
Hadoop學習筆記—9.Partitioner與自定義Partitioner
一、初步探索Partitioner
1.1 再次回顧Map階段五大步驟
在第四篇博文《初識MapReduce》中,我們認識了MapReduce的八大步湊,其中在Map階段總共五個步驟,如下圖所示:
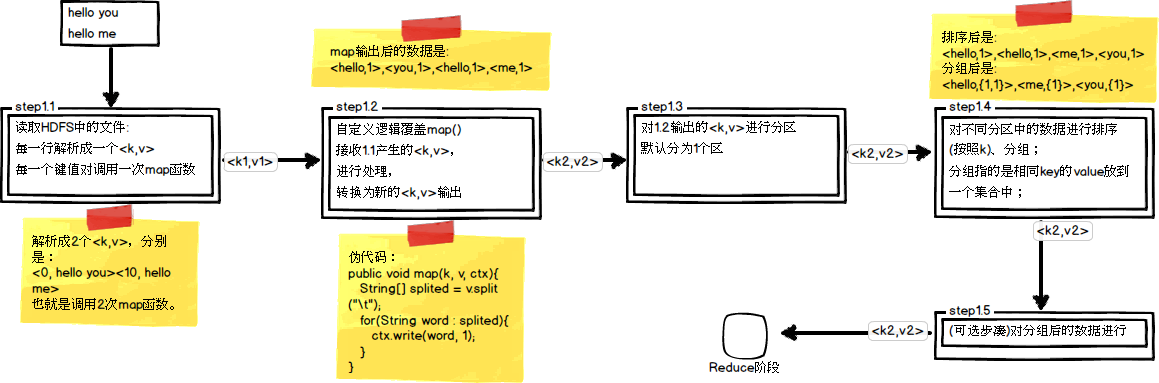
其中,step1.3就是一個分割槽操作。通過前面的學習我們知道Mapper最終處理的鍵值對<key, value>,是需要送到Reducer去合併的,合併的時候,有相同key的鍵/值對會送到同一個Reducer節點中進行歸併。哪個key到哪個Reducer的分配過程,是由Partitioner規定的。在一些叢集應用中,例如分散式快取叢集中,快取的資料大多都是靠雜湊函式來進行資料的均勻分佈的,在Hadoop中也不例外。

1.2 Hadoop內建Partitioner
MapReduce的使用者通常會指定Reduce任務和Reduce任務輸出檔案的數量(R)。使用者在中間key上使用分割槽函式來對資料進行分割槽,之後在輸入到後續任務執行程序。一個預設的分割槽函式式使用hash方法(比如常見的:hash(key) mod R)進行分割槽。hash方法能夠產生非常平衡的分割槽,鑑於此,Hadoop中自帶了一個預設的分割槽類HashPartitioner,它繼承了Partitioner類,提供了一個getPartition的方法,它的定義如下所示:
/** Partition keys by their {@link Object#hashCode()}. */ public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
現在我們來看看HashPartitoner所做的事情,其關鍵程式碼就一句:(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
這段程式碼實現的目的是將key均勻分佈在Reduce Tasks上,例如:如果Key為Text的話,Text的hashcode方法跟String的基本一致,都是採用的Horner公式計算,得到一個int整數。但是,如果string太大的話這個int整數值可能會溢位變成負數,所以和整數的上限值Integer.MAX_VALUE(即0111111111111111)進行與運算,然後再對reduce任務個數取餘,這樣就可以讓key均勻分佈在reduce上。
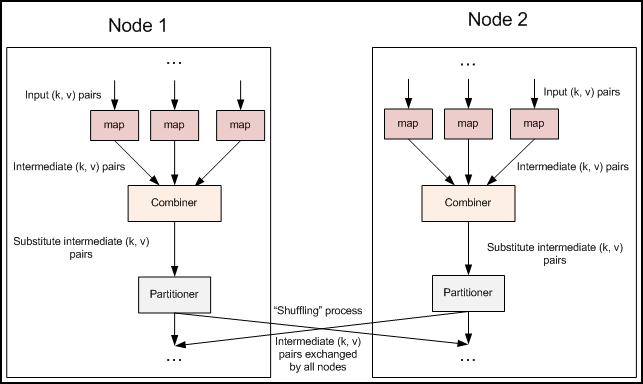
二、自己定製Partitioner
大部分情況下,我們都會使用預設的分割槽函式HashPartitioner。但有時我們又有一些特殊的應用需求,所以我們需要定製Partitioner來完成我們的業務。這裡以第五篇—自定義資料型別處理手機上網日誌為例,來對其中的日誌內容做一個特殊的分割槽:
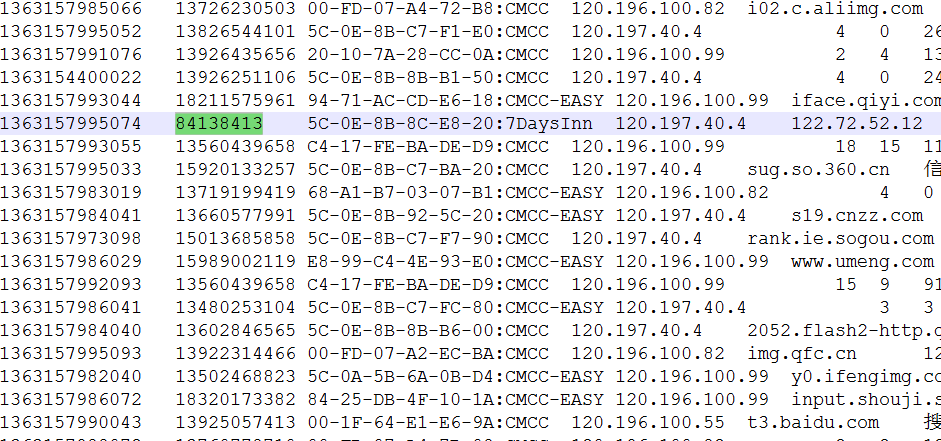
從上圖中我們可以發現,在第二列上並不是所有的資料都是手機號(例如:84138413並不是一個手機號),我們任務就是在統計手機流量時,將手機號碼和非手機號輸出到不同的檔案中。
2.1 自定義KpiPartitioner
/* * 自定義Partitioner類 */ public static class KpiPartitioner extends Partitioner<Text, KpiWritable> { @Override public int getPartition(Text key, KpiWritable value, int numPartitions) { // 實現不同的長度不同的號碼分配到不同的reduce task中 int numLength = key.toString().length(); if (numLength == 11) { return 0; } else { return 1; } } }
這裡按手機和非手機號碼的區分是按該欄位的長度來劃分,如果是11位則為手機號。接下來,就是重新修改run方法中的程式碼:設定為打包執行,設定Partitioner為KpiPartitioner,設定ReducerTask的個數為2;
public int run(String[] args) throws Exception { // 首先刪除輸出目錄已生成的檔案 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf()); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } // 定義一個作業 Job job = new Job(getConf(), "MyKpiJob"); // 分割槽需要設定為打包執行 job.setJarByClass(MyKpiJob.class); // 設定輸入目錄 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 設定自定義Mapper類 job.setMapperClass(MyMapper.class); // 指定<k2,v2>的型別 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(KpiWritable.class); // 設定Partitioner job.setPartitionerClass(KpiPartitioner.class); job.setNumReduceTasks(2); // 設定Combiner job.setCombinerClass(MyReducer.class); // 設定自定義Reducer類 job.setReducerClass(MyReducer.class); // 指定<k3,v3>的型別 job.setOutputKeyClass(Text.class); job.setOutputKeyClass(KpiWritable.class); // 設定輸出目錄 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); // 提交作業 System.exit(job.waitForCompletion(true) ? 0 : 1); return 0; }
注意:分割槽的例子必須要設定為打成jar包執行!
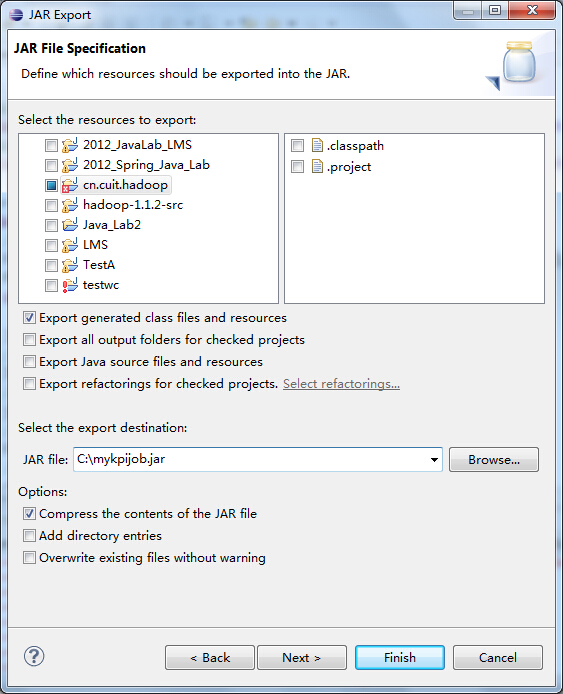
2.2 打成jar包並在Hadoop中執行
(1)通過Eclipse匯出jar包
(2)通過FTP上傳到Linux中,可以使用各種FTP工具,我一般使用XFtp。
(3)通過Hadoop Shell執行jar包中的程式

(4)檢視執行結果檔案:
首先是part-r-00000,它展示了手機號碼的統計結果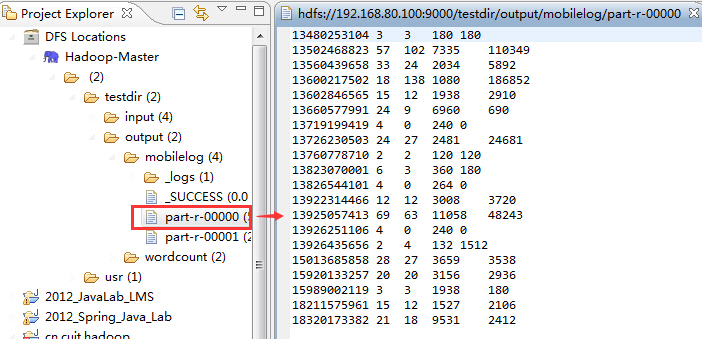
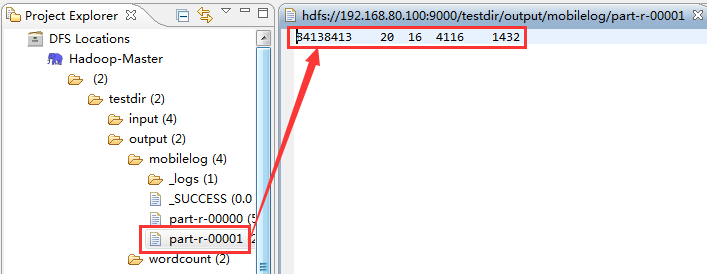
然後是part-r-00001,它展示了非手機號碼的統計結果
(5)通過Web介面驗證Partitioner的執行:通過訪問http://hadoop-master:50030
①是否有2個Reduce任務?

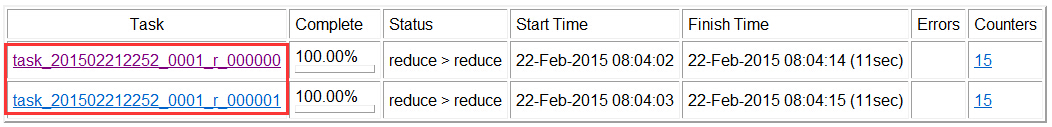
從圖中可以看出,總共有2個Reduce任務;
②Reduce輸出結果是否一致?
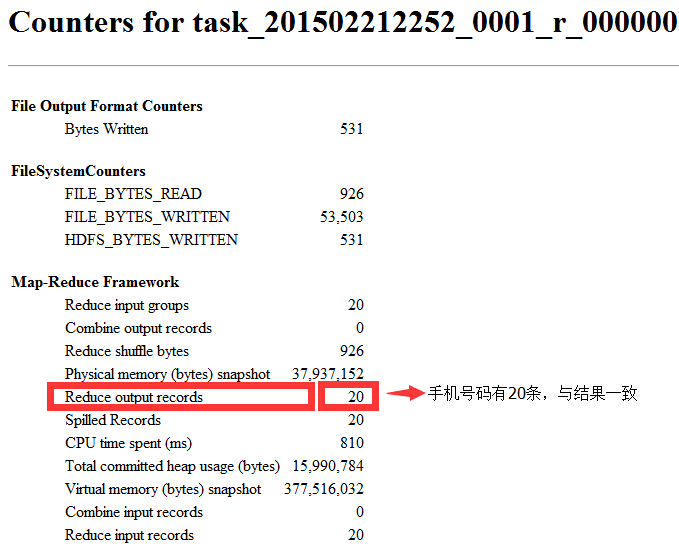
手機號碼有20條記錄,一致!
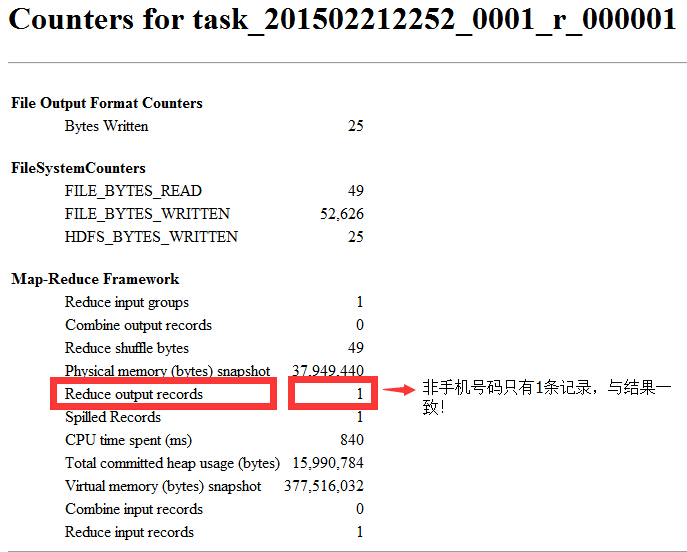
非手機號碼只有1條記錄,一致!
總結:分割槽Partitioner主要作用在於以下兩點
(1)根據業務需要,產生多個輸出檔案;
(2)多個reduce任務併發執行,提高整體job的執行效率
參考資料
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
相關推薦
Hadoop學習筆記—8.Combiner與自定義Combiner
一、Combiner的出現背景 1.1 回顧Map階段五大步驟 在第四篇博文《初識MapReduce》中,我們認識了MapReduce的八大步湊,其中在Map階段總共五個步驟,如下圖所示: 其中,step1.5是一個可選步驟,它就是我們今天需要了解的 Map規約 階段。現在,我們再來看看前一
Hadoop學習筆記—7.計數器與自定義計數器
一、Hadoop中的計數器 計數器:計數器是用來記錄job的執行進度和狀態的。它的作用可以理解為日誌。我們通常可以在程式的某個位置插入計數器,用來記錄資料或者進度的變化情況,它比日誌更便利進行分析。 例如,我們有一個檔案,其中包含如下內容: hello you hello me
Hadoop學習筆記—9.Partitioner與自定義Partitioner
一、初步探索Partitioner 1.1 再次回顧Map階段五大步驟 在第四篇博文《初識MapReduce》中,我們認識了MapReduce的八大步湊,其中在Map階段總共五個步驟,如下圖所示: 其中,step1.3就是一個分割槽操作。通過前面的學習我們知道Mapper最終處理的鍵值對&l
Shader學習筆記(三)自定義光照模型,經典光照模型Lambert與HalfLambert
自定義光照模型 #pragma surface surfaceFaction lightModel surfaceFaction:著色器程式碼的方法的名字 lightModel:光照模型的名稱 自
AngularJs學習筆記(4)——自定義指令
ref 告訴 ack 生命周期 .com bsp ctrl 參數變量 ng- 對指令的第一印象:它是一個自定義標簽! 先來看一個簡單的指令: <!doctype html> <html ng-app="myApp"> <head>
Ehcache學習筆記(2)--自定義ehcache工具類
二:自定義EhcacheUtils 1、CacheUtils package cn.kexq.commons.utils; import net.sf.ehcache.Cache; import net.sf.ehcache.CacheManager; import net.sf.eh
shiro學習筆記(3)--自定義realm、授權
一:自定義Realm 1、繼承AuthorizingRealm(因為該類中有認證、授權的抽象方法,實現簡單) public class MyRealm1 extends AuthorizingRealm{ @Override public String getName(
Android學習筆記之為Dialog自定義佈局,並說明空指標問題
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Vue:學習筆記(七)-自定義指令
提醒 原帖完整收藏於IT老兵驛站,並會不斷更新。 前言 前面總結到了元件,對混入也進行了研究,不過感覺沒有啥需要總結的,就先總結指令吧,參考這裡,記錄筆記。 正文 簡介 全域性註冊 // 註冊一個全域性自定義指令 `v-focus` Vue.di
Zynq-Linux移植學習筆記之31-使用者自定義I2C驅動
1、背景介紹 板子上通過ZYNQ的I2C-0控制器連線了三片DBF晶片和一片Ti的226測功耗晶片,示意圖如下: 如上圖所示,三塊DBF晶片的I2C地址分別為2,4,8,Ti 226晶片的I2C地址為0x40.現在需要ZYNQ通過I2C匯流排讀寫這四塊晶片的暫存器數值
springmvc學習筆記(26)——自定義型別轉換器
資料繫結流程 使用springmvc框架有諸多好處,其中較為突出的就是它的資料繫結。 當我們的前端傳過來一個表單的時候,我們只需要使用一個類物件(如Student物件)就接收,springmvc將幫我們把屬性一一對應的填充進去。這就是資料繫結。 資料繫結過程中,springmvc幫我們把前端
springmvc學習筆記(28)——自定義攔截器
1. 自定義攔截器 所謂的攔截器,就是用來攔截請求,因此我們可以對使用者發來的請求做處理。 寫一個類,實現攔截器的介面 import javax.servlet.http.HttpServletRequest; import javax.servlet.http.H
類的學習筆記(3)——自定義裝飾器及裝飾器的理解
例一: 實現多加100 def fun1(x): def fun2(y): return x(y)+100 return fun2 #裝飾器 def ff(y): return y*y
react native學習筆記24——Modal實現自定義彈出對話方塊
前言 上一篇文章介紹React Native系統提供的兩個彈出框的api——Alert與AlertIOS,Alert可以在雙平臺通用,但是隻能展示資訊量有限功能單一的文字對話方塊。AlertIOS比Alert稍微豐富一點,可以展示供使用者輸入的對話方塊,但只能
iPhone開發學習筆記005——使用XIB自定義一個UIView,然後將這個view新增到controller的view
一、新建一個single view application型別的iOS application工程,名字取為CustomView,如下圖,我們不往CustomViewViewController.xib中新增任何控制元件: 二、新建一個CustomView.xib,過程如下:然後往介面上拖一個label和
Maven學習筆記(一)——自定義maven變數以及maven內建常量
在建立Maven工程後,外掛配置中通常會用到一些Maven變數,因此需要找個地方對這些變數進行統一定義,下面介紹如何定義自定義變數。 在根節點project下增加properties節點,所有自定義變數均可以定義在此節點內,如下所示: <!-- 全域性屬性配置 --
torch學習筆記1:實現自定義層
當我們要實現自己的一些idea時,torch自帶的模組和函式已經不能滿足,我們需要自己實現層(或者類),一般的做法是把自定義層加入到已有的torch模組中。 實現 lua實現 如果自定義層的功能可以通過呼叫torch中已有的函式實現,那就只需要用l
Spring Boot學習筆記-錯誤處理及自定義
正常的Web應用開發時,需要考慮到應用執行發生異常時或出現錯誤時如何來被處理,例如捕獲必要的異常資訊,記錄日誌方便日後排錯,友好的使用者響應輸出等等。 當然應用發生錯誤,有可能是應用自身的問題,也有可能是客戶端操作的問題。 Spring Boot預設提供了一種錯誤處理機制。 預設錯誤處理機制 預設情況下,S
Vue.js學習 Item13 – 指令系統與自定義指令
基礎 除了內建指令,Vue.js 也允許註冊自定義指令。自定義指令提供一種機制將資料的變化對映為 DOM 行為。 可以用 Vue.directive(id, definition) 方法註冊一個全域性自定義指令,它接收兩個引數指令 ID 與定義物件。也可以用
Latex學習筆記(六)——自定義Latex模板
前言: 對於一個給定的模板,自己做了修改,用於日常工作寫報告使用(主要去除了封面和摘要部分),包含兩個檔案:(1) cls 檔案裡面定義好了常用的格式和環境;(2) tex 檔案裡面是我們文件內容的原始碼。當然,大家也可以根據自己的需要進行更改。 一、