
用Tensorflow處理自己的資料:製作自己的TFRecords資料集
前言
最近一直在研究深度學習,主要是針對卷積神經網路(CNN),接觸過的資料集也有了幾個,最經典的就是MNIST, CIFAR10/100, NOTMNIST, CATS_VS_DOGS 這幾種,由於這幾種是在深度學習入門中最被廣泛應用的,所以很多深度學習框架 Tensorflow、keras和pytorch都有針對這些資料集專用的資料匯入的函式封裝,但是一般情況下我們的資料集並不是這種很規範的形式,那麼如何把自己的資料集轉換成這些框架能夠使用的資料形式至關重要,接下來博主將會對現有的較流行的深度學習框架封裝自己的資料進行講解,首先是針對最流行的Tensorflow。
查閱tensorflow的官方API,在GET STARTED下面的Programmer’s Guide中有一個Reading Data的章節介紹,大體內容就是tensorflow讀取資料的方式:

可以看到,tensorflow官網給出了三種讀取資料的方法:
對於資料量較小而言,可能一般選擇直接將資料載入進記憶體,然後再分batch輸入網路進行訓練(tip:使用這種方法時,結合yield 使用更為簡潔,大家自己嘗試一下吧,我就不贅述了)。但是,如果資料量較大,這樣的方法就不適用了,因為太耗記憶體,所以這時最好使用tensorflow提供的佇列queue,也就是第二種方法 從檔案讀取資料。對於一些特定的讀取,比如csv檔案格式,官網有相關的描述,在這兒我介紹一種比較通用,高效的讀取方法(官網介紹的少),即使用tensorflow內定標準格式——TFRecord.
那下面就讓我們瞭解一下什麼是TFRecord:
1. What is TFRecord?
TFRecords其實是一種二進位制檔案,雖然它不如其他格式好理解,但是它能更好的利用記憶體,更方便複製和移動,並且不需要單獨的標籤檔案(等會兒就知道為什麼了)… …總而言之,這樣的檔案格式好處多多,所以讓我們用起來吧。這裡注意:TFRecord會根據你輸入的檔案的類,自動給每一類打上同樣的標籤。
TFRecord檔案中的資料是通過tf.train.Example Protocol Buffer的格式儲存的,下面是tf.train.Example的定義:
message Example {
Features features = 1 從上述程式碼可以看到,ft.train.Example 的資料結構相對簡潔。tf.train.Example中包含了一個從屬性名稱到取值的字典,其中屬性名稱為一個字串,屬性的取值可以為字串(BytesList ),實數列表(FloatList )或整數列表(Int64List )。例如我們可以將解碼前的圖片作為字串,影象對應的類別標號作為整數列表。
2. How to convert our own data to TFRecord?
終於我們關心的話題來了,怎麼轉換?這裡我們使用Kaggle上面有名貓狗大戰的資料集可以通過Dogs vs Cats來下載,為了方便演示,我們利用這個資料集建立了一個新的資料集,取貓狗圖片中各100張分別放在data資料夾下面的cats和dogs子檔案中,入下圖所示。
資料準備好以後,我們就要開始讀取資料,生成TFRecord了,下面直接上程式碼,對於程式碼內容隨後會有相應的說明:
# -*- coding: utf-8 -*-
import os
import tensorflow as tf
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
cwd = "D://Anaconda3//spyder//Tensorflow_ReadData//data//"
classes = {'cats', 'dogs'} #預先自己定義的類別
writer = tf.python_io.TFRecordWriter('train.tfrecords') #輸出成tfrecord檔案
def _int64_feature(value):
return tf.train.Feature(int64_list = tf.train.Int64List(value = [value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list = tf.train.BytesList(value = [value]))
for index, name in enumerate(classes):
class_path = cwd + name + '//'
for img_name in os.listdir(class_path):
img_path = class_path + img_name #每個圖片的地址
img = Image.open(img_path)
img = img.resize((208, 208))
img_raw = img.tobytes() #將圖片轉化為二進位制格式
example = tf.train.Example(features = tf.train.Features(feature = {
"label": _int64_feature(index),
"img_raw": _bytes_feature(img_raw),
}))
writer.write(example.SerializeToString()) #序列化為字串
writer.close()以上程式碼就是將資料讀去進來,生成tfrecord檔案,看過Tensorflow官方API的同學們應該都可以看懂。
3. How to read data from TFRecords?
上面已經把自己的資料儲存成tensorflow可以使用的tfrecord的形式了,那麼tensorflow到底如何使用呢?下面繼續看程式碼:
def read_and_decode(filename, batch_size): # read train.tfrecords
filename_queue = tf.train.string_input_producer([filename])# create a queue
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)#return file_name and file
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw' : tf.FixedLenFeature([], tf.string),
})#return image and label
img = tf.decode_raw(features['img_raw'], tf.uint8)
img = tf.reshape(img, [208, 208, 3]) #reshape image to 208*208*3
label = tf.cast(features['label'], tf.int32) #throw label tensor
img_batch, label_batch = tf.train.shuffle_batch([img, label],
batch_size= batch——size,
num_threads=64,
capacity=2000,
min_after_dequeue=1500,
)
return img_batch, tf.reshape(label_batch,[batch_size]) 以上是我們定義的從tfrecord檔案中讀取資料的函式,在這裡我們使用的tensorflow的佇列讀取方式。在讀取到佇列中後,資料輸出之前還要作解碼的操作從,可以使用tf.TFRecordReader的tf.parse_single_example解析器。這個操作可以將Example協議記憶體塊(protocol buffer)解析為張量。
可以看到,這個函式除了tfrecord檔案的名這一個引數外,還有batch_size這個引數,利用tf.train.shuffle_batch()這個函式對讀取到的資料進行了batch處理,這樣更有利於後續的訓練。
注意:當資料量加大時,也可以將資料寫入多個TFRecord檔案。
我們的資料是讀進來,那麼到底是不是我們想要的呢,下面就是我們的測試程式。
4. How to show TFRecords’ images?
tfrecords_file = 'D://Anaconda3//spyder//Tensorflow_ReadData//train.tfrecords'
BATCH_SIZE = 4
image_batch, label_batch = read_and_decode(tfrecords_file,BATCH_SIZE)
with tf.Session() as sess:
i = 0
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop() and i<1:
# just plot one batch size
image, label = sess.run([image_batch, label_batch])
for j in np.arange(4):
print('label: %d' % label[j])
plt.imshow(image[j,:,:,:])
plt.show()
i+=1
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()
coord.join(threads)這裡我們也是用的tensorflow官網推薦的佇列管理形式,batch_size這裡可以大家任意設定,顯示幾幅圖片都可以,這裡博主設定的是4。
這樣就可以把任意格式的資料轉換成tensorflow推薦的TFRecord的格式的了,是不是隨你有很大幫助呢。下面是完整的程式碼:
# -*- coding: utf-8 -*-
import os
import tensorflow as tf
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
#%%
cwd = "D://Anaconda3//spyder//Tensorflow_ReadData//data//"
classes = {'cats', 'dogs'}
writer = tf.python_io.TFRecordWriter('train.tfrecords')
def _int64_feature(value):
return tf.train.Feature(int64_list = tf.train.Int64List(value = [value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list = tf.train.BytesList(value = [value]))
for index, name in enumerate(classes):
class_path = cwd + name + '//'
for img_name in os.listdir(class_path):
img_path = class_path + img_name #每個圖片的地址
img = Image.open(img_path)
img = img.resize((208, 208))
img_raw = img.tobytes() #將圖片轉化為二進位制格式
example = tf.train.Example(features = tf.train.Features(feature = {
"label": _int64_feature(index),
"img_raw": _bytes_feature(img_raw),
}))
writer.write(example.SerializeToString()) #序列化為字串
writer.close()
#%%
def read_and_decode(filename, batch_size): # read train.tfrecords
filename_queue = tf.train.string_input_producer([filename])# create a queue
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)#return file_name and file
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'img_raw' : tf.FixedLenFeature([], tf.string),
})#return image and label
img = tf.decode_raw(features['img_raw'], tf.uint8)
img = tf.reshape(img, [208, 208, 3]) #reshape image to 512*80*3
# img = tf.cast(img, tf.float32) * (1. / 255) - 0.5 #throw img tensor
label = tf.cast(features['label'], tf.int32) #throw label tensor
img_batch, label_batch = tf.train.shuffle_batch([img, label],
batch_size= batch_size,
num_threads=64,
capacity=2000,
min_after_dequeue=1500,
)
return img_batch, tf.reshape(label_batch,[batch_size])
#%%
tfrecords_file = 'D://Anaconda3//spyder//Tensorflow_ReadData//train.tfrecords'
BATCH_SIZE = 4
image_batch, label_batch = read_and_decode(tfrecords_file, BATCH_SIZE)
with tf.Session() as sess:
i = 0
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop() and i<1:
# just plot one batch size
image, label = sess.run([image_batch, label_batch])
for j in np.arange(BATCH_SIZE):
print('label: %d' % label[j])
plt.imshow(image[j,:,:,:])
plt.show()
i+=1
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()
coord.join(threads)執行結果如下:
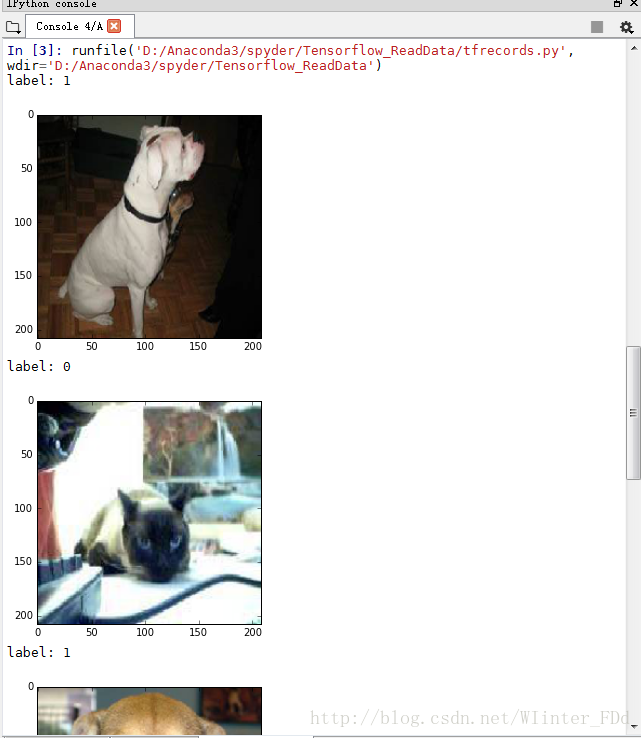
只需要Ctrl+C和V點選執行,就可以得到上面的結果了。
接下來還會講解到另外兩個深度學習框架Keras,pytorch如何將自己的資料轉化為框架可以使用的格式,敬請期待吧!!!!
相關推薦
用Tensorflow處理自己的資料:製作自己的TFRecords資料集
前言 最近一直在研究深度學習,主要是針對卷積神經網路(CNN),接觸過的資料集也有了幾個,最經典的就是MNIST, CIFAR10/100, NOTMNIST, CATS_VS_DOGS 這幾種,由於這幾種是在深度學習入門中最被廣泛應用的,所以很多深
TensorFlow Object Detection API教程——製作自己的資料集
""" Usage: # From tensorflow/models/ # Create train data: python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record
Docker實戰(二):製作自己的Docker映象
製作自己的Docker映象 製作自己的Docker映象主要有如下兩種方式: 1.使用docker commit 命令來建立映象 通過docker run命令啟動容器修改docker映象內容docker commit提交修改的映象docker run新的映象 2.使用
資料儲存-大資料:十問重複資料刪除技術
企業在選擇重複資料刪除產品時,最好想想下面的十個問題。 儲存產品提供商在釋出一款重刪產品時,如何定位自己的產品,是不是也要想想下面的問題呢? 1. 重複資料刪除技術對備份效能將產生什麼影響? 2. 重複資料刪除會降低恢復資料的效能? 3. 容量和效能擴充套件將如何隨著環境
TensorFlow 製作自己的TFRecord資料集 讀取、顯示及程式碼詳解
準備圖片資料 筆者找了2類狗的圖片, 哈士奇和吉娃娃, 全部 resize成128 * 128大小 如下圖, 儲存地址為D:\Python\data\dog 每類中有10張圖片 現在利用這2 類 20張圖片製作TFRecord檔案 製作TFRECO
pytorch 資料處理:定義自己的資料集合
資料處理 版本1 #資料處理 import os import torch from torch.utils import data from PIL import Image import numpy as np #定義自己的資料集合 class D
SSD目標檢測(2):如何製作自己的資料集(詳細說明附原始碼)
前言:因為要依賴上一章SSD目標檢測(1):圖片+視訊版物體定位(附原始碼)來訓練預測自己的資料集,所以建立自己的資料集是一個複雜且避不開的步驟,以下給出了製作自己的資料集所要經過的簡單步驟,而後也有更詳細的說明奉上。 VOC2007資料集簡介; 規定資料夾
用Tensorflow Object Detection API 訓練自己的資料集
一、準備資料集 Tensorflow Object Detection API 用 TFRecord 檔案格式讀取資料,需把 VOC 格式的資料集進行轉換(我自己的資料集是VOC2007) 1、修改 tensorflow/models/object_dete
用tensorflow訓練自己的資料_3、訓練模型
訓練模型的時候,維數一定要匹配,同時要了解你自己的資料的格式,和讀取的型別,一個one_hot編碼用的函式和非one_hot用的函式完全不一樣,這也是我當時一直出現問題的原因。 #!/usr/bin/env python2 # -*- coding: utf-8 -*-
用自己的資料,製作python版本的cifar10資料集
前期準備:3通道圖片60000張,如果你沒有那麼大的資料量,需要改變cifar-10-API中的定義,下面會具體說到。 如果你的圖片是灰度圖(單通道)可以用這種方法來改為三通道: opencv將灰度圖轉化為RGB三通道影象 要求為python2.7版本,
用Photoshop製作自己喜歡的桌面
今天工作完,準備關電腦時,發現桌面已不像樣子了,很是頭痛,然後就試著用Photoshop製作了一個簡單分門類別的桌面,先截個樣本 我的左上角一般放置計算機方面的圖示,中間綠色的框放置開發工具,右上角放置設計工具,左下角是娛樂方面的圖示,右下角都是簡易工具圖示,中間空的那塊放臨時的檔案之
分享知識-快樂自己:oracle12c創建用戶提示ORA-65096:公用用戶名或角色無效
語句 mod 租用 內容 rac 取消 nis 步驟 ORC 今天在oracle12c上創建用戶,報錯了。如下圖: 我很郁悶, 就打開了oracle官方網站找了下, 發現創建用戶是有限制的。 2.解決方案 創建用戶的時候用戶名以c##或者C##開頭即可。 錯誤寫法: c
資料處理:用pandas處理大型csv檔案
在訓練機器學習模型的過程中,源資料常常不符合我們的要求。大量繁雜的資料,需要按照我們的需求進行過濾。拿到我們想要的資料格式,並建立能夠反映資料間邏輯結構的資料表達形式。 最近就拿到一個小任務,需要處理70多萬條資料。 我們在處理csv檔案時,經常使用pandas,可以幫助處理較大的
Makefile 檔案 -只有include和src資料夾 (自己用)
檔案目錄樹結構為: [email protected]:/home# tree . ├── include │ ├── client.h │ ├── gps_module.h │ └── jt.h ├── Makefile └── src ├── clien
【tensorflow】Object DetectionAPI訓練識別自己的資料集
#一、資料準備 ###1.一個友好的標註工具 各種系統安裝已經再此介紹的很詳細了,linux下可以三行命令解決。 注意:圖片要求是png或者jpg格式 1> . 標註資訊存為xml檔案,使用該指令碼可以將所有的xml檔案轉換為1個csv檔案(自行修改xml路徑
機器學習學習筆記:用MiniVGGNet處理Cifar-10資料集
0. 引言 VGGNet,由Simonyan和Zisserman在2014年提出,論文名字是《Very Deep Learning Convolutional Neural Networks for Large-Scale Image Recognition》。他們做出的貢
Linux:一步一步製作自己的根檔案系統
一步一步製作自己的根檔案系統 在這裡,實驗過程使用的是九鼎提供的S5PV210開發板,實驗核心同樣來自其官方資料盤中Linux資料包中的的QT4.8中的相關原始碼,實驗的NFS檔案系統在虛擬中的Ubuntu14.04中建立. 建立檔案系統根目錄 root
YOLOV3實戰2:訓練自己的資料集,你不可能出錯!
大家好,我是小p,今天給大家帶來一期用darknet版本YOLO V3訓練自己資料集的教程,希望大家喜歡。 歡迎加入物件檢測群813221712討論和交流,進群請看群公告! 一、搭建環境 搭建環境和驗證環境是否已經正確配置已在YOLOV3實戰1中詳細介紹,請一定
製作自己的目標檢測資料集再利用tf-faster-rcnn訓練
1.製作資料集的工具 我利用資料集標註工具是精靈標註助手,我認為很好用。奉勸一句標註資料集時不要隨便找人給你標,如果他沒有用心給你標註,你在後面訓練會出現很多問題。在一開始標註資料集的時候不要一下子給他標註完,先標註幾十張圖片,然後用在你的網路裡,看看有沒有錯誤,如果沒有問
用Tensorflow來預處理Imagenet資料
最近想以Imagenet 2012影象分類大賽的資料來進行訓練和測試,看看如何能利用這麼大量的影象資料來完善卷積神經網路模型。之前做的基於Cifar10的資料量還是大小了,類別也不夠多。Imagenet的資料總共有146G,共包含了1000個類別的影象,總共120萬張圖片。T