
如何實現按距離排序、範圍查詢
簡介
現在幾乎所有的O2O應用中都會存在“按範圍搜素、離我最近、顯示距離”等等基於位置的互動,那這樣的功能是怎麼實現的呢?本文提供的實現方式,適用於所有資料庫。
實現
為了方便下面說明,先給出一個初始表結構,我使用的是MySQL:
CREATE TABLE `customer` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
`name` VARCHAR(5) NOT NULL COMMENT '名稱',
`lon` DOUBLE(9,6) NOT NULL COMMENT '經度',
`lat` - 實現過程主要分為四步:
1. 搜尋
在資料庫中搜索出接近指定範圍內的商戶,如:搜尋出1公里範圍內的。
2. 過濾
搜尋出來的結果可能會存在超過1公里的,需要再次過濾。如果對精度沒有嚴格要求,可以跳過。
3. 排序
距離由近到遠排序。如果不需要,可以跳過。
4. 分頁
如果需要2、3步,才需要對分頁特殊處理。如果不需要,可以在第1步直接SQL分頁。
第1步資料庫完成,後3步應用程式完成。
step1 搜尋
搜尋可以用下面兩種方式來實現。
區間查詢
customer表中使用兩個欄位儲存了經度和緯度,如果提前計算出經緯度的範圍,然後在這兩個欄位上加上索引,那搜尋效能會很不錯。
那怎麼計算出經緯度的範圍呢?已知條件是移動裝置所在的經緯度,還有滿足業務要求的半徑,這很像初中的一道平面幾何題:給定圓心座標和半徑,求該圓外切正方形四個頂點的座標。而我們面對的是一個球體,可以使用spatial4j來計算。
<dependency>
<groupId>com.spatial4j</groupId>
<artifactId>spatial4j</artifactId // 移動裝置經緯度
double lon = 116.312528, lat = 39.983733;
// 千米
int radius = 1;
SpatialContext geo = SpatialContext.GEO;
Rectangle rectangle = geo.getDistCalc().calcBoxByDistFromPt(
geo.makePoint(lon, lat), radius * DistanceUtils.KM_TO_DEG, geo, null);
System.out.println(rectangle.getMinX() + "-" + rectangle.getMaxX());// 經度範圍
System.out.println(rectangle.getMinY() + "-" + rectangle.getMaxY());// 緯度範圍計算出經緯度範圍之後,SQL是這樣:
SELECT id, name
FROM customer
WHERE (lon BETWEEN ? AND ?) AND (lat BETWEEN ? AND ?);需要給lon、lat兩個欄位建立聯合索引:
INDEX `idx_lon_lat` (`lon`, `lat`)geohash
geohash的原理不講了,詳細可以看這篇文章,講的很詳細。geohash演算法能把二維的經緯度編碼成一維的字串,它的特點是越相近的經緯度編碼後越相似,所以可以通過字首like的方式去匹配周圍的商戶。
customer表要增加一個欄位,來儲存每個商戶的geohash編碼,並且建立索引。
CREATE TABLE `customer` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主鍵',
`name` VARCHAR(5) NOT NULL COMMENT '名稱' COLLATE 'latin1_swedish_ci',
`lon` DOUBLE(9,6) NOT NULL COMMENT '經度',
`lat` DOUBLE(8,6) NOT NULL COMMENT '緯度',
`geo_code` CHAR(12) NOT NULL COMMENT 'geohash編碼',
PRIMARY KEY (`id`),
INDEX `idx_geo_code` (`geo_code`)
)
COMMENT='商戶表'
CHARSET=utf8mb4
ENGINE=InnoDB
;在新增或修改一個商戶的時候,維護好geo_code,那geo_code怎麼計算呢?spatial4j也提供了一個工具類GeohashUtils.encodeLatLon(lat, lon),預設精度是12位。這個儲存做好後,就可以通過geo_code去搜索了。拿到移動裝置的經緯度,計算geo_code,這時可以指定精度計算,那指定多長呢?我們需要一個geo_code長度和距離的對照表:
| geohash length | width | height |
|---|---|---|
| 1 | 5,009.4km | 4,992.6km |
| 2 | 1,252.3km | 624.1km |
| 3 | 156.5km | 156km |
| 4 | 39.1km | 19.5km |
| 5 | 4.9km | 4.9km |
| 6 | 1.2km | 609.4m |
| 7 | 152.9m | 152.4m |
| 8 | 38.2m | 19m |
| 9 | 4.8m | 4.8m |
| 10 | 1.2m | 59.5cm |
| 11 | 14.9cm | 14.9cm |
| 12 | 3.7cm | 1.9cm |
假設我們的需求是1公里範圍內的商戶,geo_code的長度設定為5就可以了,GeohashUtils.encodeLatLon(lat, lon, 5)。計算出移動裝置經緯度的geo_code之後,SQL是這樣:
SELECT id, name
FROM customer
WHERE geo_code LIKE CONCAT(?, '%');這樣會比區間查詢快很多,並且得益於geo_code的相似性,可以對熱點區域做快取。但這樣使用geohash還存在一個問題,geohash最終是在地圖上鋪上了一個網格,每一個網格代表一個geohash值,當傳入的座標接近當前網格的邊界時,用上面的搜尋方式就會丟失它附近的資料。比如下圖中,在綠點的位置搜尋不到白家大院,綠點和白家大院在劃分的時候就分到了兩個格子中。 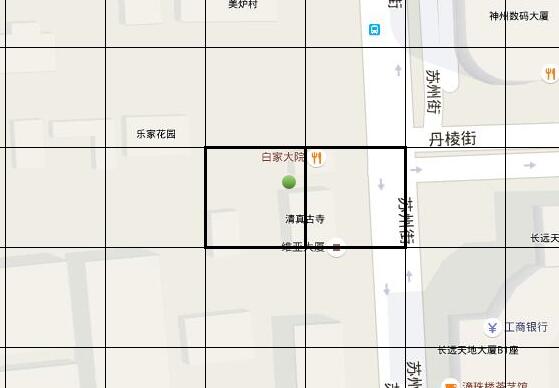
解決這個問題思路也比較簡單,我們查詢時,除了使用綠點的geohash編碼進行匹配外,還使用周圍8個網格的geohash編碼,這樣可以避免這個問題。那怎麼計算出周圍8個網格的geohash呢,可以使用geohash-java來解決。
<dependency>
<groupId>ch.hsr</groupId>
<artifactId>geohash</artifactId>
<version>1.3.0</version>
</dependency>// 移動裝置經緯度
double lon = 116.312528, lat = 39.983733;
GeoHash geoHash = GeoHash.withCharacterPrecision(lat, lon, 10);
// 當前
System.out.println(geoHash.toBase32());
// N, NE, E, SE, S, SW, W, NW
GeoHash[] adjacent = geoHash.getAdjacent();
for (GeoHash hash : adjacent) {
System.out.println(hash.toBase32());
}最終我們的sql變成了這樣:
SELECT id, name
FROM customer
WHERE geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%')
OR geo_code LIKE CONCAT(?, '%');原來的1次查詢變成了9次查詢,效能肯定會下降,這裡可以優化下。還用上面的需求場景,搜尋1公里範圍內的商戶,從上面的表格知道,geo_code長度為5時,網格寬高是4.9KM,用9個geo_code查詢時,範圍太大了,所以可以將geo_code長度設定為6,即縮小了查詢範圍,也滿足了需求。還可以繼續優化,在儲存geo_code時,只計算到6位,這樣就可以將sql變成這樣:
SELECT id, name
FROM customer
WHERE geo_code IN (?, ?, ?, ?, ?, ?, ?, ?, ?);這樣將字首匹配換成了直接匹配,速度會提升很多。
step2 過濾
上面兩種搜尋方式,都不是精確搜尋,只是儘量縮小搜尋範圍,提升響應速度。所以需要在應用程式中做過濾,把距離大於1公里的商戶過濾掉。計算距離同樣使用spatial4j。
// 移動裝置經緯度
double lon1 = 116.3125333347639, lat1 = 39.98355521792821;
// 商戶經緯度
double lon2 = 116.312528, lat2 = 39.983733;
SpatialContext geo = SpatialContext.GEO;
double distance = geo.calcDistance(geo.makePoint(lon1, lat1), geo.makePoint(lon2, lat2))
* DistanceUtils.DEG_TO_KM;
System.out.println(distance);// KM過濾程式碼就不寫了,遍歷一遍搜尋結果即可。
step3 排序
同樣,排序也需要在應用程式中處理。排序基於上面的過濾結果做就可以了Collections.sort(list, comparator)。
step4 分頁
如果需要2、3步,只能在記憶體中分頁,做法也很簡單,可以參考這篇文章。
總結
全文的重點都在於搜尋如何實現,更好的利用資料庫的索引,兩種搜尋方式以百萬資料量為分割線,第一種適用於百萬以下,第二種適用於百萬以上,未經過嚴格驗證。可能有人會有疑問,過濾和排序都在應用層做,記憶體佔用會不會很嚴重?這是個潛在問題,但大多數情況下不會。看我們大部分的應用場景,都是單一種類POI(Point Of Interest)的搜尋,如酒店、美食、KTV、電影院等等,這種資料密度是很小,1公里內的酒店,能有多少家,50家都算多的,所以最終要看具體業務資料密度。本文沒有分析原理,只講了具體實現,有關分析的文章可以看參考連結。
相關推薦
如何實現按距離排序、範圍查詢
簡介現在幾乎所有的O2O應用中都會存在“按範圍搜素、離我最近、顯示距離”等等基於位置的互動,那這樣的功能是怎麼實現的呢?本文提供的實現方式,適用於所有資料庫。實現為了方便下面說明,先給出一個初始表結構,我使用的是MySQL:CREATE TABLE `customer` (
基於MySQL實現按距離排序、範圍查詢geoHash
簡介 現在幾乎所有的O2O應用中都會存在“按範圍搜素、離我最近、顯示距離”等等類似的功能,那這樣的功能是怎麼實現的呢?本文提供了基於MySQL的實現方式,同樣適用於其它資料庫。本文不分析,只講怎麼實現,有關分析的文章可以看參考連結。 實現 為了方便下面說明,先給出一個初始
[Mysql] 如何實現按距離排序、範圍查詢
總結: 1.適合場景: 查詢範圍為某個具體距離範圍內,如1公里範圍內 2.缺點:查詢的是距離範圍內的,如果要按距離排序,sql語句在下文所屬中加上下面語句 order by abs(htl.lng -" + lng + ")+abs(htl.lat -"+lat+")
Redis 設計與實現 (八)--排序、慢查詢日誌、監視器
監視 strong add 2.4 bsp log 格式 sadd 請求 一、排序 SORT <key> 對一個數字值的key進行排序 1、alpha 對字符串類型的鍵進行排序 2、asc / desc redis 默認升序排序asc
node實現電影列表 排序、按照區間查詢功能、去重功能、搜尋功能
目標 電影列表 排序、按照區間查詢功能、去重功能、搜尋功能 複習:eval函式的使用場景、陣列去重(至少你要懂得6種) 排序 ---- **.**.find().sort() ------ (查詢所有的資
AngularJs實現 每列排序,輸入查詢、插入升序降序圖示
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <
MySql中實現 按經緯度搜索附近的人,並按距離排序的簡單實現
按經緯度搜索附近的人,並按距離排序的簡單實現這是一種簡單的實現,資料量不大的情況下還是能滿足需求的,寫在這裡做一份記錄。當然也希望有其他更好的方案。主要思路就是:先以自己的經緯度為中心,計算一定半徑內的方形經緯度邊界,然後用此方形經緯度邊界過濾使用者,並使用一個計算兩點經緯度之
ElasticSearchTemplate實現給定經緯度的“離我最近”排序/按距離排序
按步驟來吧。第一步,準備要使用此排序方式的、要存入ES的Bean,新增位置資訊屬性,並加 @GeoPointField 。位置屬性的型別為GeoPoint。正常情況下應該是用SpringData包下的GeoPoint型別,但是使用期間會出現各種無法判斷的錯誤,所以我們一般自己
(九)數據結構之簡單排序算法實現:冒泡排序、插入排序和選擇排序
html lan 獎章 tmx 4tb wot 數據結構 lec get d59FG8075P7伊http://www.zcool.com.cn/collection/ZMTg2NTU2NjQ=.html 312V畏蝗淤ZP哦睬http://www.zcool.com.c
entity framework 實現按照距離排序
在做專案時,經常會遇到“離我最近”這種需求。顧名思義,它需要根據使用者的經緯度和事物的經緯度計算距離,然後進行排序,最後分頁(當然這些操作要在資料庫中進行,否則就變成假分頁了)。 我們通常可以用sql語句來實現 SELECT es_name, es_lon, es_lat,
氣泡排序、選擇排序、二分查詢、插入排序
氣泡排序、選擇排序、二分查詢、插入排序 氣泡排序 氣泡排序的思想就是兩兩比較,按從小到大輸出的話,兩個值相比,較小的放前大的放後,那麼第一次兩兩比較結束後,最大值放在末尾,接下來再繼續兩兩比較,但是這一次不需要比較到最後,因為最後已經是最大值了,所以每次兩兩比較結束後,都會少比一次,
Hadoop完全分散式用MapReduce實現自定義排序、分割槽和分組
經過前面一段時間的學習,簡單的單詞統計已經不能實現更多的需求,就連自帶的一些函式方法等也是跟不上節奏了;加上前面一篇MapReduce的底層執行步驟的瞭解,今天學習自定義的排序、分組、分割槽相對也特別容易。 認為不好理解,先參考一下前面的一篇:https://bl
Mybatis實現增刪改查、模糊查詢、多條件查詢
專案總體結構如下: 資料庫準備:在 資料庫dbmybatis中建立一張category的表,我錄入了幾條記錄方便測試,表字段結構如下圖: 1.建立好了表後使用idea新建一個Maven專案,pom.xml加入如下依賴: <dependencies> &
ItemDecoration詳解以及用ItemDecoration實現按字母排序列表
首先看看實現的效果 可以看出要實現上面效果,有三個步驟: 1.漢字轉化為拼音,並且根據首字母排序 2.用ItemDecoration實現字母行的顯示 3.自定義實現右側的按字母導航欄 當然重點講講ItemDecoration的實現。都知道RecyclerView本
mysql筆記三之條件、模糊、範圍查詢
1.-- 條件查詢 滿足條件 就能夠進入結果集 -- 比較運算子 -- > -- 查詢大於18歲的資
Java中陣列氣泡排序、選擇排序、二分查詢的詳細分析
前言:儘管在實際開發中,我們通過Arrays工具類就可以便利地對陣列進行排序和查詢的操作,但是掌握氣泡排序、選擇排序、二分法查詢的思想對於程式設計來說還是極其重要的,在很多場景都會用到。希望通過這篇部落格的分析能給大家帶來收穫。 主題:陣列的排序和查詢 1、冒泡法排序:
Hadoop完全分散式下實現自定義排序、分割槽和分組
經過前面一段時間的學習,簡單的單詞統計已經不能實現更多的需求,就連自帶的一些函式方法等也是跟不上節奏了;加上前面一篇MapReduce的底層執行步驟的瞭解,今天學習自定義的排序、分組、分割槽相對也特別容易。 自定義排序 自定義的排序有許多許多,根據不同的業務需
java實現按拼音排序
List<WaPayFileVO> list =(List<WaPayFileVO>) dao.execQueryBeanList(pagesql, params.toArray(), new BeanListProcessor(WaPayFileVO.class)); i
java-氣泡排序、選擇排序、二分查詢
1、氣泡排序 1 public void bubbleSort(int[] arr) { 2 for (int i = 0; i < arr.length - 1; i++) { //外迴圈只需要比較arr.length-1次就可以了 3 for
Python八大演算法的實現,插入排序、希爾排序、氣泡排序、快速排序、直接選擇排序、堆排序、歸併排序、基數排序。
1、插入排序 描述 插入排序的基本操作就是將一個數據插入到已經排好序的有序資料中,從而得到一個新的、個數加一的有序資料,演算法適用於少量資料的排序,時間複雜度為O(n^2)。是穩定的排序方法。插入演算法把要排序的陣列分成兩部分:第一部分包含了這個陣列的所有元素,但將最後一