
GAN原理解析,公式推導與python實現
1-生成模型
1-1 生成模型與判別模型
生成式對抗網路,顧名思義就是生成模型嘛!那什麼是生成模型呢?與判別模型有什麼區別呢?
先來理解一下判別模型。
學過機器學習的人都知道,入門級的演算法邏輯迴歸,最後的預測,是通過sigmoid函式:
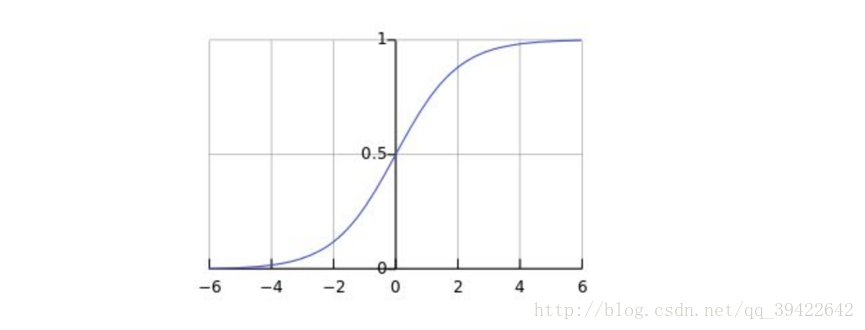
生成一個0-1之間的數值,然後用某一閥值來做分類,我們稱之為判別模型:由資料直接學習,通過決策函式
而生成模型,則先學習出一個聯合概率密度分佈
生成模型的核心,就是先求兩個比較好求的概率,然後通過貝葉斯概率公式這樣的關係來進行分類。
簡單的看,
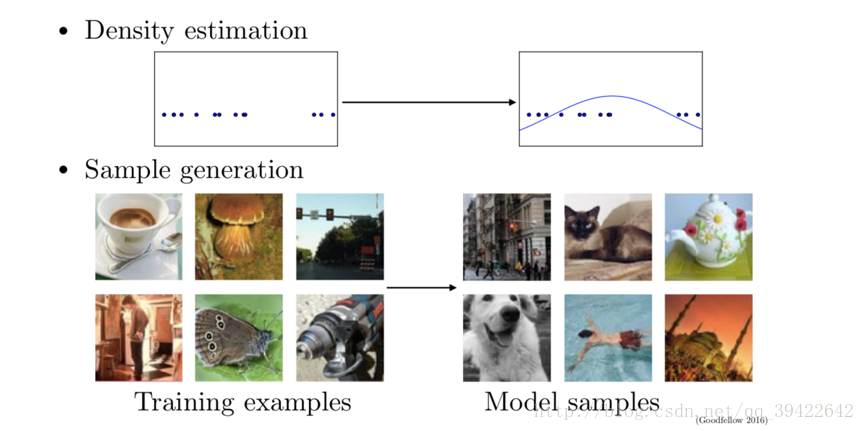
1-2 為什麼學習生成模型?
我們可以總結一下它的優點:
- 能生成高維的資料或者複雜的概率分佈,且高維資料分佈在數學和工業界都扮演著重要的作用
- 還可以為強化學習做一定準備
- 對於缺失資料較多的場景,可以用來生成更多的樣例資料,是當前用來解決資訊缺失的最好方式。
舉一些例子:
Next Video Frame Prediction
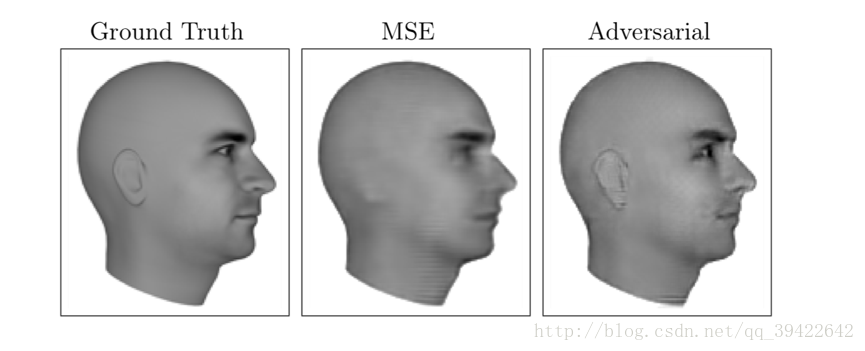
大概意思是預測下一幀會是什麼?比如第一個頭像是當前幀的狀態,然後給出一個MSE(均方差矩陣),預測下一幀會出現什麼,如圖就是頭轉了大約15度或者30度左右的樣子。
很明顯,這個應用是很強大的,比如某些打碼的片子,甚者打碼的圖片,三級片之類的,或者有損失的古物,古畫,都有可能通過生成模型,來生成新的。
Single Image Super-Resolution

或者處理比較模糊的圖片,因為畫素太低,導致人看了不怎麼清楚,可以通過GAN來生成更高畫素的圖片,看的更清晰。上圖左為原始圖片,第二張為 使用bicubic method的插值法得出的,第三張是使用ResNet,第四張是使用GAN來生成的。
Image to Image Translation

根據你畫的樣子,給你生成一個你可能想都沒想過的樣子,或者根據地圖,生成場景之類的。
總之,GAN的特點之一,就是生成,生成一些你可能想都沒想過的東西。
1-3 生成模型原理—似然原理
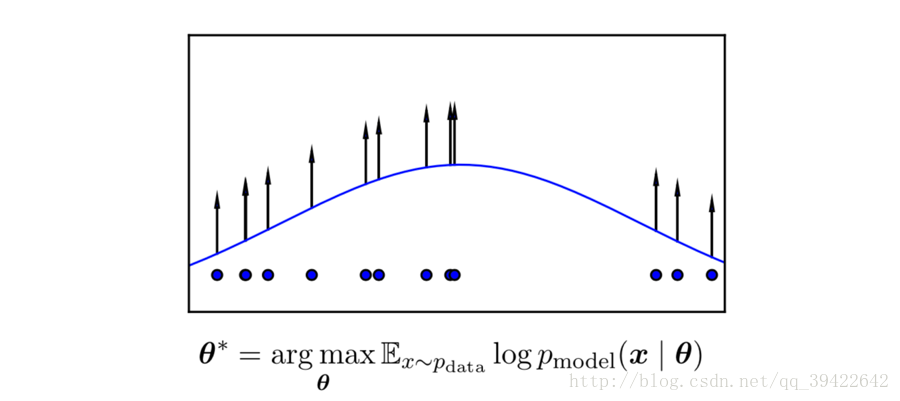
所謂的生成模型,其實就是基於最大似然估計的,而最大似然估計就是用的似然原理。
什麼是似然原理呢?我們舉個例子,比如你要估計一個學校的數學成績是多少,肯定不會直接找全校的學生,然後再把他們的數學成績放在一起計算吧。因為這樣做的代價太大了,現實情況根本不允許。
那我們該怎麼辦呢?
那我們可以隨機取樣嘛,用樣本來估計總體。什麼意思呢?我們知道一個群體的某一形狀假如服從正態分佈,如圖所示,那麼這個分佈的形狀由兩方面決定,分別是均值
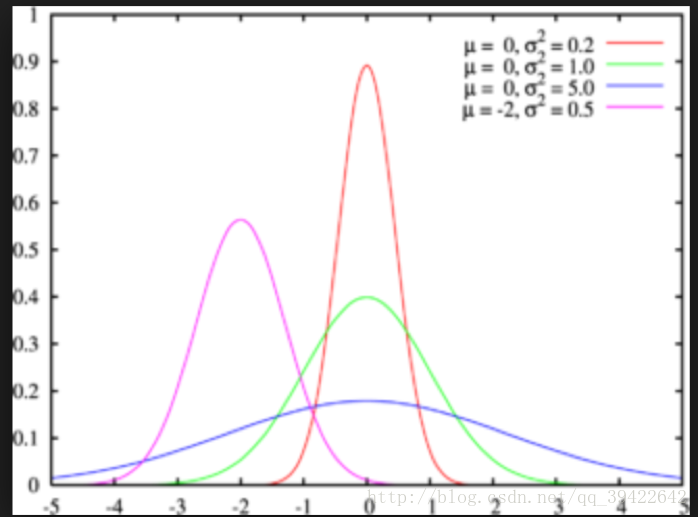
那我們能否用樣本(抽到的學生)的均值和方差,估計總體(整個學校的學生)的均值和方差,這樣不就得到了總體的概率分佈了嗎?其實這就是生成模型的原理。
想要詳細瞭解它的公式推導,可以看一下這篇的最後一個部分:概率統計學習基礎
2-生成式對抗網路
2-1 生成式對抗網路工作原理
前面我們說的都是前期知識準備,瞭解生成模型,接下來看一下真正的生成式對抗網路,它的工作流如下:
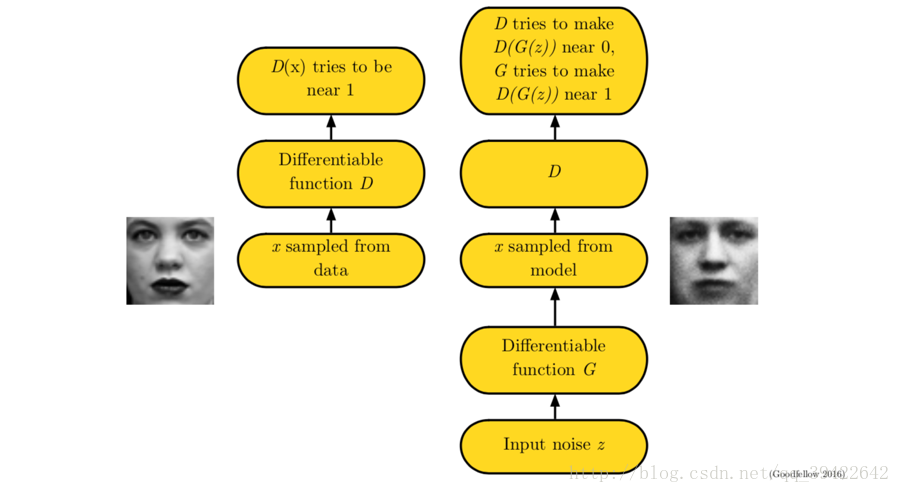
GAN是一種structured probabilistic model,具體介紹在deep learning這本書的第16章有。
顧名思義,生成-對抗,其核心也是兩個,一個是生成,用圖中的
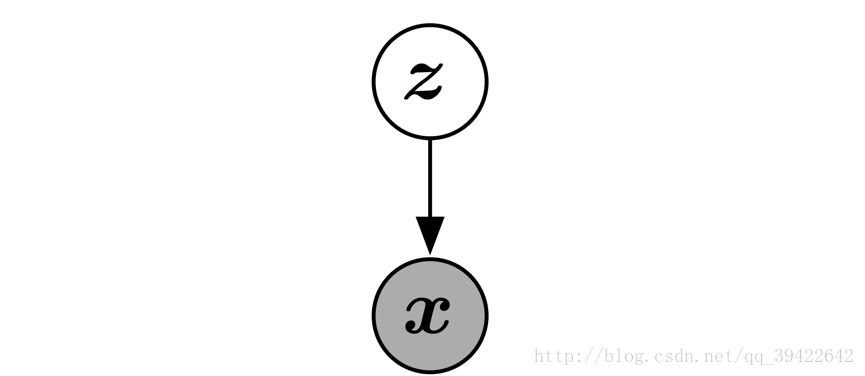
GAN是一個有向圖模型,它的每一個隱變數都在影響觀測變數。
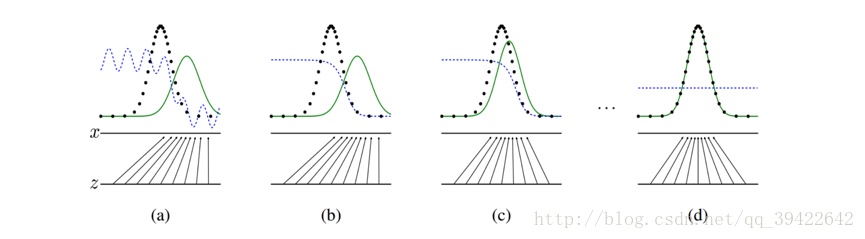
我們希望達到的效果,就如上圖所示,生成式對抗網路會訓練並更新判別分佈(D,圖中藍色虛線部分),希望能將真實的分佈(
主要目標就兩個:
- 判別器
D(x) 獨自訓練自己,希望能分辨出真實的資料分佈和生成器給的資料分佈 - 生成器
G(z) 也訓練自己,希望以假亂真,讓判別器判別不出到底哪個是真,哪個是假
我們輸入noise樣本給
如果
- 舉個例子,這個過程就像是一個畫畫的老師在教,或者說監督學生畫畫一樣,老師就是對抗的部分,學生就是生成部分。老師手上有一副真的蒙娜麗莎,學生手上有一副蒙娜麗莎的贗品,學生在模仿贗品畫蒙娜麗莎,然後給老師看,老實說你這裡畫得不像,重來,然後不斷改進,直到學生畫得蒙娜麗莎老師分辨不出來到底是真是假是,訓練停止。
判別部分(Generator Network)
輸入z,通過對應的引數,能生成x,x屬於生成的概率分佈:
訓練過程
GAN的訓練過程也是使用SGD,或者其他的優化演算法來做優化,一般使用minibatch,值得注意的是,我們可以讓其中一個先跑一下,一般讓生成部分先跑, 使得生成的效率更高一點。
2-2 判別器的損失函式
一個演算法模型最重要的,莫過於損失函式和優化的方法了,對於判別部分來說,所有的GAN變體都是使用相同的損失函式
首先我們必須先定義樣本是從真實分佈
另一項是根據負類的對數損失函式構建的: