
CUDA學習之CUDA本質和原理-CUDA技術深入解析
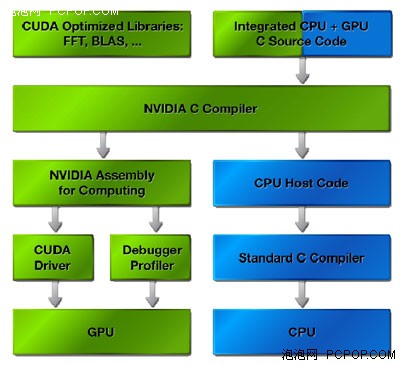
從NVIDIA官方網站上找的CUDA資料可以看出CUDA的實現流程如下圖:

CUDA的實現流程
從圖上我們可以看出CUDA在整個GPU計算中充當的就是翻譯的角色,我們知道GPU的結構和CPU差別很大,GPU強調的是並行性重複性的計算工作,GPU因為結構和CPU不同,計算指令也不一樣,而在GPU加速中,CUDA就是負責把CPU的計算指令翻譯成GPU的計算指令,同時還負責視訊記憶體和計算機系統記憶體中資料的交換操作.

我們可以形象的的把顯示卡也看成一臺結構不一樣的計算機,它以GPU為CPU,視訊記憶體為記憶體,CUDA就負責把我們平常使用的CPU指令轉換成這臺顯示卡計算機所能接受的指令,並負責資料在這兩臺計算機之間的交換

CUDA的計算流程
開發人員使用一種全新的程式設計模式將並行資料對映、安排到GPU中。CUDA程式則把要處理的資料細分成更小的區塊,然後並行的執行它們。這種程式設計模式允許開發人員只需對GPU程式設計一次,無論是包含多處理器的GPU產品或是低成本、處理器數量較少的產品。當GPU計算程式執行的時候,開發者只是需要在主CPU上執行程式,CUDA驅動會自動在GPU上載入和執行程式。主機端程式可以通過高速的PCI Express匯流排與GPU進行資訊互動。資料的傳輸、GPU運算功能的啟動以及其它一些CPU 和GPU互動都可以通過呼叫專門的執行時驅動中的專門操作來完成。
編譯過程
CUDA的核心部分是專門開發的C編譯器。C語言對大多數開發人員都十分熟悉的,可以使程式設計人員專注於開發並行程式而不是處理負責的圖形API。為了簡化開發,CUDA的C編譯器允許程式設計師將CPU 和 GPU的程式碼混合記錄到一個程式檔案中。一些簡單程式碼被增加到的C程式中,通知CUDA編譯器哪些函式由CPU處理,哪些為GPU編譯。然後程式被CUDA編譯器編譯,而CPU處理的程式碼則由開發者的標準C編譯器編。

PTX中間媒介語言
整個編譯過程需要幾個階段。首先,所有的程式碼都要讓CPU來處理,這些都會從檔案中提取,並且他們都會通過標準的編譯器。用於GPU處理的程式碼,首先要轉換成中間媒介性語言——PTX
NVIDIA CUDA技術基於一種全新的用於開拓GPU運算效能的軟體架構,CUDA程式執行時,GPU作為主CPU的協處理器工作,GPU可以處理大量的並行資訊,同時CPU組織、解釋、與後臺交流要處理的資訊。應用程式的計算密集型部分要被執行很多次,每次由主應用程式提交的不同資料,經過編譯後由GPU並行執行。
CUDA輔助CPU進行通用運算功能的示意圖
CUDA可以用來生產資源,比如生成幾何圖形,在程式中進行材質貼圖等等,同時這些也可以傳遞到傳統的圖形API來生成。3D圖形API也可以將渲染後的結果傳送到CUDA進行後續處理。CUDA本身就是基於圖形晶片,而這種圖形晶片也具備通用計算的能力。這裡有許多互動性的例子,在GPU的視訊記憶體中儲存資料將更具優勢,系統可以繞過速度相對較慢的PCI-Express匯流排,直接呼叫視訊記憶體中的資料。
另一方面需要指出的是,針對這種在視訊記憶體內的資源共享來說,圖形資料並不總是短小精悍的,並且也會給程式設計師帶來一些頭痛的問題。例如,轉換解析度或者顏色深度時,圖形資料就有優先權。因此,如果在緩衝中的資源需要增加的時候,驅動程式會毫不猶豫的將應用程式分配給CUDA來執行。這樣CUDA計算和圖形處理就不會產生衝突。對於資料的分配和管理,CUDA還有待於更進一步完善。尤其是當我們的系統中有幾個GPU的時候,我們首先就無法使用SLI模式了,我們只能用一顆GPU來完成顯示工作。不過這也是避免系統混亂的最好辦法。
CUDA API其本質上來講是由各種操作視訊記憶體的函式組成的。cudaMalloc用來分配記憶體,cudaFree用來釋放記憶體,cudaMemcpy用來互相拷貝記憶體和視訊記憶體之間的資料。
名詞解析
thread執行緒 在CUDA裡定義thread執行緒的概念。因為這裡所指的執行緒,與傳統的“CPU執行緒”是有所區別的,同時也不是我們在GPU文章裡所指的“執行緒”。在GPU中,執行緒是最基本的元素,它貫穿於資料處理的始終。與CPU中的執行緒不同,CUDA的執行緒是非常輕巧微小的,這就意味著,單獨的執行緒處理起來會非常的簡單快速。
warp 不要試圖從字面理解warp的概念,因為它僅僅是一種象徵性的比喻,一個由NVIDIA自創的術語罷了。NVIDIA的意思是CUDA的整個處理工作,就像是一架織布機,織物在織布機內快速的來回穿過。
在CUDA中的一個warp,是由32個執行緒組成的。這也是SIMD處理中,資料的最小封包單位。CUDA採用的是多處理並行架構,它的主旨就是儘量能並行處理更多的資料。
grid 柵格,將許多個block塊封裝起來。這種資料機制的優勢就在於可以同時在GPU中處理多個block塊。這種方式將GPU所有硬體資源都緊密的聯絡在一起。
從CUDA原理中得到的優化PC啟示:
PhysX物理加速也是建立在CUDA技術之上的,CUDA執行時不但要佔用CPU資源,還要在顯示卡的GPU和視訊記憶體中劃分出一定的資源來用做GUP計算如:物理加速,通用計算等.通過對CUDA的分析我們就不難理解為什麼9500GT級別的顯示卡在開啟物理加速以後為什麼效能不升反降的原因.
隨著,大量遊戲對物理加速的支援和許多軟體開始對GPU加速的支援,顯示卡將不單是圖形處理,GPU的效能,流處理器的數量,和視訊記憶體的大小將直接影響著使用者遊戲和軟體的執行速度.在新應用下我們選擇顯示卡應該著重考慮以下幾方面:
1.顯示卡的GPU效能,效能強大的GPU才能夠更好的執行物理加速和CUDA通用計算,特別是在執行3D遊戲時,GPU要同時負責圖形加速和物理加速,對GPU效能有一定要求.
2.流處器的數量和頻率,流處理器數目越多頻率越高,平行計算能力越強
3.視訊記憶體的大小和速度,大容量的高速視訊記憶體在CUDA計算中能夠在更短的時間內交換更多的資料,在3D遊戲中也不會因為視訊記憶體太小而影響效能.
NVIDIA推薦的CUDA和物理加速顯示256M的9600GT以上的顯示卡,但是在目前來看,物理加速和CUDA要能夠流暢執行的話,一塊512M DDR3的9600GT是基本的要求,512M視訊記憶體才有足夠的視訊記憶體空間給CUDA作為GPU計算記憶體使用.而如果視訊記憶體只有256M,在CUDA計算量大的時候將直接影響效能,如果是3D遊戲,圖形處理也將受到影響.
相關推薦
CUDA學習之CUDA本質和原理-CUDA技術深入解析
從NVIDIA官方網站上找的CUDA資料可以看出CUDA的實現流程如下圖: CUDA的實現流程 從圖上我們可以看出CUDA在整個GPU計算中充當的就是翻譯的角色,我們知道GPU的結構和CPU差別很大,GPU強調的是並行性重複性的計算工作,GPU因為結構和CPU不同,計算指令
CUDA學習之使用GPU輸出HelloWorld
最近在學習CUDA,程式設計入門第一步便是“HelloWorld”,主要程式碼如下: #include "cuda_runtime.h" #include "device_launch_parameters.h" #include "iostream" __global__ void sayHel
CUDA學習之使用clock()函式
clock()函式是C/C++中的計時函式,相關的資料型別是clock_t,使用clock函式可以計算執行某一段程式所需的時間,如下所示程式計算從10000000逐漸減一直到0所需的時間。 #include "cuda_runtime.h" #include "device_launch_parame
CUDA學習之淺談cuBLAS
各位小夥伴們~!今天我們來談談CUDA中使用範圍很廣的一個程式設計庫——cuBLAS。 cuBLAS利用GPU加速向量、矩陣的線性運算。由於本人主要的研究方向是資料探勘,在資料探勘各種演算法中,包含著很多的向量、矩陣運算額,而隨著資料量的增大,普通的
我的CUDA學習之旅4——Sobel運算元影象邊緣檢測CUDA實現
引言 關於影象邊緣檢測,記得剛開始接觸影象處理時,第一個自己實現的程式是通過筆記本攝像頭採集影象,利用OpenCV自帶的演算法庫進行Canny運算元邊緣檢測,那時候當看到程式執行後,視訊視窗實時顯示經Canny運算元邊緣分割後的影象,覺得十分有科技感,後來慢慢
我的CUDA學習之旅1——大影象分塊處理程式(包括求均值,最大值等)
引言 在我的第一篇文章中我簡單介紹了CUDA以及我的一些個人學習見解,在本文中我將開始正式開始CUDA實踐之旅,眾做周知CUDA目前應用的領域十分廣泛,它能把一些普通的CPU程式碼提速幾十倍甚至幾百倍。在本人所從事的影象處理領域,在一些大影象的處理上(4K以上
機器學習之支援向量機原理和sklearn實踐
1. 場景描述 問題:如何對對下圖的線性可分資料集和線性不可分資料集進行分類? 思路: (1)對線性可分資料集找到最優分割超平面 (2)將線性不可分資料集通過某種方法轉換為線性可分資料集 下面將帶著這兩個問題對支援向量機相關問題進行總結 2. 如何找到最優分割超平面 一般地,當訓練資料集線性可分時,存
Python自動化3.0-------學習之路------日期和時間!
unix dst python自動化 相關 http -a 年份 字符串 cti Python 日期和時間 Python 程序能用很多方式處理日期和時間,轉換日期格式是一個常見的功能。 Python 提供了一個 time 和 calendar 模塊可以用於格式化日期和時間。
lua學習之閉包實現原理
引入 內嵌 種類 同時 概念比較 就會 類型 種類型 賦值語句 感覺學習lua的過程中, 閉包的概念比較難以理解,這裏記錄下對閉包的學習。 閉包的概念 在Lua中,閉包(closure)是由一個函數和該函數會訪問到的非局部變量(或者是upvalue)組成的,其中
oracle學習之基本查詢和條件過濾,分組函數使用
pic sub 排序 acl date 數值 模糊查詢 使用 char oracle是殷墟出土的甲骨文的第一個單詞,所以在中國叫做甲骨文,成立於1977年,總部位於美國加州。 在安裝好後,主要有兩個服務需要開啟: 1,實例服務,OracleServiceORCL,決定是否可
shell學習之變量和引號
11.變量的概念:變量是程序中保存用戶的一塊內存空間,變量名就是這塊內存空間的地址,變量的值保存在計算機內存中。變量的定義:可以簡單的理解,變量就是內存中一個鍵值關系對,如下 A可以理解為其在內存中的地址,1為其具體的內容。 [root@node-2 ~]# A=1 [root@node-2 ~]# echo
jquery學習之初始化和獲取值
pan AS jquery UNC function jquery對象 加載 就會 獲取值 jquery在運行的時候 在界面加載完之後再加載jquery對象,jquery加載的元素就會被加載出來 $(document).ready(function(){ //這裏填寫需
大數據學習之(Storm)-原理詳解!
大數據 storm 角色 Client client的主要作用是提交topology到集群 Worker Worker是運行在Supervisor節點上的一個獨立的JVM進程,主要作用是運行topology,一個topology可以包含多個worker,但一個worker只能屬於一個topology
小白的java學習之路 “ 類和對象”
之路 抽象 AS 類和對象 可維護 屬性和方法 style “.” 信息 一.※ 萬物皆對象 二.對象的兩個特征: 屬性:對象具有的各種特征 方法:對象執行的操作 對象:用來描述客觀事物的一個實體,由一組屬性和方法構成 三.
Linux學習之十三-vi和vim編輯器及其快捷鍵
man 參考 AS 選擇 都是 常用 linu ins align vi和vim編輯器及其快捷鍵 1、vi與vim區別 它們都是多模式編輯器,不同的是vim 是vi的升級版本,它不僅兼容vi的所有指令,而且還有一些新的特性在裏面。 vim的這些優勢主要體現在以下幾個方面:
Python學習之路 —— *args 和**kwargs
轉載自部落格園: http://www.cnblogs.com/moodlxs/p/3232222.html 當函式的引數不確定時,可以使用*args 和**kwargs,*args 沒有key值,**kwargs有key值。 話不多說直接上程式碼 [python] de
JSP學習之---運用useBean和jdbc操作。實現簡答前臺操作資料庫。
JSP學習之—運用useBean和jdbc操作。實現簡答前臺操作資料庫。 功能描述 1 . 在”student”表中查詢所有大於特定年齡的學生資訊,此年齡由使用者指定(提示,在網頁上面新增一個文字框用於使用者輸入年齡,然後根據使用者輸入的年齡建立sql語句,下面加一個按鈕,單擊按
python學習之列表物件實現原理解析
l=[1,2,3] id(l[0]) 1652911120 id(l[1]) 1652911152 id(l[2]) 1652911184
C++PrimerPlus學習之記憶體模型和名稱空間
標頭檔案 如果檔名包含在尖括號中,則C++編譯器將在儲存標準標頭檔案的主機系統的檔案系統的中查詢。如果檔名包含在雙引號中,則編譯器將在當前目錄下查詢。 使用條件編譯防止多次包含標頭檔案 #ifndef XXX_H_ #define XXX_H_ ... #en
機器學習之擬合和過擬合問題
過擬合:當某個模型過度的學習訓練資料中的細節和噪音,以至於模型在新的資料上表現很差,我們稱過擬合發生了,通俗點就是:模型在訓練集中測試的準確度遠遠高於在測試集中的準確度。 過擬合問題通常發生在變數特徵過多的時候。這種情況下訓練出的方程總是能很好的擬合訓練資料,也就是說,我們的代價函式可能非常接近於0或者就為