
PHP的WEB系統從單機到分散式叢集的演進
當一個Web系統從日訪問量10萬逐步增長到1000萬,甚至超過1億的過程中,Web系統承受的壓力會越來越大,在這個過程中,我們會遇到很多的問題。為了解決這些效能壓力帶來問題,我們需要在Web系統架構層面搭建多個層次的快取機制。在不同的壓力階段,我們會遇到不同的問題,通過搭建不同的服務和架構來解決。
Web負載均衡
Web負載均衡(Load Balancing),簡單地說就是給我們的伺服器叢集分配“工作任務”,而採用恰當的分配方式,對於保護處於後端的Web伺服器來說,非常重要。
負載均衡的策略有很多,我們從簡單的講起哈。
1. HTTP重定向
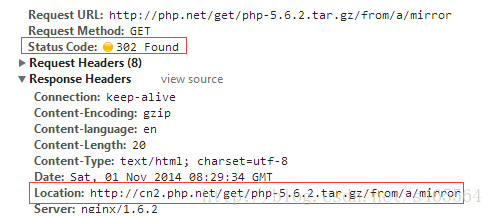
當用戶發來請求的時候,Web伺服器通過修改HTTP響應頭中的Location標記來返回一個新的url,然後瀏覽器再繼續請求這個新url,實際上就是頁面重定向。通過重定向,來達到“負載均衡”的目標。例如,我們在下載PHP原始碼包的時候,點選下載連結時,為了解決不同國家和地域下載速度的問題,它會返回一個離我們近的下載地址。重定向的HTTP返回碼是302,如下圖:
如果使用PHP程式碼來實現這個功能,方式如下:

這個重定向非常容易實現,並且可以自定義各種策略。但是,它在大規模訪問量下,效能不佳。而且,給使用者的體驗也不好,實際請求發生重定向,增加了網路延時。
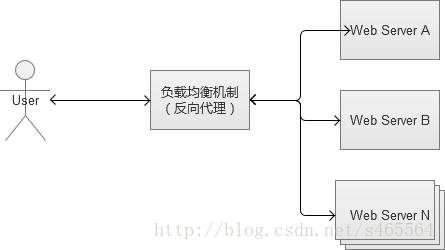
2. 反向代理負載均衡
反向代理服務的核心工作主要是轉發HTTP請求,扮演了瀏覽器端和後臺Web伺服器中轉的角色。因為它工作在HTTP層(應用層),也就是網路七層結構中的第七層,因此也被稱為“七層負載均衡”。可以做反向代理的軟體很多,比較常見的一種是Nginx。
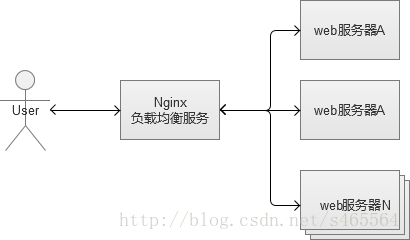
Nginx是一種非常靈活的反向代理軟體,可以自由定製化轉發策略,分配伺服器流量的權重等。反向代理中,常見的一個問題,就是Web伺服器儲存的session資料,因為一般負載均衡的策略都是隨機分配請求的。同一個登入使用者的請求,無法保證一定分配到相同的Web機器上,會導致無法找到session的問題。
解決方案主要有兩種:
1. 配置反向代理的轉發規則,讓同一個使用者的請求一定落到同一臺機器上(通過分析cookie),複雜的轉發規則將會消耗更多的CPU,也增加了代理伺服器的負擔。
2. 將session這類的資訊,專門用某個獨立服務來儲存,例如redis/memchache,這個方案是比較推薦的。
反向代理服務,也是可以開啟快取的,如果開啟了,會增加反向代理的負擔,需要謹慎使用。這種負載均衡策略實現和部署非常簡單,而且效能表現也比較好。但是,它有“單點故障”的問題,如果掛了,會帶來很多的麻煩。而且,到了後期Web伺服器繼續增加,它本身可能成為系統的瓶頸。
3. IP負載均衡
IP負載均衡服務是工作在網路層(修改IP)和傳輸層(修改埠,第四層),比起工作在應用層(第七層)效能要高出非常多。原理是,他是對IP層的資料包的IP地址和埠資訊進行修改,達到負載均衡的目的。這種方式,也被稱為“四層負載均衡”。常見的負載均衡方式,是LVS(Linux Virtual Server,Linux虛擬服務),通過IPVS(IP Virtual Server,IP虛擬服務)來實現。
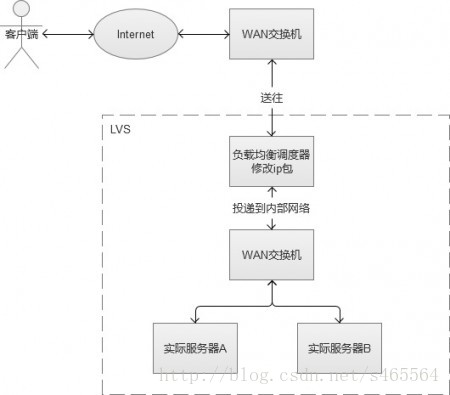
在負載均衡伺服器收到客戶端的IP包的時候,會修改IP包的目標IP地址或埠,然後原封不動地投遞到內部網路中,資料包會流入到實際Web伺服器。實際伺服器處理完成後,又會將資料包投遞迴給負載均衡伺服器,它再修改目標IP地址為使用者IP地址,最終回到客戶端。
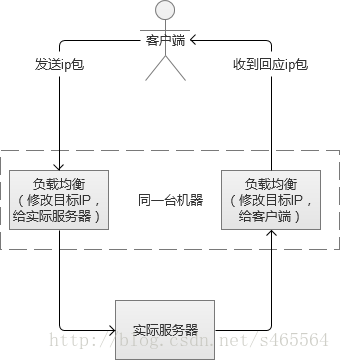
上述的方式叫LVS-NAT,除此之外,還有LVS-RD(直接路由),LVS-TUN(IP隧道),三者之間都屬於LVS的方式,但是有一定的區別,篇幅問題,不贅敘。
IP負載均衡的效能要高出Nginx的反向代理很多,它只處理到傳輸層為止的資料包,並不做進一步的組包,然後直接轉發給實際伺服器。不過,它的配置和搭建比較複雜。
4. DNS負載均衡
DNS(Domain Name System)負責域名解析的服務,域名url實際上是伺服器的別名,實際對映是一個IP地址,解析過程,就是DNS完成域名到IP的對映。而一個域名是可以配置成對應多個IP的。因此,DNS也就可以作為負載均衡服務。

這種負載均衡策略,配置簡單,效能極佳。但是,不能自由定義規則,而且,變更被對映的IP或者機器故障時很麻煩,還存在DNS生效延遲的問題。
5. DNS/GSLB負載均衡
我們常用的CDN(Content Delivery Network,內容分發網路)實現方式,其實就是在同一個域名對映為多IP的基礎上更進一步,通過GSLB(Global Server Load Balance,全域性負載均衡)按照指定規則對映域名的IP。一般情況下都是按照地理位置,將離使用者近的IP返回給使用者,減少網路傳輸中的路由節點之間的跳躍消耗。
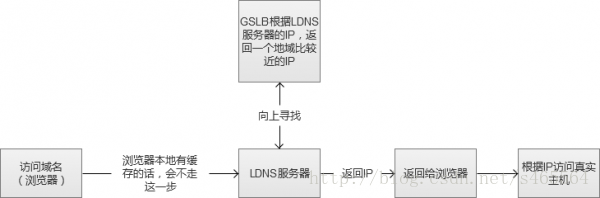
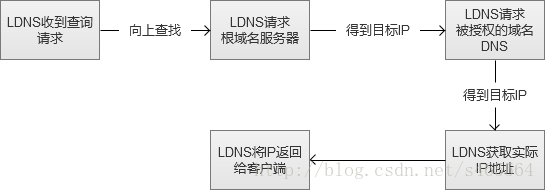
圖中的“向上尋找”,實際過程是LDNS(Local DNS)先向根域名服務(Root Name Server)獲取到頂級根的Name Server(例如.com的),然後得到指定域名的授權DNS,然後再獲得實際伺服器IP。
CDN在Web系統中,一般情況下是用來解決大小較大的靜態資源(html/Js/Css/圖片等)的載入問題,讓這些比較依賴網路下載的內容,儘可能離使用者更近,提升使用者體驗。
例如,我訪問了一張imgcache.gtimg.cn上的圖片(騰訊的自建CDN,不使用qq.com域名的原因是防止http請求的時候,帶上了多餘的cookie資訊),我獲得的IP是183.60.217.90。
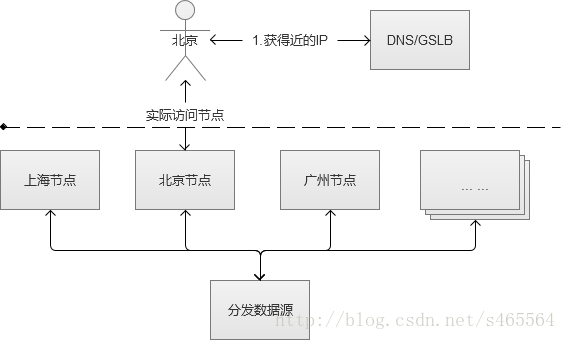
這種方式,和前面的DNS負載均衡一樣,不僅效能極佳,而且支援配置多種策略。但是,搭建和維護成本非常高。網際網路一線公司,會自建CDN服務,中小型公司一般使用第三方提供的CDN。
Web系統的快取機制的建立和優化
剛剛我們講完了Web系統的外部網路環境,現在我們開始關注我們Web系統自身的效能問題。我們的Web站點隨著訪問量的上升,會遇到很多的挑戰,解決這些問題不僅僅是擴容機器這麼簡單,建立和使用合適的快取機制才是根本。
最開始,我們的Web系統架構可能是這樣的,每個環節,都可能只有1臺機器。

我們從最根本的資料儲存開始看哈。
一、 MySQL資料庫內部快取使用
MySQL的快取機制,就從先從MySQL內部開始,下面的內容將以最常見的InnoDB儲存引擎為主。
1. 建立恰當的索引
最簡單的是建立索引,索引在表資料比較大的時候,起到快速檢索資料的作用,但是成本也是有的。首先,佔用了一定的磁碟空間,其中組合索引最突出,使用需要謹慎,它產生的索引甚至會比源資料更大。其次,建立索引之後的資料insert/update/delete等操作,因為需要更新原來的索引,耗時會增加。當然,實際上我們的系統從總體來說,是以select查詢操作居多,因此,索引的使用仍然對系統性能有大幅提升的作用。
2. 資料庫連線執行緒池快取
如果,每一個數據庫操作請求都需要建立和銷燬連線的話,對資料庫來說,無疑也是一種巨大的開銷。為了減少這型別的開銷,可以在MySQL中配置thread_cache_size來表示保留多少執行緒用於複用。執行緒不夠的時候,再建立,空閒過多的時候,則銷燬。

其實,還有更為激進一點的做法,使用pconnect(資料庫長連線),執行緒一旦建立在很長時間內都保持著。但是,在訪問量比較大,機器比較多的情況下,這種用法很可能會導致“資料庫連線數耗盡”,因為建立連線並不回收,最終達到資料庫的max_connections(最大連線數)。因此,長連線的用法通常需要在CGI和MySQL之間實現一個“連線池”服務,控制CGI機器“盲目”建立連線數。
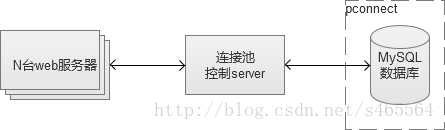
建立資料庫連線池服務,有很多實現的方式,PHP的話,我推薦使用swoole(PHP的一個網路通訊拓展)來實現。
3. Innodb快取設定(innodb_buffer_pool_size)
innodb_buffer_pool_size這是個用來儲存索引和資料的記憶體快取區,如果機器是MySQL獨佔的機器,一般推薦為機器實體記憶體的80%。在取表資料的場景中,它可以減少磁碟IO。一般來說,這個值設定越大,cache命中率會越高。
4. 分庫/分表/分割槽。
MySQL資料庫表一般承受資料量在百萬級別,再往上增長,各項效能將會出現大幅度下降,因此,當我們預見資料量會超過這個量級的時候,建議進行分庫/分表/分割槽等操作。最好的做法,是服務在搭建之初就設計為分庫分表的儲存模式,從根本上杜絕中後期的風險。不過,會犧牲一些便利性,例如列表式的查詢,同時,也增加了維護的複雜度。不過,到了資料量千萬級別或者以上的時候,我們會發現,它們都是值得的。
二、 MySQL資料庫多臺服務搭建
1臺MySQL機器,實際上是高風險的單點,因為如果它掛了,我們Web服務就不可用了。而且,隨著Web系統訪問量繼續增加,終於有一天,我們發現1臺MySQL伺服器無法支撐下去,我們開始需要使用更多的MySQL機器。當引入多臺MySQL機器的時候,很多新的問題又將產生。
1. 建立MySQL主從,從庫作為備份
這種做法純粹為了解決“單點故障”的問題,在主庫出故障的時候,切換到從庫。不過,這種做法實際上有點浪費資源,因為從庫實際上被閒著了。
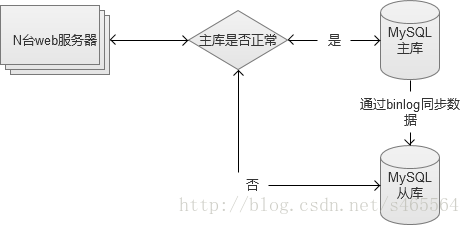
2. MySQL讀寫分離,主庫寫,從庫讀。
兩臺資料庫做讀寫分離,主庫負責寫入類的操作,從庫負責讀的操作。並且,如果主庫發生故障,仍然不影響讀的操作,同時也可以將全部讀寫都臨時切換到從庫中(需要注意流量,可能會因為流量過大,把從庫也拖垮)。

3. 主主互備。
兩臺MySQL之間互為彼此的從庫,同時又是主庫。這種方案,既做到了訪問量的壓力分流,同時也解決了“單點故障”問題。任何一臺故障,都還有另外一套可供使用的服務。
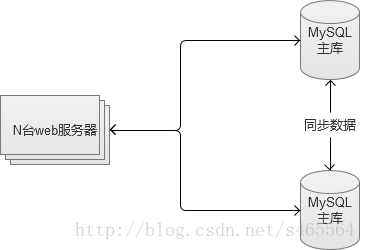
不過,這種方案,只能用在兩臺機器的場景。如果業務拓展還是很快的話,可以選擇將業務分離,建立多個主主互備。
三、 MySQL資料庫機器之間的資料同步
每當我們解決一個問題,新的問題必然誕生在舊的解決方案上。當我們有多臺MySQL,在業務高峰期,很可能出現兩個庫之間的資料有延遲的場景。並且,網路和機器負載等,也會影響資料同步的延遲。我們曾經遇到過,在日訪問量接近1億的特殊場景下,出現,從庫資料需要很多天才能同步追上主庫的資料。這種場景下,從庫基本失去效用了。
於是,解決同步問題,就是我們下一步需要關注的點。
1. MySQL自帶多執行緒同步
MySQL5.6開始支援主庫和從庫資料同步,走多執行緒。但是,限制也是比較明顯的,只能以庫為單位。MySQL資料同步是通過binlog日誌,主庫寫入到binlog日誌的操作,是具有順序的,尤其當SQL操作中含有對於表結構的修改等操作,對於後續的SQL語句操作是有影響的。因此,從庫同步資料,必須走單程序。
2. 自己實現解析binlog,多執行緒寫入。
以資料庫的表為單位,解析binlog多張表同時做資料同步。這樣做的話,的確能夠加快資料同步的效率,但是,如果表和表之間存在結構關係或者資料依賴的話,則同樣存在寫入順序的問題。這種方式,可用於一些比較穩定並且相對獨立的資料表。
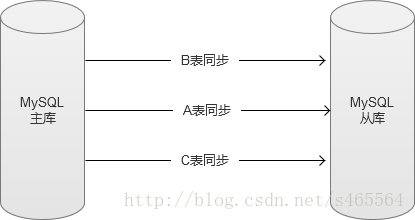
國內一線網際網路公司,大部分都是通過這種方式,來加快資料同步效率。還有更為激進的做法,是直接解析binlog,忽略以表為單位,直接寫入。但是這種做法,實現複雜,使用範圍就更受到限制,只能用於一些場景特殊的資料庫中(沒有表結構變更,表和表之間沒有資料依賴等特殊表)。
四、 在Web伺服器和資料庫之間建立快取
實際上,解決大訪問量的問題,不能僅僅著眼於資料庫層面。根據“二八定律”,80%的請求只關注在20%的熱點資料上。因此,我們應該建立Web伺服器和資料庫之間的快取機制。這種機制,可以用磁碟作為快取,也可以用記憶體快取的方式。通過它們,將大部分的熱點資料查詢,阻擋在資料庫之前。

1. 頁面靜態化
使用者訪問網站的某個頁面,頁面上的大部分內容在很長一段時間內,可能都是沒有變化的。例如一篇新聞報道,一旦釋出幾乎是不會修改內容的。這樣的話,通過CGI生成的靜態html頁面快取到Web伺服器的磁碟本地。除了第一次,是通過動態CGI查詢資料庫獲取之外,之後都直接將本地磁碟檔案返回給使用者。
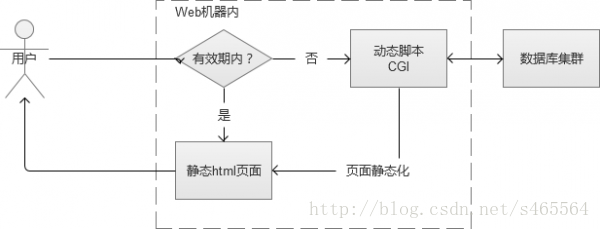
在Web系統規模比較小的時候,這種做法看似完美。但是,一旦Web系統規模變大,例如當我有100臺的Web伺服器的時候。那樣這些磁碟檔案,將會有100份,這個是資源浪費,也不好維護。這個時候有人會想,可以集中一臺伺服器存起來,呵呵,不如看看下面一種快取方式吧,它就是這樣做的。
2. 單臺記憶體快取
通過頁面靜態化的例子中,我們可以知道將“快取”搭建在Web機器本機是不好維護的,會帶來更多問題(實際上,通過PHP的apc拓展,可通過Key/value操作Web伺服器的本機記憶體)。因此,我們選擇搭建的記憶體快取服務,也必須是一個獨立的服務。
記憶體快取的選擇,主要有redis/memcache。從效能上說,兩者差別不大,從功能豐富程度上說,Redis更勝一籌。
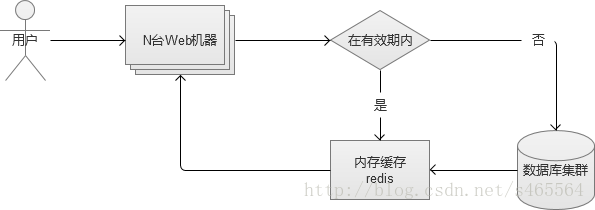
3. 記憶體快取叢集
當我們搭建單臺記憶體快取完畢,我們又會面臨單點故障的問題,因此,我們必須將它變成一個叢集。簡單的做法,是給他增加一個slave作為備份機器。但是,如果請求量真的很多,我們發現cache命中率不高,需要更多的機器記憶體呢?因此,我們更建議將它配置成一個叢集。例如,類似redis cluster。
Redis cluster叢集內的Redis互為多組主從,同時每個節點都可以接受請求,在拓展叢集的時候比較方便。客戶端可以向任意一個節點發送請求,如果是它的“負責”的內容,則直接返回內容。否則,查詢實際負責Redis節點,然後將地址告知客戶端,客戶端重新請求。
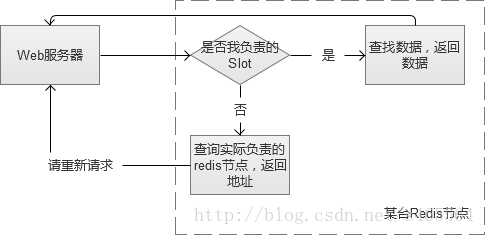
對於使用快取服務的客戶端來說,這一切是透明的。

記憶體快取服務在切換的時候,是有一定風險的。從A叢集切換到B叢集的過程中,必須保證B叢集提前做好“預熱”(B叢集的記憶體中的熱點資料,應該儘量與A叢集相同,否則,切換的一瞬間大量請求內容,在B叢集的記憶體快取中查詢不到,流量直接衝擊後端的資料庫服務,很可能導致資料庫宕機)。
4. 減少資料庫“寫”
上面的機制,都實現減少資料庫的“讀”的操作,但是,寫的操作也是一個大的壓力。寫的操作,雖然無法減少,但是可以通過合併請求,來起到減輕壓力的效果。這個時候,我們就需要在記憶體快取叢集和資料庫叢集之間,建立一個修改同步機制。
先將修改請求生效在cache中,讓外界查詢顯示正常,然後將這些sql修改放入到一個佇列中儲存起來,佇列滿或者每隔一段時間,合併為一個請求到資料庫中更新資料庫。

除了上述通過改變系統架構的方式提升寫的效能外,MySQL本身也可以通過配置引數innodb_flush_log_at_trx_commit來調整寫入磁碟的策略。如果機器成本允許,從硬體層面解決問題,可以選擇老一點的RAID(Redundant Arrays of independent Disks,磁碟列陣)或者比較新的SSD(Solid State Drives,固態硬碟)。
5. NoSQL儲存
不管資料庫的讀還是寫,當流量再進一步上漲,終會達到“人力有窮時”的場景。繼續加機器的成本比較高,並且不一定可以真正解決問題的時候。這個時候,部分核心資料,就可以考慮使用NoSQL的資料庫。NoSQL儲存,大部分都是採用key-value的方式,這裡比較推薦使用上面介紹過Redis,Redis本身是一個記憶體cache,同時也可以當做一個儲存來使用,讓它直接將資料落地到磁碟。
這樣的話,我們就將資料庫中某些被頻繁讀寫的資料,分離出來,放在我們新搭建的Redis儲存叢集中,又進一步減輕原來MySQL資料庫的壓力,同時因為Redis本身是個記憶體級別的Cache,讀寫的效能都會大幅度提升。
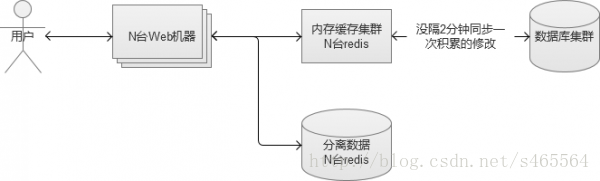
國內一線網際網路公司,架構上採用的解決方案很多是類似於上述方案,不過,使用的cache服務卻不一定是Redis,他們會有更豐富的其他選擇,甚至根據自身業務特點開發出自己的NoSQL服務。
6. 空節點查詢問題
當我們搭建完前面所說的全部服務,認為Web系統已經很強的時候。我們還是那句話,新的問題還是會來的。空節點查詢,是指那些資料庫中根本不存在的資料請求。例如,我請求查詢一個不存在人員資訊,系統會從各級快取逐級查詢,最後查到到資料庫本身,然後才得出查詢不到的結論,返回給前端。因為各級cache對它無效,這個請求是非常消耗系統資源的,而如果大量的空節點查詢,是可以衝擊到系統服務的。
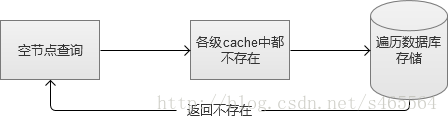
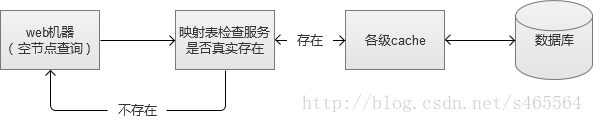
在我曾經的工作經歷中,曾深受其害。因此,為了維護Web系統的穩定性,設計適當的空節點過濾機制,非常有必要。
我們當時採用的方式,就是設計一張簡單的記錄對映表。將存在的記錄儲存起來,放入到一臺記憶體cache中,這樣的話,如果還有空節點查詢,則在快取這一層就被阻擋了。
異地部署(地理分散式)
完成了上述架構建設之後,我們的系統是否就已經足夠強大了呢?答案當然是否定的哈,優化是無極限的。Web系統雖然表面上看,似乎比較強大了,但是給予使用者的體驗卻不一定是最好的。因為東北的同學,訪問深圳的一個網站服務,他還是會感到一些網路距離上的慢。這個時候,我們就需要做異地部署,讓Web系統離使用者更近。
一、 核心集中與節點分散
有玩過大型網遊的同學都會知道,網遊是有很多個區的,一般都是按照地域來分,例如廣東專區,北京專區。如果一個在廣東的玩家,去北京專區玩,那麼他會感覺明顯比在廣東專區卡。實際上,這些大區的名稱就已經說明了,它的伺服器所在地,所以,廣東的玩家去連線地處北京的伺服器,網路當然會比較慢。
當一個系統和服務足夠大的時候,就必須開始考慮異地部署的問題了。讓你的服務,儘可能離使用者更近。我們前面已經提到了Web的靜態資源,可以存放在CDN上,然後通過DNS/GSLB的方式,讓靜態資源的分散“全國各地”。但是,CDN只解決的靜態資源的問題,沒有解決後端龐大的系統服務還只集中在某個固定城市的問題。
這個時候,異地部署就開始了。異地部署一般遵循:核心集中,節點分散。
1. 核心集中:實際部署過程中,總有一部分的資料和服務存在不可部署多套,或者部署多套成本巨大。而對於這些服務和資料,就仍然維持一套,而部署地點選擇一個地域比較中心的地方,通過網路內部專線來和各個節點通訊。
2. 節點分散:將一些服務部署為多套,分佈在各個城市節點,讓使用者請求儘可能選擇近的節點訪問服務。
例如,我們選擇在上海部署為核心節點,北京,深圳,武漢,上海為分散節點(上海自己本身也是一個分散節點)。我們的服務架構如圖:
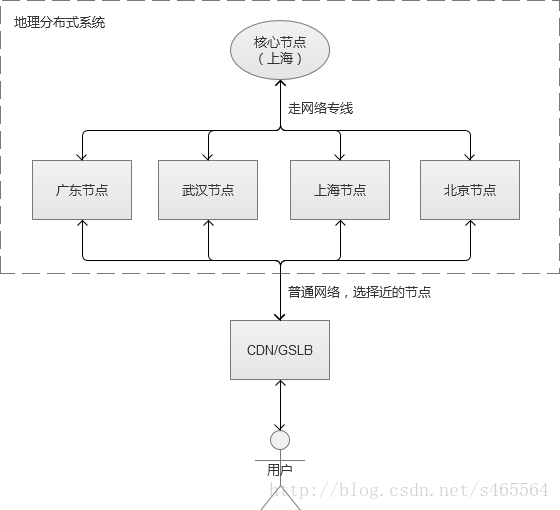
需要補充一下的是,上圖中上海節點和核心節點是同處於一個機房的,其他分散節點各自獨立機房。
國內有很多大型網遊,都是大致遵循上述架構。它們會把資料量不大的使用者核心賬號等放在核心節點,而大部分的網遊資料,例如裝備、任務等資料和服務放在地區節點裡。當然,核心節點和地域節點之間,也有快取機制。
二、 節點容災和過載保護
節點容災是指,某個節點如果發生故障時,我們需要建立一個機制去保證服務仍然可用。毫無疑問,這裡比較常見的容災方式,是切換到附近城市節點。假如系統的天津節點發生故障,那麼我們就將網路流量切換到附近的北京節點上。考慮到負載均衡,可能需要同時將流量切換到附近的幾個地域節點。另一方面,核心節點自身也是需要自己做好容災和備份的,核心節點一旦故障,就會影響全國服務。
過載保護,指的是一個節點已經達到最大容量,無法繼續接接受更多請求了,系統必須有一個保護的機制。一個服務已經滿負載,還繼續接受新的請求,結果很可能就是宕機,影響整個節點的服務,為了至少保障大部分使用者的正常使用,過載保護是必要的。
解決過載保護,一般2個方向:
1. 拒絕服務,檢測到滿負載之後,就不再接受新的連線請求。例如網遊登入中的排隊。
2. 分流到其他節點。這種的話,系統實現更為複雜,又涉及到負載均衡的問題。
小結
Web系統會隨著訪問規模的增長,漸漸地從1臺伺服器可以滿足需求,一直成長為“龐然大物”的大叢集。而這個Web系統變大的過程,實際上就是我們解決問題的過程。在不同的階段,解決不同的問題,而新的問題又誕生在舊的解決方案之上。
系統的優化是沒有極限的,軟體和系統架構也一直在快速發展,新的方案解決了老的問題,同時也帶來新的挑戰。
相關推薦
PHP的WEB系統從單機到分散式叢集的演進
當一個Web系統從日訪問量10萬逐步增長到1000萬,甚至超過1億的過程中,Web系統承受的壓力會越來越大,在這個過程中,我們會遇到很多的問題。為了解決這些效能壓力帶來問題,我們需要在Web系統架構層面搭建多個層次的快取機制。在不同的壓力階段,我們會遇
HRMS(人力資源管理系統)-從單機應用到SaaS應用-系統介紹
上週釋出的《2018,全新出發(全力推動實現住有所居)》文章,其中記錄了個人在這5年過程中的成長和收穫,有幸認識了不少部落格園的朋友,大家一起學習交流,在這個過程當中好多朋友提出SaaS系統如何設計,架構方面如何下手,在這5年的過程中我參與規劃設計了很多的SaaS系統其中有不少的坑和痛苦的經驗,特別
HRMS(人力資源管理系統)-從單機應用到SaaS應用-架構分析(功能性、非功能性、關鍵約束)-上篇
一、開篇 上一篇《HRMS(人力資源管理系統)-從單機應用到SaaS應用-系統介紹》我們已經詳細的分析了HRMS系統具備的功能,並且從HRMS系統的概念、系統功能、HR行業管理現狀及痛點、發展趨勢及行業前景、行業內的服務提供商情況、HRMS系統的建設意義及價值等方面進行了系統化的分析梳理。我想大家
HRMS(人力資源管理系統)-從單機應用到SaaS應用-架構分析(功能性、非功能性、關鍵約束)-下篇
一、開篇 本篇主將具體結合HRMS系統進行架構概要分析,按照上篇的理論指導,開展具體的架構分析過程實踐,通過分析找到關鍵功能、關鍵非功能性需求(關鍵質量及約束)等。 在闡述具體的架構工作方法之前,請大家先檢視以下三方面的內容: 1、HRMS系統的介紹?(涵蓋哪些功能
asp.net core 從單機到叢集
asp.net core 從單機到叢集 Intro 這篇文章主要以我的活動室預約的專案作為示例,看一下一個 asp.net core 應用從單機應用到分散式應用需要做什麼。 示例專案 活動室預約提供了兩個版本,叢集版 和 單機版 單機版方便部署,不依賴其他環境,資料庫使用的是 sqlite,詳細部署文件可以參
P9架構師講解從單機至億級流量大型網站系統架構的演進過程
獲取域名 哈希算法 相關 方案 nat 可靠的 發布 成了 反向 階段一、單機構建網站 網站的初期,我們經常會在單機上跑我們所有的程序和軟件。此時我們使用一個容器,如tomcat、jetty、jboos,然後直接使用JSP/servlet技術,或者使用一些開源的框架如mav
阿里P9架構師講解從單機至億級流量大型網站系統架構的演進過程
階段一、單機構建網站 網站的初期,我們經常會在單機上跑我們所有的程式和軟體。此時我們使用一個容器,如tomcat、jetty、jboos,然後直接使用JSP/servlet技術,或者使用一些開源的框架如maven+spring+struct+hibernate、maven+
阿里P9架構師簡述從單機至億級流量大型網站系統架構的演進過程
階段一、單機構建網站 網站的初期,我們經常會在單機上跑我們所有的程式和軟體。此時我們使用一個容器,如tomcat、jetty、jboos,然後直接使用JSP/servlet技術,或者使用一些開源的框架如maven+spring+struct+hibernate、maven+
億級Web系統搭建——單機到分散式叢集
導讀】徐漢彬曾在阿里巴巴和騰訊從事4年多的技術研發工作,負責過日請求量過億的Web系統升級與重構,目前在小滿科技創業,從事SaaS服務技術建設。 大規模流量的網站架構,從來都是慢慢“成長”而來。而這個過程中,會遇到很多問題,在不斷解決問題的過程中,Web系統變得越來越
Hadoop單機/偽分散式叢集搭建(新手向)
此文已由作者朱笑笑授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 本文主要參照官網的安裝步驟實現了Hadoop偽分散式叢集的搭建,希望能夠為初識Hadoop的小夥伴帶來借鑑意義。 環境: (1)系統環境:CentOS 7.3.1611 64位 (2)J
從構建分散式秒殺系統聊聊Disruptor高效能佇列
前言 秒殺架構持續優化中,基於自身認知不足之處在所難免,也請大家指正,共同進步。文章標題來自碼友的建議,希望可以把阻塞佇列ArrayBlockingQueue這個佇列替換成Disruptor,由於之前曾接觸過這個東西,聽說很不錯,正好藉此機會整合進來。 簡介 LMAX
從構建分散式秒殺系統聊聊WebSocket推送通知
前言 秒殺架構到後期,我們採用了訊息佇列的形式實現搶購邏輯,那麼之前丟擲過這樣一個問題:訊息佇列非同步處理完每個使用者請求後,如何通知給相應使用者秒殺成功? 場景對映 首先,我們舉一個生活中比較常見的例子:我們去銀行辦理業務,一般會選擇相關業務列印一個排號紙,然後就
從構建分散式秒殺系統聊聊驗證碼
前言 為了攔截大部分請求,秒殺案例前端引入了驗證碼。淘寶上很多人吐槽,等輸入完秒殺活動結束了,對,結束了...... 當然了,驗證碼的真正作用是,有效攔截刷單操作,讓羊毛黨空手而歸。 驗證碼 那麼到底什麼是驗證碼呢?驗證碼作為一種人機識別手段,其終極目的,就是區分正常人和機器的操作。我們常見的網際網路註冊、
從構建分散式秒殺系統聊聊限流特技 侵立刪
轉自:https://mp.weixin.qq.com/s/Jgp4KCRmuqVp6W6nd3Bxtw 前言 俗話說的好,冰凍三尺非一日之寒,滴水穿石非一日之功,羅馬也不是一天就建成的。兩週前秒殺案例初步成型,分享到了中國最大的同性交友網站-碼雲。同時也收到了不
【從零開始/親測國內外均可】基於阿里雲Ubuntu的kubernetes(k8s)主從節點分散式叢集搭建——分步詳細攻略v1.11.3【準備工作篇】
從零開始搭建k8s叢集——香港節點無牆篇【大陸節點有牆的安裝方法我會在每一步操作的時候提醒大家的注意,並告訴大家如何操作】 由於容器技術的火爆,現在使用K8s開展服務變得越來越廣泛了。 本攻略是基於阿里雲主機搭建的一個單主節點和單從節點的最簡k8s分散式叢集。 為了製作
Redis入門(七):Redis分散式鎖(單機模式/叢集模式)
Redis 實現分散式鎖 單機模式的Redis分散式鎖 優缺點 實現比較輕,大多數時候能滿足需求;因為是單機單例項部署,如果redis服務宕機,那麼所有需要獲取分散式鎖的地方均無法獲取鎖,將全部阻塞,需要做好降級處理。 當鎖過期後,執行任務的程序還沒有
kudu分散式儲存系統從入門到精通
課程目標 通過對本課程的學習能夠讓您對kudu從入門到精通,對已經從事相關大資料工作的學員能夠更深層次的學習新知識 適用人群 零基礎學員,大資料愛好者 課程簡介 系統環境: CentOS7.4+JDK
在搭建Hadoop 分散式叢集的時候,多次格式化檔案系統,啟動hdfs,yarn,後jps 發現datanode為啟動
可以參考:https://www.cnblogs.com/dxwhut/p/5679501.html https://blog.csdn.net/baidu_15113429/article/details/53739734 https://www.cnblogs.com/lishpei/p
【分散式系統】漫談分散式系統中的技術 —— 從 IPC/RPC,SOA,Web Service/REST 到 micro services(微服務)
1. 什麼是分散式系統 A distributed system is a system whose components are located on different networked computers, which then communicat
《雲端計算與分散式系統 從並行處理到物聯網》下載
2018年11月01日 12:51:53 qq_43553691 閱讀數:6 標籤: 程式設計 資料