累加器(AC)中,EA為另一個運算元在主存當中的有效地址。 該指令是把AC和EA的資料相加,最後把計算的和送回AC中,即AC+EA -> AC。
python中展示執行過程中圖片的程式碼
轉自:http://www.cnblogs.com/yinxiangnan-charles/p/5928689.htm 一:利用lmatplotlib第三方庫函式來畫圖片 import matplotlib as plt # plt中的方法來讀取圖片 image=plt
對迴圈中setTimeout執行過程的思考
題目 for (var i = 0; i < 5; i++) { setTimeout(function() { console.log(i); }, 1000 * i); } 答案 每隔一秒輸出5 分析 由於setT
資料庫中Explain 執行過程的檢視
因為最近看Hive ,Hive 其實就是MapReduce的封裝,基於一個統一的查詢分析層,通過SQL語句的方式對HDFS上的資料查詢進行查詢,統計和分析,這個過程是一個MR過程,我們如何能夠通過檢視執行sql的過程來檢視MR這個過程,從而做到後續的一些優化之類的。 使用E
Task執行過程分析5——ReduceTask內部實現
與MapTask一樣,ReduceTask也分為四種,即Job-setup Task,Job-cleanup Task,Task-cleanup Task和Reduce Task。本文重點介紹第四種——普通Reduce Task。 Reduce Task要從各
mysql中SQL執行過程詳解
mysql執行一個查詢的過程,到底做了些什麼: 客戶端傳送一條查詢給伺服器; 伺服器先
大話Spark(3)-一圖深入理解WordCount程式在Spark中的執行過程
本文以WordCount為例, 畫圖說明spark程式的執行過程 WordCount就是統計一段資料中每個單詞出現的次數, 例如hello spark hello you 這段文字中hello出現2次, spark出現1次, you出現1次. 先上完整程式碼: object WordCount {
AntCall Task:執行過程中呼叫並執行其他target
AntCall 任務的作用是允許在一個target的執行過程中呼叫並執行其他的target。例如,在打包專案前需要對專案進行編譯,那麼可以在打包專案的target中通過AntCall任務使得編譯的target先執行。當然這種情況也可以通過target間設定depends屬性來
C#調用SQL中存儲過程並用DataGridView顯示執行結果
exec char 登錄名 dataset type data comm and def //連接數據庫 SqlConnection con = new SqlConnection("server=服務器名稱;database=數據庫名稱;user id=登錄名;pwd=登
pip install 執行過程中遇到的各種問題
efault 就是 阿裏 pip安裝 clas aliyun blog key 新版 一、pip install 安裝指定版本的包 要用 pip 安裝指定版本的 Python 包,只需通過 == 操作符 指定。 pip install robotframework ==
生成器接受和返還功能在執行過程中的詳解
top exce ret one 代碼 stop ngx put rsa 1 import random 2 3 SENTENCES=[ 4 ‘How are you ?‘, 5 ‘Fine,thank you!‘, 6 ‘Nothi
Hive執行過程中出現Caused by : java.lang.ClassNotFoundException: org.cloudera.htrace.Trace的錯誤解決辦法(圖文詳解)
pre wid logs In 實用 過程 ase edit 微信 不多說,直接上幹貨! 問題詳情 如下 這個錯誤的意思是缺少 htrace-core-2.04.jar。 解決辦法:
多線程:子線程執行過程中調用主線程
ring this 方法 his tca error ren ESS string 直接在子線程中調用方法,線程的ID為3,通過Post則為1 執行結果: 2018-09-13 11:21:11:1735 : 主線程:1 2018-09-13 11:21:16:
(轉)Linux 中/etc/profile、~/.bash_profile 環境變量配置及執行過程
行修改 你在 關系 轉載 登錄用戶 後者 nbsp inux 第一個 環境變量是和Shell緊密相關的,用戶登錄系統後就啟動了一個Shell。對於Linux來說一般是bash,但也可以重新設定或切換到其它的 Shell。對於UNIX,可能是CShelll。環境變量是通過Sh
VS中設定逐過程執行屬性和運算子
在VS除錯程式碼的時候,想進入關鍵系或者屬性的具體實現的時候會彈出這個視窗 點選“是”之後,vs就直接跳過關鍵字,即使逐語句也無法進入具體實現,下次還是繼續彈出這個視窗。 點選“否”之後,再次除錯的時候就不會提示這個視窗,但是還是無法逐語句的進行除錯。 原因: VS在不知道
(轉)Linux 中/etc/profile、~/.bash_profile 環境變數配置及執行過程
環境變數是和Shell緊密相關的,使用者登入系統後就啟動了一個Shell。對於Linux來說一般是bash,但也可以重新設定或切換到其它的 Shell。對於UNIX,可能是CShelll。環境變數是通過Shell命令來設定的,設定好的環境變數又可以被所有當前使用者所執行的程式所使用。對於bash這個Shell
jediscluster執行過程中出現no reachable node in cluster異常
redis.clients.jedis.exceptions.JedisConnectionException: no reachable node in cluster at redis.clients.jedis.JedisSlotBasedConnecti
WMS->動畫執行過程中位移的計算
mWin.mShownPosition為最終window的位置,計算過程主要參考了app transition動畫,螢幕旋轉動畫,attach的window的動畫,目標牆紙的動畫進行計算,最終計算出動畫視窗的位置,大小alpha值,函式很簡單主要使用了一些線性代數的矩陣變換,只是簡單的縮放平