
Hadoop學習筆記—5.自定義型別處理手機上網日誌
一、測試資料:手機上網日誌
1.1 關於這個日誌
假設我們如下一個日誌檔案,這個檔案的內容是來自某個電信運營商的手機上網日誌,檔案的內容已經經過了優化,格式比較規整,便於學習研究。
該檔案的內容如下(這裡我只截取了三行):
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 視訊網站 15 12 1527 2106 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 資訊保安 20 20 3156 2936 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 綜合門戶 57 102 7335 110349 200
每一行不同的欄位有有不同的含義,具體的含義如下圖所示:
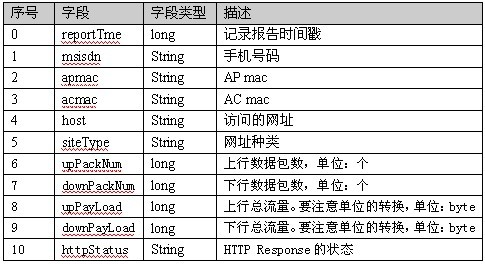
1.2 要實現的目標
有了上面的測試資料—手機上網日誌,那麼問題來了,如何通過map-reduce實現統計不同手機號使用者的上網流量資訊?通過上表可知,第6~9個欄位是關於流量的資訊,也就是說我們需要為每個使用者統計其upPackNum、downPackNum、upPayLoad以及downPayLoad這個四個欄位的數量和,達到以下的顯示結果:
13480253104 3 3 180 180
13502468823 57 102 7335 110349
二、解決思路:封裝手機流量
2.1 Writable介面
經過上一篇的學習,我們知道了在Hadoop中操作所有的資料型別都需要實現一個叫Writable的介面,實現了該接口才能夠支援序列化,才能方便地在Hadoop中進行讀取和寫入。
public interface Writable { /** * Serialize the fields of this object to <code>out</code>. */ voidwrite(DataOutput out) throws IOException; /** * Deserialize the fields of this object from <code>in</code>. */ void readFields(DataInput in) throws IOException; }
從上面的程式碼中可以看到Writable 介面只有兩個方法的定義,一個是write 方法,一個是readFields 方法。前者是把物件的屬性序列化到DataOutput 中去,後者是從DataInput 把資料反序列化到物件的屬性中。(簡稱“讀進來”,“寫出去”)
java 中的基本型別有char、byte、boolean、short、int、float、double 共7 中基本型別,除了char,都有對應的Writable 型別。但是,沒有我們需要的對應型別。於是,我們需要仿照現有的對應Writable 型別封裝一個自定義的資料型別,以供本次試驗使用。
2.2 封裝KpiWritable型別
我們需要為每個使用者統計其upPackNum、downPackNum、upPayLoad以及downPayLoad這個四個欄位的數量和,而這個四個欄位又都是long 型別,於是我們可以封裝以下程式碼:
/* * 自定義資料型別KpiWritable */ public class KpiWritable implements Writable { long upPackNum; // 上行資料包數,單位:個 long downPackNum; // 下行資料包數,單位:個 long upPayLoad; // 上行總流量,單位:byte long downPayLoad; // 下行總流量,單位:byte public KpiWritable() { } public KpiWritable(String upPack, String downPack, String upPay, String downPay) { upPackNum = Long.parseLong(upPack); downPackNum = Long.parseLong(downPack); upPayLoad = Long.parseLong(upPay); downPayLoad = Long.parseLong(downPay); } @Override public String toString() { String result = upPackNum + "\t" + downPackNum + "\t" + upPayLoad + "\t" + downPayLoad; return result; } @Override public void write(DataOutput out) throws IOException { out.writeLong(upPackNum); out.writeLong(downPackNum); out.writeLong(upPayLoad); out.writeLong(downPayLoad); } @Override public void readFields(DataInput in) throws IOException { upPackNum = in.readLong(); downPackNum = in.readLong(); upPayLoad = in.readLong(); downPayLoad = in.readLong(); } }
通過實現Writable介面的兩個方法,就封裝好了KpiWritable型別。
三、程式設計實現:依然MapReduce
3.1 自定義Mapper類
/* * 自定義Mapper類,重寫了map方法 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, KpiWritable> { protected void map( LongWritable k1, Text v1, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context) throws IOException, InterruptedException { String[] spilted = v1.toString().split("\t"); String msisdn = spilted[1]; // 獲取手機號碼 Text k2 = new Text(msisdn); // 轉換為Hadoop資料型別並作為k2 KpiWritable v2 = new KpiWritable(spilted[6], spilted[7], spilted[8], spilted[9]); context.write(k2, v2); }; }
這裡將第6~9個欄位的資料都封裝到KpiWritable型別中,並將手機號和KpiWritable作為<k2,v2>傳入下一階段;
3.2 自定義Reducer類
/* * 自定義Reducer類,重寫了reduce方法 */ public static class MyReducer extends Reducer<Text, KpiWritable, Text, KpiWritable> { protected void reduce( Text k2, java.lang.Iterable<KpiWritable> v2s, org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context) throws IOException, InterruptedException { long upPackNum = 0L; long downPackNum = 0L; long upPayLoad = 0L; long downPayLoad = 0L; for (KpiWritable kpiWritable : v2s) { upPackNum += kpiWritable.upPackNum; downPackNum += kpiWritable.downPackNum; upPayLoad += kpiWritable.upPayLoad; downPayLoad += kpiWritable.downPayLoad; } KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "", upPayLoad + "", downPayLoad + ""); context.write(k2, v3); }; }
這裡將Map階段每個手機號所對應的流量記錄都一一進行相加求和,最後生成一個新的KpiWritable型別物件與手機號作為新的<k3,v3>返回;
3.3 完整程式碼實現
完整的程式碼如下所示:


public class MyKpiJob extends Configured implements Tool { /* * 自定義資料型別KpiWritable */ public static class KpiWritable implements Writable { long upPackNum; // 上行資料包數,單位:個 long downPackNum; // 下行資料包數,單位:個 long upPayLoad; // 上行總流量,單位:byte long downPayLoad; // 下行總流量,單位:byte public KpiWritable() { } public KpiWritable(String upPack, String downPack, String upPay, String downPay) { upPackNum = Long.parseLong(upPack); downPackNum = Long.parseLong(downPack); upPayLoad = Long.parseLong(upPay); downPayLoad = Long.parseLong(downPay); } @Override public String toString() { String result = upPackNum + "\t" + downPackNum + "\t" + upPayLoad + "\t" + downPayLoad; return result; } @Override public void write(DataOutput out) throws IOException { out.writeLong(upPackNum); out.writeLong(downPackNum); out.writeLong(upPayLoad); out.writeLong(downPayLoad); } @Override public void readFields(DataInput in) throws IOException { upPackNum = in.readLong(); downPackNum = in.readLong(); upPayLoad = in.readLong(); downPayLoad = in.readLong(); } } /* * 自定義Mapper類,重寫了map方法 */ public static class MyMapper extends Mapper<LongWritable, Text, Text, KpiWritable> { protected void map( LongWritable k1, Text v1, org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, KpiWritable>.Context context) throws IOException, InterruptedException { String[] spilted = v1.toString().split("\t"); String msisdn = spilted[1]; // 獲取手機號碼 Text k2 = new Text(msisdn); // 轉換為Hadoop資料型別並作為k2 KpiWritable v2 = new KpiWritable(spilted[6], spilted[7], spilted[8], spilted[9]); context.write(k2, v2); }; } /* * 自定義Reducer類,重寫了reduce方法 */ public static class MyReducer extends Reducer<Text, KpiWritable, Text, KpiWritable> { protected void reduce( Text k2, java.lang.Iterable<KpiWritable> v2s, org.apache.hadoop.mapreduce.Reducer<Text, KpiWritable, Text, KpiWritable>.Context context) throws IOException, InterruptedException { long upPackNum = 0L; long downPackNum = 0L; long upPayLoad = 0L; long downPayLoad = 0L; for (KpiWritable kpiWritable : v2s) { upPackNum += kpiWritable.upPackNum; downPackNum += kpiWritable.downPackNum; upPayLoad += kpiWritable.upPayLoad; downPayLoad += kpiWritable.downPayLoad; } KpiWritable v3 = new KpiWritable(upPackNum + "", downPackNum + "", upPayLoad + "", downPayLoad + ""); context.write(k2, v3); }; } // 輸入檔案目錄 public static final String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/HTTP_20130313143750.dat"; // 輸出檔案目錄 public static final String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/mobilelog"; @Override public int run(String[] args) throws Exception { // 首先刪除輸出目錄已生成的檔案 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf()); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } // 定義一個作業 Job job = new Job(getConf(), "MyKpiJob"); // 設定輸入目錄 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 設定自定義Mapper類 job.setMapperClass(MyMapper.class); // 指定<k2,v2>的型別 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(KpiWritable.class); // 設定自定義Reducer類 job.setReducerClass(MyReducer.class); // 指定<k3,v3>的型別 job.setOutputKeyClass(Text.class); job.setOutputKeyClass(KpiWritable.class); // 設定輸出目錄 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); // 提交作業 Boolean res = job.waitForCompletion(true); if(res){ System.out.println("Process success!"); System.exit(0); } else{ System.out.println("Process failed!"); System.exit(1); } return 0; } public static void main(String[] args) { Configuration conf = new Configuration(); try { int res = ToolRunner.run(conf, new MyKpiJob(), args); System.exit(res); } catch (Exception e) { e.printStackTrace(); } } }View Code
3.4 除錯執行效果

附件下載
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
相關推薦
Hadoop學習筆記—5.自定義型別處理手機上網日誌
一、測試資料:手機上網日誌 1.1 關於這個日誌 假設我們如下一個日誌檔案,這個檔案的內容是來自某個電信運營商的手機上網日誌,檔案的內容已經經過了優化,格式比較規整,便於學習研究。 該檔案的內容如下(這裡我只截取了三行): 1363157993044 18211575961 94-71-
Hadoop自定義型別處理手機上網日誌
job提交原始碼分析 在eclipse中的寫的程式碼如何提交作業到JobTracker中的哪? (1)在eclipse中呼叫的job.waitForCompletion(true)實際上執行如下方法 connect(); info = jobClient.submitJobInt
Hadoop學習筆記—5.自定義類型處理手機上網日誌
clas stat 基本 手機上網 oop interrupt pil 依然 手機號碼 一、測試數據:手機上網日誌 1.1 關於這個日誌 假設我們如下一個日誌文件,這個文件的內容是來自某個電信運營商的手機上網日誌,文件的內容已經經過了優化,格式比較規整,便於學習研究。
python學習筆記5-自定義函數
函數調用 筆記 取值 修改 args pytho class 名稱 func 1 自定義函數 (1)函數代碼塊以def關鍵字開頭,然後函數標識符名稱和圓括號 (2)任何傳入參數和自變量必須放在圓括號中間。圓括號之間可以用於定義參數 (3)函數的第一行語句可以選擇
學習筆記19_自定義錯誤頁
默認 errors acc .html 調試 error redirect nbsp edi 在WebConfig中,可以配置當服務器發生哪些錯誤時,能跳轉到那個頁面: <customErrors mode ="On" defaultRedirect = " defa
轉:C#制作ORM映射學習筆記一 自定義Attribute類
技術 sage 其中 username pac ont 學習 collect reat 之前在做unity項目時發現只能用odbc連接數據庫,感覺非常的麻煩,因為之前做web開發的時候用慣了ORM映射,所以我想在unity中也用一下ORM(雖然我知道出於性能的考慮這樣做事不
vue2.0學習筆記之自定義組件
2.0 sco ron 自定義組件 定義 temp use 使用 imp step one: 推薦結構 step two: Loading.vue <template> <h3>{{msg}}<
ASP.NET MVC 學習筆記-7.自定義配置信息(後續)
字符串 return abstract 新的 work 生成 value DC 連接字符串加密 自定義配置信息的高級應用 通過上篇博文對簡單的自定義配置信息的學習,使得更加靈活的控制系統配置信息。實際項目中,這種配置的靈活度往往無法滿足項目的靈活度和擴展性。 比如,一個
node學習筆記6——自定義模塊
例子 學習筆記 log 2個 模塊 而且 nodejs 說明 分享 自定義模塊三大關鍵詞: require——引入模塊; exports——單個輸出; module——批量輸出。 從例子下手: 1.創建module.js: exports.a=22; exports.
Spring boot 學習筆記 1 - 自定義錯誤
note ride 覆蓋 ide rac med exception cat 異常 Spring Boot提供了WebExceptionHandler一個以合理的方式處理所有錯誤的方法。它在處理順序中的位置就在WebFlux提供的處理程序之前,這被認為是最後一個處理程序。
EF學習筆記——生成自定義實體類
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Android學習筆記之自定義View
一、自定義View的分類 1.1.繼承 View 這種方法主要用於實現一些不規則的效果(不方便通過佈局的組合方式來實現),比如靜態或動態地顯示一些不規則的圖形(因此需要重寫onDraw方法)。值得注意的是,繼承View的自定義View需要自己制定 wrap_content
Swift學習筆記三 自定義TableViewCell
學了tableView的用法,不得不說自定義TableViewCell,畢竟靠系統的cell遠遠滿足不了產品需求 所以在上個筆記的基礎上 自定義了一個cell 直接上程式碼 override init(style: UITableViewCellStyle, r
pytorch 學習筆記之自定義 Module
pytorch 是一個基於 python 的深度學習庫。pytorch 原始碼庫的抽象層次少,結構清晰,程式碼量適中。相比於非常工程化的 tensorflow,pytorch 是一個更易入手的,非常棒的深度學習框架。 對於系統學習 pytorch,官方提供了非
VB.NET學習筆記:自定義控制元件之擴充套件DataGridViewColumnHeaderCell類增加CheckBox全選複選框
測試環境:windows 7和Microsoft Visual Studio 2015 點選下載本文原始碼 VB.NET雖然提供了大量控制元件供我們使用,但很多控制元件僅提供最基礎的功能。比如用DataGridView控制元件可以非常方便顯示或操作資料庫資料,我們可以在首列新增DataGri
C++基礎學習筆記:自定義陣列模板類
//!時間:2017年9月12日(週二)下午 //!內容:陣列模板類 /* 修改:2017年9月13上午 成員方法中delete未正確匹配 改進:2017年9月13晚上 陣列總量改為固定 */ #define _CRTDBG_MAP_ALLOC #include <iostream>
Hadoop 學習研究(十): 自定義輸入輸出
自定義輸入輸出應用:在對資料需要進行一定條件的過濾和簡單處理的時候可以使用自定義輸入檔案格式類。 hadoop內建的輸入檔案格式類有: 1)FileInputFormat<K,V>這個是基本的父類,我們自定義就直接使用它作為父類; 2)TextInputForm
C++ 筆記——字串自定義加密處理
根據慣例,先放定義。加密,是以某種特殊的演算法改變原有的資訊資料,使得未授權的使用者即使獲得了已加密的資訊,但因不知解密的方法,仍然無法瞭解資訊的內容。 加密演算法非常多,常見的加密演算法有MD5、AES、Base64、DES等等。但是此篇部落格記錄的加密演算法和上述加密演算法無關,主要
【MyBatis學習16】自定義型別處理器typeHandlers介紹
<update id="update" parameterType="twm.mybatisdemo.pojo.User"> update user set username=#{username},password=#{pa
安卓學習筆記(10)-自定義彈出式對話方塊
之前學習彈出式對話方塊的時候,我們可以在AlertDialog中放置我們自己設計的佈局內容,如TextView,EditView,多選框,單選框等等,但是按鈕使用的都是其自帶的PositiveButton和NegativeButton,最多可使用三個按鈕