
文字檢索問題----第六屆泰迪杯C題賽後總結
一,開篇
本人蔘加了第六屆泰迪杯,並且選擇了C題。是一道文字檢索的問題。要求是:可以根據官方給出的訓練集跟測試集,最後在最後測試集中執行演算法進行答案回答,完全相關為1,完全不相關為0.資料模式如圖:
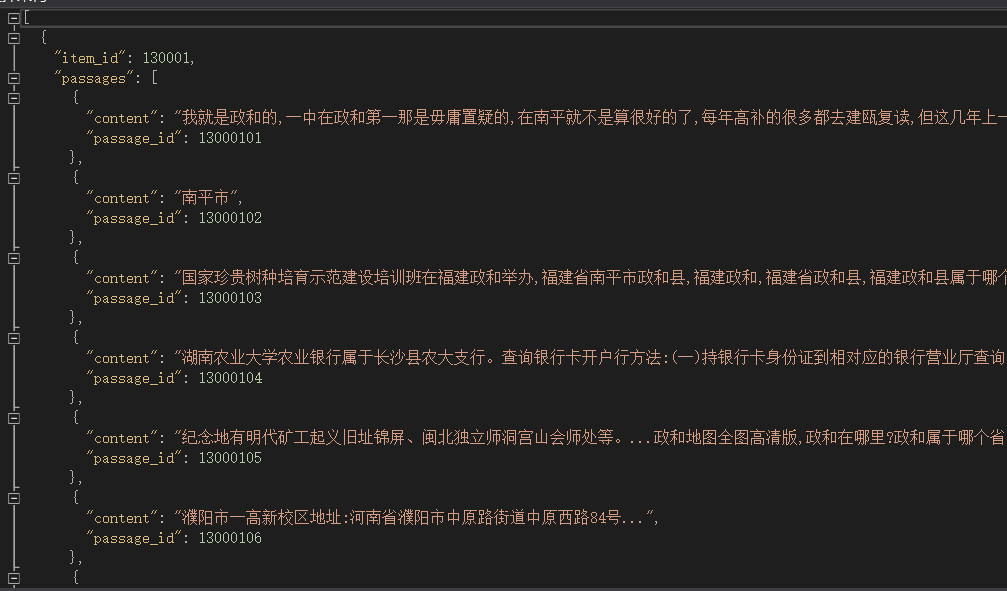
二.預處理
首先提取相關檔案。文件檔案為json格式檔案,用python進行這次比賽。對於json檔案,可用import json進行提取。其中的json.load()函式提取出來。需要注意的是檔案中,以一個問題一個物件進行儲存,訓練集總共5000個問題。每個問題中又包括問題id(item_id),數個問題,問題有包括了內容跟passage_id。而對於答案的提問則在每個問題的最後。以下是提取部分的程式碼:
with open (filepath,'r',encoding='utf-8') as f: with open (filepath1, 'w', encoding='utf-8') as a: with open (filepath2, 'w', encoding='utf-8') as b: lines = json.load(f) for line in lines: a.write(line['question']+'\n') x.append(line['item_id']) for kk in line['passages']: b.write(kk['content']+'\n') y.append(kk['passage_id'])
提取出來後,查閱了相關各類資料,文獻。相關資料在最後附上。
對於文字檢索問題,首先需要進行對於句子或是文章的分解,將其分解為一個個詞語。這時候可以下載jieba包,之後可以直接import jieba對文字進行分詞操作。分詞後,可以發現詞語中有很多無關詞語,這些我們將此稱為停用詞。我們應當將其全部去掉,否則會影響最後的正確率。而停用詞網上也有已經完好的停用詞庫,大家可以自己下載使用。附上程式碼:
def stopwordslist(filepath): stopwords = [line.strip () for line in open (filepath, 'r').readlines ()] return stopwords # 對句子進行分詞 def seg_sentence(sentence): sence =jieba.cut (sentence, cut_all=False) sentence_seged =sence.split(" ") stopwords = stopwordslist ("C:\\Users\\lenovo\\Desktop\\bear\\stop.txt") # 這裡載入停用詞的路徑 outstr = '' for word in sentence_seged: if word not in stopwords: if word != '\t': outstr += word outstr += " " outstr +='\n' return outstr
在以上步驟完成後,初步資料的清洗操作完成。
三.模型建立
對於文字檢索來說,廣泛使用了神經網路。我推薦大家看一下《面向高考閱讀理解觀點類問題的答案抽取方法》這篇論文。我們最後打算根據文獻,使用word2vec+SVM+LDA。博主寫得是word2vec方面,最後三個演算法在合起來加權。
word2vec就是對word進行embedding
首先,我們知道,在機器學習和深度學習中,對word的最簡單的表示就是使用one-hot([0,0,1,0,0…..]來表示一個word). 但是用one-hot表示一個word的話,會有一些弊端:從向量中無法看出word之間的關係((wworda)Twwordb=0
(wworda)Twwordb=0),而且向量也太稀疏. 所以一些人就想著能否用更小的向量來表示一個word,希望這些向量能夠承載一些語法和語義上的資訊, 這就產生了word2vec
而已經有人對於word2vec進行了打包處理,各位可以直接下載使用,它在genism裡面。
使用時候直接可以from gensim.models import word2vec
當你匯入後,訓練模型只需要一句話model=word2vec.Word2Vec(sentence,min_count=10,size=50)
儲存的時候使用model.save('/model/word2vec_model')就行
匯入的時候也是一句話model = word2vec.Word2Vec.load("\word2vec_model.model")
python中的word2vec自帶了許多功能函式。接來下講幾個基礎的
model.similarity(u"高速", u"火車")#計算兩個詞之間的餘弦距離
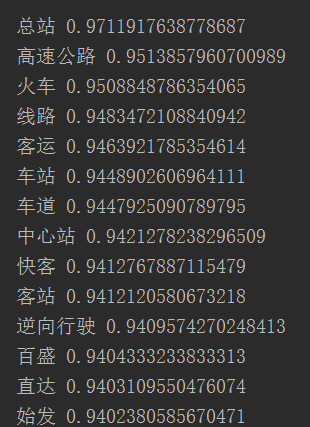
model.most_similar(u"高速")#計算餘弦距離最接近“滋潤”的10個詞
但你可以發現這些都是單個詞彙的相似性問題,處理句子的演算法如下:
def pipei(s1="",s2=""):
results=[]
k = 0
for i in s1:
result=0
for j in s2:
try:
result = max(model.similarity(i,j),result)
except KeyError:
if i==j:
result = 1
results.append(result)
for kk in results:
k = k+kk
return k/len(s1)
def pp(s1,s2):
return (pipei(s1,s2)+pipei(s2,s1))/2自此,你可以求出兩個句子之間的相似性,你可以用它去測量問題跟答案之間的相似度。
由於問題的id跟答案的id前五位是相同的,我們以此為匹配條件,進行匹配,進行迴圈。測量出的結果大概是83%左右。
之後再跟同學的演算法進行加權,這裡就不進行細說了。
PS:word2vec本質上是一層神經網路,正確率問題應該不高,但是這次由於理解錯官方意思,在其他方面忙活了很久。耽誤了時間。
第一次參賽,希望大佬不要吐槽。
score相關推薦
文字檢索問題----第六屆泰迪杯C題賽後總結
一,開篇 本人蔘加了第六屆泰迪杯,並且選擇了C題。是一道文字檢索的問題。要求是:可以根據官方給出的訓練集跟測試集,最後在最後測試集中執行演算法進行答案回答,完全相關為1,完全不相關為0.資料模式如圖:二.預處理 首先提取相關檔案。文件檔案為json格式檔案,用py
藍橋杯第六屆省賽JAVA真題----生命之樹
生命之樹 在X森林裡,上帝建立了生命之樹。 他給每棵樹的每個節點(葉子也稱為一個節點)上,都標了一個整數,代表這個點的和諧值。 上帝要在這棵樹內選出一個非空節點集S,使得對於S中的任意兩個點a,b,都存在一個點列 {a, v1, v2, …, vk, b} 使得
藍橋杯第六屆省賽JAVA真題----壘骰子
壘骰子賭聖atm晚年迷戀上了壘骰子,就是把骰子一個壘在另一個上邊,不能歪歪扭扭,要壘成方柱體。經過長期觀察,atm 發現了穩定骰子的奧祕:有些數字的面貼著會互相排斥!我們先來規範一下骰子:1 的對面是 4,2 的對面是 5,3 的對面是 6。假設有 m 組互斥現象,每組中的那
第六屆中國軟體杯WIFI探針資料分析
Hello Spark_WIFIProbe_Analyse 基於Hadoop,Spark的WIFI探針大資料分析。 使用Scala語言 版本2.11.0 匯入資料庫,tanzhen 把lib包內容放入/home/example中 //分析資料 s
南海石門中學第六屆創新班 2015-5-30 課時總結
這次創新班,老師給我們講了今年考的試題。其中,涉及到了幾個重要的思想:並查集和揹包問題。 並查集的建立 所謂並查集,以我自己的理解而言,就是合併時有著進一步的速度優勢的集合。首先,我們有一定的資料,這些資料間有一定的連線,而我要找出連通塊,就需要通過合併來找出一些點是否連通。 首先,我們有一
第六屆山東省ACM競賽 A題 Nias and Tug-of-War(java)
Nias and Tug-of-War Time Limit: 1000MS Memory limit: 65536K 題目描述 Nias is fond of tug-of-war. One day, he organized a tug-of-war
第六屆"泰迪杯"數據挖掘挑戰賽C題參賽經歷總結
論文 https 中文 git osi ram lec 原理 hub 第六屆"泰迪杯"參賽經歷總結 Part 1 賽題 點擊Part 1 賽題進入題目網站 Part 2 C題參考與建議 智能閱讀模型的構建 —— 一份閱讀建議 一、 賽題 1、 賽題 (1) 主題:以文
算法筆記_208:第六屆藍橋杯軟件類決賽真題(Java語言A組)
boolean style 空格 ima eight jdk1 ++ port 但是 目錄 1 胡同門牌號 2 四階幻方 3 顯示二叉樹 4 穿越雷區 5 切開字符串 6 鋪瓷磚 前言:以下代碼僅供參考,若有錯誤歡迎指正哦~ 1 胡同門牌號 標題:胡
"浪潮杯"第六屆ACM山東省省賽山科場總結
stl 努力 自己 遍歷 mail 每一個 英語 -a 成對 從空間拷過來的。盡管已經過去一個月了。記憶猶新 也算是又一次拾起這個blog Just begin 看著一群群大牛還有隊友男神的省賽總結都出了 我最終也耐不住寂寞 來做個流水賬抒抒情好了 第一
第六屆藍盾杯總結
比賽總結 9月17日,我和我的小隊成員張恒鵬,劉洪海,以及帶隊老師曲老師,參加了在山大軟件園舉辦的藍盾杯網絡空間安全比賽,隊名:WHat戰隊。並且拿到了一等獎,超乎意料之外。本來我們只是奔著測驗一下我們的攻防策略而去的,嘿嘿! 比賽一共分為兩個階段,第一階段為挑戰賽,答ctf題,第
藍橋杯第六屆-牌型總數&&藍橋杯第七屆-湊算式&&藍橋杯第七屆-方格填數
amp abs 絕對值 return tin ace con name 可能性 牌型總數 去掉大小王之後就相當於4套1到13的數字牌的集合(因為忽略花色了),所以1到13各有4張;枚舉思路就是考慮13種數字牌在自己手中到底有幾張,共有五種可能性,也就是某種數字牌在手中可
第六屆藍橋杯真題總結
for a* 截斷 如果 pan 文字 居中 size using 第一題:獎券數目 有些人很迷信數字,比如帶“4”的數字,認為和“死”諧音,就覺得不吉利。 雖然這些說法純屬無稽之談,但有時還要迎合大眾的需求。某抽
第六屆藍橋杯java b組第三題
watermark alt args 暴力破解 out col HR sdn oid 第三題 三羊獻瑞 觀察下面的加法算式: 其中,相同的漢字代表相同的數字,不同的漢字代表不同的數字。 請你填寫“三羊獻瑞”所代表的4位數字(答案唯一),不要填寫任何多余內容。 答案這個題目
第六屆藍橋杯java b組第一題
都是 text nbsp post ppa hbm 藍橋杯 文字 fill 第一題 三角形面積 圖中的所有小方格面積都是1。 那麽,圖中的三角形面積應該是多少呢? 請填寫三角形的面積。不要填寫任何多余內容或說明性文字。 填空答案 28 沒什麽好說的 第一題很水 估計
第六屆藍橋杯java b組第8題
CP stat exti 要求 得到 嚴格 else scan 內容 樂羊羊飲料廠正在舉辦一次促銷優惠活動。樂羊羊C型飲料,憑3個瓶蓋可以再換一瓶C型飲料,並且可以一直循環下去,但不允許賒賬。 請你計算一下,如果小明不浪費瓶蓋,盡量地參加活動,那麽,對於他初始買入的n瓶飲料
2015年第六屆藍橋杯C/C++程序設計本科B組決賽 ——居民集會(編程大題)
con 要求 數據 color 資源 例如 aps 計算 調試 標題:居民集會 藍橋村的居民都生活在一條公路的邊上,公路的長度為L,每戶家庭的 位置都用這戶家庭到公路的起點的距離來計算,第i戶家庭距起點的距 離為di。每年,藍橋村都要舉行一次集會。今年,由於村裏的人口太多,
加法變乘法——第六屆藍橋杯C語言B組(省賽)第六題
clu 自己 nbsp 加法 藍橋杯 重新 () std spa 原創 加法變乘法 我們都知道:1+2+3+ ... + 49 = 1225現在要求你把其中兩個不相鄰的加號變成乘號,使得結果為2015 比如:1+2+3+...+10*11+12+...+27*28+29+
【藍橋杯】第六屆國賽C語言B組 2.完美正方形(dfs)
spa else img IT bool break main LG fill 如果一些邊長互不相同的正方形,可以恰好拼出一個更大的正方形,則稱其為完美正方形。 歷史上,人們花了很久才找到了若幹完美正方形。比如:如下邊長的22個正方形2 3 4 6 7 8 12 13 14
【藍橋杯】第六屆國賽C語言B組 1.積分之迷(水題)
水題 urn class %d names 風鈴 需要 藍橋 std 小明開了個網上商店,賣風鈴。共有3個品牌:A,B,C。為了促銷,每件商品都會返固定的積分。 小明開業第一天收到了三筆訂單:第一筆:3個A + 7個B + 1個C,共返積分:315第二筆:4個A + 10個
三羊獻瑞——第六屆藍橋杯C語言B組(省賽)第三題
lan font oid 漢字 print ack size IV cnblogs 原創 三羊獻瑞 觀察下面的加法算式: 祥 瑞 生 輝 + 三 羊 獻 瑞 ------------------- 三 羊 生 瑞 氣 (如果有對齊問題,可以參看【圖1.jp