
MongoDB分片(sharding)/分割槽(partitioning)介紹
分片簡介
分片是指將資料拆分,將其分散存放在不同的機器上的過程。有時也用分割槽(partitioning)來表示這個概念。
幾乎所有資料庫軟體都能進行手動分片(manual sharding)。應用需要維護與若干不同資料庫伺服器的連線,每個連線還是完全獨立的。應用程式管理不同伺服器上不同資料的儲存,還管理在合適的資料庫上查詢資料的工作。
Mongodb支援自動分片(autosharding),可以使資料庫架構對應用程式不可見,也可以簡化系統管理。Mongodb自動處理資料在分片上的分佈,也更容易新增和刪除分片。
理解叢集的元件
Mongodb的分片機制允許你建立一個包含許多臺機器(分片)的叢集。將資料子集分散在叢集中,每個分片維護著一個數據集合的子集。與單個伺服器和副本集相比,使用叢集架構可以使應用程式具有更大的資料處理能力。
複製是讓多臺伺服器都擁有同樣的資料副本,每一臺伺服器都是其它伺服器的映象,而每一個分片和其它分片擁有不同的資料子集。
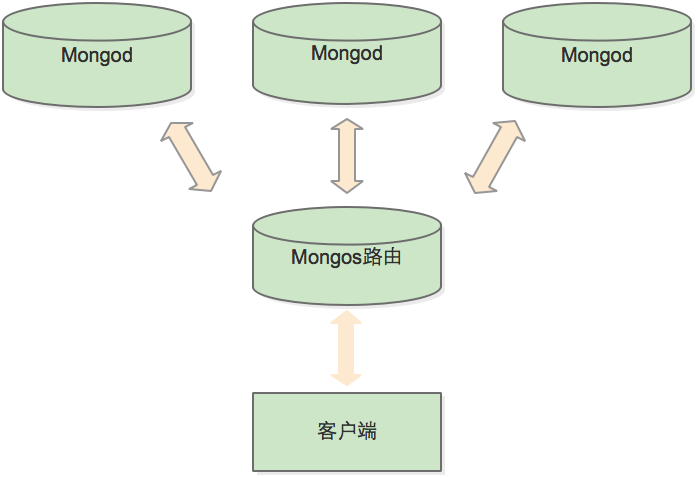
為了對應用程式隱藏資料庫架構的細節,在分片之前要先執行mongos進行一次路由過程。這個路由伺服器維護著一個“內容列表”,指明瞭每個分片包含什麼資料內容。應用程式只需要連線到路由伺服器,就可以像使用單機伺服器一樣進行正常的請求了。路由伺服器知道哪些資料位於哪個分片,可以將請求轉發給相應的分片。每個分片對請求的響應都會發送給路由伺服器,路由伺服器將所有響應合併在一起,返回給應用程式。對應用程式來說,它只知道自己是連線到了一臺單機mongod伺服器。
使用分片的連線:
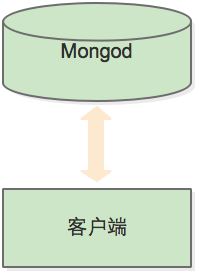
不使用分片連線
快速建立一個簡單的叢集
在單臺伺服器上快速建立一個叢集。首先,使用--nodb選項啟動mongo shell:
$mongo --nodb使用ShardingTest類建立叢集:
>cluster = new ShardingTest({"shards" : 3 , "chunksize" : 1})執行這個命令會建立一個包含3個分片(mongod程序)的叢集。分別執行在30000,30001,30002埠。預設情況下,ShardingTest會在30999埠啟動mongos。接下來就連線到這個mongos開始使用叢集。
叢集會將日誌輸出到當前shell中,所以再開啟一個shell用來連線到叢集的mongos:
>db = (new Mongo("localhost:30999")).getDB("test")現在的情況如“使用分片的連線”所示,客戶端(shell)連線到了一個mongos。現在就可以將請求傳送給mongos了,它會自動將請求路由到合適的分片。客戶端不需要知道分片的任何資訊,比如分片數量和分片地址。只要有分片存在,就可以向mongos傳送請求,它會自動將請求轉發到合適的分片上。
首先插入一些資料:
>for(var i=0;i<100000;i++){
db.users.insert({"username" : "user"+i , "created_at" : new Date()});
}
>db.users.count()
100000可以看到,與mongos進行互動與使用單機伺服器完全一樣,如上圖“不使用分片的連線”。
執行sh.status()可以看到叢集的狀態:分片摘要資訊、資料庫摘要資訊、集合摘要資訊:
>sh.status()
...Sharding Status...
sharding version : {"_id" : 1 , "version" : 3}
shards :
{"_id" : "shard0000" , "host" : "localhost : 30000"}
{"_id" : "shard0001" , "host" : "localhost : 30001"}
{"_id" : "shard0002" , "host" : "localhost : 30002"}
databases:
{"_id" : "admin" , "partitioned" : false , "primary" : "config" }
{"_id" : "test" , "partitioned" : false , "primary" : "shard0001" }sh命令與rs命令很像,除了它是用於分片的:rs是一個全域性變數,其中定義了許多分片操作的輔助函式。可以執行sh.help()檢視可以使用的輔助函式。如sh.status()的輸出所示,當前擁有3個分片,2個數據庫(其中admin資料庫是自動建立的)。
與上面sh.status()的輸出資訊不同,test資料庫可能有一個不同的主分片(primary shard)。主分片是為每個資料庫隨機選擇的,所有資料都會位於主分片上。MongoDB現在還不能自動將資料分發到不同的分片上,因為它不知道你希望如何分發資料。必須要明確指定,對於每一個集合,應該如何分發資料。
主分片與副本集中的主節點不同。主分片指的是組成分片的整個副本集。而副本集中的主節點是指副本集中能夠處理寫請求的單臺伺服器。
要對一個集合分片,首先要對這個集合的資料庫啟用分片,執行如下命令:
>sh.enableSharding("test")現在就可以對test資料庫內的集合進行分片了。
對集合分片時,要選擇一個片鍵(shard key)。片鍵是集合的一個鍵,MongoDB根據這個鍵拆分資料。例如,如果選擇基於“username”進行分片,MongoDB會根據不同的使用者名稱進行分片。選擇片鍵可以認為是選擇集合中資料的順序。它與索引是個相似的概念:隨著集合的不斷增長,片鍵就會成為集合上最重要的索引。只有被索引過的鍵才能夠作為片鍵。
在啟用分片之前,先在希望作為片鍵的鍵上建立索引:
>db.users.ensureIndex({"username" : 1})現在就可以依據“username”對集合分片了:
>sh.shardCollection(“test.users” , "username" : 1)幾分鐘之後,再次執行sh.status(),可以看到,這次的輸出資訊比較多:
...Sharding Status...
sharding version : {"_id" : 1 , "version" : 3}
shards :
{“_id” : "shard0000" , "host" : "localhost : 30000"}
{“_id” : "shard0001" , "host" : "localhost : 30001"}
{“_id” : "shard0002" , "host" : "localhost : 30002"}
databases:
{"_id" : "admin" , "partitioned" : false , "primary" : "cofig"}
{"_id" : "test" , "partitioned" : true , "primary" : "shard0000"}
test.users chunks:
shard0001 4
shard0002 4
shard0000 5
{"username" : {$minkey : 1}} -->> {"username" : "user1704"}
on : shard0001
{"username" : "user1704"} -->> {"username" : "user24083"}
on : shard0002
{"username" : "user24083"} -->> {"username" : "user31126"}
on : shard0001
{"username" : "user31126"} -->> {"username" : "user38170"}
on : shard0002
{"username" : "user38170"} -->> {"username" : "user45213"}
on : shard0001
{"username" : "user45213"} -->> {"username" : "user52257"}
on : shard0002
{"username" : "user52257"} -->> {"username" : "user59300"}
on : shard0001
{"username" : "user59300"} -->> {"username" : "user66344"}
on : shard0002
{"username" : "user66344"} -->> {"username" : "user73388"}
on : shard0000
{"username" : "user73388"} -->> {"username" : "user80430"}
on : shard0000
{"username" : "user80430"} -->> {"username" : "user87475"}
on : shard0000
{"username" : ”user87475“} -->> {"username" : "user94518"}
on : shard0000
{"username" : "user94518"} -->> {"username" : {$maxkey : 1}}集合被分成了多個數據塊,每一個數據塊都是集合的一個數據子集。這些是按照片鍵的範圍排列的({”username“ :minvalue} -->>{"username" : maxvalue}指出了每個資料塊的資料範圍)。通過檢視輸出資訊中的"on" : shard部分,可以發現集合資料比較均勻地分佈在不同分片上。
在分片之前,集合實際上是一個單一的資料塊。分片依據片鍵將集合拆分為多個數據塊,這塊資料塊被分佈在叢集中的每個分片上:
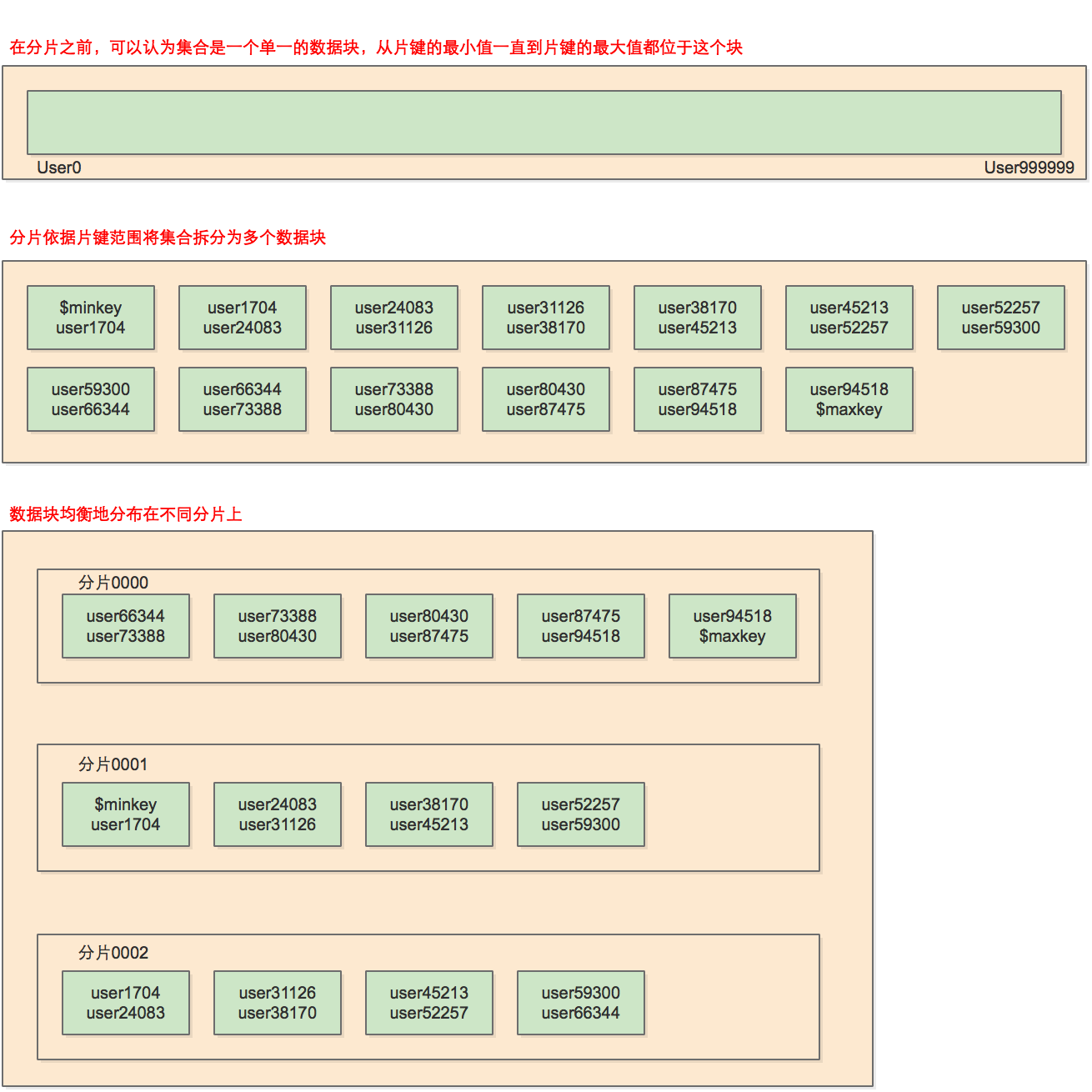
注意,資料塊列表開始的鍵值和結束的鍵值:$minkey和$maxkey。可以將$minkey認為是”負無窮“,它比MongoDB中的任何值都要小。類似地,可以將$maxkey認為是”正無窮“,它比MongoDB中的任何值都要大。片鍵值的範圍始終位於$minkey和$maxkey之間。這些值實際上是BSON型別。只是用於內部使用,不應該被用在應用程式中。如果希望在shell中使用的話,可以用Minkey和Maxkey常量代替。
現在資料已經分佈在多個分片上了,接下來做一個查詢操作。首先,做一個基於指定的使用者名稱的查詢:
>db.users.find({username : "user12345"})
{
"_id" : ObjectId("50b0451951d30ac5782499e6"),
"username" : "user12345",
"created_at" : ISODate("2012-11-24T03:55:05.636Z")
}可以看到查詢可以正常工作,現在執行explain()來看看MongoDB到底是如何處理這次查詢的:
>db.users.find(username : "user12345").explain()
{
"clusteredType" : "ParallelSort",
"shards" : {
"localhost : 30001" : [{
"cursor" : "BtreeCursor username_1",
"nscanned" : 1,
"nscannedObjects" : 1,
"n" : 1,
"millis" : 0,
"nYields" : 0,
"nChunkSkips" : 0,
"isMultiKey" : false,
"indexOnly" : false,
"indexBounds" : {
"username" : [[
"user12345",
"user12345"
]
]
}
}]
},
"n" : 1,
"nChunkSkips" : 0,
"nYields" : 0,
"nscanned" : 1,
"nscannedObjects" : 1,
"millisTotal" : 0,
"millsAvg" : 0,
"numQueries" : 1,
"numShards" : 1
}由於”username“是片鍵,所以mongos能夠直接將查詢傳送到正確的分片上。作為對比,來看一下查詢所有資料的過程:
>db.users.find().explain()
{
"clusteredType" : "ParallelSort",
"shards" : {
"localhost : 30000" : [{
"cursor" : "BasicCursor",
"nscanned" : 37393,
"nscannedObjects" : 37393,
"n" : 37393,
"millis" : 38,
"nYields" : 0,
"nChunkSkips" : 0,
"isMultiKey" : false,
"indexOnly" : false,
"indexBounds" : {
}
}],
"localhost : 30001" : [{
"cursor" : "BasicCursor",
"nscanned" : 31303,
"nscannedObjects" : 31303,
"n" : 31303,
"millis" : 37,
"nYields" : 0,
"nChunkSkips" : 0,
"isMultiKey" : false,
"indexOnly" : false,
"indexBounds" : {
}
}],
"localhost : 30002" : [{
"cursor" : "BasicCursor",
"nscanned" : 31304,
"nscannedObjects" : 31304,
"n" : 31304,
"millis" : 36,
"nYields" : 0,
"nChunkSkips" : 0,
"isMultiKey" : false,
"indexOnly" : false,
"indexBounds" : {
}
}]
},
"n" : 100000,
"nChunkSkips" : 0,
"nYields" : 0,
"nscanned" : 100000,
"nscannedObjects" : 100000,
"millisTotal" : 111,
"millsAvg" : 37,
"numQueries" : 3,
"numShards" : 3
}
執行cluster.stop()就可以關閉整個叢集了。
>cluster.stop()相關推薦
MongoDB分片(sharding)/分割槽(partitioning)介紹
分片簡介 分片是指將資料拆分,將其分散存放在不同的機器上的過程。有時也用分割槽(partitioning)來表示這個概念。 幾乎所有資料庫軟體都能進行手動分片(manual sharding)。應用需要維護與若干不同資料庫伺服器的連線,每個連線還是完全獨立的。應用程
Linux中磁碟的管理(格式化,分割槽,掛載)
今天主要跟大家分享一下有關linux中磁碟管理方面的知識,在這之前先跟大家普及一下磁碟的基礎概念: 一.磁碟的概念: 磁碟:計算機的外部儲存器裝置,是一種利用電流的磁效應為工作原
windows10+ubuntu 16.04+雙硬碟(SSD+HDD)分割槽(圖文)
有一種需求是雙系統雙硬碟(win10+linux,ssd+hdd),那麼處理好兩個系統之間的關係和充分發揮ssd的功效則非常重要,網上查了很多資料,發現雙硬碟雙系統方面的資料相對比較少,所以本文會詳細講清楚如何在ssd+hdd硬碟上搭建linux(ubuntu)
mycat分片規則之分片枚舉(sharding-by-intinfile)
別人 ade 員工信息 cat oracle server register 正常 cor 剛開始看教程資料的時候,看教程文檔感覺模糊,完全沒明白分片枚舉是個什麽樣的概念。於是網上搜素別人做的 案例來看,終於讓我搜索到一份完整的測試案例,見如下地址: https://w
MongoDB分片群集(實現分片服務啟用、分片服務管理、單點故障模擬)
Opens 取數 page use chmod 組成 壓力 多個 clu MongoDB分片概述 1、什麽是分片 高數據量和吞吐量的數據庫應用會對單機的性能造成較大壓力,大的查詢量會將單機的CPU耗盡,大的數據量對單機的存儲壓力較大,最終會耗盡系統的內存而將壓力轉移到磁盤
MongoDB分片群集的部署(用心描述,詳細易懂)!!
tomat prim 提高自己 ati 客戶端 sys 存儲 stat 配置 概念: MongoDB分片是使用多個服務器存儲數據的方法,以支持巨大的數據存儲和對數據進行存儲 優勢: 1、減少了每個分片需啊喲處理的請求數,群集可以提高自己的存儲容量和吞吐量 2、減少了每個分片
分片技術(sharding)——區塊鏈擴容問題的良方
任何一個曾經開發過DApp的程式設計師都必須考慮到當前公共區塊鏈的侷限性,其中區塊鏈侷限性的最重要和最明顯的問題就是有限的吞吐量,比如,每秒處理的交易量過少。為了執行一個能夠處理實際吞吐量需求的DApp,區塊鏈就必須具有可擴充套件性。 進行區塊鏈擴容的一個答案就是分片技
MongoDB 分片管理(不定時更新)
背景: 通過上一篇的 MongoDB 分片的原理、搭建、應用 大致瞭解了MongoDB分片的安裝和一些基本的使用情況,現在來說明下如何管理和優化MongoDB分片的使用。 知識點: 1) 分片的配置和檢視 ① 新增分片:sh.addShard("IP:
分片技術(Sharding):化整為零,分而治之
目前的區塊練技術面臨著一個巨大的瓶頸,那就是:如何有效地提升區塊的吞吐量(TPS)。 區塊鏈的擴充套件性一直是大多數公鏈發展過程中難以避開的一塊攔路石,比特幣因之有一段長達三年的擴容之爭,以太坊一度因為一個小小的密碼貓遊戲而長時間擁堵不堪。 目前提出的問題解決思路
PostgreSQL分割槽表(Table Partitioning)應用
一、簡介 在資料庫日漸龐大的今天,為了方便對資料庫資料的管理,比如按時間,按地區去統計一些資料時,基數過於龐大,多有不便。很多商業資料庫都提供分割槽的概念,按不同的維度去存放資料,便於後期的管理,PostgreSQL也不例外。 PostgresSQ
資料庫分片(Sharding)技術
假如您有一個應用程式,隨著業務越來越有起色,系統所牽涉到的資料量也就越來越大,此時您要涉及到對系統進行伸縮(Scale)的問題了。 一種典型的擴充套件方法叫做“向上伸縮(Scale Up)”,它的意思是通過使用更好的硬體來提高系統的效能引數。 而另一種方法則叫做“向外伸縮(Scale O
應用Mongoose開發MongoDB(2)模型(models)
length 輸出 ror highlight unit required opts nbsp 在一起 數據模型及基礎操作模板 為了使工程結構清晰,將數據模型(Schema, Model)的建立與增刪查改的基礎操作模板寫在一起,命名為數據庫設計中的Collection(
應用Mongoose開發MongoDB(3)控制器(controllers)
條目 選擇 mongoose 電腦 java 組合 將在 light sta 控制器的基本構成與如何通過路由調用 控制器中通過建立函數並導出,實現前端對數據庫的查詢、新建、刪除與修改的需求,並使之可以在路由中調用,完成API的封裝。本文著重於結構之間的關系,具體問題解決
MongoDB執行計劃分析詳解(1)
mongo smu pre als comm 計劃 -- {} direct 正文 queryPlanner queryPlanner是現版本explain的默認模式,queryPlanner模式下並不會去真正進行query語句查詢,而是針對query語句進行執行計劃分析並
mongodb副本集的內部機制(借鑒lanceyan.com)
proc 導致 功能 來看 href 開始 既然 不想 for 針對mongodb的內部機制提出以下幾個引導性的問題: 副本集故障轉移,主節點是如何選舉的?能否手動幹涉下架某一臺主節點。 官方說副本集數量最好是奇數,為什麽? mongodb副本集是如何同步的?如果同步不及
MongoDB 線上環境按照及配置(授權方式啟動)
users inux 相對 mongos emd 刪除數據 ocl conf get 1創建文件repo文件 #vim /etc/yum.repos.d/mongodb-org-3.4.repo [mongodb-org-3.4] name=MongoDB Reposito
MongoDB的數據類型(四)
expr lpad time rip mar serialize 類型轉換 fun oat JSON JSON是一種簡單的數據表示方式,它易於理解、易於解析、易於記憶。但從另一方面來說,因為只有null、布爾、數字、字符串、數組和對象這幾種數據類型,所以JSON有一
Mongodb同步數據到hive(二)
數據 rod review nohup dir 查看 type 數據查詢 腳本 Mongodb同步數據到hive(二) 1、 概述 上一篇文章主要介紹了mongodb-based,通過直連mongodb的方式進行數據映射來進行數據查詢,但是那種方式會對
MongoDB集群搭建教程收集(待實踐)
https build blank detail com -1 const mongodb集群 收集 先收集,後續再實踐。 MongoDB的集群應該和MySQL的定位保持一致,因為要認為它就是一個數據庫。 集群方式有也是有很多,比如分庫,分片,主從,主主等等。 下面是
mongodb的基本概念 學習筆記(二)
不能 所有 訪問 數據庫 理解 基本上 其他 mongodb 連接 mongodb的基本概念1.文檔1.1定義:文檔是mongodb的核心概念。多個鍵及其關聯的值有序地放 置在一起便是文檔。 文檔可以理解為關系數據庫總的一行數據。1.2表示方法:{"greeting":"h