
用版本控制工具將資料庫版本化(轉)
原文地址:http://blog.csdn.net/tywo45/article/details/2480078
1、概述
版本化資料庫的起點——建立一個數據庫Schema基線,這個基線是一些資料庫指令碼(包括create table,alter table,drop table,insert data,update data,delete data等)。這些指令碼可以位於同一.sql檔案中,也可根據其它規劃分別位於不同檔案中,例如將檢視指令碼,初始化資料指令碼,建表指令碼分別置於不同的檔案中。
2、版本化資料庫過程
資料庫版本化與程式碼版本化的區別在於資料庫中的生產資料是現場(即使用者)創造的,當我們的表結構發生改變時,不能直接用drop table然後再create table,因為這樣會導致生產資料丟失。而程式碼則完全由開發人員創造,可以用完全覆蓋的方式升級。由於這點不同,致使資料庫在版本化的過程中必然要採用與程式碼不同的方法。
軟體過程有一個過程方法叫迭代過程。對資料庫的版本化,我覺得也可以採用這種類似的方法------後一個版本的指令碼依賴於前一個版本的指令碼,即當你要把資料庫升級到第n個版本時,你必須先把資料庫升級到第(n-1)個版本,以此遞迴。方法很簡單,但實際的過程並不會太順利,設想以下一個場景來描述一些常見的困難和問題。
人力系統在V2.0.14版本時,有一張表叫demo_user,這張表有兩個欄位id和name,在我們進行V2.0.16版本的開發時,使用者提出了要有cn_name(中文名)資訊,並且這個資訊不允許為空,如果為空,則必須用“無中文名”顯示。這是個很簡單的需求,我們只需要在demo_user表中新增一個cn_name欄位即可------alter table demo_user add cn_name varchar2(64) not null;這個看似沒有錯誤的語句,實際上是行不通的-----因為現場的這張表是有資料的,我們執行這條語句時會報下圖所示的錯誤。
有經驗的程式設計師可能想到了解決方法------將本來一條可以搞定的SQL分成三條,分別為:
alter table demo_user add cn_name varchar2(64) null; update demo_user set cn_name = '無中文名'; alter table demo_user modify cn_name varchar2(64) not null;
再設想,在V2.0.16版本時,日本有家公司要用我們公司的人力系統,我們的資料庫如何直接從無到V2.0.16版本?
很容易想到的一個方法是利用遞迴法,從第一個版本的指令碼開始跑,一直跑到V2.0.16。如果我們中間經歷了1000個版本,那就跑1000遍吧。實施的要哭了!面對重複性勞動時,人們都會抽象出一種比較好的方法來處理,就像設計模式中的狀態模式代替無窮的if else語句一樣,我們用各版本的全量指令碼來代替增量指令碼。這話不太好懂,以上面場景的demo_user表為例來說明一下吧。
以增量指令碼的形式,我們會有三條SQL:
alter table demo_user add cn_name varchar2(64) null; update demo_user set cn_name = '無中文名'; alter table demo_user modify cn_name varchar2(64) not null;
但以全量指令碼的形式,我們只有一條SQL:
create table demo_user ( ID VARCHAR2(18) not null, NAME VARCHAR2(60) not null, CN_NAME VARCHAR2(64) not null );
看到上面的全量和增量,有何感想?是不是覺得全量指令碼只能用於新增局點,而已有局點,只能用增量指令碼?是的,全量指令碼就是給新增局點用的,但是目前,我覺得我們還不需要提供全量指令碼------原因是,維護全量指令碼給我們帶來的實惠要遠遠少於我們的付出。
再設想一個場景,日本局點不需要cn_name,他需要的是jp_name(日本名字)--------都說日本人bt,不過這個需求一點也不bt。如何做到呢?… …不累贅了,直接地說吧,此場景說明了,我們的指令碼需要做到差異化控制,所以差異化控制功能必須納入到控制範圍,至於如何做到差異化控制?接著看吧!
以上說得哆嗦了點,下面說說我們將資料庫版本化後,在VSS(或其它版本控制軟體工具)下的目錄結構吧!見下圖,相信圖來得夠直接了,俺就不哆嗦了:
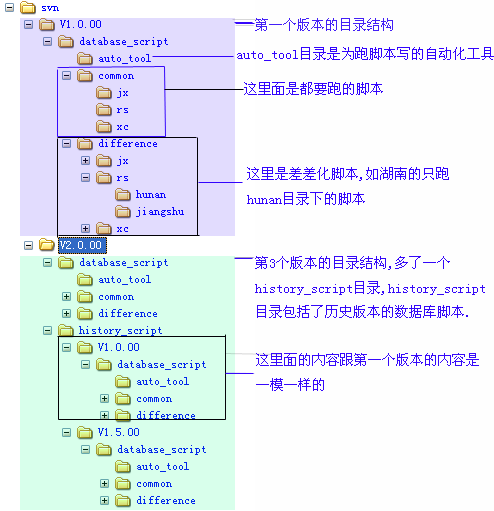
圖2.1
3、問題列表
以專案的實際情況舉例,其實各種情況都可以泛化的 1,是否需要建一個oracle和sybase目錄,以區分對待主業和實業。 答:這是個偽問題。我們同一個版本只會發往主業或實業中的一個,所以不存在用oracle和sybase這樣的目錄來區分。如果實業的改動和主業的改動一樣,那麼就分別在主業版本和實業版本都加上相應的指令碼。 2,開發要做哪些事?QA要做哪些事?實施要做哪些事? 答: 開發要做的: 1、提供資料庫指令碼,包括共用指令碼和差異化指令碼 2、寫好rs_build.sql QA要做的: 1、釋出新版本時,需要將上一版本的指令碼複製到新版本的歷史指令碼中一併釋出(參見圖2.1)。 實施要做的: 1、修改rs_execute_sql.bat指令碼(就是將使用者名稱、密碼和資料庫名修改成相應的就可以了) 2、雙擊execute.bat以執行指令碼 3、從.log檔案中檢查是否有錯,如果發現錯誤,及時和開發人員溝通,然後由開發人員處理異常情況。4、資料庫版本管理產品
- SQL Source Control
- DBV資料庫版本管理工具
- Flyway
- dbdeploy
- liquibase
5、後記
資料庫版本化看似是個可有可無的過程,但做好了,可以減少開發和實施的許多事情,我們的系統就是個活生生的例子。之前在newland公司的時候,開發部門也沒有資料庫指令碼控制,上個月聽說那個部門已經接近解散了。本文所闡述的方法是來自以前在ht時的經驗做法,但根據以前的一些問題作了些許改進。軟體公司的發展都會經歷從幼稚到成熟,借鑑其它公司的成功經驗,提前認識並解決問題可減少損失。
相關推薦
用版本控制工具將資料庫版本化(轉)
原文地址:http://blog.csdn.net/tywo45/article/details/2480078 1、概述 版本化資料庫的起點——建立一個數據庫Schema基線,這個基線是一些資料庫指令碼(包括create table,alter table,drop table,insert data,
Docker最全教程——資料庫容器化(十)
終於按時完成第二篇。本來準備著手講一些實踐,但是資料庫部分沒有講到,部分實踐會存在一些問題,於是就有了此篇以及後續——資料庫容器化。本篇將從SQL Server容器化實踐開始,並逐步講解其他資料庫的容器化實踐,中間再穿插一些知識點和實踐細節。在編寫的過程中,我一直處於一種矛盾的心理,是一筆帶過呢?還是儘可能的
Hibernate執行原生sql時,將資料庫的char(n)型別轉換成了character型別的解決方案
在使用Hibernate的原生態SQL對Oracle進行查詢時,碰到查詢char型別的時候始終返回的是一個字元,開始認為應該是Hibernate在做對映的把資料型別給對映成char(1),在經過查詢網上的一些資料,得知產生這個問題的主要原因確實是Hibernate再查詢Or
FCN用卷積層代替FC層原因(轉)
alex spa 內容 pool 計算 lex 級別 conv2 本質 分類任務 CNN對於常見的分類任務,基本是一個魯棒且有效的方法。例如,做物體分類的話,入門級別的做法就是利用caffe提供的alexnet的模型,然後把輸出的全連接層稍稍修改稱為自己想要的類別數,然後再
變量的聲明、定義、初始化(轉)
局部變量 聲明和定義 包含 int 外部變量 存儲 變量聲明 bsp 運行 先分享一下關於變量聲明和定義的區別: 變量的聲明有兩種情況: (1) 一種是需要建立存儲空間的(定義、聲明)。例如:int a在聲明的時候就已經建立了存儲空間。 (2) 另一種是不需要
用 LVS 搭建一個負載均衡集群(轉)
always iptable sina watch 通過 main test 集群服務器 負載 http://blog.jobbole.com/87503/ 第一篇:《如何生成每秒百萬級別的 HTTP 請求?》 第二篇:《為最佳性能調優 Nginx》 第三篇:《用 L
使用java8的lambda將list轉為map(轉)
實體 nts acc UNC illegal identity 簡潔 tps username 常用方式 代碼如下: public Map<Long, String> getIdNameMap(List<Account> accounts)
java IoC(控制反轉) 通俗易懂的解釋(轉)
IoC(控制反轉) 首先想說說IoC(Inversion of Control,控制反轉)。這是spring的核心,貫穿始終。所謂IoC,對於spring框架來說,就是由spring來負責控制物件的生命週期和物件間的關係。這是什麼意思呢,舉個簡單的例子,我們是如何找女朋友的?常見的情況是,我
session的活化與鈍化 (轉)
session的活化與鈍化就是當用戶訪問時網站異常,不能丟掉session,所有也必須採用檔案儲存;和之前那個統計網站訪問量一樣的原理。 class Person implements必須實現這兩個介面,實現session活化和鈍化的要求 活化:從硬碟上讀取到記憶體中
資料庫三正規化(轉)
轉自:資料庫設計三大正規化 資料庫設計正規化 什麼是正規化:簡言之就是,資料庫設計對資料的儲存效能,還有開發人員對資料的操作都有莫大的關係。所以建立科學的,規範的的資料庫是需要滿足一些 規範的來優化資料資料儲存方式。在關係型資料庫中這些規範就可以稱為正規化。 什麼是三大正規化: 第一正規化:當關系模
用Vultr自己搭建ss/ssr伺服器教程(轉)
第一次電腦系統使用SSR / SS客戶端時,需要安裝.NET Framework 4.0,不然無法正常使用,微軟官網下載 .NET Framework 4.0是SSR / SS的執行庫,沒有這個SSR / SS客戶端無法正常執行。有的電腦系統可能會自帶.NET
無線網絡中,使用MDK3把指定的用戶或者熱點踢到掉線(轉)
欺騙 超過 bsp 信息 code www 參數 參考 wifi熱點 閱讀目錄 準備 驗證洪水攻擊 / Authentication Flood Attack 取消身份驗證攻擊 / Deauth攻擊 參考 回到頂部 準備 1:系統環境為ubu
使用pandas模組從資料庫讀取資料(轉)
轉自:http://www.tuicool.com/articles/ZVzEz2N Python中用Pandas進行資料分析,最常用的就是Dataframe資料結構,之前寫過一篇文章介紹Pandas的基本用法,後來有些朋友問Pandas怎麼從資料庫中讀取資料,怎麼從檔
簡單好用的sshfs -- 通過ssh對映遠端路徑(轉)
最近習慣性訪問N個Linux機器,在不同機器間跳來跳去,很是麻煩,最終,找到了sshfs,可以把遠端目錄直接對映到本地,無需修改遠端機器的設定,僅要求有ssh連線的許可權(ssh都沒有的話,還能幹啥?!~!) 安裝: #如果是ubuntu apt-get install sshfs #如果是Fed
資料庫事務管理(轉)
概述 不管你直接採用JDBC進行資料庫事務操作,還是使用基於Spring或EJB的宣告式事務功能進行事務管理,它們最終都是使用底層資料庫的事務管理功能 完成最終任務的。資料庫事務擁有許多語義概念,它們是你進行事務程式設計和事務管理的基礎,只有掌握好資料庫事務的基礎知識
用CMake建立動態庫和靜態庫(轉)
五,靜態庫與動態庫構建 讀者雲,太能羅唆了,一個Hello World就折騰了兩個大節。OK,從本節開始,我們不再折騰Hello World了,我們來折騰Hello World的共享庫。 本節的任務:1,建立一個靜態庫和動態庫,提供HelloFunc函式供其他程式程式設計使用
shelve -- 用來持久化任意的Python對象(轉)
src 缺省 alt 開始 log 因此 每一個 gpo plain 這幾天接觸了Python中的shelve這個module,感覺比pickle用起來更簡單一些,它也是一個用來持久化(序列化)Python對象的簡單工具。當我們寫程序的時候如果不想用關系數據庫那麽重量級的東
資料庫日期處理(轉)
通常,你需要獲得當前日期和計算一些其他的日期,例如,你的程式可能需要判斷一個月的第一天或者最後一天。你們大部分人大概都知道怎樣把日期進行分割(年、月、日等),然後僅僅用分割出來的年、月、日等放在幾個函式中計算出自己所需要的日期!在這篇文章裡,我將告訴你如何使用DATEADD和DATEDIFF函式來計算出在你的
基於GitLab與Git Extensions搭建版本控制工具
基本 cmd img html nat 需求 無法 spa hang 1.背景 大家知道GitHub是現在非常流行的代碼托管工具,但是如果有些項目不想開源的話,則需要付費,因此萌生了自己搭建一個Git的版本控制工具,供內網使用。GitLab則是個好的選擇,但是GitL
Git分布式版本控制工具
繼續 新建 執行 是把 -h png 版本號 工作 直接 一、安裝Git 1、下載Windows版的Git:msysgit;官方下載地址:http://msysgit.github.io,安裝選定要安裝的目錄(路徑杜絕中文),剩下的按照默認安裝即可,參考:GIt安裝教