
深入理解HBase的系統架構
很好的一篇文章,作者翻譯的真心棒。非常感謝。原文出處:https://blog.csdn.net/Yaokai_AssultMaster/article/details/72877127。請大家尊重原創,如需轉載,請寫明原文出處。謝謝
HBase的構成
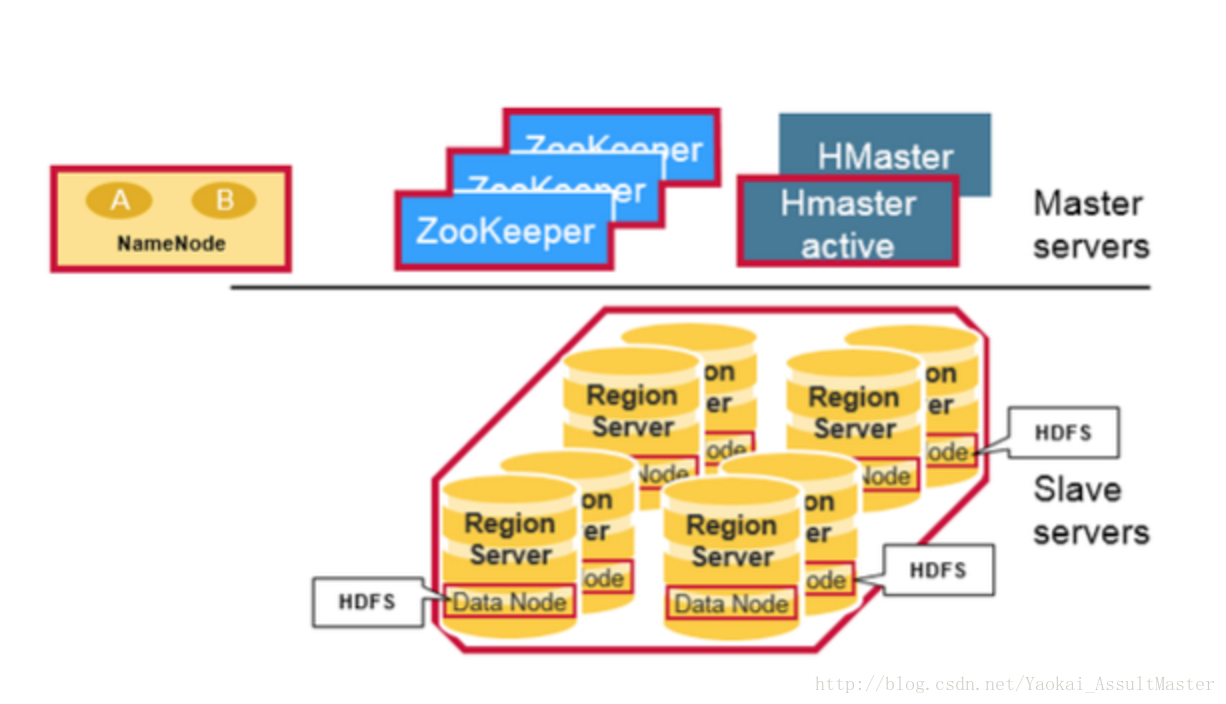
物理上來說,HBase是由三種類型的伺服器以主從模式構成的。這三種伺服器分別是:Region server,HBase HMaster,ZooKeeper。
其中Region server負責資料的讀寫服務。使用者通過溝通Region server來實現對資料的訪問。
HBase HMaster負責Region的分配及資料庫的建立和刪除等操作。
ZooKeeper作為HDFS的一部分,負責維護叢集的狀態(某臺伺服器是否線上,伺服器之間資料的同步操作及master的選舉等)。
另外,Hadoop DataNode負責儲存所有Region Server所管理的資料。HBase中的所有資料都是以HDFS檔案的形式儲存的。出於使Region server所管理的資料更加本地化的考慮,Region server是根據DataNode分佈的。HBase的資料在寫入的時候都儲存在本地。但當某一個region被移除或被重新分配的時候,就可能產生資料不在本地的情況。這種情況只有在所謂的compaction之後才能解決。
NameNode負責維護構成檔案的所有物理資料塊的元資訊(metadata)。
HBase結構如下圖所示:
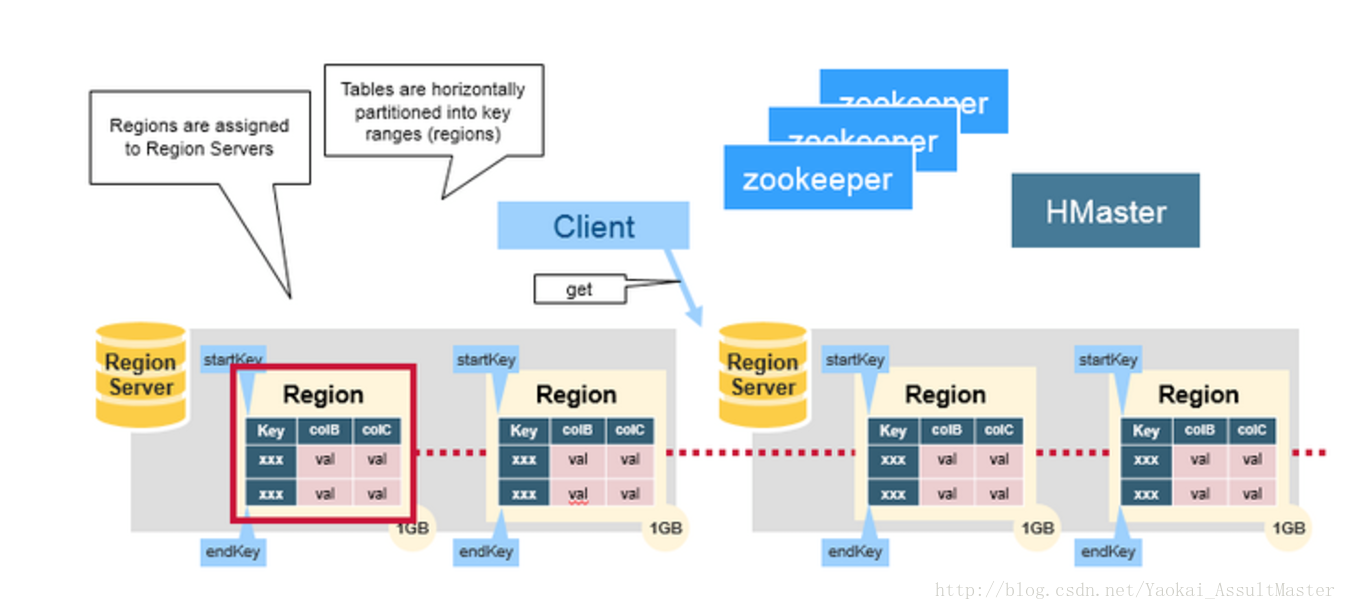
Regions
HBase中的表是根據row key的值水平分割成所謂的region的。一個region包含表中所有row key位於region的起始鍵值和結束鍵值之間的行。叢集中負責管理Region的結點叫做Region server。Region server負責資料的讀寫。每一個Region server大約可以管理1000個region。Region的結構如下圖所示:
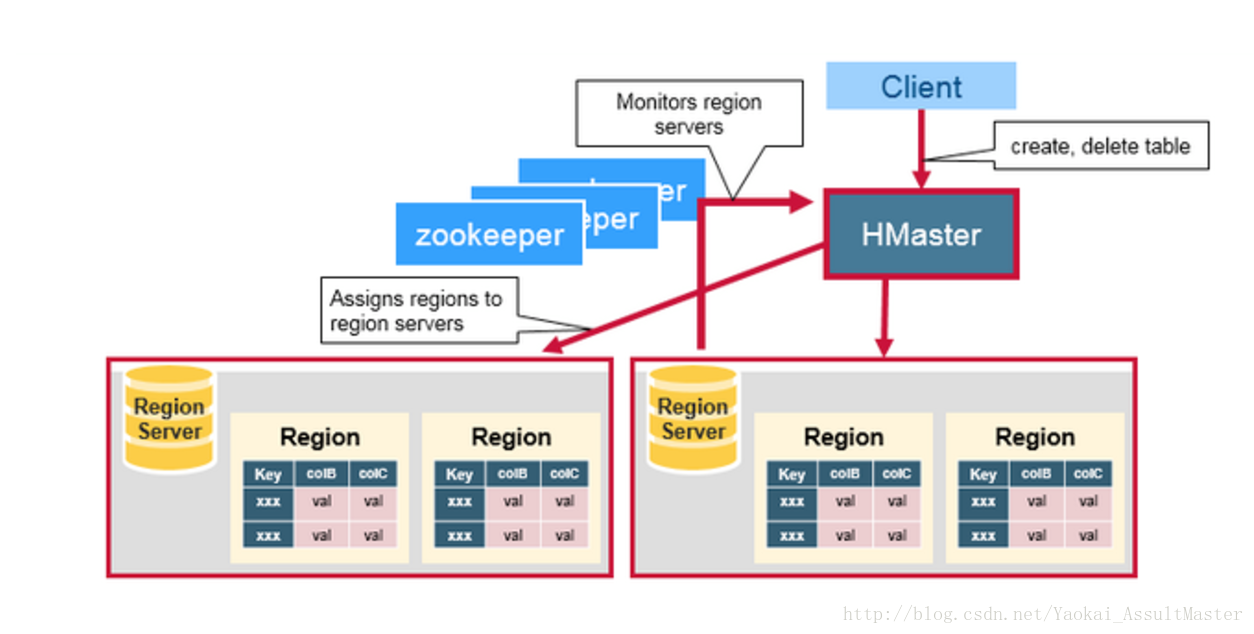
HBase的HMaster
HMaster負責region的分配,資料庫的建立和刪除操作。
具體來說,HMaster的職責包括:
- 調控Region server的工作
- 在叢集啟動的時候分配region,根據恢復服務或者負載均衡的需要重新分配region。
- 監控叢集中的Region server的工作狀態。(通過監聽zookeeper對於ephemeral node狀態的通知)。
- 管理資料庫
- 提供建立,刪除或者更新表格的介面。
HMaster的工作如下圖所示:
ZooKeeper
HBase利用ZooKeeper維護叢集中伺服器的狀態並協調分散式系統的工作。ZooKeeper維護伺服器是否存活,是否可訪問的狀態並提供伺服器故障/宕機的通知。ZooKeeper同時還使用一致性演算法來保證伺服器之間的同步。同時也負責Master選舉的工作。需要注意的是要保證良好的一致性及順利的Master選舉,叢集中的伺服器數目必須是奇數。例如三臺或五臺。
ZooKeeper的工作如下圖所示:
HBase各組成部分之間的合作
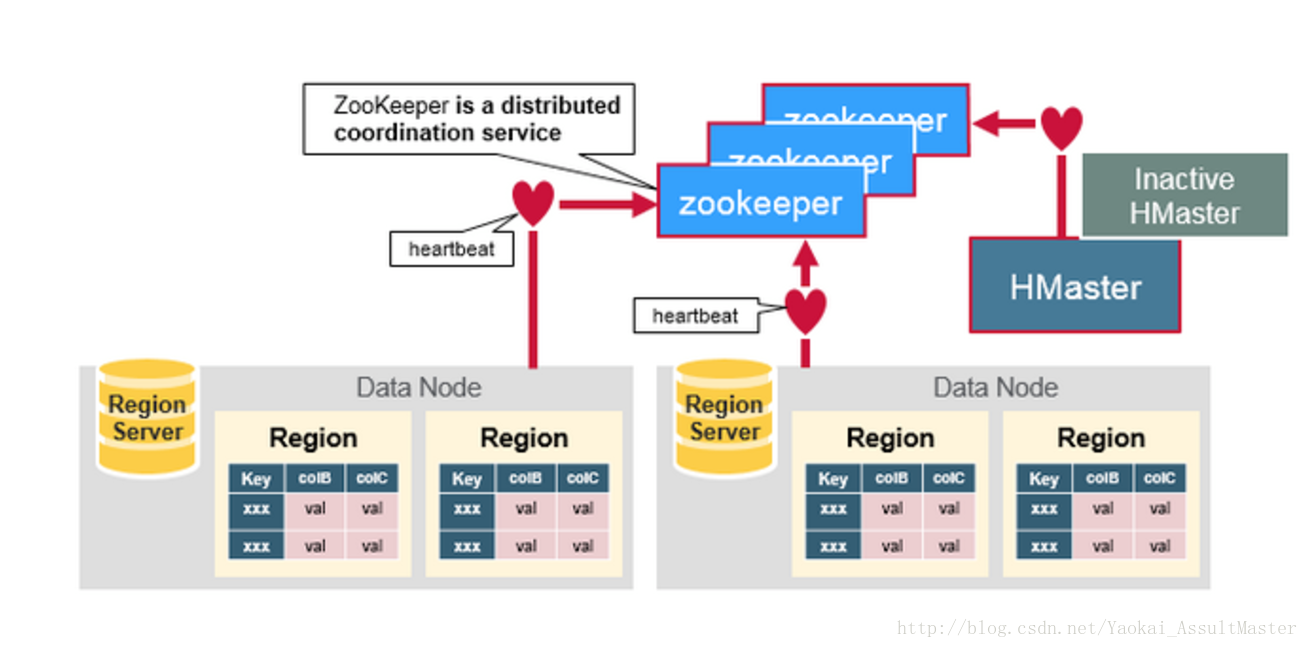
ZooKeeper用來協調分散式系統的成員之間共享的狀態資訊。Region Server及HMaster也與ZooKeeper連線。ZooKeeper通過心跳資訊為活躍的連線維持相應的ephemeral node。如下圖所示:
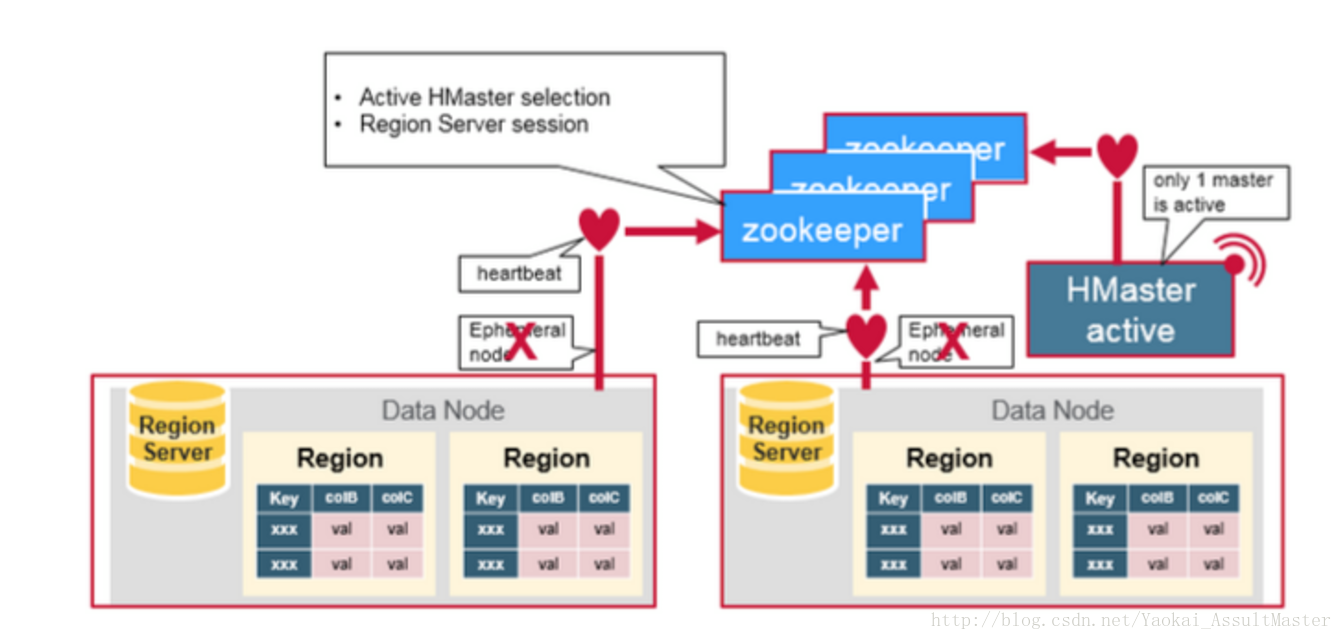
每一個Region server都在ZooKeeper中建立相應的ephemeral node。HMaster通過監控這些ephemeral node的狀態來發現正常工作的或發生故障下線的Region server。HMaster之間通過互相競爭建立ephemeral node進行Master選舉。ZooKeeper會選出區中第一個建立成功的作為唯一一個活躍的HMaster。活躍的HMaster向ZooKeeper傳送心跳資訊來表明自己線上的狀態。不活躍的HMaster則監聽活躍HMaster的狀態,並在活躍HMaster發生故障下線之後重新選舉,從而實現了HBase的高可用性。
如果Region server或者HMaster不能成功向ZooKeeper傳送心跳資訊,則其與ZooKeeper的連線超時之後與之相應的ephemeral node就會被刪除。監聽ZooKeeper狀態的其他節點就會得到相應node不存在的資訊,從而進行相應的處理。活躍的HMaster監聽Region Server的資訊,並在其下線後重新分配Region server來恢復相應的服務。不活躍的HMaster監聽活躍HMaster的資訊,並在起下線後重新選出活躍的HMaster進行服務。
HBase的第一次讀寫
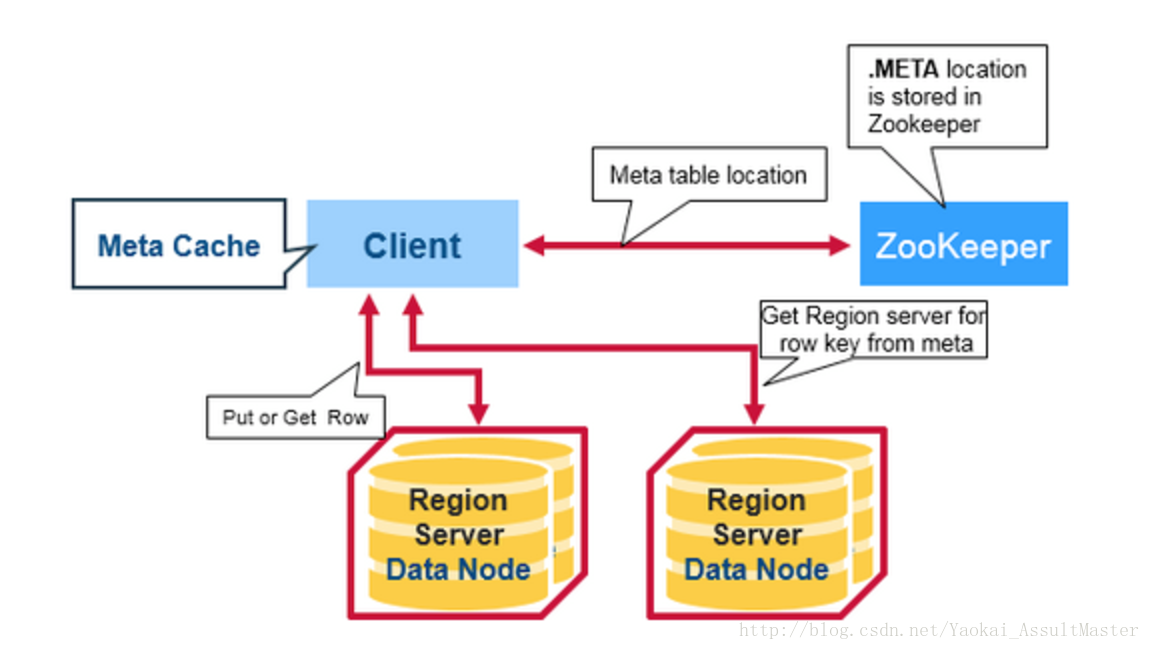
HBase中有一個特殊的起目錄作用的表格,稱為META table。META table中儲存叢集region的地址資訊。ZooKeeper中會儲存META table的位置。
當用戶第一次想HBase中進行讀或寫操作時,以下步驟將被執行:
- 客戶從ZooKeeper中得到儲存META table的Region server的資訊。
- 客戶向該Region server查詢負責管理自己想要訪問的row key的所在的region的Region server的地址。客戶會快取這一資訊以及META table所在位置的資訊。
- 客戶與負責其row所在region的Region Server通訊,實現對該行的讀寫操作。
在未來的讀寫操作中,客戶會根據快取尋找相應的Region server地址。除非該Region server不再可達。這時客戶會重新訪問META table並更新快取。這一過程如下圖所示:
HBase的META table
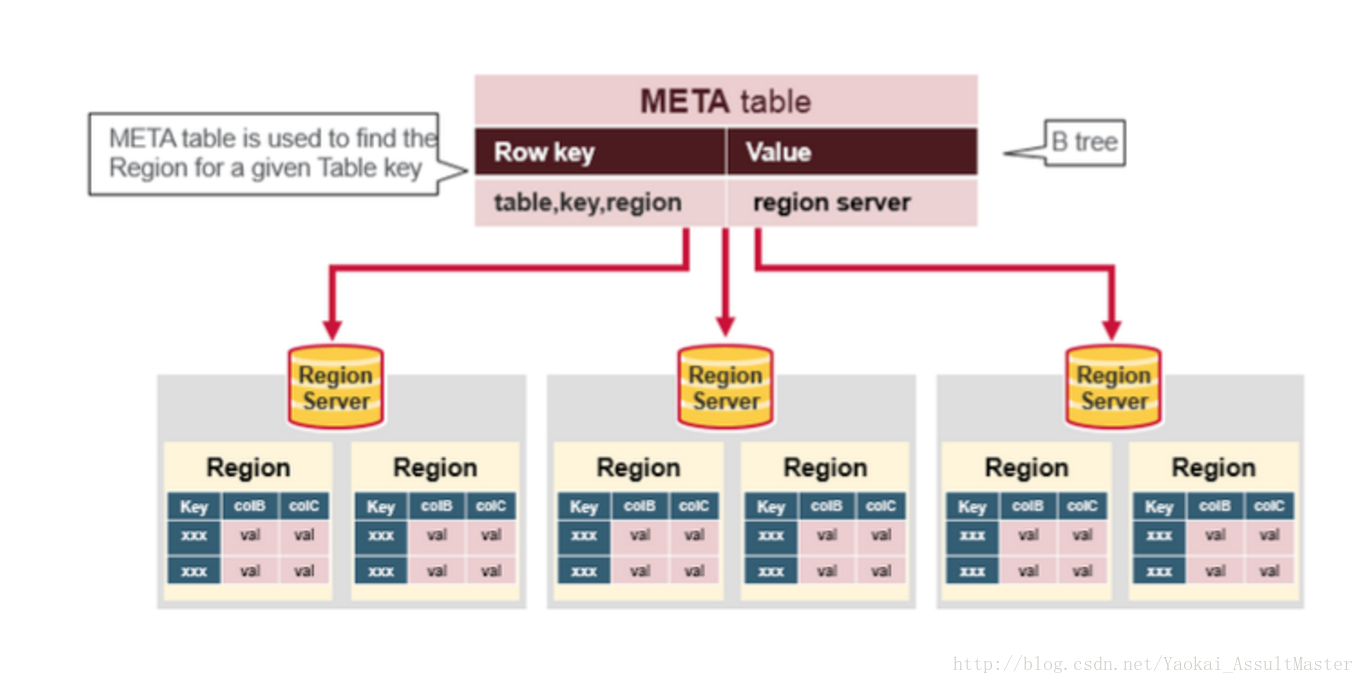
- META table中儲存了HBase中所有region的資訊。
- META table的格式類似於B tree。
- META table的結構如下:
- 鍵:region的起始鍵,region id。
- 值:Region server
如下圖所示:
Region Server的組成
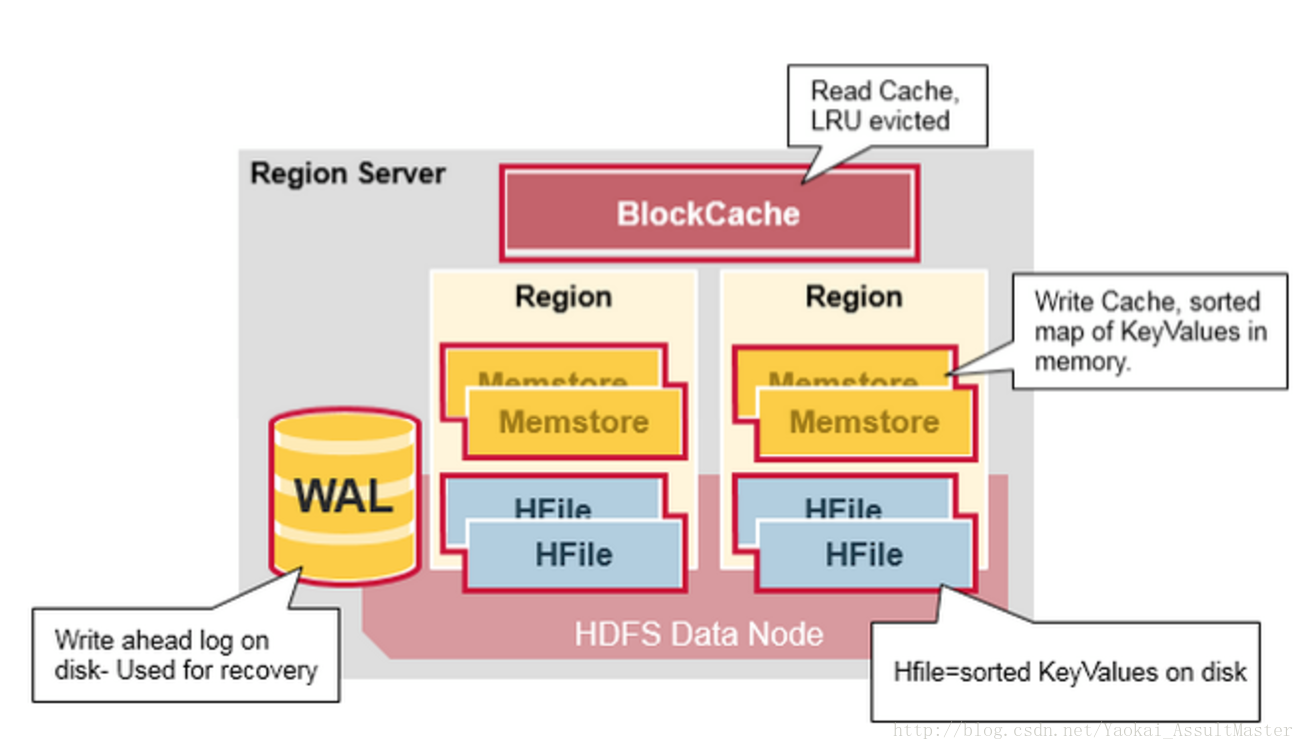
執行在HDFS DataNode上的Region server包含如下幾個部分:
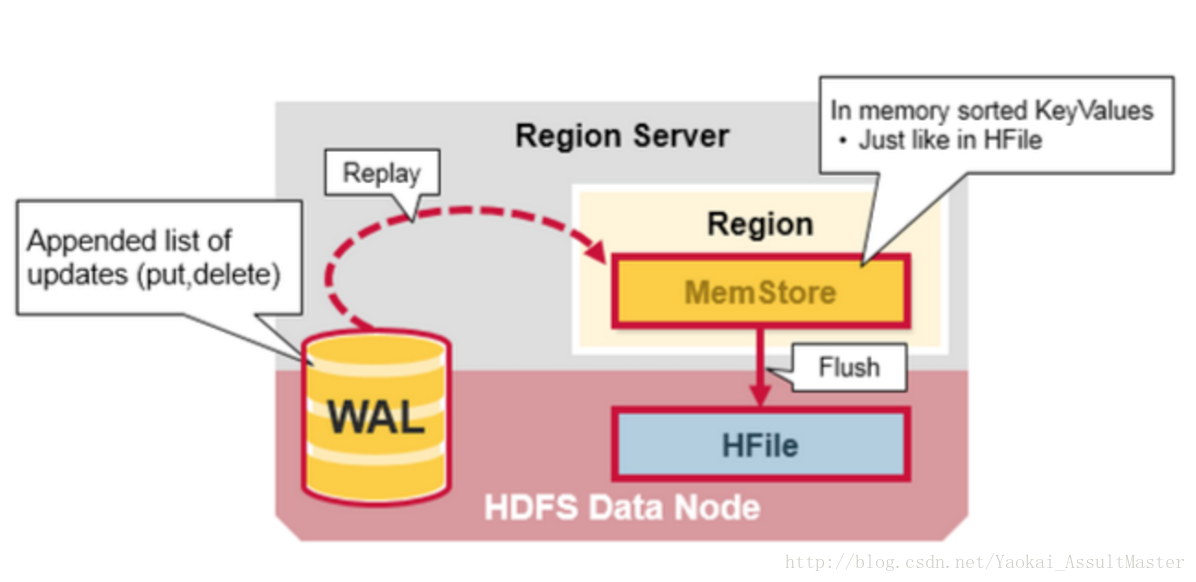
- WAL:既Write Ahead Log。WAL是HDFS分散式檔案系統中的一個檔案。WAL用來儲存尚未寫入永久性儲存區中的新資料。WAL也用來在伺服器發生故障時進行資料恢復。
- Block Cache:Block cache是讀快取。Block cache將經常被讀的資料儲存在記憶體中來提高讀取資料的效率。當Block cache的空間被佔滿後,其中被讀取頻率最低的資料將會被殺出。
- MemStore:MemStore是寫快取。其中儲存了從WAL中寫入但尚未寫入硬碟的資料。MemStore中的資料在寫入硬碟之前會先進行排序操作。每一個region中的每一個column family對應一個MemStore。
- Hfiles:Hfiles存在於硬碟上,根據排序號的鍵儲存資料行。
Region server的結構如下圖所示:
HBase的寫操作步驟
步驟一
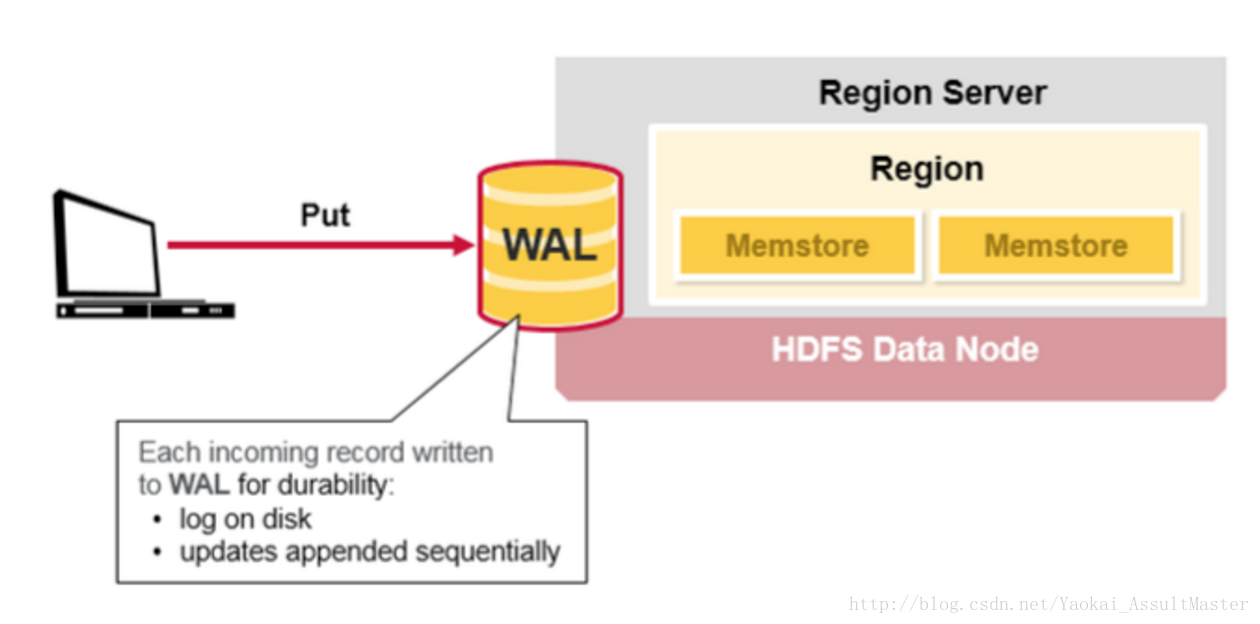
當HBase的使用者發出一個PUT請求時(也就是HBase的寫請求),HBase進行處理的第一步是將資料寫入HBase的write-ahead log(WAL)中。
- WAL檔案是順序寫入的,也就是所有新新增的資料都被加入WAL檔案的末尾。WAL檔案存在硬碟上。
- 當server出現問題之後,WAL可以被用來恢復尚未寫入HBase中的資料(因為WAL是儲存在硬碟上的)。
如下圖所示:
步驟二
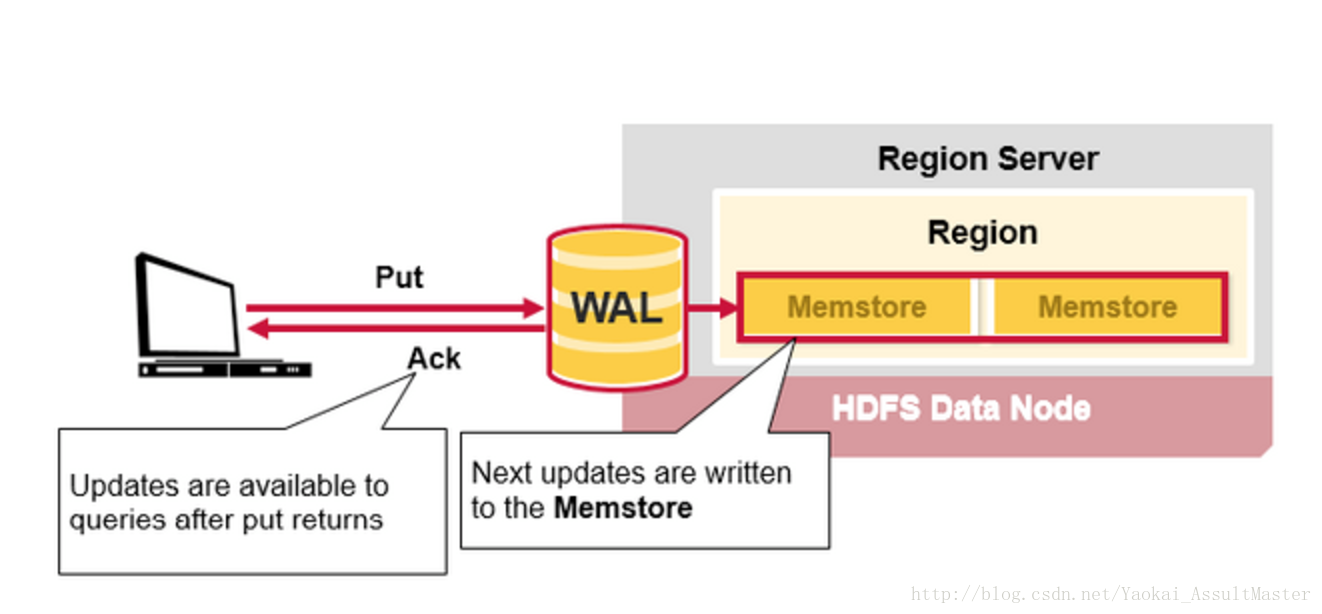
當資料被成功寫入WAL後,HBase將資料存入MemStore。這時HBase就會通知使用者PUT操作已經成功了。
過程如下圖所示:
HBase的MemStore
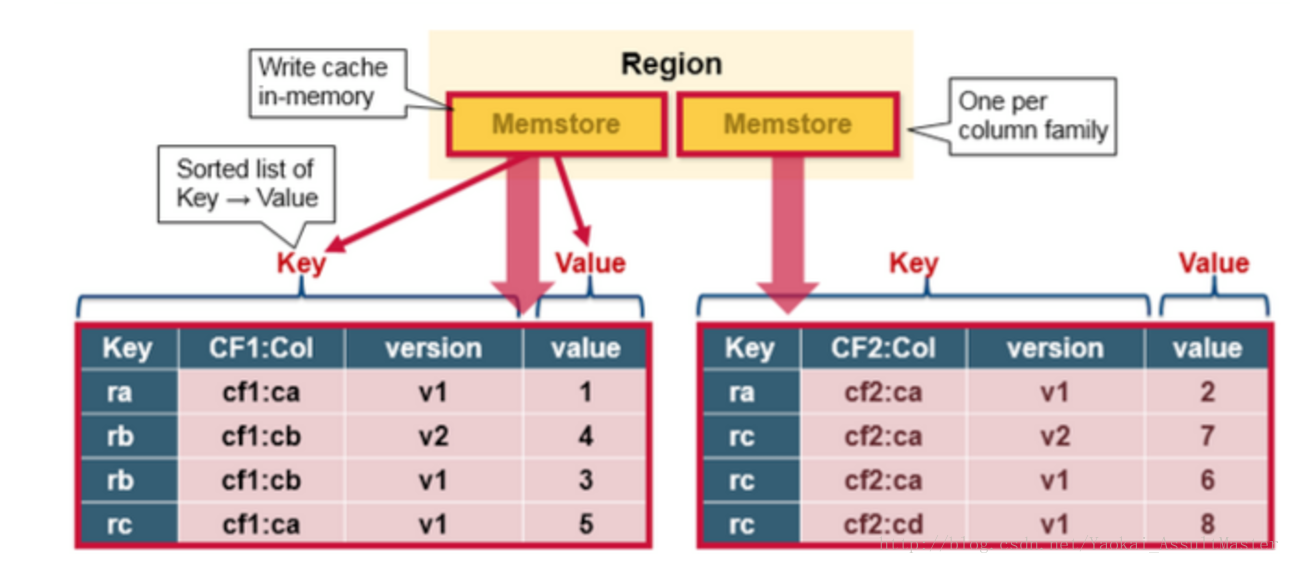
Memstore存在於記憶體中,其中儲存的是按鍵排好序的待寫入硬碟的資料。資料也是按鍵排好序寫入HFile中的。每一個Region中的每一個Column family對應一個Memstore檔案。因此對資料的更新也是對應於每一個Column family。
如下圖所示:
HBase Region Flush
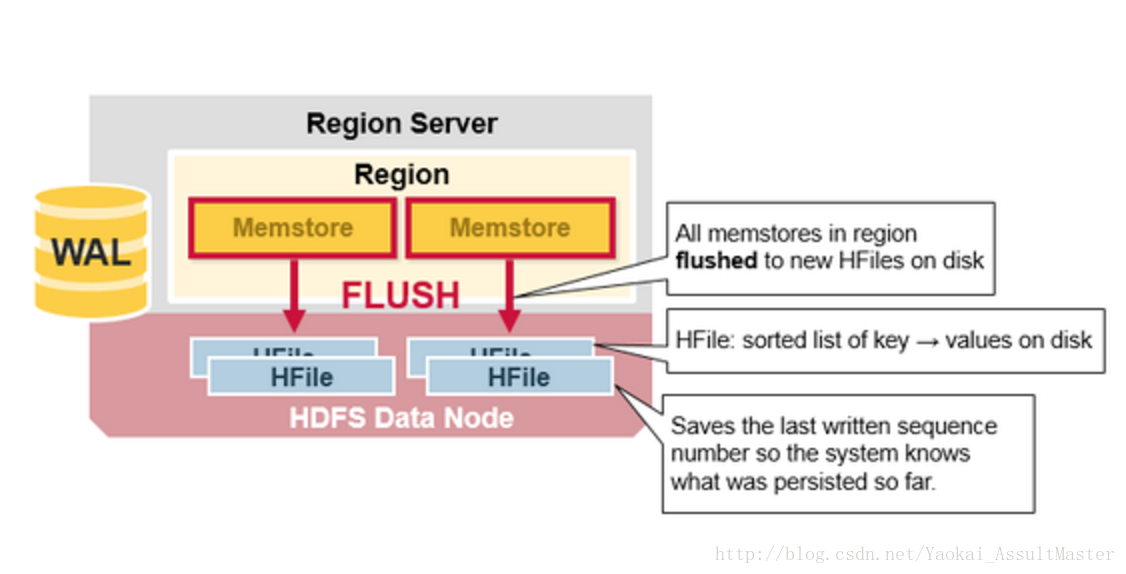
當MemStore中積累了足夠多的資料之後,整個Memcache中的資料會被一次性寫入到HDFS裡的一個新的HFile中。因此HDFS中一個Column family可能對應多個HFile。這個HFile中包含了相應的cell,或者說鍵值的例項。這些檔案隨著MemStore中積累的對資料的操作被flush到硬碟上而建立。
需要注意的是,MemStore儲存在記憶體中,這也是為什麼HBase中Column family的數目有限制的原因。每一個Column family對應一個MemStore,當MemStore存滿之後,裡面所積累的資料就會一次性flush到硬碟上。同時,為了使HDFS能夠知道當前哪些資料已經被儲存了,MemStore中還儲存最後一次寫操作的序號。
每個HFile中最大的序號作為meta field儲存在其中,這個序號標明瞭之前的資料向硬碟儲存的終止點和接下來繼續儲存的開始點。當一個region啟動的時候,它會讀取每一個HFile中的序號來得知當前region中最新的操作序號是什麼(最大的序號)。
如下圖所示:
HFile
HBase中的鍵值資料對儲存在HFile中。上面已經說過,當MemStore中積累足夠多的資料的時候就會將其中的資料整個寫入到HDFS中的一個新的HFile中。因為MemStore中的資料已經按照鍵排好序,所以這是一個順序寫的過程。由於順序寫操作避免了磁碟大量定址的過程,所以這一操作非常高效。
如下圖所示:
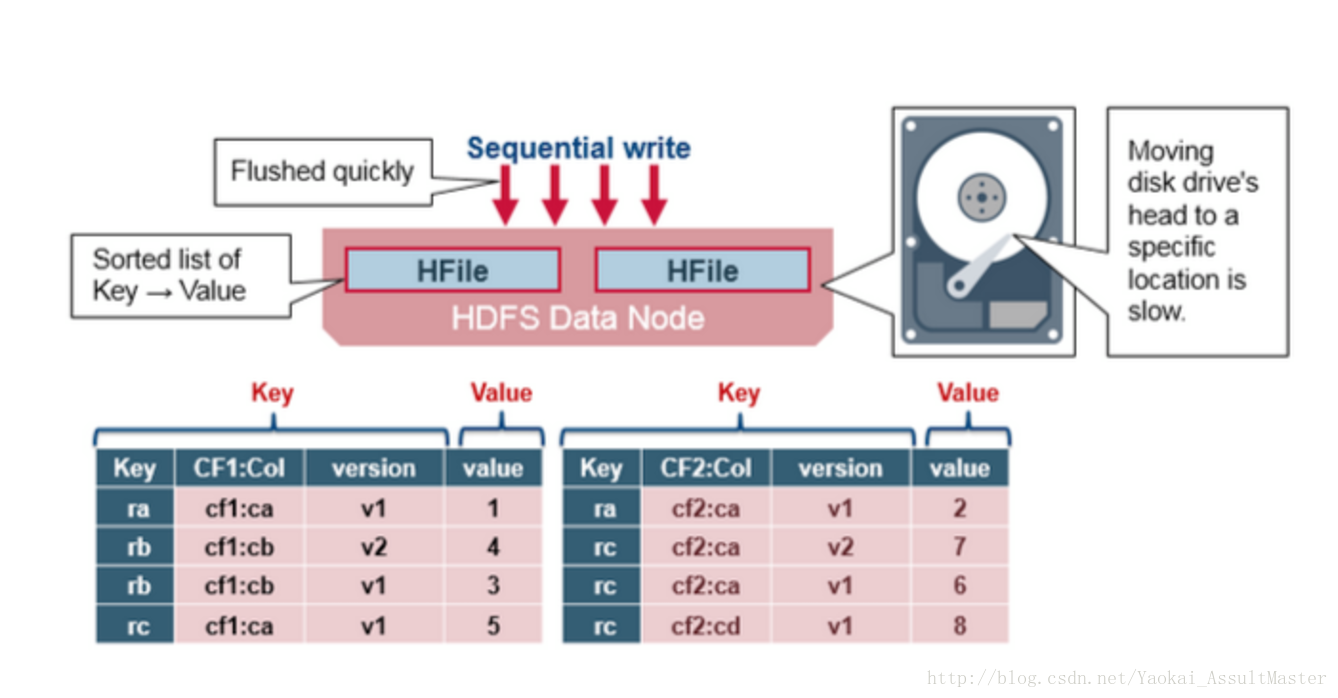
HFile的結構
HFile中包含了一個多層索引系統。這個多層索引是的HBase可以在不讀取整個檔案的情況下查詢資料。這一多層索引類似於一個B+樹。
- 鍵值對根據鍵大小升序排列。
- 索引指向64KB大小的資料塊。
- 每一個數據塊還有其相應的葉索引(leaf-index)。
- 每一個數據塊的最後一個鍵作為中間索引(intermediate index)。
- 根索引(root index)指向中間索引。
檔案結尾指向meta block。因為meta block是在資料寫入硬碟操作的結尾寫入該檔案中的。檔案的結尾同時還包含一些別的資訊。比如bloom filter及時間資訊。Bloom filter可以幫助HBase加速資料查詢的速度。因為HBase可以利用Bloom filter跳過不包含當前查詢的鍵的檔案。時間資訊則可以幫助HBase在查詢時跳過讀操作所期望的時間區域之外的檔案。
如下圖所示:
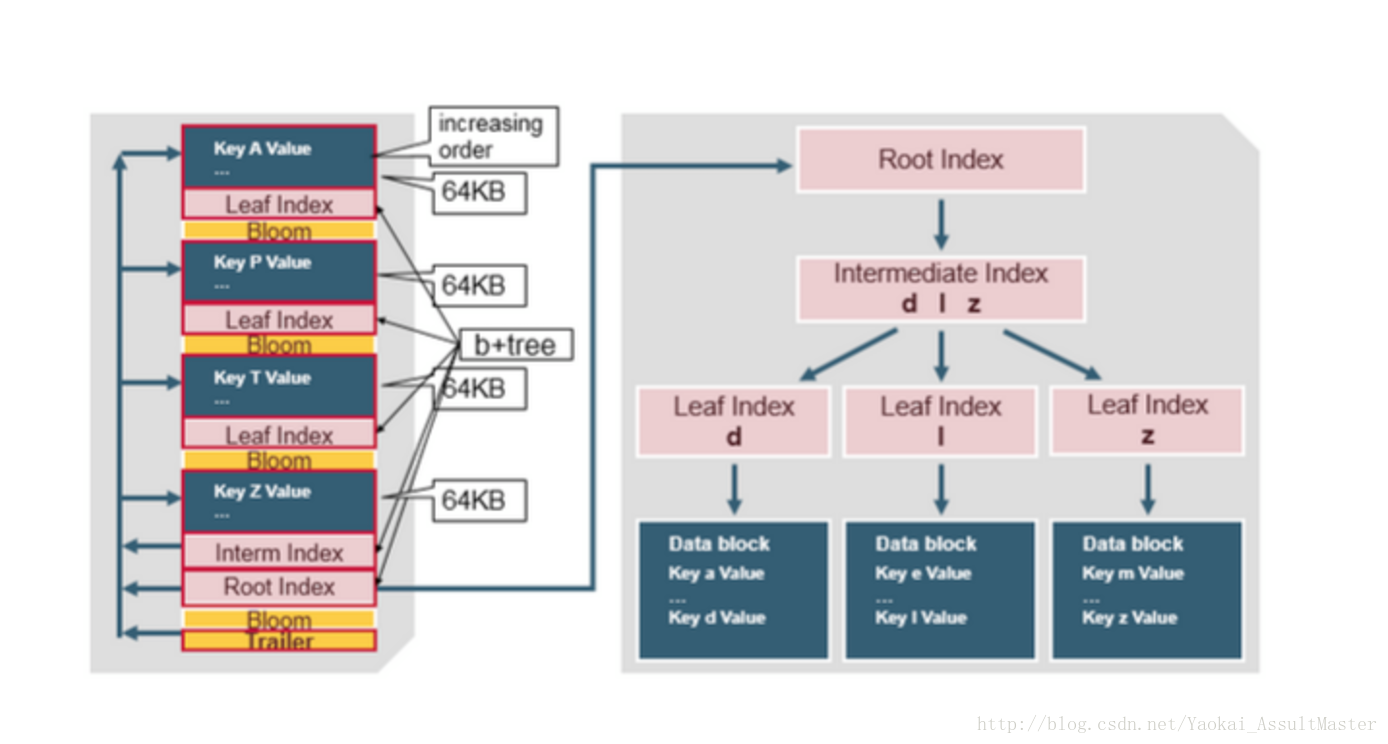
HFile的索引
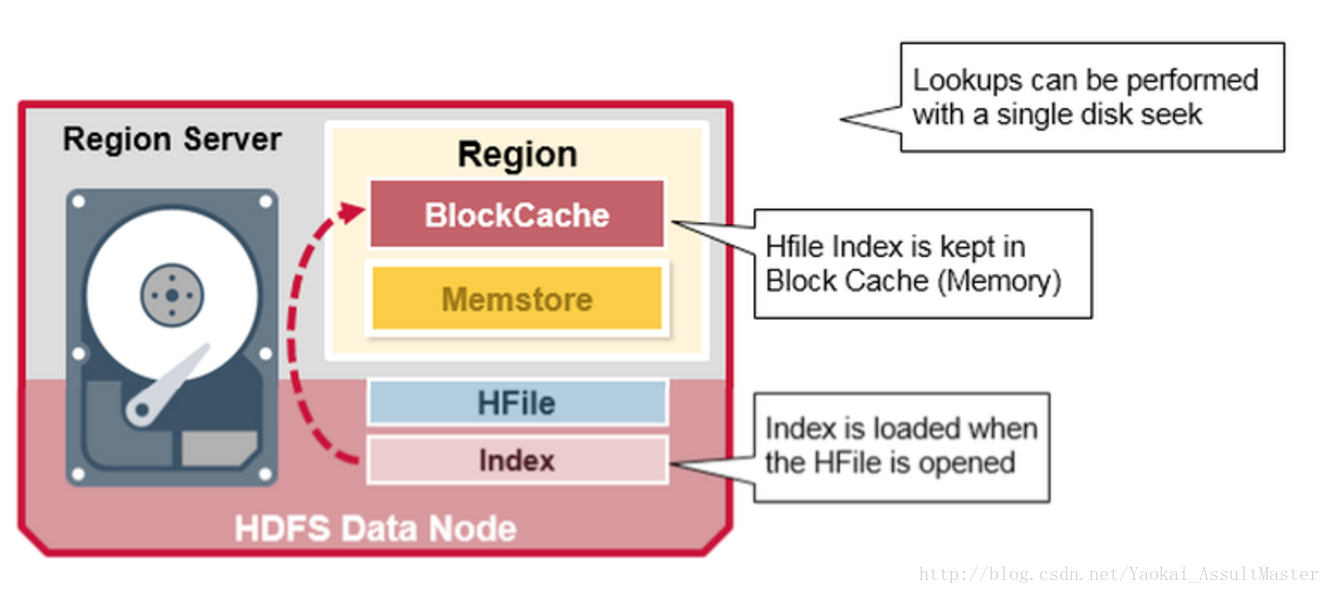
HFile的索引在HFile被開啟時會被讀取到記憶體中。這樣就可以保證資料檢索只需一次硬碟查詢操作。
如下圖所示:
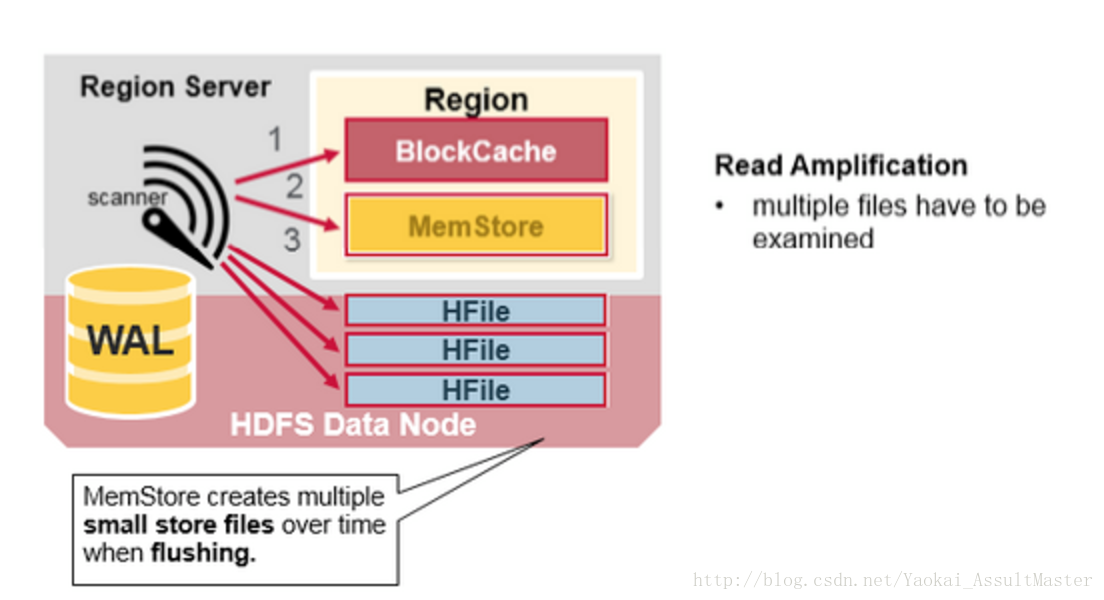
HBase的讀合併(Read Merge)以及讀放大(Read amplification)
通過上面的論述,我們已經知道了HBase中對應於某一行資料的cell可能位於多個不同的檔案或儲存介質中。比如已經存入硬碟的行位於硬碟上的HFile中,新加入或更新的資料位於記憶體中的MemStore中,最近讀取過的資料則位於記憶體中的Block cache中。所以當我們讀取某一行的時候,為了返回相應的行資料,HBase需要根據Block cache,MemStore以及硬碟上的HFile中的資料進行所謂的讀合併操作。
- HBase會首先從Block cache(HBase的讀快取)中尋找所需的資料。
- 接下來,HBase會從MemStore中尋找資料。因為作為HBase的寫快取,MemStore中包含了最新版本的資料。
- 如果HBase從Block cache和MemStore中沒有找到行所對應的cell所有的資料,系統會接著根據索引和
bloom filter從相應的HFile中讀取目標行的cell的資料。
如下圖所示:
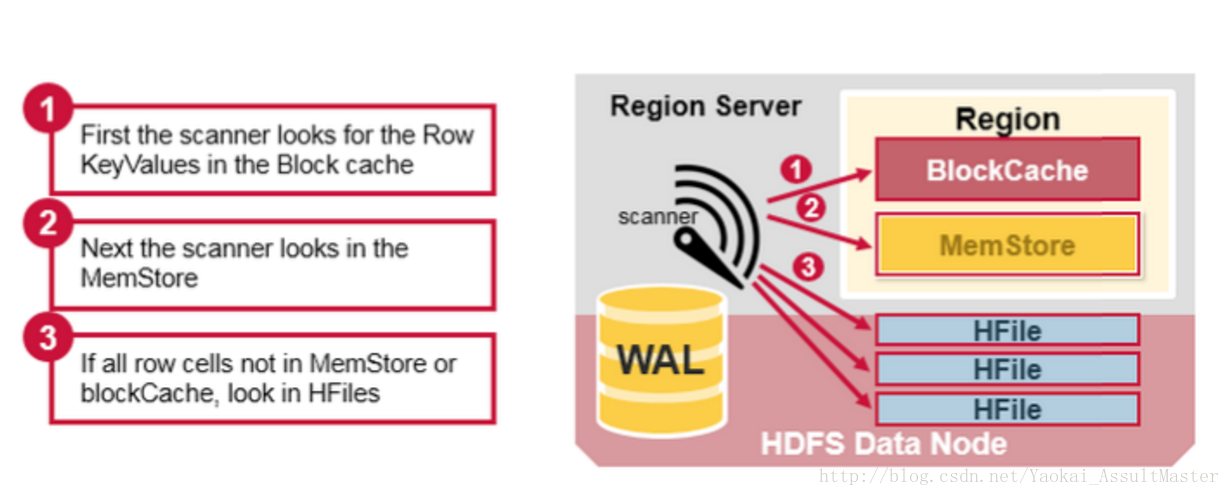
這裡一個需要注意的地方是所謂的讀放大效應(Read amplification)。根據前文所說,一個MemStore對應的資料可能儲存於多個不同的HFile中(由於多次的flush),因此在進行讀操作的時候,HBase可能需要讀取多個HFile來獲取想要的資料。這會影響HBase的效能表現。
如下圖所示:
HBase的Compaction
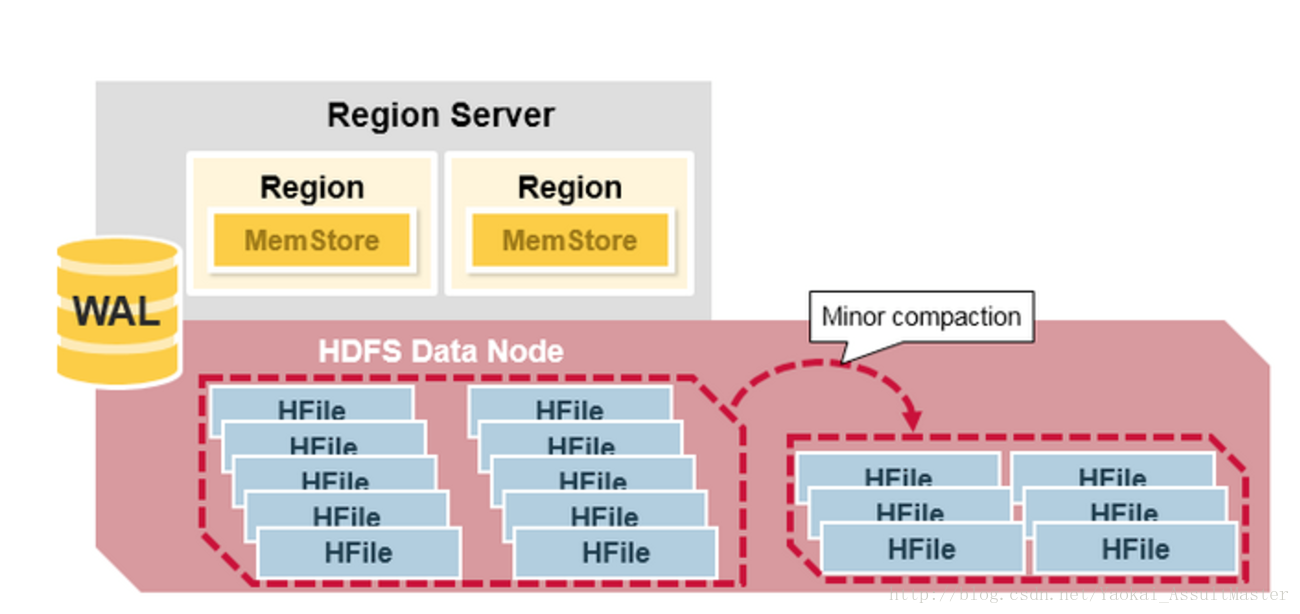
Minor Compaction
HBase會自動選取一些較小的HFile進行合併,並將結果寫入幾個較大的HFile中。這一過程稱為Minor compaction。Minor compaction通過Merge sort的形式將較小的檔案合併為較大的檔案,從而減少了儲存的HFile的數量,提升HBase的效能。
這一過程如下圖所示:
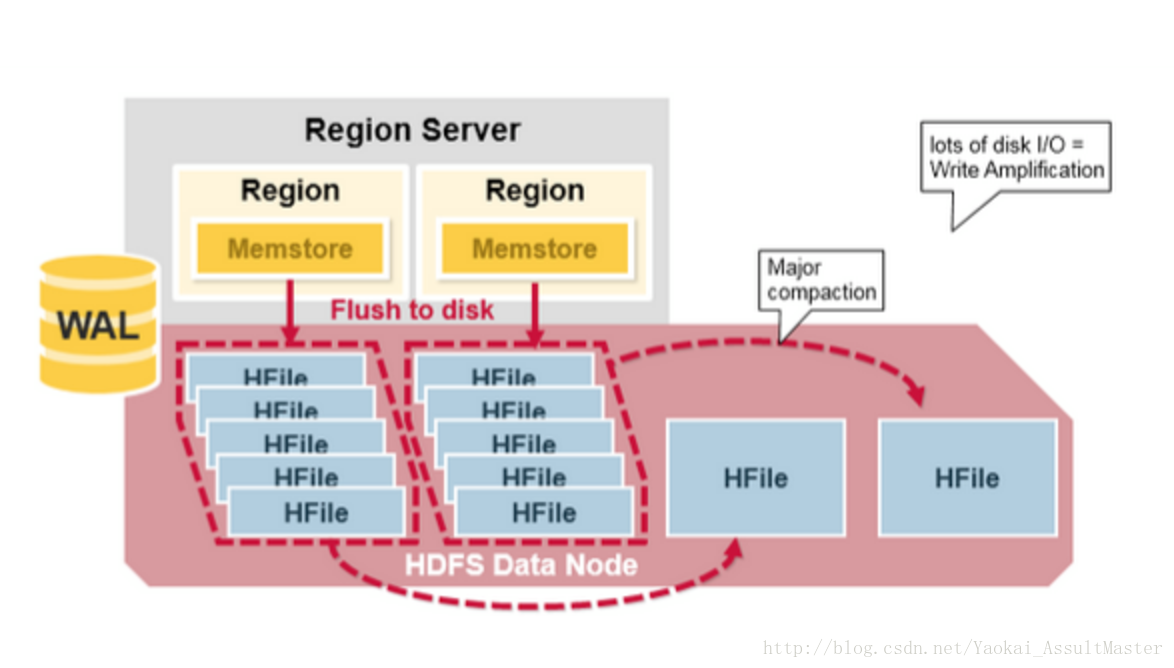
Major Compaction
所謂Major Compaction指的是HBase將對應於某一個Column family的所有HFile重新整理併合併為一個HFile,並在這一過程中刪除已經刪除或過期的cell,更新現有cell的值。這一操作大大提升讀的效率。但是因為Major compaction需要重新整理所有的HFile並寫入一個HFile,這一過程包含大量的硬碟I/O操作以及網路資料通訊。這一過程也稱為寫放大(Write amplification)。在Major compaction進行的過程中,當前Region基本是處於不可訪問的狀態。
Major compaction可以配置在規定的時間自動執行。為避免影響業務,Major compaction一般安排在夜間或週末進行。
需要注意的一點事,Major compaction會將當前Region所服務的所有遠端資料下載到本地Region server上。這些遠端資料可能由於伺服器故障或者負載均衡等原因而儲存在於遠端伺服器上。
這一過程如下圖所示:
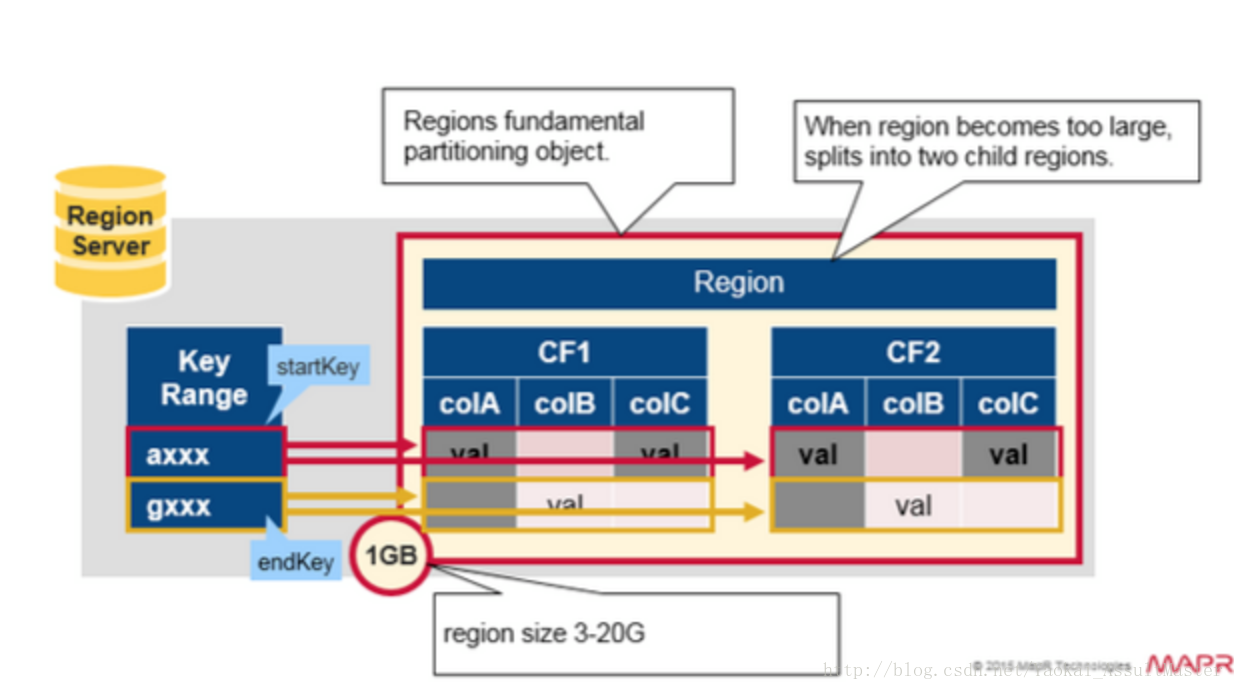
Region的分割(Region split)
首先我們快速複習一下Region:
- HBase中的表格可以根據行鍵水平分割為一個或幾個region。每個region中包含了一段處於某一起始鍵值和終止鍵值之間的連續的行鍵。
- 每一個region的預設大小為1GB。
- 相應的Region server負責向客戶提供訪問某一region中的資料的服務。
- 每一個Region server能夠管理大約1000個region(這些region可能來自同一個表格,也可能來自不同的表格)。
如下圖所示:
每一個表格最初都對應於一個region。隨著region中資料量的增加,region會被分割成兩個子region。每一個子region中儲存原來一半的資料。同時Region server會通知HMaster這一分割。出於負載均衡的原因,HMaster可能會將新產生的region分配給其他的Region server管理(這也就導致了Region server服務遠端資料的情況的產生)。
如下圖所示:
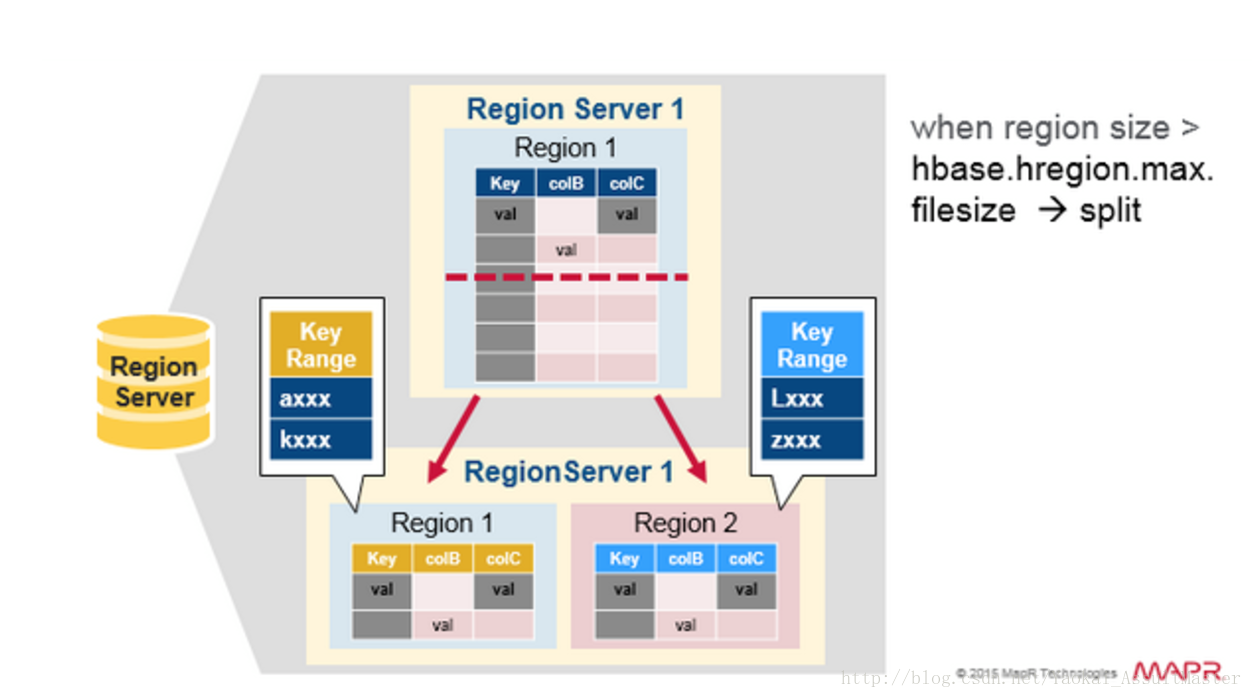
讀操作的負載均衡(Read Load Balancing)
Region的分割最初是在Region server本地發生的。但是出於負載均衡的原因,HMaster可能會將新產生的region分配給其他的Region server進行管理。這也就導致了Region server管理儲存在遠端伺服器上的region情況的產生。這一情況會持續至下一次Major compaction之前。如上文所示,Major compaction會將任何不在本地的資料下載至本地。
也就是說,HBase中的資料在寫入時總是儲存在本地的。但是隨著region的重新分配(由於負載均衡或資料恢復),資料相對於Region server不再一定是本地的。這種情況會在Major compaction後得到解決。
如下圖所示:
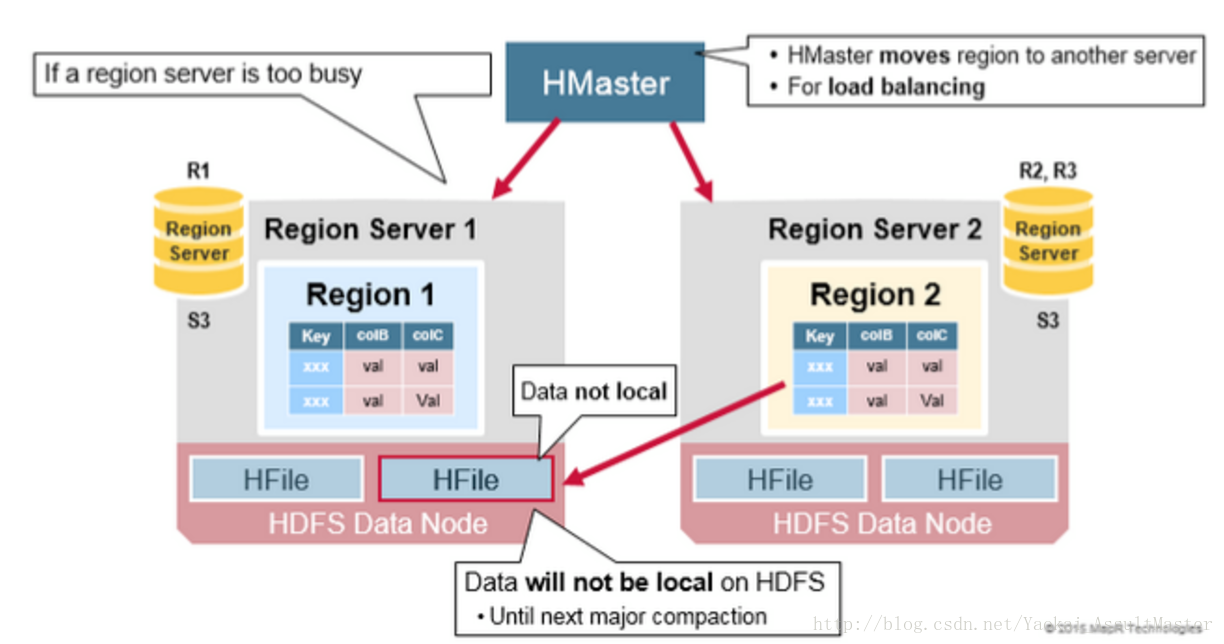
HDFS的資料備份(Data Replication)
HDFS中所有的資料讀寫操作都是針對主節點進行的。HDFS會自動備份WAL和HFile。HBase以來HDFS來提供可靠的安全的資料儲存。當資料被寫入HDFS本地時,另外兩份備份資料會分別儲存在另外兩臺伺服器上。
如下圖所示:
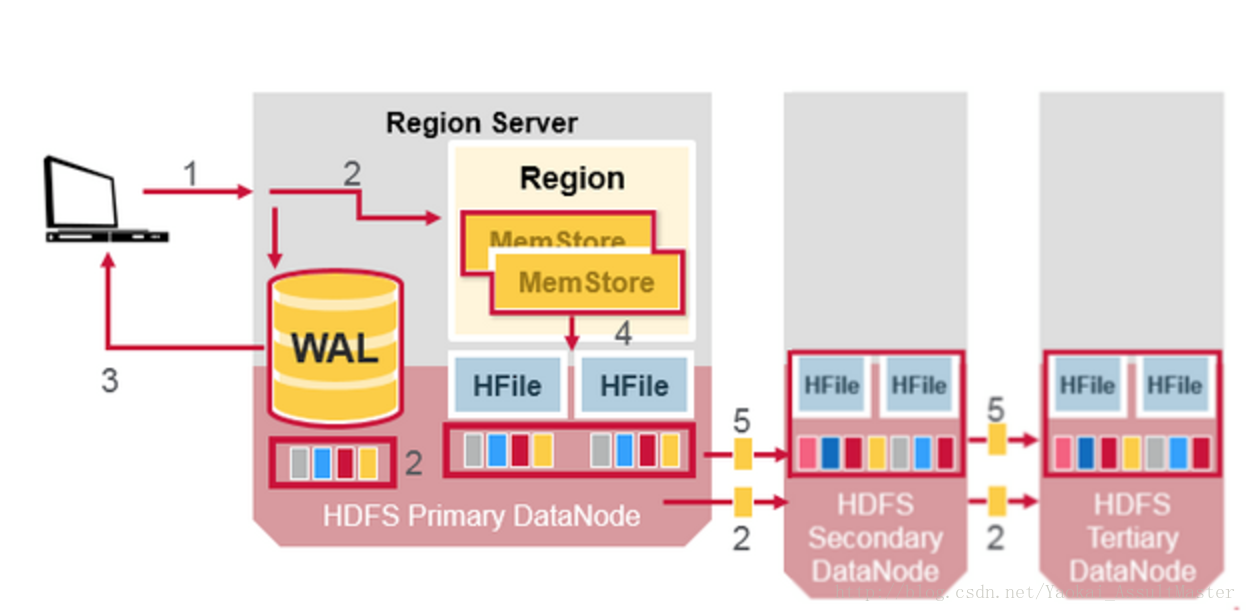
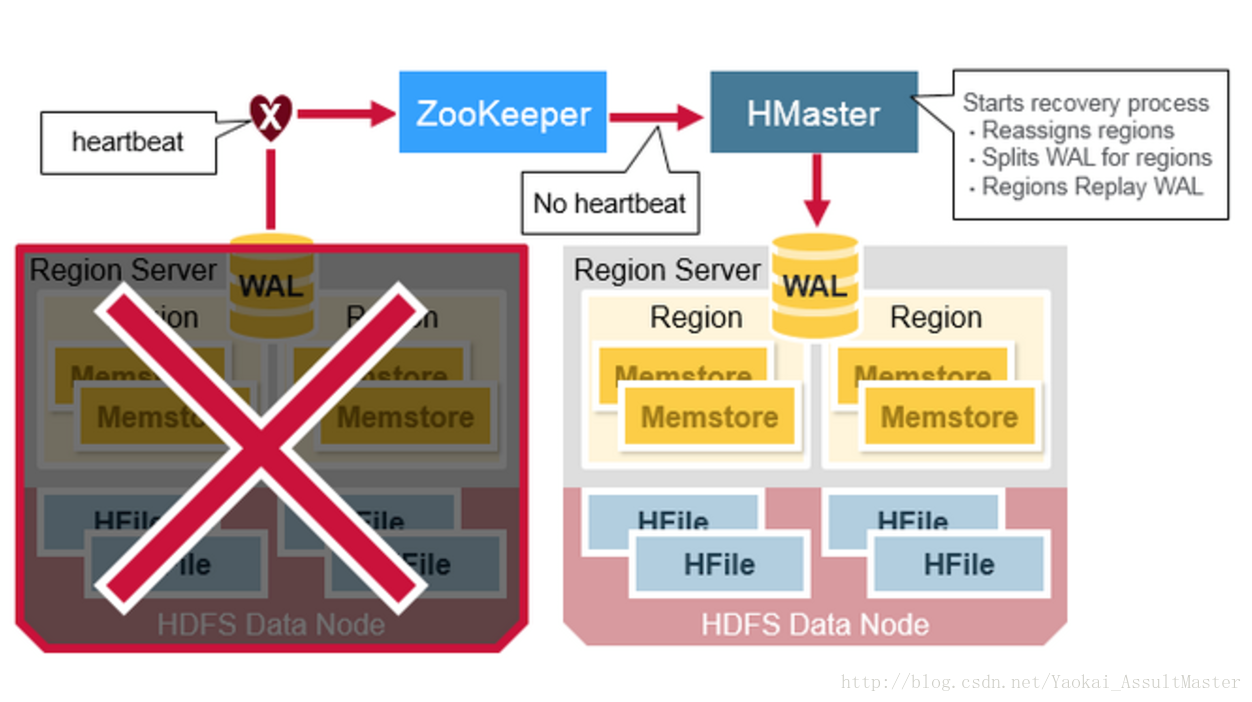
HBase的異常恢復(Crash Recovery)
WAL檔案和HFile都儲存於硬碟上且存在備份,因此恢復它們是非常容易的。那麼HBase如何恢復位於記憶體中的MemStore呢?
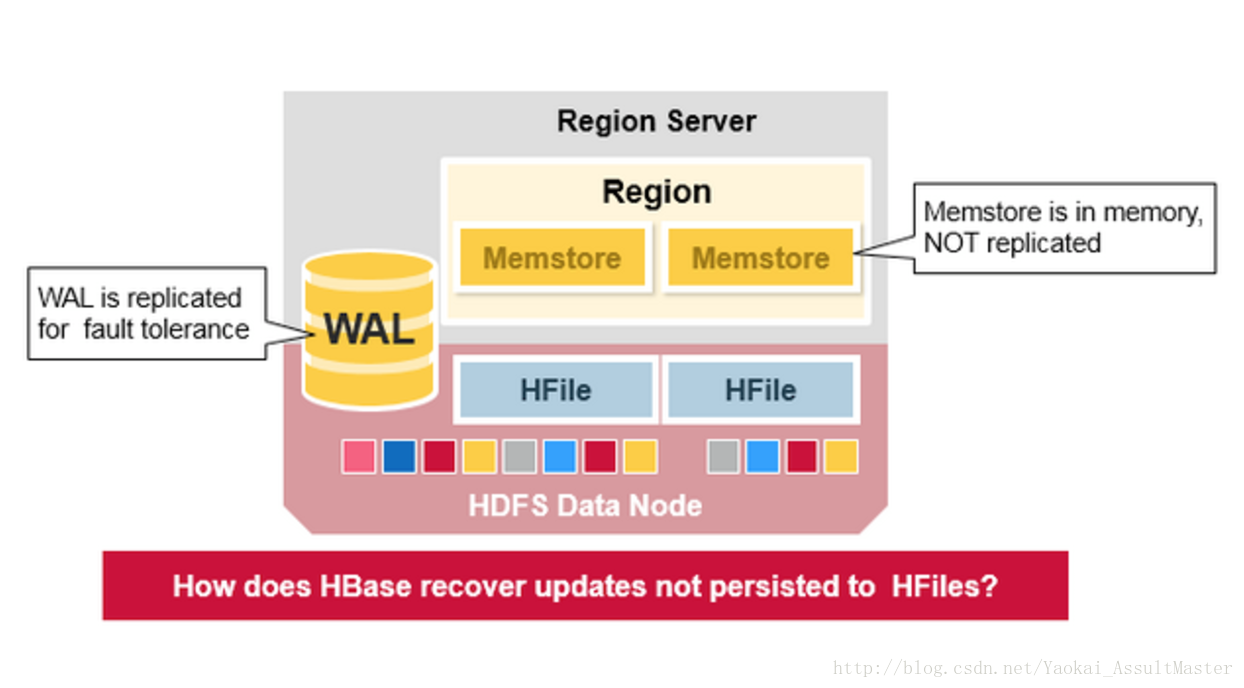
當Region server宕機的時候,其所管理的region在這一故障被發現並修復之前是不可訪問的。ZooKeeper負責根據伺服器的心跳資訊來監控伺服器的工作狀態。當某一伺服器下線之後,ZooKeeper會發送該伺服器下線的通知。HMaster收到這一通知之後會進行恢復操作。
HMaster會首先將宕機的Region server所管理的region分配給其他仍在工作的活躍的Region server。然後HMaster會將該伺服器的WAL分割並分別分配給相應的新分配的Region server進行儲存。新的Region server會讀取並順序執行WAL中的資料操作,從而重新建立相應的MemStore。
如下圖所示:
資料恢復(Data Recovery)
WAL檔案之中儲存了一系列資料操作。每一個操作對應WAL中的一行。新的操作會順序寫在WAL檔案的末尾。
那麼當MemStore中儲存的資料因為某種原因丟失之後應該如何恢復呢?HBase以來WAL對其進行恢復。相應的Region server會順序讀取WAL並執行其中的操作。這些資料被存入記憶體中當前的MemStore並排序。最終當MemStore存滿之後,這些資料被flush到硬碟上。
如下圖所示:
Apache HBase的優缺點
優點
- 強一致性模型
- 當一個寫操作得到確認時,所有的使用者都將讀到同一個值。
- 可靠的自動擴充套件
- 當region中的資料太多時會自動分割。
- 使用HDFS分佈儲存並備份資料。
- 內建的恢復功能
- 使用WAL進行資料恢復。
- 與Hadoop整合良好
- MapReduce在HBase上非常直觀。
缺點
- WAL回覆較慢。
- 異常恢復複雜且低效。
- 需要進行佔用大量資源和大量I/O操作的Major compaction。
相關推薦
深度預警:深入理解HBase的系統架構
HBase的構成 物理上來說,HBase是由三種類型的伺服器以主從模式構成的。這三種伺服器分別是:Region server,HBase HMaster,ZooKeeper。 其中Region server負責資料的讀寫服務。使用者通過溝通Region server來實現對資料的訪問。 HBase
深入理解HBase的系統架構
很好的一篇文章,作者翻譯的真心棒。非常感謝。原文出處:https://blog.csdn.net/Yaokai_AssultMaster/article/details/72877127。請大家尊重原創,如需轉載,請寫明原文出處。謝謝HBase的構成物理上來說,HBase是由
深入理解分散式系統中的快取架構(上)
本文主要介紹大型分散式系統中快取的相關理論,常見的快取元件以及應用場景。 1 快取概述 2 快取的分類 快取主要分為以下四類 2.1 CDN快取 基本介紹 CDN(Content Delivery Network 內容分發網路)的基本原理是廣泛採用
深入理解計算機系統-作業2.10
oid 位置 pla borde 作業2 nbsp body 開始 width 1 void inplace_swap(int *x, int *y){ 2 *y = *x ^ *y;/*step1*/ 3 *x = *x ^ *y;/*step2*/ 4
深入理解計算機系統 第三章大略和第五章大略
$0 一個 編譯 存儲器 系統 32位 做了 ++i 擴展 這2章總結的很少,主要是覺得沒那麽重要。 1.2個操作數的指令,第二個操作數通常是目的操作數:movb a b,move a to b,而add a b,b+=a,指令分為指令類,如mov類:movb,movw,m
電子書 深入理解計算機系統.pdf
大量 內容 ora 其他 hal 科學 本科生 and acm 內容簡介 和第2版相比,本版內容上*大的變化是,從以IA32和x86-64為基礎轉變為完全以x86-64為基礎。主要更新如下: 基於x86-64,大量地重寫代碼,首次介紹對處理浮點數據的程序的機器級支持。
《深入理解計算機系統》Tiny服務器4——epoll類型IO復用版Tiny
[] 用戶數據 nts tin 服務 監視 結束 col 結構 前幾篇博客分別講了基於多進程、select類型的IO復用、poll類型的IO復用以及多線程版本的Tiny服務器模型,並給出了主要的代碼。至於剩下的epoll類型的IO復用版,本來打算草草帶過,畢竟和其他兩種
深入理解計算機系統之虛擬存儲器
fragment 策略 動態鏈接 字段 索引 ~~ cti 錯誤 個數 http://blog.csdn.net/al_xin/article/details/38590931 進程提供給應用程序的關鍵抽象: 一個獨立的邏輯控制流,它提供一個假象,好像我們的程序獨占地
《深入理解計算機系統》關於csapp.h和csapp.c的編譯問題(轉)
系統 文件中 class net 工作 inux 而且 pan div 編譯步驟如下: 1.我的當前工作目錄為/home/sxh2/clinux,目錄下有3個文件inet_aton.c csapp.h csapp.c。 2.編譯csapp.c文件,命令為gcc -c csa
深入理解計算機系統(序章)------談程序員為什麽要懂底層計算機結構
人類 是你 驅動 計算機世界 執行過程 鍵盤 二進制 java虛擬機 調優 萬丈高樓平地起,計算機系統就像程序員金字塔的地基。理解了計算機系統的構造原理,在寫程序的道路上才能越走越遠。道理LZ很早就懂了,可是一直沒下定決心好好鉆研,或許是覺得日常工作中根本用不到這些,又
深入理解計算機系統(1.2)------存儲設備
高速 計算 想法 知識 1-1 運用 文件 字符 設備 上一章我們講解了hello world 程序在計算機系統中是如何運行的。 hello 程序的機器指令最初是存放在磁盤上的,當程序加載時,他們被復制到主存;當處理器運行程序的時候,指令又從主存復制到處理器。相似的,數
3.2《深入理解計算機系統》筆記(二)內存和高速緩存的原理【插圖】
img sram 本質 text ddr rate too 是我 很大的 《深入計算機系統》筆記(一)主要是講解程序的構成、執行和控制。接下來就是運行了。我跳過了“處理器體系結構”和“優化程序性能”,這兩章的筆記繼續往後延遲! 《深入計算機系統》的一個很大的用處
深入理解計算機系統(2.4)------整數的表示(無符號編碼和補碼編碼)
class 映射 們的 c語言 正數 裏的 小例子 負數 類型 上一篇博客我們主要介紹了布爾代數和C語言當中的幾個運算符。那麽這一篇博客我們主要介紹在計算機中整數是如何表示的,諸如我們在編碼過程中遇到的對數據類型進行強制轉換可能會得到意想不到的結果在這篇博客裏你會得到解
深入理解計算機系統(3.1)------匯編語言和機器語言
找到 生產 有著 shu 符號 ces pc機 高效率 機器語言 《深入理解計算機系統》第三章——程序的機器級表示。作者首先講解了匯編代碼和機器代碼的關系,闡述了匯編承上啟下的作用;接著從機器語言IA32著手,分別講述了如何存儲數據、如何訪問數據
深入理解計算機系統(3.3)------操作數指示符和數據傳送指令
邏輯操作 無效 系統 get 訪問 www. 執行 十六 title 在上一篇博客 程序編碼以及數據格式 中我們給出了一個簡單的C程序,然後編譯成了匯編代碼。大家看不懂沒關系,後面的博客我們將逐漸揭開一些匯編指令的神秘面紗。本篇博客我們將對操作數指示符和數據傳送指令進行
深入理解計算機系統(3.8)------數組分配和訪問
2個 說明 add 如果 c++編譯 類型 操作 http 程序 上一篇博客我們講解了匯編語言中過程(函數)的調用實現。理解數據如何在調用者和被調用者之間傳遞,以及在被調用者當中局部變量內存的分配以及釋放是最重要的。那麽這篇博客我們將講解數組的分配和訪問。 1、
速讀《深入理解計算機系統(第三版)》問題及解決
情況 csdn 第六章 填充 以及 函數 順序 時鐘 管理所 第一章 計算機漫遊 P13:用戶棧和運行時堆有什麽區別?數據結構中經常說堆棧,這裏的堆和棧一樣嗎?和操作系統的堆、棧有什麽區別? 參考:堆和棧的區別(內存和數據結構) 操作系統: 棧:由操作系統自動分配釋放
《深入理解計算機系統》速讀提問
64位 概述 經歷 實現 故障 相關 不能 提升 轉換 一、計算機系統漫遊 本章通過運行一個hello程序為例,概述了計算機操作系統的運行過程,講述了組成計算機系統的硬件和系統軟件,講到了處理器處理一個程序的過程。 這一章中出現了一個我首次聽說到的詞匯Amdahl定律,該定
《深入理解計算機系統》第一章學習筆記
文件 傳遞 ati 線性 邏輯 double 動態 內容 起源 信息就是位+上下文 源程序:就是一個由0和1組合的位(bit)序列,8位組成一字(byte),每個字節表示某個文本字符。 系統中所有的信息——包括磁盤文件、存儲器中的程序、存儲器中存放的用戶數據以及網絡上傳送的