
.NET基礎拾遺(3)字串、集合和流
一、字串處理
1.1 StringBuilder型別有什麼作用?
眾所周知,在.NET中String是引用型別,具有不可變性,當一個String物件被修改、插入、連線、截斷時,新的String物件就將被分配,這會直接影響到效能。但在實際開發中經常碰到的情況是,一個String物件的最終生成需要經過一個組裝的過程,而在這個組裝過程中必將會產生很多臨時的String物件,而這些String物件將會在堆上分配,需要GC來回收,這些動作都會對程式效能產生巨大的影響。事實上,在String的組裝過程中,其臨時產生的String物件例項都不是最終需要的,因此可以說是沒有必要分配的。
鑑於此,在.NET中提供了StringBuilder
以下程式碼展示了使用StringBuilder和不適用StringBuilder的效能差異:(這裡的效能檢測工具使用了老趙的CodeTimer類)


public class Program { private const String item = "一個專案"; privateView Codeconst String split = ";"; static void Main(string[] args) { int number = 10000; // 使用StringBuilder CodeTimer.Time("使用StringBuilder: ", 1, () => { UseStringBuilder(number); }); // 不使用StringBuilderCodeTimer.Time("使用不使用StringBuilder: : ", 1, () => { NotUseStringBuilder(number); }); Console.ReadKey(); } static String UseStringBuilder(int number) { System.Text.StringBuilder sb = new System.Text.StringBuilder(); for (int i = 0; i < number; i++) { sb.Append(item); sb.Append(split); } sb.Remove(sb.Length - 1, 1); return sb.ToString(); } static String NotUseStringBuilder(int number) { String result = ""; for (int i = 0; i < number; i++) { result += item; result += split; } return result; } }
上述程式碼的執行結果如下圖所示,可以看出由於StringBuilder不會產生任何的中間字串變數,因此效率上優秀不少!

看到StringBuilder這麼優秀,不禁想發出一句:臥槽,牛逼!

於是,我們拿起我們的錘子(Reflector)撕碎StringBuilder的外套,看看裡面到底裝了什麼?我們發現,在StringBuilder中定義了一個字元陣列m_ChunkChars,它儲存StringBuilder所管理著的字串中的字元。

經過對StringBuilder預設構造方法的分析,系統預設初始化m_ChunkChars的長度為16(0x10),當新追加進來的字串長度與舊有字串長度之和大於該字元陣列容量時,新建立字元陣列的容量會增加到2n+1(假如當前字元陣列容量為2n)。
此外,StringBuilder內部還有一個同為StringBuilder型別的m_ChunkPrevious,它是內部的一個StringBuilder物件,前面提到當追加的字串長度和舊字串長度之合大於字元陣列m_ChunkChars的最大容量時,會根據當前的(this)StringBuilder建立一個新的StringBuilder物件,將m_ChunkPrevious指向新建立的StringBuilder物件。
下面是StringBuilder中實現擴容的核心程式碼:
private void ExpandByABlock(int minBlockCharCount) { ...... int num = Math.Max(minBlockCharCount, Math.Min(this.Length, 0x1f40)); this.m_ChunkPrevious = new StringBuilder(this); this.m_ChunkOffset += this.m_ChunkLength; this.m_ChunkLength = 0; ...... this.m_ChunkChars = new char[num]; }
可以看出,初始化m_ChunkPrevious在前,建立新的字元陣列m_ChunkChars在後,最後才是複製字元到陣列m_ChunkChars中(更新當前的m_ChunkChars)。歸根結底,StringBuilder是在內部以字元陣列m_ChunkChars為基礎維護一個連結串列m_ChunkPrevious,該連結串列如下圖所示:

在最終的ToString方法中,當前的StringBuilder物件會根據這個連結串列以及記錄的長度和偏移變數去生成最終的一個String物件例項,StringBuilder的內部實現中使用了一些指標操作,其內部原理有興趣的園友可以自己去通過反編譯工具檢視原始碼。
1.2 String和Byte[]物件之間如何相互轉換?
在實際開發中,經常會對資料進行處理,不可避免地會遇到字串和位元組陣列相互轉換的需求。字串和位元組陣列的轉換,事實上是代表了現實世界資訊和數字世界資訊之間的轉換,要了解其中的機制,需要先對位元、直接以及編碼這三個概念有所瞭解。
(1)位元:bit是一個位,計算機內物理儲存的最基本單元,一個bit就是一個二進位制位;
(2)位元組:byte由8個bit構成,其值可以由一個0~255的整數表示;
(3)編碼:編碼是數字資訊和現實資訊的轉換機制,一種編碼通常就定義了一種字符集和轉換的原則,常用的編碼方式包括UTF8、GB2312、Unicode等。
下圖直觀地展示了位元、位元組、編碼和字串的關係:

從上圖可以看出,位元組陣列和字串的轉換必然涉及到某種編碼方式,不同的編碼方式由不同的轉換結果。在C#中,可以使用System.Text.Encoding來管理常用的編碼。
下面的程式碼展示瞭如何在位元組陣列和字串之間進行轉換(分別使用UTF8、GB2312以及Unicode三種編碼方式):
class Program { static void Main(string[] args) { string s = "我是字串,I am a string!"; // 位元組陣列 -> 字串 Byte[] utf8 = StringToByte(s, Encoding.UTF8); Byte[] gb2312 = StringToByte(s, Encoding.GetEncoding("GB2312")); Byte[] unicode = StringToByte(s, Encoding.Unicode); Console.WriteLine(utf8.Length); Console.WriteLine(gb2312.Length); Console.WriteLine(unicode.Length); // 字串 -> 字元陣列 Console.WriteLine(ByteToString(utf8, Encoding.UTF8)); Console.WriteLine(ByteToString(gb2312, Encoding.GetEncoding("GB2312"))); Console.WriteLine(ByteToString(unicode, Encoding.Unicode)); Console.ReadKey(); } // 字串 -> 位元組陣列 static Byte[] StringToByte(string str, Encoding encoding) { if (string.IsNullOrEmpty(str)) { return null; } return encoding.GetBytes(str); } // 位元組陣列 -> 字串 static string ByteToString(Byte[] bytes, Encoding encoding) { if (bytes == null || bytes.Length <= 0) { return string.Empty; } return encoding.GetString(bytes); } }View Code
上述程式碼的執行結果如下圖所示:

我們也可以從上圖中看出,不同的編碼方式產生的位元組陣列的長度各不相同。
1.3 BASE64編碼的作用以及C#中對其的支援
和傳統的編碼不同,BASE64編碼的設計致力於混淆那些8位位元組的資料流(解決網路傳輸中的明碼問題),在網路傳輸、郵件等系統中被廣泛應用。需要明確的是:BASE64不屬於加密機制,但它卻是把明碼變成了一種很難識別的形式。
BASE64的演算法如下:
BASE64把所有的位分開,並且重新組合成位元組,新的位元組只包含6位,最後在每個位元組前新增兩個0,組成了新的位元組陣列。例如:一個位元組陣列只包含三個位元組(每個位元組又有8位位元),對其進行BASE64編碼時會將其分配到4個新的位元組中(為什麼是4個呢?計算3*8/6=4),其中每個位元組只填充低6位,最後把高2位置為零。
下圖清晰地展示了上面所講到的BASE64的演算法示例:

在.NET中,BASE64編碼的應用也很多,例如在ASP.NET WebForm中,預設為我們生成了一個ViewState來保持狀態,如下圖所示:

這裡的ViewState其實就是伺服器在返回給瀏覽器前進行了一次BASE64編碼,我們可以通過一些解碼工具進行反BASE64編碼檢視其中的奧祕:
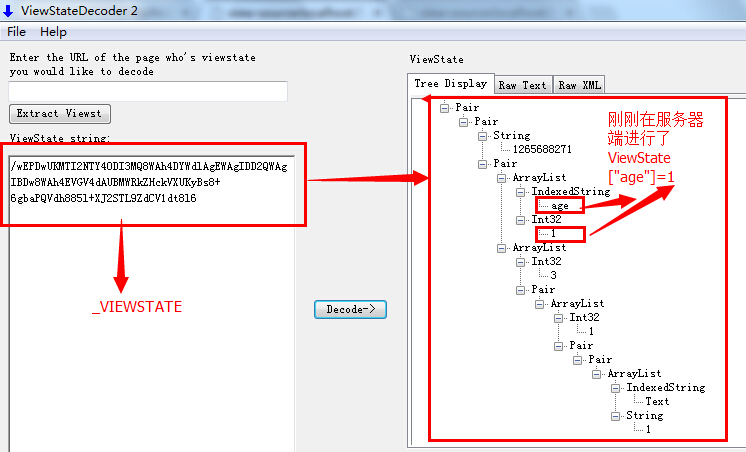
那麼,問題來了?在.NET中開發中,怎樣來進行BASE64的編碼和解碼呢,.NET基類庫中提供了一個Convert類,其中有兩個靜態方法提供了BASE64的編碼和解碼,但要注意的是:Convert型別在轉換失敗時會直接丟擲異常,我們需要在開發中注意對潛在異常的處理(比如使用is或as來進行高效的型別轉換)。下面的程式碼展示了其用法:
class Program { static void Main(string[] args) { string test = "abcde "; // 生成UTF8位元組陣列 byte[] bytes = Encoding.UTF8.GetBytes(test); // 轉換成Base64字串 string base64 = BytesToBase64(bytes); Console.WriteLine(base64); // 轉換回UTF8位元組陣列 bytes = Base64ToBytes(base64); Console.WriteLine(Encoding.UTF8.GetString(bytes)); Console.ReadKey(); } // Bytes to Base64 static string BytesToBase64(byte[] bytes) { try { return Convert.ToBase64String(bytes); } catch { return null; } } // Base64 to Bytes static Byte[] Base64ToBytes(string base64) { try { return Convert.FromBase64String(base64); } catch { return null; } } }View Code
上面程式碼的執行結果如下圖所示:

1.4 簡述SecureString安全字串的特點和用法
也許很多人都是第一次知道還有SecureString這樣一個型別,我也不例外。SecureString並不是一個常用的型別,但在一些擁有特殊需求的額場合,它就會有很大的作用。顧名思義,SecureString意為安全的字串,它被設計用來儲存一些機密的字串,完成傳統字串所不能做到的工作。
(1)傳統字串以明碼的形式被分配在記憶體中,一個簡單的記憶體讀寫軟體就可以輕易地捕獲這些字串,而在這某些機密系統中是不被允許的。也許我們會覺得對字串加密就可以解決類似問題,But,事實總是殘酷的,對字串加密時字串已經以明碼方式駐留在記憶體中很久了!對於該問題唯一的解決辦法就是在字串的獲得過程中直接進行加密,SecureString的設計初衷就是解決該類問題。
(2)為了保證安全性,SecureString是被分配在非託管記憶體上的(而普通String是被分配在託管記憶體中的),並且SecureString的物件從分配的一開始就以加密的形式存在,我們所有對於SecureString的操作(無論是增刪查改)都是逐字元進行的。
逐字元機制:在進行這些操作時,駐留在非託管記憶體中的字串就會被解密,然後進行具體操作,最後再進行加密。不可否認的是,在具體操作的過程中有小段時間字串是處於明碼狀態的,但逐字元的機制讓這段時間維持在非常短的區間內,以保證破解程式很難有機會讀取明碼的字串。
(3)為了保證資源釋放,SecureString實現了標準的Dispose模式(Finalize+Dispose雙管齊下,因為上面提到它是被分配到非託管記憶體中的),保證每個物件在作用域退出後都可以被釋放掉。
記憶體釋放方式:將其物件記憶體全部置為0,而不是僅僅告訴CLR這一塊記憶體可以分配,當然這樣做仍然是為了確保安全。熟悉C/C++的朋友可能就會很熟悉,這不就是 memset 函式乾的事情嘛!下面這段C程式碼便使用了memset函式將記憶體區域置為0:
// 下面申請的20個位元組的記憶體有可能被別人用過 char chs[20]; // memset記憶體初始化:memset(void *,要填充的資料,要填充的位元組個數) memset(chs,0,sizeof(chs));
看完了SecureString的原理,現在我們通過下面的程式碼來熟悉一下在.NET中的基本用法:
using System; using System.Runtime.InteropServices; using System.Security; namespace UseSecureString { class Program { static void Main(string[] args) { // 使用using語句保證Dispose方法被及時呼叫 using (SecureString ss = new SecureString()) { // 只能逐字元地操作SecureString物件 ss.AppendChar('e'); ss.AppendChar('i'); ss.AppendChar('s'); ss.AppendChar('o'); ss.AppendChar('n'); ss.InsertAt(1, 'd'); // 列印SecureStrign物件 PrintSecureString(ss); } Console.ReadKey(); } // 列印SecureString物件 public unsafe static void PrintSecureString(SecureString ss) { char* buffer = null; try { // 只能逐字元地訪問SecureString物件 buffer = (char*)Marshal.SecureStringToCoTaskMemUnicode(ss); for (int i = 0; *(buffer + i) != '\0'; i++) { Console.Write(*(buffer + i)); } } finally { // 釋放記憶體物件 if (buffer != null) { Marshal.ZeroFreeCoTaskMemUnicode((System.IntPtr)buffer); } } } } }View Code
其執行顯示的結果很簡單:

這裡需要注意的是:為了顯示SecureString的內容,程式需要訪問非託管記憶體,因此會用到指標,而要在C#使用指標,則需要使用unsafe關鍵字(前提是你在專案屬性中勾選了允許不安全程式碼,對你沒看錯,指標在C#可以使用,但是被認為是不安全的!)。此外,程式中使用了Marshal.SecureStringToCoTaskMemUnicode方法來把安全字串解密到非託管記憶體中,最後就是就是我們不要忘記在使用非託管資源時需要確保及時被釋放。
1.5 簡述字串駐留池機制
字串具有不可變性,程式中對於同一個字串的大量修改或者多個引用賦值同一字串在理論上會產生大量的臨時字串物件,這會極大地降低系統的效能。對於前者,可以使用StringBuilder型別解決,而後者,.NET則提供了另一種不透明的機制來優化,這就是傳說中的字串駐留池機制。
使用了字串駐留池機制之後,當CLR啟動時,會在內部建立一個容器,該容器內部維持了一個類似於key-value對的資料結構,其中key是字串的內容,而value則是字串在託管堆上的引用(也可以理解為指標或地址)。當一個新的字串物件需要分配時,CLR首先監測內部容器中是否已經存在該字串物件,如果已經包含則直接返回已經存在的字串物件引用;如果不存在,則新分配一個字串物件,同時把其新增到內部容器中取。But,這裡有一個例外,就是當程式設計師用new關鍵字顯示地申明新分配一個字串物件時,該機制將不會起作用。
從上面的描述中,我們可以看到字串駐留池的本質是一個快取,內部維持了一個鍵為字串內容,值為該字串在堆中的引用地址的鍵值對資料結構。我們可以通過下面一段程式碼來加深對於字串駐留池的理解:
class Program { static void Main(string[] args) { // 01.兩個字串物件,理論上引用應該不相等 // 但是由於字串池機制,二者指向了同一物件 string a = "abcde"; string b = "abcde"; Console.WriteLine(object.ReferenceEquals(a, b)); // 02.由於編譯器的優化,所以下面這個c仍然指向了同一引用地址 string c = "a" + "bc" + "de"; Console.WriteLine(object.ReferenceEquals(a, c)); // 03.顯示地使用new來分配記憶體,這時候字串池不起作用 char[] arr = { 'a', 'b', 'c', 'd', 'e' }; string d = new string(arr); Console.WriteLine(object.ReferenceEquals(a, d)); Console.ReadKey(); } }View Code
在上述程式碼中,由於字串駐留池機制的使用,變數a、b、c都指向了同一個字串例項物件,而d則使用了new關鍵字顯示申明,因此字串駐留池並沒有對其起作用,其執行結果如下圖所示:

字串駐留池的設計本意是為了改善程式的效能,因此在C#中預設是打開了字串駐留池機制,But,.NET也為我們提供了字串駐留池的開關介面,如果程式集標記了一個System.Runtime.CompilerServices.CompilationRelaxationsAttribute特性,並且指定了一個System.Runtime.CompilerServices.CompilationRelaxations.NoStringInterning標誌,那麼CLR不會採用字串駐留池機制,其程式碼宣告如下所示,但是我新增後一直沒有嘗試成功:
[assembly: System.Runtime.CompilerServices.CompilationRelaxations(System.Runtime.CompilerServices.CompilationRelaxations.NoStringInterning)]
二、常用集合和泛型
2.1 int[]是值型別還是引用型別?
在.NET中的陣列型別和C++中區別很大,.NET中無論是儲存值型別物件的陣列還是儲存引用型別的陣列,其本身都是引用型別,其記憶體也都是分配在堆上的。它們的共同特徵在於:所有的陣列型別都繼承自System.Array,而System.Array又實現了多個介面,並且直接繼承自System.Object。不同之處則在於儲存值型別物件的陣列所有的值都已經包含在陣列內,而儲存引用型別物件的陣列,其值則是一個引用,指向位於託管堆中的例項物件。
下圖直觀地展示了二者記憶體分配的差別(假設object[]中儲存都是DateTime型別的物件例項):

在.NET中CLR會檢測所有對陣列的訪問,任何檢視訪問陣列邊界以外的程式碼都會產生一個IndexOutOfRangeException異常。
2.2 陣列之間如何進行轉換?
陣列型別的轉換需要遵循以下兩個原則:
(1)包含值型別的陣列不能被隱式轉換成其他任何型別;
(2)兩個陣列型別能夠相互轉換的一個前提是兩者維數相同;
我們可以通過以下程式碼來看看陣列型別轉換的機制:
// 編譯成功 string[] sz = { "a", "a", "a" }; object[] oz = sz; // 編譯失敗,值型別的陣列不能被轉換 int[] sz2 = { 1, 2, 3 }; object[] oz2 = sz; // 編譯失敗,兩者維數不同 string[,] sz3 = { { "a", "b" }, { "a", "c" } }; object[] oz3 = sz3;
除了型別上的轉換,我們平時還可能會遇到內容轉換的需求。例如,在一系列的使用者介面操作之後,系統的後臺可能會得到一個DateTime的陣列,而現在的任務則是將它們儲存到資料庫中,而資料庫訪問層提供的介面只接受String[]引數,這時我們要做的就是把DateTime[]從內容上轉換為String[]物件。當然,慣常做法是遍歷整個源陣列,逐一地轉換每個物件並且將其放入一個目標陣列型別容器中,最後再生成目標陣列。But,這裡我們推薦使用Array.ConvertAll方法,它提供了一個簡便的轉換陣列間內容的介面,我們只需指定源陣列的型別、物件陣列的型別和具體的轉換演算法,該方法就能高效地完成轉換工作。
下面的程式碼清楚地展示了普通的陣列內容轉換方式和使用Array.ConvertAll的陣列內容轉換方式的區別:
class Program { static void Main(string[] args) { String[] times ={"2008-1-1", "2008-1-2", "2008-1-3"}; // 使用不同的方法轉換 DateTime[] result1 = OneByOne(times); DateTime[] result2 = ConvertAll(times); // 結果是相同的 Console.WriteLine("手動逐個轉換的方法:"); foreach (DateTime item in result1) { Console.WriteLine(item.ToString("yyyy-MM-dd")); } Console.WriteLine("使用Array.Convert方法:"); foreach (DateTime item2 in result2) { Console.WriteLine(item2.ToString("yyyy-MM-dd")); } Console.ReadKey(); } // 逐個手動轉換 private static DateTime[] OneByOne(String[] times) { List<DateTime> result = new List<DateTime>(); foreach (String item in times) { result.Add(DateTime.Parse(item)); } return result.ToArray(); } // 使用Array.ConertAll方法 private static DateTime[] ConvertAll(String[] times) { return Array.ConvertAll(times, new Converter<String, DateTime> (DateTimeToString)); } private static DateTime DateTimeToString(String time) { return DateTime.Parse(time); } }View Code
從上述程式碼可以看出,二者實現了相同的功能,但是Array.ConvertAll不需要我們手動地遍歷陣列,也不需要生成一個臨時的容器物件,更突出的優勢是它可以接受一個動態的演算法作為具體的轉換邏輯。當然,明眼人一看就知道,它是以一個委託的形式作為引數傳入,這樣的機制保證了Array.ConvertAll具有較高的靈活性。
2.3 簡述泛型的基本原理
泛型的語法和概念類似於C++中的template(模板),它是.NET 2.0中推出的眾多特性中最為重要的一個,方便我們設計更加通用的型別,也避免了容器操作中的裝箱和拆箱操作。
假如我們要實現一個排序演算法,要求能夠針對各種型別進行排序。按照以前的做法,我們需要對int、double、float等型別都實現一次,但是我們發現除了資料型別,其他的處理邏輯完全一致。這時,我們便可以考慮使用泛型來進行實現:
public static class SortHelper<T> where T : IComparable { public static void BubbleSort(T[] array) { int length = array.Length; for (int i = 0; i <= length - 2; i++) { for (int j = length - 1; j >= 1; j--) { // 對兩個元素進行交換 if (array[j].CompareTo(array[j - 1]) < 0) { T temp = array[j]; array[j] = array[j - 1]; array[j - 1] = temp; } } } } }
Tips:Microsoft在產品文件中建議所有的泛型引數名稱都以T開頭,作為一箇中編碼的通用規範,建議大家都能遵守這樣的規範,類似的規範還有所有的介面都以I開頭。
泛型型別和普通型別有一定的區別,通常泛型型別被稱為開放式型別,.NET中規定開放式型別不能例項化,這樣也就確保了開放式型別的泛型引數在被指定前,不會被例項化成任何物件(事實上,.NET也沒有辦法確定到底要分配多少記憶體給開放式型別)。為開放式的型別提供泛型的例項導致了一個新的封閉型別的生成,但這並不代表新的封閉型別和開放型別有任何繼承關係,它們在類結構圖上是處於同一層次,並且兩者之間沒有任何關係。下圖展示了這一概念:

此外,在.NET中的System.Collections.Generic名稱空間下提供了諸如List<T>、Dictionary<T>、LinkedList<T>等泛型資料結構,並且在System.Array中定義了一些靜態的泛型方法,我們應該在編碼實踐時充分使用這些泛型容器,以提高我們的開發和系統的執行效率。
2.4 泛型的主要約束和次要約束是什麼?
當一個泛型引數沒有任何約束時,它可以進行的操作和運算是非常有限的,因為不能對實參進行任何型別上的保證,這時候就需要用到泛型約束。泛型的約束分為:主要約束和次要約束,它們都使實參必須滿足一定的規範,C#編譯器在編譯的過程中可以根據約束來檢查所有泛型型別的實參並確保其滿足約束條件。
(1)主要約束
一個泛型引數至多擁有一個主要約束,主要約束可以是一個引用型別、class或者struct。如果指定一個引用型別(class),那麼實參必須是該型別或者該型別的派生型別。相反,struct則規定了實參必須是一個值型別。下面的程式碼展示了泛型引數主要約束:
public class ClassT1<T> where T : Exception { private T myException; public ClassT1(T t) { myException = t; } public override string ToString() { // 主要約束保證了myException擁有source成員 return myException.Source; } } public class ClassT2<T> where T : class { private T myT; public void Clear() { // T是引用型別,可以置null myT = null; } } public class ClassT3<T> where T : struct { private T myT; public override string ToString() { // T是值型別,不會發生NullReferenceException異常 return myT.ToString(); } }View Code
泛型引數有了主要約束後,也就能夠在型別中對其進行一定的操作了。
(2)次要約束
次要約束主要是指實參實現的介面的限定。對於一個泛型,可以有0到無限的次要約束,次要約束規定了實參必須實現所有的次要約束中規定的介面。次要約束與主要約束的語法基本一致,區別僅在於提供的不是一個引用型別而是一個或多個介面。例如我們為上面程式碼中的ClassT3增加一個次要約束:
public class ClassT3<T> where T : struct, IComparable { ...... }View Code
三、流和序列化
3.1 流的概念以及.NET中有哪些常見的流?
流是一種針對位元組流的操作,它類似於記憶體與檔案之間的一個管道。在對一個檔案進行處理時,本質上需要經過藉助OS提供的API來進行開啟檔案,讀取檔案中的位元組流,再關閉檔案等操作,其中讀取檔案的過程就可以看作是位元組流的一個過程。

常見的流型別包括:檔案流、終端操作流以及網路Socket等,在.NET中,System.IO.Stream型別被設計為作為所有流型別的虛基類,所有的常見流型別都繼承自System.IO.Stream型別,當我們需要自定義一種流型別時,也應該直接或者間接地繼承自Stream型別。下圖展示了在.NET中常見的流型別以及它們的型別結構:

從上圖中可以發現,Stream型別繼承自MarshalByRefObject型別,這保證了流型別可以跨越應用程式域進行互動。所有常用的流型別都繼承自System.IO.Stream型別,這保證了流型別的同一性,並且遮蔽了底層的一些複雜操作,使用起來非常方便。
下面的程式碼中展示瞭如何在.NET中使用FileStream檔案流進行簡單的檔案讀寫操作:
class Program { private const int bufferlength = 1024; static void Main(string[] args) { //建立一個檔案,並寫入內容 string filename = @"C:\TestStream.txt"; string filecontent = GetTestString(); try { if (File.Exists(filename)) { File.Delete(filename); } // 建立檔案並寫入內容 using (FileStream fs = new FileStream(filename, FileMode.Create)) { Byte[] bytes = Encoding.UTF8.GetBytes(filecontent); fs.Write(bytes, 0, bytes.Length); } // 讀取檔案並打印出來 using (FileStream fs = new FileStream(filename, FileMode.Open)) { Byte[] bytes = new Byte[bufferlength]; UTF8Encoding encoding = new UTF8Encoding(true); while (fs.Read(bytes, 0, bytes.Length) > 0) { Console.WriteLine(encoding.GetString(bytes)); } } // 迴圈分批讀取列印 //using (FileStream fs = new FileStream(filename, FileMode.Open, FileAccess.Read)) //{ // Byte[] bytes = new Byte[bufferlength]; // int bytesRead; // do //