
TCP的那些事(下)
原文連結:https://coolshell.cn/articles/11609.html
這篇文章是下篇,所以如果你對TCP不熟悉的話,還請你先看看上篇《TCP的那些事兒(上)》 上篇中,我們介紹了TCP的協議頭、狀態機、資料重傳中的東西。但是TCP要解決一個很大的事,那就是要在一個網路根據不同的情況來動態調整自己的發包的速度,小則讓自己的連線更穩定,大則讓整個網路更穩定。在你閱讀下篇之前,你需要做好準備,本篇文章有好些演算法和策略,可能會引發你的各種思考,讓你的大腦分配很多記憶體和計算資源,所以,不適合在廁所中閱讀。
TCP的RTT演算法
從前面的TCP重傳機制我們知道Timeout的設定對於重傳非常重要。
- 設長了,重發就慢,丟了老半天才重發,沒有效率,效能差;
- 設短了,會導致可能並沒有丟就重發。於是重發的就快,會增加網路擁塞,導致更多的超時,更多的超時導致更多的重發。
而且,這個超時時間在不同的網路的情況下,根本沒有辦法設定一個死的值。只能動態地設定。 為了動態地設定,TCP引入了RTT——Round Trip Time,也就是一個數據包從發出去到回來的時間。這樣傳送端就大約知道需要多少的時間,從而可以方便地設定Timeout——RTO(Retransmission TimeOut),以讓我們的重傳機制更高效。 聽起來似乎很簡單,好像就是在傳送端發包時記下t0,然後接收端再把這個ack回來時再記一個t1,於是RTT = t1 – t0。沒那麼簡單,這只是一個取樣,不能代表普遍情況。
經典演算法
RFC793 中定義的經典演算法是這樣的:
1)首先,先採樣RTT,記下最近好幾次的RTT值。
2)然後做平滑計算SRTT( Smoothed RTT)。公式為:(其中的 α 取值在0.8 到 0.9之間,這個演算法英文叫Exponential weighted moving average,中文叫:加權移動平均)
SRTT = ( α * SRTT ) + ((1- α) * RTT)
3)開始計算RTO。公式如下:
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ]
其中:
- UBOUND是最大的timeout時間,上限值
- LBOUND是最小的timeout時間,下限值
- β 值一般在1.3到2.0之間。
Karn / Partridge 演算法
但是上面的這個演算法在重傳的時候會出有一個終極問題——你是用第一次發資料的時間和ack回來的時間做RTT樣本值,還是用重傳的時間和ACK回來的時間做RTT樣本值?
這個問題無論你選那頭都是按下葫蘆起了瓢。 如下圖所示:
- 情況(a)是ack沒回來,所以重傳。如果你計算第一次傳送和ACK的時間,那麼,明顯算大了。
- 情況(b)是ack回來慢了,但是導致了重傳,但剛重傳不一會兒,之前ACK就回來了。如果你是算重傳的時間和ACK回來的時間的差,就會算短了。
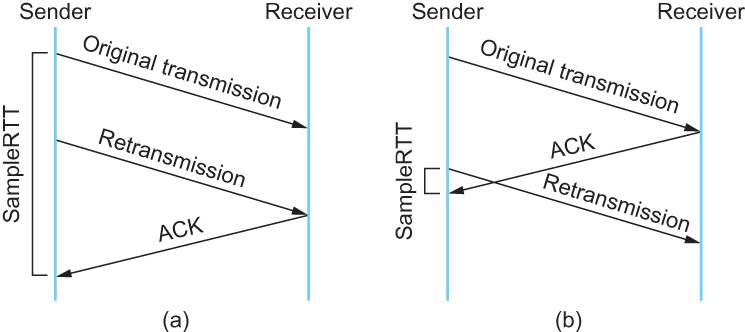
所以1987年的時候,搞了一個叫Karn / Partridge Algorithm,這個演算法的最大特點是——忽略重傳,不把重傳的RTT做取樣(你看,你不需要去解決不存在的問題)。
但是,這樣一來,又會引發一個大BUG——如果在某一時間,網路閃動,突然變慢了,產生了比較大的延時,這個延時導致要重轉所有的包(因為之前的RTO很小),於是,因為重轉的不算,所以,RTO就不會被更新,這是一個災難。 於是Karn演算法用了一個取巧的方式——只要一發生重傳,就對現有的RTO值翻倍(這就是所謂的 Exponential backoff),很明顯,這種死規矩對於一個需要估計比較準確的RTT也不靠譜。
Jacobson / Karels 演算法
前面兩種演算法用的都是“加權移動平均”,這種方法最大的毛病就是如果RTT有一個大的波動的話,很難被發現,因為被平滑掉了。所以,1988年,又有人推出來了一個新的演算法,這個演算法叫Jacobson / Karels Algorithm(參看RFC6289)。這個演算法引入了最新的RTT的取樣和平滑過的SRTT的差距做因子來計算。 公式如下:(其中的DevRTT是Deviation RTT的意思)
SRTT = SRTT + α (RTT – SRTT) —— 計算平滑RTT
DevRTT = (1-β)*DevRTT + β*(|RTT-SRTT|) ——計算平滑RTT和真實的差距(加權移動平均)
RTO= µ * SRTT + ∂ *DevRTT —— 神一樣的公式
(其中:在Linux下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——這就是演算法中的“調得一手好引數”,nobody knows why, it just works…) 最後的這個演算法在被用在今天的TCP協議中(Linux的原始碼在:tcp_rtt_estimator)。
TCP滑動視窗
需要說明一下,如果你不瞭解TCP的滑動視窗這個事,你等於不瞭解TCP協議。我們都知道,TCP必需要解決的可靠傳輸以及包亂序(reordering)的問題,所以,TCP必需要知道網路實際的資料處理頻寬或是資料處理速度,這樣才不會引起網路擁塞,導致丟包。
所以,TCP引入了一些技術和設計來做網路流控,Sliding Window是其中一個技術。 前面我們說過,TCP頭裡有一個欄位叫Window,又叫Advertised-Window,這個欄位是接收端告訴傳送端自己還有多少緩衝區可以接收資料。於是傳送端就可以根據這個接收端的處理能力來發送資料,而不會導致接收端處理不過來。 為了說明滑動視窗,我們需要先看一下TCP緩衝區的一些資料結構:
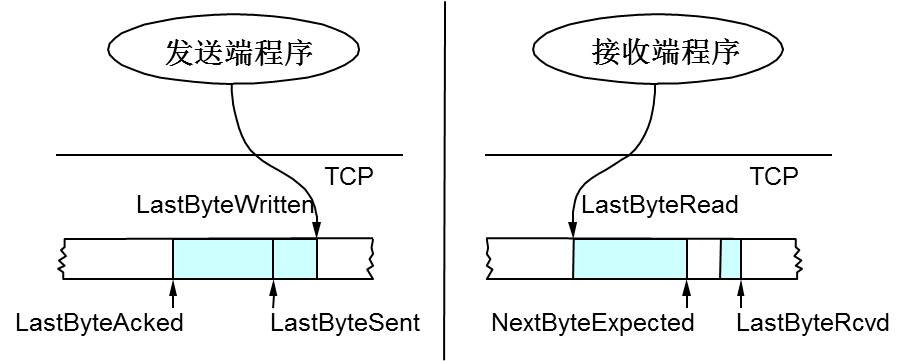
上圖中,我們可以看到:
- 接收端LastByteRead指向了TCP緩衝區中讀到的位置,NextByteExpected指向的地方是收到的連續包的最後一個位置,LastByteRcved指向的是收到的包的最後一個位置,我們可以看到中間有些資料還沒有到達,所以有資料空白區。
- 傳送端的LastByteAcked指向了被接收端Ack過的位置(表示成功傳送確認),LastByteSent表示發出去了,但還沒有收到成功確認的Ack,LastByteWritten指向的是上層應用正在寫的地方。
於是:
- 接收端在給傳送端回ACK中會彙報自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
- 而傳送方會根據這個視窗來控制傳送資料的大小,以保證接收方可以處理。
下面我們來看一下發送方的滑動視窗示意圖:
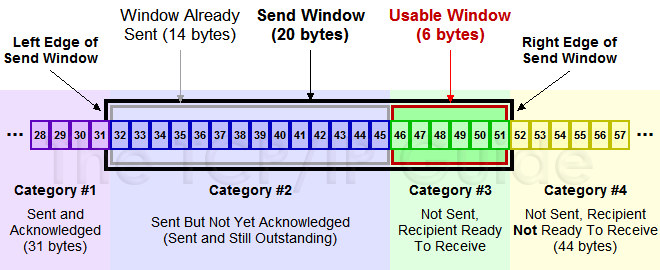
(圖片來源)
上圖中分成了四個部分,分別是:(其中那個黑模型就是滑動視窗)
- #1已收到ack確認的資料。
- #2發還沒收到ack的。
- #3在視窗中還沒有發出的(接收方還有空間)。
- #4視窗以外的資料(接收方沒空間)
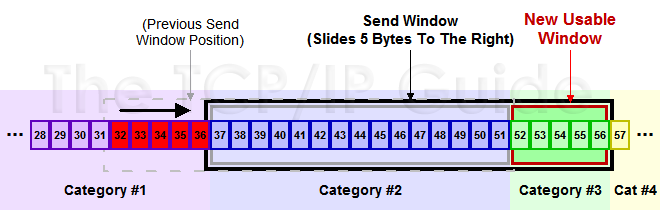
下面是個滑動後的示意圖(收到36的ack,併發出了46-51的位元組):
下面我們來看一個接受端控制傳送端的圖示:
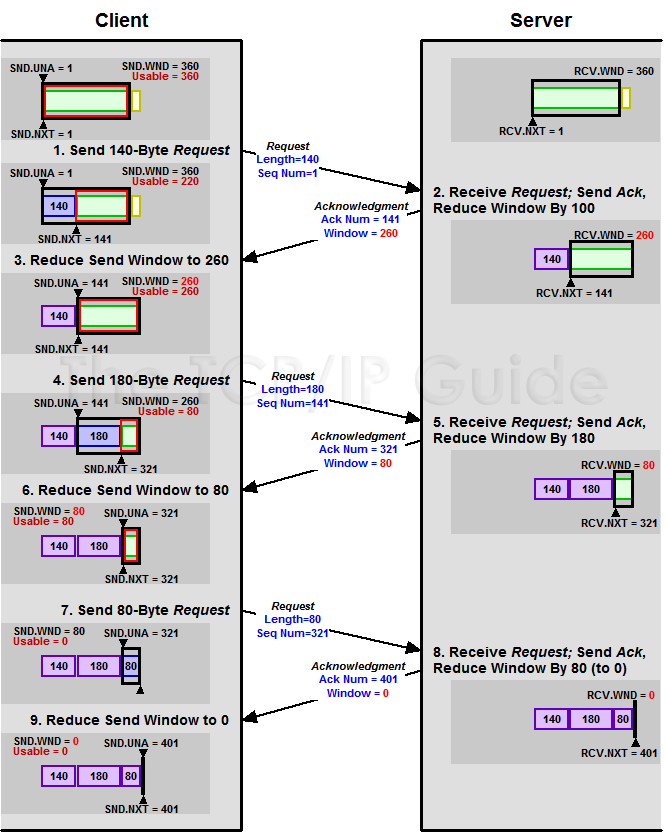
(圖片來源)
Zero Window
上圖,我們可以看到一個處理緩慢的Server(接收端)是怎麼把Client(傳送端)的TCP Sliding Window給降成0的。此時,你一定會問,如果Window變成0了,TCP會怎麼樣?是不是傳送端就不發資料了?是的,傳送端就不發資料了,你可以想像成“Window Closed”,那你一定還會問,如果傳送端不發資料了,接收方一會兒Window size 可用了,怎麼通知傳送端呢?
解決這個問題,TCP使用了Zero Window Probe技術,縮寫為ZWP,也就是說,傳送端在視窗變成0後,會發ZWP的包給接收方,讓接收方來ack他的Window尺寸,一般這個值會設定成3次,第次大約30-60秒(不同的實現可能會不一樣)。如果3次過後還是0的話,有的TCP實現就會發RST把連結斷了。
注意:只要有等待的地方都可能出現DDoS攻擊,Zero Window也不例外,一些攻擊者會在和HTTP建好鏈發完GET請求後,就把Window設定為0,然後服務端就只能等待進行ZWP,於是攻擊者會併發大量的這樣的請求,把伺服器端的資源耗盡。(關於這方面的攻擊,大家可以移步看一下Wikipedia的SockStress詞條)
另外,Wireshark中,你可以使用tcp.analysis.zero_window來過濾包,然後使用右鍵選單裡的follow TCP stream,你可以看到ZeroWindowProbe及ZeroWindowProbeAck的包。
Silly Window Syndrome
Silly Window Syndrome翻譯成中文就是“糊塗視窗綜合症”。正如你上面看到的一樣,如果我們的接收方太忙了,來不及取走Receive Windows裡的資料,那麼,就會導致傳送方越來越小。到最後,如果接收方騰出幾個位元組並告訴傳送方現在有幾個位元組的window,而我們的傳送方會義無反顧地傳送這幾個位元組。
要知道,我們的TCP+IP頭有40個位元組,為了幾個位元組,要達上這麼大的開銷,這太不經濟了。
另外,你需要知道網路上有個MTU,對於乙太網來說,MTU是1500位元組,除去TCP+IP頭的40個位元組,真正的資料傳輸可以有1460,這就是所謂的MSS(Max Segment Size)注意,TCP的RFC定義這個MSS的預設值是536,這是因為IP裝置都得最少接收576尺寸的大小(實際上來說576是撥號的網路的MTU,而576減去IP頭的20個位元組就是536)。
如果你的網路包可以塞滿MTU,那麼你可以用滿整個頻寬,如果不能,那麼你就會浪費頻寬。(大於MTU的包有兩種結局,一種是直接被丟了,另一種是會被重新分塊打包傳送) 你可以想像成一個MTU就相當於一個飛機的最多可以裝的人,如果這飛機裡滿載的話,頻寬最高,如果一個飛機只運一個人的話,無疑成本增加了,也而相當二。
所以,Silly Windows Syndrome這個現像就像是你本來可以坐200人的飛機裡只做了一兩個人。 要解決這個問題也不難,就是避免對小的window size做出響應,直到有足夠大的window size再響應,這個思路可以同時實現在sender和receiver兩端。
- 如果這個問題是由Receiver端引起的,那麼就會使用 David D Clark’s 方案。在receiver端,如果收到的資料導致window size小於某個值,可以直接ack(0)回sender,這樣就把window給關閉了,也阻止了sender再發資料過來,等到receiver端處理了一些資料後windows size 大於等於了MSS,或者,receiver buffer有一半為空,就可以把window開啟讓send 傳送資料過來。
- 如果這個問題是由Sender端引起的,那麼就會使用著名的Nagle’s algorithm。這個演算法的思路也是延時處理,他有兩個主要的條件:1)要等到 Window Size>=MSS 或是 Data Size >=MSS,2)收到之前傳送資料的ack回包,他才會發資料,否則就是在攢資料。
另外,Nagle演算法預設是開啟的,所以,對於一些需要小包場景的程式——比如像telnet或ssh這樣的互動性比較強的程式,你需要關閉這個演算法。你可以在Socket設定TCP_NODELAY選項來關閉這個演算法(關閉Nagle演算法沒有全域性引數,需要根據每個應用自己的特點來關閉)
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value,sizeof(int));另外,網上有些文章說TCP_CORK的socket option是也關閉Nagle演算法,這不對。TCP_CORK其實是更新激進的Nagle算漢,完全禁止小包傳送,而Nagle演算法沒有禁止小包傳送,只是禁止了大量的小包傳送。最好不要兩個選項都設定。
TCP的擁塞處理 – Congestion Handling
上面我們知道了,TCP通過Sliding Window來做流控(Flow Control),但是TCP覺得這還不夠,因為Sliding Window需要依賴於連線的傳送端和接收端,其並不知道網路中間發生了什麼。TCP的設計者覺得,一個偉大而牛逼的協議僅僅做到流控並不夠,因為流控只是網路模型4層以上的事,TCP的還應該更聰明地知道整個網路上的事。
具體一點,我們知道TCP通過一個timer取樣了RTT並計算RTO,但是,如果網路上的延時突然增加,那麼,TCP對這個事做出的應對只有重傳資料,但是,重傳會導致網路的負擔更重,於是會導致更大的延遲以及更多的丟包,於是,這個情況就會進入惡性迴圈被不斷地放大。試想一下,如果一個網路內有成千上萬的TCP連線都這麼行事,那麼馬上就會形成“網路風暴”,TCP這個協議就會拖垮整個網路。這是一個災難。
所以,TCP不能忽略網路上發生的事情,而無腦地一個勁地重發資料,對網路造成更大的傷害。對此TCP的設計理念是:TCP不是一個自私的協議,當擁塞發生的時候,要做自我犧牲。就像交通阻塞一樣,每個車都應該把路讓出來,而不要再去搶路了。
擁塞控制主要是四個演算法:1)慢啟動,2)擁塞避免,3)擁塞發生,4)快速恢復。這四個演算法不是一天都搞出來的,這個四演算法的發展經歷了很多時間,到今天都還在優化中。 備註:
- 1988年,TCP-Tahoe 提出了1)慢啟動,2)擁塞避免,3)擁塞發生時的快速重傳
- 1990年,TCP Reno 在Tahoe的基礎上增加了4)快速恢復
慢熱啟動演算法 – Slow Start
首先,我們來看一下TCP的慢熱啟動。慢啟動的意思是,剛剛加入網路的連線,一點一點地提速,不要一上來就像那些特權車一樣霸道地把路佔滿。新同學上高速還是要慢一點,不要把已經在高速上的秩序給搞亂了。
慢啟動的演算法如下(cwnd全稱Congestion Window):
1)連線建好的開始先初始化cwnd = 1,表明可以傳一個MSS大小的資料。
2)每當收到一個ACK,cwnd++; 呈線性上升
3)每當過了一個RTT,cwnd = cwnd*2; 呈指數讓升
4)還有一個ssthresh(slow start threshold),是一個上限,當cwnd >= ssthresh時,就會進入“擁塞避免演算法”(後面會說這個演算法)
所以,我們可以看到,如果網速很快的話,ACK也會返回得快,RTT也會短,那麼,這個慢啟動就一點也不慢。下圖說明了這個過程。
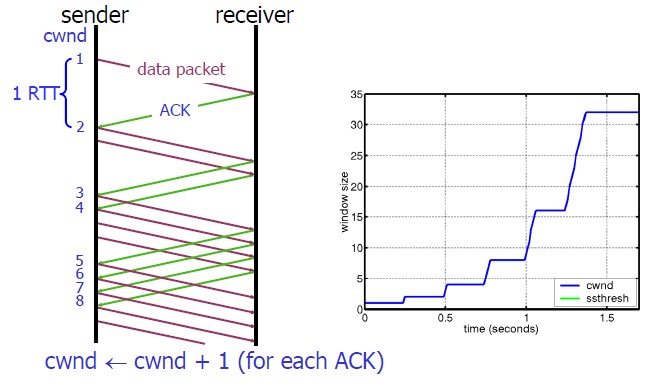
這裡,我需要提一下的是一篇Google的論文而Linux 3.0以前,比如2.6,Linux採用了RFC3390,cwnd是跟MSS的值來變的,如果MSS< 1095,則cwnd = 4;如果MSS>2190,則cwnd=2;其它情況下,則是3。
擁塞避免演算法 – Congestion Avoidance
前面說過,還有一個ssthresh(slow start threshold),是一個上限,當cwnd >= ssthresh時,就會進入“擁塞避免演算法”。一般來說ssthresh的值是65535,單位是位元組,當cwnd達到這個值時後,演算法如下:
1)收到一個ACK時,cwnd = cwnd + 1/cwnd
2)當每過一個RTT時,cwnd = cwnd + 1
這樣就可以避免增長過快導致網路擁塞,慢慢的增加調整到網路的最佳值。很明顯,是一個線性上升的演算法。
擁塞狀態時的演算法
前面我們說過,當丟包的時候,會有兩種情況:
1)等到RTO超時,重傳資料包。TCP認為這種情況太糟糕,反應也很強烈。
- sshthresh = cwnd /2
- cwnd 重置為 1
- 進入慢啟動過程
2)Fast Retransmit演算法,也就是在收到3個duplicate ACK時就開啟重傳,而不用等到RTO超時。
- TCP Tahoe的實現和RTO超時一樣。
- TCP Reno的實現是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 進入快速恢復演算法——Fast Recovery
- TCP Reno的實現是:
上面我們可以看到RTO超時後,sshthresh會變成cwnd的一半,這意味著,如果cwnd<=sshthresh時出現的丟包,那麼TCP的sshthresh就會減了一半,然後等cwnd又很快地以指數級增漲爬到這個地方時,就會成慢慢的線性增漲。我們可以看到,TCP是怎麼通過這種強烈地震盪快速而小心得找到網站流量的平衡點的。
快速恢復演算法 – Fast Recovery
TCP Reno
這個演算法定義在RFC5681。快速重傳和快速恢復演算法一般同時使用。快速恢復演算法是認為,你還有3個Duplicated Acks說明網路也不那麼糟糕,所以沒有必要像RTO超時那麼強烈。 注意,正如前面所說,進入Fast Recovery之前,cwnd 和 sshthresh已被更新:
- cwnd = cwnd /2
- sshthresh = cwnd
然後,真正的Fast Recovery演算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是確認有3個數據包被收到了)
- 重傳Duplicated ACKs指定的資料包
- 如果再收到 duplicated Acks,那麼cwnd = cwnd +1
- 如果收到了新的Ack,那麼,cwnd = sshthresh ,然後就進入了擁塞避免的演算法了。
如果你仔細思考一下上面的這個演算法,你就會知道,上面這個演算法也有問題,那就是——它依賴於3個重複的Acks。注意,3個重複的Acks並不代表只丟了一個數據包,很有可能是丟了好多包。但這個演算法只會重傳一個,而剩下的那些包只能等到RTO超時,於是,進入了惡夢模式——超時一個視窗就減半一下,多個超時會超成TCP的傳輸速度呈級數下降,而且也不會觸發Fast Recovery演算法了。
通常來說,正如我們前面所說的,SACK或D-SACK的方法可以讓Fast Recovery或Sender在做決定時更聰明一些,但是並不是所有的TCP的實現都支援SACK(SACK需要兩端都支援),所以,需要一個沒有SACK的解決方案。而通過SACK進行擁塞控制的演算法是FACK(後面會講)
TCP New Reno
於是,1995年,TCP New Reno(參見 RFC 6582 )演算法提出來,主要就是在沒有SACK的支援下改進Fast Recovery演算法的——
- 當sender這邊收到了3個Duplicated Acks,進入Fast Retransimit模式,開發重傳重複Acks指示的那個包。如果只有這一個包丟了,那麼,重傳這個包後回來的Ack會把整個已經被sender傳輸出去的資料ack回來。如果沒有的話,說明有多個包丟了。我們叫這個ACK為Partial ACK。
- 一旦Sender這邊發現了Partial ACK出現,那麼,sender就可以推理出來有多個包被丟了,於是乎繼續重傳sliding window裡未被ack的第一個包。直到再也收不到了Partial Ack,才真正結束Fast Recovery這個過程
我們可以看到,這個“Fast Recovery的變更”是一個非常激進的玩法,他同時延長了Fast Retransmit和Fast Recovery的過程。
演算法示意圖
下面我們來看一個簡單的圖示以同時看一下上面的各種演算法的樣子:
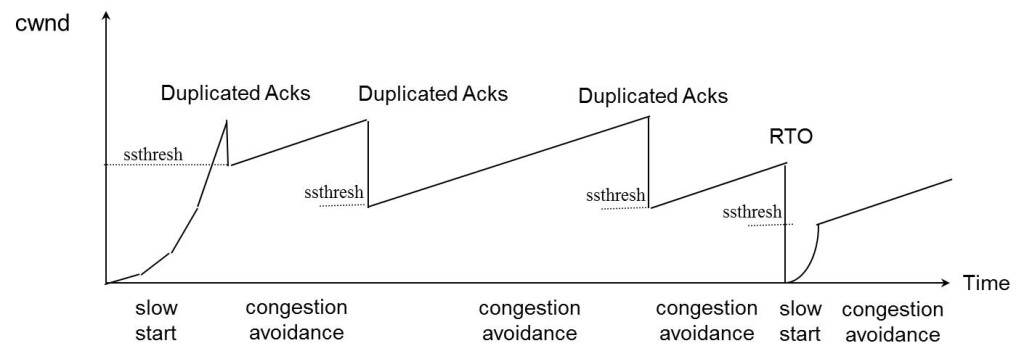
FACK演算法
FACK全稱Forward Acknowledgment 演算法,論文地址在這裡(PDF)Forward Acknowledgement: Refining TCP Congestion Control 這個演算法是其於SACK的,前面我們說過SACK是使用了TCP擴充套件欄位Ack了有哪些資料收到,哪些資料沒有收到,他比Fast Retransmit的3 個duplicated acks好處在於,前者只知道有包丟了,不知道是一個還是多個,而SACK可以準確的知道有哪些包丟了。 所以,SACK可以讓傳送端這邊在重傳過程中,把那些丟掉的包重傳,而不是一個一個的傳,但這樣的一來,如果重傳的包資料比較多的話,又會導致本來就很忙的網路就更忙了。所以,FACK用來做重傳過程中的擁塞流控。
- 這個演算法會把SACK中最大的Sequence Number 儲存在snd.fack這個變數中,snd.fack的更新由ack帶秋,如果網路一切安好則和snd.una一樣(snd.una就是還沒有收到ack的地方,也就是前面sliding window裡的category #2的第一個地方)
- 然後定義一個awnd = snd.nxt – snd.fack(snd.nxt指向傳送端sliding window中正在要被髮送的地方——前面sliding windows圖示的category#3第一個位置),這樣awnd的意思就是在網路上的資料。(所謂awnd意為:actual quantity of data outstanding in the network)
- 如果需要重傳資料,那麼,awnd = snd.nxt – snd.fack + retran_data,也就是說,awnd是傳出去的資料 + 重傳的資料。
- 然後觸發Fast Recovery 的條件是: ( ( snd.fack – snd.una ) > (3*MSS) ) || (dupacks == 3) ) 。這樣一來,就不需要等到3個duplicated acks才重傳,而是隻要sack中的最大的一個數據和ack的資料比較長了(3個MSS),那就觸發重傳。在整個重傳過程中cwnd不變。直到當第一次丟包的snd.nxt<=snd.una(也就是重傳的資料都被確認了),然後進來擁塞避免機制——cwnd線性上漲。
我們可以看到如果沒有FACK在,那麼在丟包比較多的情況下,原來保守的演算法會低估了需要使用的window的大小,而需要幾個RTT的時間才會完成恢復,而FACK會比較激進地來幹這事。 但是,FACK如果在一個網路包會被 reordering的網路裡會有很大的問題。
其它擁塞控制演算法簡介
TCP Vegas 擁塞控制演算法
這個演算法1994年被提出,它主要對TCP Reno 做了些修改。這個演算法通過對RTT的非常重的監控來計算一個基準RTT。然後通過這個基準RTT來估計當前的網路實際頻寬,如果實際頻寬比我們的期望的頻寬要小或是要多的活,那麼就開始線性地減少或增加cwnd的大小。如果這個計算出來的RTT大於了Timeout後,那麼,不等ack超時就直接重傳。(Vegas 的核心思想是用RTT的值來影響擁塞視窗,而不是通過丟包) 這個演算法的論文是《TCP Vegas: End to End Congestion Avoidance on a Global Internet》這篇論文給了Vegas和 New Reno的對比:
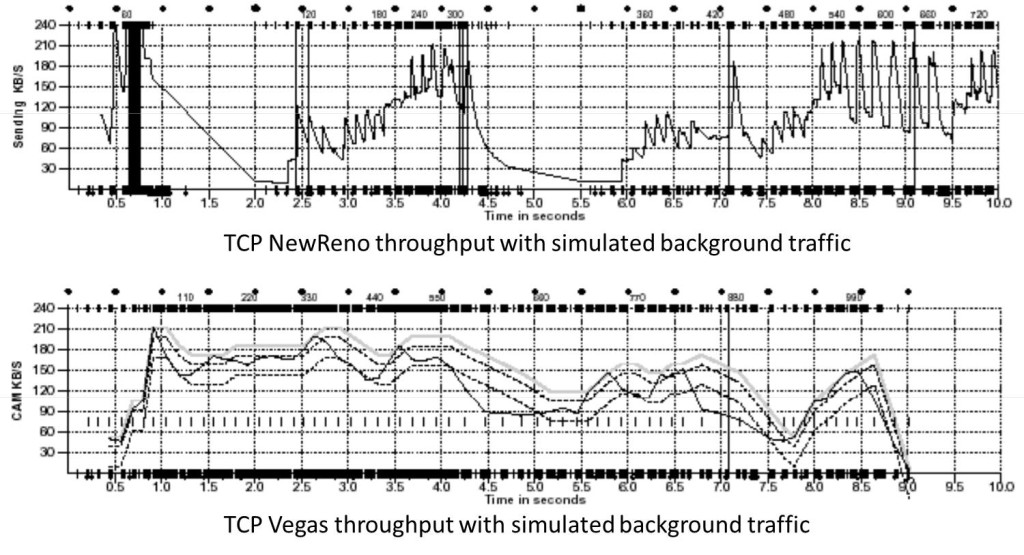
HSTCP(High Speed TCP) 演算法
這個演算法來自RFC 3649(Wikipedia詞條)。其對最基礎的演算法進行了更改,他使得Congestion Window漲得快,減得慢。其中:
- 擁塞避免時的視窗增長方式: cwnd = cwnd + α(cwnd) / cwnd
- 丟包後窗口下降方式:cwnd = (1- β(cwnd))*cwnd
注:α(cwnd)和β(cwnd)都是函式,如果你要讓他們和標準的TCP一樣,那麼讓α(cwnd)=1,β(cwnd)=0.5就可以了。 對於α(cwnd)和β(cwnd)的值是個動態的變換的東西。 關於這個演算法的實現,你可以參看Linux原始碼:/net/ipv4/tcp_highspeed.c
TCP BIC 演算法
2004年,產內出BIC演算法。現在你還可以查得到相關的新聞《Google:美科學家研發BIC-TCP協議 速度是DSL六千倍》 BIC全稱Binary Increase Congestion control,在Linux 2.6.8中是預設擁塞控制演算法。BIC的發明者發這麼多的擁塞控制演算法都在努力找一個合適的cwnd – Congestion Window,而且BIC-TCP的提出者們看穿了事情的本質,其實這就是一個搜尋的過程,所以BIC這個演算法主要用的是Binary Search——二分查詢來幹這個事。 關於這個演算法實現,你可以參看Linux原始碼:/net/ipv4/tcp_bic.c
TCP WestWood演算法
westwood採用和Reno相同的慢啟動演算法、擁塞避免演算法。westwood的主要改進方面:在傳送端做頻寬估計,當探測到丟包時,根據頻寬值來設定擁塞視窗、慢啟動閾值。 那麼,這個演算法是怎麼測量頻寬的?每個RTT時間,會測量一次頻寬,測量頻寬的公式很簡單,就是這段RTT內成功被ack了多少位元組。因為,這個頻寬和用RTT計算RTO一樣,也是需要從每個樣本來平滑到一個值的——也是用一個加權移平均的公式。 另外,我們知道,如果一個網路的頻寬是每秒可以傳送X個位元組,而RTT是一個數據發出去後確認需要的時候,所以,X * RTT應該是我們緩衝區大小。所以,在這個演算法中,ssthresh的值就是est_BD * min-RTT(最小的RTT值),如果丟包是Duplicated ACKs引起的,那麼如果cwnd > ssthresh,則 cwin = ssthresh。如果是RTO引起的,cwnd = 1,進入慢啟動。 關於這個演算法實現,你可以參看Linux原始碼: /net/ipv4/tcp_westwood.c
其它
後記
好了,到這裡我想可以結束了,TCP發展到今天,裡面的東西可以寫上好幾本書。本文主要目的,還是把你帶入這些古典的基礎技術和知識中,希望本文能讓你瞭解TCP,更希望本文能讓你開始有學習這些基礎或底層知識的興趣和信心。
當然,TCP東西太多了,不同的人可能有不同的理解,而且本文可能也會有一些荒謬之言甚至錯誤,還希望得到您的反饋和批評。
相關推薦
TCP的那些事(下)
原文連結:https://coolshell.cn/articles/11609.html 這篇文章是下篇,所以如果你對TCP不熟悉的話,還請你先看看上篇《TCP的那些事兒(上)》 上篇中,我們介紹了TCP的協議頭、狀態機、資料重傳中的東西。但是TCP要解決一個很大的
關於爛程式碼的那些事(下)
假設你已經讀過爛程式碼系列的前兩篇:瞭解了什麼是爛程式碼,什麼是好程式碼,但是還是不可避免的接觸到了爛程式碼(就像之前說的,幾乎沒有程式設計師可以完全避免寫出爛程式碼!)接下來的問題便是:如何應對這些身邊的爛程式碼。 1.改善可維護性 改善程式碼質量是項大工程,要
TCP 的那些事兒(下)
以及 int 不能 資源 body 快速 ssi oid ima http://coolshell.cn/articles/11609.html 這篇文章是下篇,所以如果你對TCP不熟悉的話,還請你先看看上篇《TCP的那些事兒(上)》 上篇中,我們介紹了TCP的協議
我與Git的那些破事(下)--分支模型
在上篇文章中,我提到了Git的基本概念和一些本人實際專案中的總結。然而,最近讀了Vincent Driessen寫的一篇文章,覺得他總結的太好了,站在他肩膀上忍不住將自己的理解分享出來。Vincent Driessen的文章連線放在本文最下方,有需要的童鞋可去參考一二。 話不多上,乾貨頂上。 分支模型 上述
軟件project—思考項目開發那些事(一)
app 爛代碼 fontsize 模式 大型 不明確 極限 後拋 con 閱讀文件夾: 1.背景2.項目管理,質量、度量、進度3.軟件開發是一種設計活動而不是建築活動4.高速開發(簡單的系統結構與復雜的業務模型)5.技術人員的業務理解與產品經理的業務理解的終於業務模型
關於爛代碼的那些事(上)
天才 是個 莫名其妙 多項目 變量 ++ 經歷 新功能 修改 轉自:http://blog.2baxb.me/archives/1343 1.摘要 最近寫了不少代碼,review了不少代碼,也做了不少重構,總之是對著爛代碼工作了幾周。為了抒發一下這幾周裏好幾次到達崩潰邊
懷孕、產檢的那些事(一)
div 報告 mage 北京大學 之前 clas spa 測試 class 小孩在北京大學深圳醫院出生的,產檢也是在那裏,以下說的都是北大醫院的情況,每個醫院可能不相同,想起多少寫多少吧。第一次寫,寫的很亂。 最開始呢是發現媳婦沒有來月經,然後就去藥店買了早早孕試紙(選擇在
玩兒蟲那些事(四)—— 使用curl
nod -h div sel ant validate 空間 pre rap 目錄 一、爬一個簡單的網站 二、模擬登錄新浪 三、各種請求的發送 四、使用curl 五、模擬登錄QQ空間 六、selenium的使用 七、phantomjs的使用 八、開源框架webmagic
我和 WebSocket 的那些事(一)
com lis 都沒有 情況下 系統 並不是 任務管理 js實現 因此 我的策劃大佬離職了,在他go之前我都沒有解決好一個問題,感覺如果我換了工作面試的時候,別人問到 “你在做項目的時候,遇到的最頭疼的問題是什麽,是怎麽解決的?”,首先想到的應該也是他,今天感覺是時候寫
工作那些事(十一)談談碼農與農民工區別和發展之路 工作那些事(十二)如果哪一天,沒有了電腦 工作那些事(十三)再次失業
工作那些事系列連結快速通道,不斷更新中: 工作那些事(一)今年工作不好找 工作那些事(二)應聘時填寫個人資訊ABCD 工作那些事(三)什麼樣的公司能吸引你,什麼樣的公司適合你? 工作那些事(四)大公司VS小公司 工作那些事(五)談談專案資料整理和積累 工作那些事(六)談談
淺談 kubernetes service 那些事 (下篇)
歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 五、K8s 1.8 新特性——ipvs ipvs與iptables的效能差異 隨著服務的數量增長,IPTables 規則則會成倍增長,這樣帶來的問題是路由延遲帶來的服務訪問延遲,同時新增或刪除一條規則也有較大延遲。不同規模下,kube-proxy新增一條
mybatis快取那些事(二)
前言 前面在mybatis快取那些事(一) 中,我們介紹了mybatis的一級快取。這裡再和大家一起學習下mybatis中的二級快取。 MyBatis的二級快取是Application級別的快取,它可以提高對資料庫查詢的效率,以提高應用的效能。 MyBatis的快取機制整體設計以及二級快
關於JAVA你必須知道的那些事(三):繼承和訪問修飾符
今天乘著還有一些時間,把上次拖欠的面向物件程式設計三大特性中遺留的繼承和多型給簡單說明一下。這一部分還是非常重要的,需要仔細思考。 繼承 繼承:它是一種類與類之間的關係,通過使用已存在的類作為基礎來建立新類。其中已存在的類稱為父類(或基類); 建立的新類稱為子類(或派生類)。簡單的就是子類繼
關於JAVA你必須知道的那些事(二):封裝
時隔近一年,我突然想起來這個文章還沒有發完,所以就繼續開始寫。也不知道自己上次寫到哪裡了,不管了這裡從面向物件的三個特性說起。 類和物件 在這之前,我們先了解什麼是物件,已經什麼是面向物件?物件:萬物皆物件,現實中實際存在的事物都可以看成一個物件。而面向物件就是人在關注物件, 關注事物的資訊
關於JAVA你必須知道的那些事(四):單例模式和多型
好吧,今天一定要把面向物件的最後一個特性:多型,給說完。不過我們先來聊一聊設計模式,因為它很重要。 設計模式 官方的解釋是,設計模式是:一套被反覆使用,多數人知曉的,經過分類編目,程式碼設計經驗的總結。說人話就是:軟體開發人員在軟體開發過程中面臨的一般問題的解決方案。 常見的設計模式可以
vue前端開發那些事(1)
如上圖所示,用vue開發一個小型網站所涉及到的知識點。這只是前端部分已經這麼多了。接下來我分解開來說。 1、Node 當我們開發vue專案的時候,首先要安裝Node.js,那麼我們即使當時不理解為什麼,但是專案完成後,應該抽個空,理解下。有兩個問題: a、什麼是Node? b、No
痞子衡嵌入式:飛思卡爾Kinetis開發板OpenSDA偵錯程式那些事(上)- 背景與架構
大家好,我是痞子衡,是正經搞技術的痞子。今天痞子衡給大家介紹的是飛思卡爾Kinetis MCU開發闆闆載OpenSDA偵錯程式(上篇)。 眾所周知,嵌入式軟體開發幾乎離不開偵錯程式,因為寫一個稍有程式碼規模(5K行以上)的嵌入式應用程式一般不可能一次性搞定,沒有任何bug,出了bug並不可怕,只要我
聊聊高併發(三十五)Java記憶體模型那些事(三)理解記憶體屏障
硬體層提供了一系列的記憶體屏障 memory barrier / memory fence(Intel的提法)來提供一致性的能力。拿X86平臺來說,有幾種主要的記憶體屏障 1. lfence,是一種Load Barrier 讀屏障 2. sfence, 是一種Store
聊聊高併發(三十三)Java記憶體模型那些事(一)從一致性(Consistency)的角度理解Java記憶體模型
可以說併發系統要解決的最核心問題之一就是一致性的問題,關於一致性的研究已經有幾十年了,有大量的理論,演算法支援。這篇說說一致性這個主題一些經常提到的概念,理清Java記憶體模型在其中的位置。 一致性問題更準確的說是一致性需求,看系統需要什麼樣的一致性保證。比如分散式領域
專案build.gradle的那些事(小記)
忙碌的2017.12已過,接著迎接忙碌的2018.... 很久沒寫東西了,今天想跟著經驗寫最近對build.gradle的一些認為值得記錄的東西。 一、關於簽名 以前很多人都喜歡直接把簽名的資訊直接寫在gradle,但是這樣的做法不是太好,我們可以這樣做,用一個檔案專門存下簽名的配置