
MySQL MHA高可用方案
四、配置relay_log的清除方式(在每個Node上)
(1)所有Node的cnf配置檔案加上
relay_log_purge=0
MHA在發生切換的過程中,從庫的恢復過程中依賴於relay log的相關資訊,所以這裡要將relay log的自動清除設定為OFF,採用手動清除relay log的方式。
在預設情況下,從伺服器上的中繼日誌會在SQL執行緒執行完畢後被自動刪除。但是在MHA環境中,這些中繼日誌在恢復其他從伺服器時可能會被用到,因此需要禁用中繼日誌的自動刪除功能。定期清除中繼日誌需要考慮到複製延時的問題。在ext3的檔案系統下,刪除大的檔案需要一定的時間,會導致嚴重的複製延時。為了避免複製延時,需要暫時為中繼日誌建立硬連結,因為在linux系統中通過硬連結刪除大檔案速度會很快。
提示:在mysql資料庫中,刪除大表時,通常也採用建立硬連結的方式
MHA節點中包含了pure_relay_logs命令工具,它可以為中繼日誌建立硬連結,執行SET GLOBAL relay_log_purge=1,等待幾秒鐘以便SQL執行緒切換到新的中繼日誌,再執行SET GLOBAL relay_log_purge=0。
pure_relay_logs指令碼引數如下所示:
--user mysql 使用者名稱 --password mysql 密碼 --port 埠號 --workdir 指定建立relay log的硬連結的位置,預設是/var/tmp,由於系統不同分割槽建立硬連結檔案會失敗,故需要執行硬連結具體位置,成功執行指令碼後,硬連結的中繼日誌檔案被刪除 --disable_relay_log_purge 預設情況下,如果relay_log_purge=1,指令碼會什麼都不清理,自動退出,通過設定這個引數,當relay_log_purge=1的情況下會將relay_log_purge設定為0。清理relay log之後,最後將引數設定為OFF。
(2)在每臺slave Node上建立
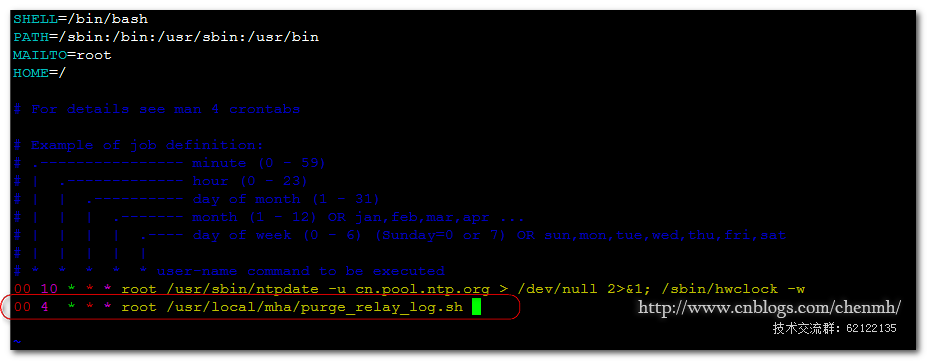
vim /usr/local/mha/purge_relay_log.sh
#!/bin/bash
user=root
passwd=root ####確保使用者和密碼能通過127.0.0.1登入
host='127.0.0.1'
port=3306
work_dir='/mysql/data'
purge='/usr/local/mha/bin/purge_relay_logs'
$purge --user=$user --password=$passwd --host=$host --disable_relay_log_purge --port=$port --workdir=$work_dir >> /usr/local/mha/purge_relay_logs.log 2>&1
chmod u+x /usr/local/mha/purge_relay_log.sh
將指令碼加入到os定時任務中
五、檢測啟動MHA
1.檢查ssh配置
masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf
[root@monitor ha1]# masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf Thu Aug 25 14:53:30 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Aug 25 14:53:30 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 14:53:30 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 14:53:30 2016 - [info] Starting SSH connection tests.. Thu Aug 25 14:53:35 2016 - [debug] Thu Aug 25 14:53:31 2016 - [debug] Connecting via SSH from [email protected]192.168.137.20(192.168.137.20:22) to [email protected]192.168.137.10(192.168.137.10:22).. Thu Aug 25 14:53:33 2016 - [debug] ok. Thu Aug 25 14:53:33 2016 - [debug] Connecting via SSH from [email protected]192.168.137.20(192.168.137.20:22) to [email protected]192.168.137.30(192.168.137.30:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:35 2016 - [debug] Thu Aug 25 14:53:31 2016 - [debug] Connecting via SSH from [email protected]192.168.137.30(192.168.137.30:22) to [email protected]192.168.137.10(192.168.137.10:22).. Thu Aug 25 14:53:33 2016 - [debug] ok. Thu Aug 25 14:53:33 2016 - [debug] Connecting via SSH from [email protected]192.168.137.30(192.168.137.30:22) to [email protected]192.168.137.20(192.168.137.20:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:36 2016 - [debug] Thu Aug 25 14:53:30 2016 - [debug] Connecting via SSH from [email protected]192.168.137.10(192.168.137.10:22) to [email protected]192.168.137.20(192.168.137.20:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:34 2016 - [debug] Connecting via SSH from [email protected]192.168.137.10(192.168.137.10:22) to [email protected]192.168.137.30(192.168.137.30:22).. Thu Aug 25 14:53:35 2016 - [debug] ok. Thu Aug 25 14:53:36 2016 - [info] All SSH connection tests passed successfully.
可以看到每個Node到其它的Node都是相通的。
2.檢查整個複製環境
masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf


[root@monitor ha1]# masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf Thu Aug 25 16:09:19 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Aug 25 16:09:19 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 16:09:19 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 16:09:19 2016 - [info] MHA::MasterMonitor version 0.55. Thu Aug 25 16:09:20 2016 - [info] Dead Servers: Thu Aug 25 16:09:20 2016 - [info] Alive Servers: Thu Aug 25 16:09:20 2016 - [info] 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] 192.168.137.20(192.168.137.20:3306) Thu Aug 25 16:09:20 2016 - [info] 192.168.137.30(192.168.137.30:3306) Thu Aug 25 16:09:20 2016 - [info] Alive Slaves: Thu Aug 25 16:09:20 2016 - [info] 192.168.137.20(192.168.137.20:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Thu Aug 25 16:09:20 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] Primary candidate for the new Master (candidate_master is set) Thu Aug 25 16:09:20 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Thu Aug 25 16:09:20 2016 - [info] Replicating from 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] Not candidate for the new Master (no_master is set) Thu Aug 25 16:09:20 2016 - [info] Current Alive Master: 192.168.137.10(192.168.137.10:3306) Thu Aug 25 16:09:20 2016 - [info] Checking slave configurations.. Thu Aug 25 16:09:20 2016 - [info] read_only=1 is not set on slave 192.168.137.20(192.168.137.20:3306). Thu Aug 25 16:09:20 2016 - [info] Checking replication filtering settings.. Thu Aug 25 16:09:20 2016 - [info] binlog_do_db= , binlog_ignore_db= Thu Aug 25 16:09:20 2016 - [info] Replication filtering check ok. Thu Aug 25 16:09:20 2016 - [info] Starting SSH connection tests.. Thu Aug 25 16:09:25 2016 - [info] All SSH connection tests passed successfully. Thu Aug 25 16:09:25 2016 - [info] Checking MHA Node version.. Thu Aug 25 16:09:26 2016 - [info] Version check ok. Thu Aug 25 16:09:26 2016 - [info] Checking SSH publickey authentication settings on the current master.. Thu Aug 25 16:09:27 2016 - [info] HealthCheck: SSH to 192.168.137.10 is reachable. Thu Aug 25 16:09:29 2016 - [info] Master MHA Node version is 0.54. Thu Aug 25 16:09:29 2016 - [info] Checking recovery script configurations on the current master.. Thu Aug 25 16:09:29 2016 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/mysql/log --output_file=/tmp/save_binary_logs_test --manager_version=0.55 --start_file=mysql-bin.000138 Thu Aug 25 16:09:29 2016 - [info] Connecting to [email protected]192.168.137.10(192.168.137.10).. Creating /tmp if not exists.. ok. Checking output directory is accessible or not.. ok. Binlog found at /mysql/log, up to mysql-bin.000138 Thu Aug 25 16:09:30 2016 - [info] Master setting check done. Thu Aug 25 16:09:30 2016 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers.. Thu Aug 25 16:09:30 2016 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=192.168.137.20 --slave_ip=192.168.137.20 --slave_port=3306 --workdir=/tmp --target_version=5.6.15-log --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ --slave_pass=xxx Thu Aug 25 16:09:30 2016 - [info] Connecting to [email protected]192.168.137.20(192.168.137.20:22).. Checking slave recovery environment settings.. Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000006 Temporary relay log file is /mysql/data/mysql-relay-bin.000006 Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Thu Aug 25 16:09:31 2016 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='root' --slave_host=192.168.137.30 --slave_ip=192.168.137.30 --slave_port=3306 --workdir=/tmp --target_version=5.6.15-log --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ --slave_pass=xxx Thu Aug 25 16:09:31 2016 - [info] Connecting to [email protected]192.168.137.30(192.168.137.30:22).. Checking slave recovery environment settings.. Opening /mysql/data/relay-log.info ... ok. Relay log found at /mysql/data, up to mysql-relay-bin.000002 Temporary relay log file is /mysql/data/mysql-relay-bin.000002 Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure. done. Testing mysqlbinlog output.. done. Cleaning up test file(s).. done. Thu Aug 25 16:09:32 2016 - [info] Slaves settings check done. Thu Aug 25 16:09:32 2016 - [info] 192.168.137.10 (current master) +--192.168.137.20 +--192.168.137.30 Thu Aug 25 16:09:32 2016 - [info] Checking replication health on 192.168.137.20.. Thu Aug 25 16:09:32 2016 - [info] ok. Thu Aug 25 16:09:32 2016 - [info] Checking replication health on 192.168.137.30.. Thu Aug 25 16:09:32 2016 - [info] ok. Thu Aug 25 16:09:32 2016 - [info] Checking master_ip_failover_script status: Thu Aug 25 16:09:32 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Checking the Status of the script.. OK Thu Aug 25 16:09:32 2016 - [info] OK. Thu Aug 25 16:09:32 2016 - [warning] shutdown_script is not defined. Thu Aug 25 16:09:32 2016 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.View Code
--ignore_fail_on_start: 當有slave 節點宕掉時,預設是啟動不了的,加上 --ignore_fail_on_start 即使有節點宕掉也能啟動MHA,加上該引數會忽略啟動檔案中配置ignore_fail=1的server
3.檢查MHA Manager狀態
masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf

由於mha還沒有啟動,所以這裡檢測是stopped
4.啟動MHA
nohup masterha_manager --conf=/usr/local/mha/ha1/ha1.cnf --ignore_fail_on_start --ignore_last_failover < /dev/null > /usr/local/mha/ha1/start.log 2>&1 &
--remove_dead_master_conf:該引數代表當發生主從切換後,老的主庫的ip將會從配置檔案中移除。這裡暫時不使用該引數,因為發生使用該引數會將ha1.cnf配置檔案搞亂。
--start_log:日誌。
--ignore_last_failover:發生主從切換後,MHAmanager服務會自動停掉,且在manager_workdir目錄下面生成檔案app1.failover.complete,若要啟動MHA,必須先刪除該檔案,該引數代表忽略上次MHA觸發切換產生的檔案,這裡設定為-ignore_last_failover。 在預設情況下,如果MHA檢測到連續發生宕機,且兩次宕機間隔不足8小時的話,則不會進行Failover,之所以這樣限制是為了避免ping-pong效應。
--ignore_fail_on_start: 當有slave 節點宕掉時,預設是啟動不了的,加上 --ignore_fail_on_start 即使有節點宕掉也能啟動MHA,加上該引數會忽略啟動檔案中配置ignore_fail=1的server。
(1)再次檢視MHA狀態是否正常:
[root@monitor ha1]# masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf ha1 (pid:6371) is running(0:PING_OK), master:192.168.137.10 [root@monitor ha1]#
(2)檢視啟動日誌
cat manager.log
Thu Aug 25 17:11:50 2016 - [info] 192.168.137.10 (current master) +--192.168.137.20 +--192.168.137.30 Thu Aug 25 17:11:50 2016 - [info] Checking master_ip_failover_script status: Thu Aug 25 17:11:50 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Checking the Status of the script.. OK Thu Aug 25 17:11:50 2016 - [info] OK. Thu Aug 25 17:11:50 2016 - [warning] shutdown_script is not defined. Thu Aug 25 17:11:50 2016 - [info] Set master ping interval 1 seconds. Thu Aug 25 17:11:50 2016 - [info] Set secondary check script: /usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 Thu Aug 25 17:11:50 2016 - [info] Starting ping health check on 192.168.137.10(192.168.137.10:3306).. Thu Aug 25 17:11:50 2016 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond.. [[email protected] ha1]#
(3)產生的檔案
ha1.master_status.health:mha正常啟動會產生該檔案
manager.log:mha監控日誌
start.log:mha啟動時生成的日誌
5.關閉MHA
masterha_stop --conf=/usr/local/mha/ha1/ha1.cnf
六、故障處理步驟
發生主從切換後,MHA服務會自動停掉
1.檢查日誌
檢查故障處理的日誌,確保故障正常轉移。
cat /usr/local/mha/ha1/manager.log
2.處理故障master
處理故障的master,將其配置為從庫chang到新的master,可以從manager.log找到change語句。
grep "CHANGE MASTER TO MASTER" /usr/local/mha/ha1/manager.log | tail -1
Fri Aug 26 12:04:22 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.10', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000143', MASTER_LOG_POS=22123166, MASTER_USER='repl', MASTER_PASSWORD='xxx';
注意:這裡要確保slave的SQL_THREAD和IO_TRREAD正常,如果是配置半同步複製要確保半同步複製啟動正常,可以執行"show status like '%rpl_%';",具體參考前面半同步複製的搭建。
3.修改ha1.cnf配置檔案
需要修改"secondary_check_script"選項中的master_host、master_ip、master_port為新的master;如果兩臺電腦的配置都相同的話其它地方不用修改。
4.刪除fail檔案(非必需)
由於啟動mha的時候加上了--ignore_last_failover引數,所以不刪除failower生成的檔案也能啟動,否則需要刪除failower生成的檔案“ha1.failover.complete”。
rm -f /usr/local/mha/ha1/ha1.failover.complete
5.check檢查
檢查SSH配置 masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf 檢查複製 masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf 檢查狀態 masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf
必需保證所有的檢查都通過
6.啟動MHA
nohup masterha_manager --conf=/usr/local/mha/ha1/ha1.cnf --ignore_fail_on_start --ignore_last_failover < /dev/null > /usr/local/mha/ha1/start.log 2>&1 &
七、模擬Failover
1.自動failover
我這裡是非同步複製,137.20是當前的master,然後在137.20上執行併發插入,同時關閉137.10和137.30的IO執行緒,在137.20上壓測一段時間,然後先開啟137.30的IO執行緒,過幾秒鐘再開啟137.10的IO執行緒;保證137.30的binlog比候選的137.10的binlog更新。
master 137.20(22497564)
candidate slave:137.10(pos=9857376)
new replay slave:137.30(pos=22461852)
Fri Aug 26 11:57:36 2016 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query) Fri Aug 26 11:57:36 2016 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/mysql/log --output_file=/tmp/save_binary_logs_test --manager_version=0.55 --binlog_prefix=mysql-bin Fri Aug 26 11:57:36 2016 - [info] Executing seconary network check script: /usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 --user=root --master_host=192.168.137.20 --master_ip=192.168.137.20 --master_port=3306 Fri Aug 26 11:57:37 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111)) Fri Aug 26 11:57:37 2016 - [warning] Connection failed 1 time(s).. Fri Aug 26 11:57:38 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111)) Fri Aug 26 11:57:38 2016 - [warning] Connection failed 2 time(s).. Fri Aug 26 11:57:38 2016 - [info] HealthCheck: SSH to 192.168.137.20 is reachable. Monitoring server backup is reachable, Master is not reachable from backup. OK. Fri Aug 26 11:57:39 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111)) Fri Aug 26 11:57:39 2016 - [warning] Connection failed 3 time(s).. Monitoring server master is reachable, Master is not reachable from master. OK. Fri Aug 26 11:57:41 2016 - [info] Master is not reachable from all other monitoring servers. Failover should start. Fri Aug 26 11:57:41 2016 - [warning] Master is not reachable from health checker! Fri Aug 26 11:57:41 2016 - [warning] Master 192.168.137.20(192.168.137.20:3306) is not reachable! Fri Aug 26 11:57:41 2016 - [warning] SSH is reachable. Fri Aug 26 11:57:41 2016 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /usr/local/mha/ha1/ha1.cnf again, and trying to connect to all servers to check server status.. Fri Aug 26 11:57:41 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Aug 26 11:57:41 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Fri Aug 26 11:57:41 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Fri Aug 26 11:57:42 2016 - [info] Dead Servers: Fri Aug 26 11:57:42 2016 - [info] 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:42 2016 - [info] Alive Servers: Fri Aug 26 11:57:42 2016 - [info] 192.168.137.10(192.168.137.10:3306) Fri Aug 26 11:57:42 2016 - [info] 192.168.137.30(192.168.137.30:3306) Fri Aug 26 11:57:42 2016 - [info] Alive Slaves: Fri Aug 26 11:57:42 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:42 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:42 2016 - [info] Primary candidate for the new Master (candidate_master is set) Fri Aug 26 11:57:42 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled Fri Aug 26 11:57:42 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306) Fri Aug 26 11:57:42 2016 - [info] Not candidate for the new Master (no_master is set) Fri Aug 26 11:57:42 2016 - [info] Checking slave configurations.. Fri Aug 26 11:57:42 2016 - [info] read_only=1 is not set on slave 192.168.137.10(192.168.137.10:3306). Fri Aug 26 11:57:42 2016 - [info] Checking replication filtering settings.. Fri Aug 26 11:57:42 2016 - [info] Replication filtering check ok. Fri Aug 26 11:57:42 2016 - [info] Master is down! Fri Aug 26 11:57:42 2016 - [info] Terminating monitoring script. Fri Aug 26 11:57:42 2016 - [info] Got exit code 20 (Master dead). Fri Aug 26 11:57:42 2016 - [info] MHA::MasterFailover version 0.55. Fri Aug 26 11: