
【Hadoop】YARN詳解與安裝指南
一 背景介紹
自從Hadoop推出以來,在大資料計算上得到廣泛使用。其他分散式計算框架也出現,比如spark等。隨著Hadoop的使用和研究越來越透徹,它暴漏出來的問題也越來越明顯。比如NameNode的單點故障,任務排程器JobTracker的單點故障和效能瓶頸。各個公司對這幾個問題都做出了對原始碼的改變,比如阿里對NameNode做出修改使Hadoop的叢集可以跨機房,而騰訊也做出了改變讓Hadoop可以管理更多的節點。 相對於各個企業對Hadoop做出改變以適應應用需求,Apache基金也對Hadoop做出了升級,從Hadoop 0.2.2.0推出了Hadoop二代,即YARN。YARN對原有的Hadoop做出了多個地方的升級,對資源的管理與對任務的排程更加精準。下面就對YARN從叢集本身到叢集的安裝做一個詳細的介紹。二 YARN介紹
2.1 框架基本介紹
相對於第一代Hadoop,YARN的升級主要體現在兩個方面,一個是程式碼的重構上,另外一個是功能上。通過程式碼的重構不在像當初一代Hadoop中一個類的原始碼幾千行,使原始碼的閱讀與維護都不在讓人望而卻步。除了程式碼上的重構之外,最主要的就是功能上的升級。 功能上的升級主要解決的一代Hadoop中的如下幾個問題: 1:JobTracker的升級。這個其中有兩個方面,一個是程式碼的龐大,導致難以維護和閱讀;另外一個是功能的龐大,導致的單點故障和消耗問題。這也是YARN對原有Hadoop改善最大的一個方面。 2:資源的排程粗粒度。在第一代Hadoop中,資源排程是對map和reduce以slot為單位,而且map中的slot與reduce的slot不能相互更換使用。即就算執行map任務沒有多餘的slot,但是reduce有很多空餘slot也不能分配給map任務使用。 3:對計算節點中的任務管理粒度太大。 針對上述相應問題,YARN對Hadoop做了細緻的升級。YARN已經不再是一個單純的計算平臺,而是一個資源的監管平臺。在YARN框架之上可以使用MapReduce計算框架,也可以使用其他的計算或者資料處理,通過YARN框架對計算資源管理。升級後的YARN框架與原有的Hadoop框架之間的區別可以用下圖解釋: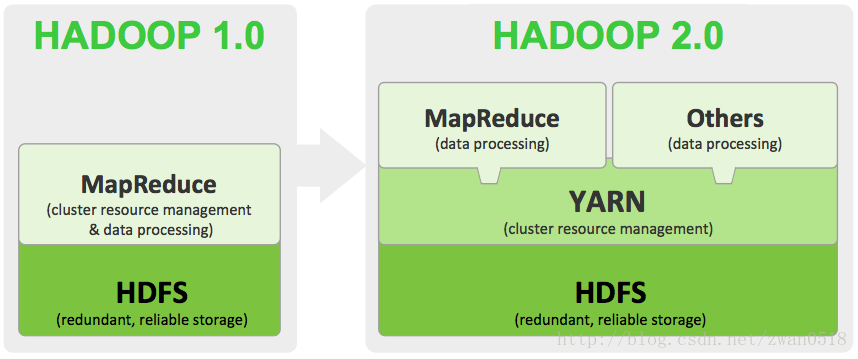
 細節內容待補充。
細節內容待補充。
2.2 框架架構解讀
相對於一代Hadoop中計算框架的JobTracker與TaskTracker兩個主要通訊模組,YARN的模組變的更加豐富。在一代Hadoop中JobTracker負責資源排程與任務分配,而在YARN中則把這兩個功能拆分由兩個不同元件完成,這不僅減少了單個類的程式碼量(單個類不到1000行),也讓每個類的功能更加專一。原有的JobTracker分為了如今的ResourceManager與ApplicationMaster 兩個功能元件,一個負責任務的管理一個負責任務的管理。有人會問那任務的排程與計算節點的誰來負責。任務的排程有可插拔的調 度器ResourceScheduler,計算節點有NodeManager來完成。這在下面會細說。 YARN的架構設計如下圖所示: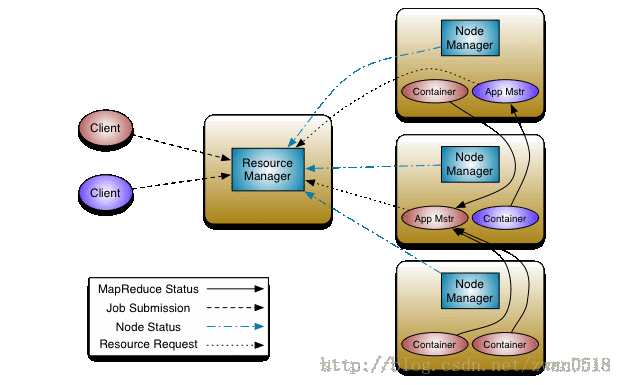
- 叢集唯一的ResourceManager
- 每個任務對應的ApplicationMaster
- 每個機器節點上的NodeManager
- 執行在每個NodeManager上針對某個任務的Container
2.3 功能元件細講
ResourceManager ResourceManager是這一代Hadoop升級中最主要的一個功能元件。 NodeManager ResourceScheduler三 安裝
相對於Hadoop的安裝,YARN的安裝稍微繁瑣一點,因為它的元件更多。對於一代Hadoop,它大的元件就可以分為HDFS與MapReduce,HDFS主要是NameNode與Datanode,而MapReduce就是JobTracker與TaskTracker。YARN框架中HDFS部分雖然和一代Hadoop相同,但是啟動方式則和一代完全不同;而MapReduce部分則更加複雜。所以安裝起來稍微繁瑣一點。下面我們就參考官方文件,開始慢慢講解整個安裝過程。在安裝過程中遇到的問題都記錄在附錄中給出的連線中。 YARN安裝可以通過下載tar包或者通過原始碼兩種方式安裝,我們叢集是採用的下載tar包然後進行解壓的安裝方式,下載地址在附錄中給出。為了方便安裝,我們是解壓到根目錄/yarn。解壓tar包後的YARN目錄結構有一點需要注意,即配置檔案conf所在的正確位置應該是/yarn/conf,但是解壓後/yarn目錄中是沒有conf檔案的,但是有有個/etc/hadoop目錄。所有的配置檔案就在該目錄下,你需要做的是把該檔案move到/yarn/conf位置。再做下一步的安裝。如果你解壓後的檔案沒有出現上面情況,那這一步操作可以取消。對於YARN的安裝主要是HDFS安裝與MapReduce安裝。我們的叢集共有四臺機器,其中一臺作為NameNode所在,一臺作為ResourceManager所在,剩下的兩臺則擔任資料節點與計算節點。具體的機器安排如下:
linux-c0001:ResourceManager
linux-c0002:NameNode linux-c0003:DataNode/NodeManager linux-c0004:DataNode/NodeManager因為我們的叢集上已經安裝有其他版本的Hadoop,比如Apache的Hadoop還有Intel推出的Intel Distributiong Hadoop,所以很多預設的埠號都要修改,資料檔案的儲存位置與執行Hadoop的使用者都要修改。在安裝的過程中因為已經安裝的Hadoop的存在,也遇到了很多問題。這在下面還有附錄中的連線中都會有說明。 下面針對每個安裝進行介紹:
3.1 HDFS安裝與配置
HDFS安裝主要是NameNode與DataNode的安裝與配置,其中NameNode還需要一步格式化formate操作。其中HDFS的配置主要存在於core-site.xml與hdfs-site.xml兩個檔案中。這兩個配置檔案的預設屬性已經在附錄中給出,但是在我們叢集中不能採用。因為,我們叢集中已經安裝有其他Hadoop,如果全部採用預設配置則會出現衝突,在安裝過程中出現Port in use 的BindException。主要需要配置的地方如下幾點: 1:NameNode配置在我們叢集中c0002是NameNode所在的機器,在該機器的配置檔案中需要修改的是兩個檔案core-site.xml與hdfs-site.xml。需要修改的配置檔案指定namenode所在主機與埠號,NameNode的資料檔案目錄等幾點。
下面分別給出我們的core-site.xml與hdfs-site.xml的配置: core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux-c0002:9090</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration><configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>linux-c0002:50071</value>
</property>
<property>
<name>dfs.namenode.backup.address</name>
<value>linux-c0002:50101</value>
</property>
<property>
<name>dfs.namenode.backup.http-address</name>
<value>linux-c0002:50106</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/YarnRun/name1,/home/hadoop/YarnRun/name2</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>2:DataNode的配置
DataNode的配置是在hdfs-site.xml中進行個性化配置的,主要包括DataNode的主機和對外埠號,資料檔案位置。按照正常DataNode的主機與對外埠號是不用額外配置的,在安裝的時候採用預設的埠號就好。但是,還是那個原因,因為我們叢集中安裝有其他的Hadoop版本,所以不得不對預設的DataNode中的埠號做一定的修改。下面給出配置後的檔案內容: hdfs-site.xml(DataNode)
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>linux-c0002:50071</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>linux-c0003:50011</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>linux-c0003:50076</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>linux-c0003:50021</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/YarnRun/data1</value>
</property>
</configuration>3:slaves檔案的修改
slaves檔案主要是指明子節點的位置,即資料節點和計算節點的位置。和一代Hadoop不同的是,在YARN中不需要配置masters檔案,只有slaves配置檔案。在slaves新增兩個子節點主機名(整個叢集的主機名在叢集中的所有主機的hosts檔案中已經註明):
linux-c0003
linux-c00044:Namenode的格式化
採用官方文件給出的格式化命令進行格式化(cluster_name沒有指定則不需要新增該引數)
$HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>5:Namenode啟動
採用官方文件給出的啟動命令直接啟動就好。(注意:啟動命令與格式化命令的指令碼不再同一個檔案中)
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode6:檢查NameNode是否啟動
輸入jps命令,看是否有NameNode程序;或者訪問其web連結看是否能正常訪問。如果不能正常訪問,則去看相應的日誌進行相應的定向修改。
7:DataNode的啟動 在YARN中DataNode的啟動與第一代Hadoop的啟動是不相同的,在第一代Hadoop中你執行一個start-all命令包括NameNode與各個節點上的DataNode都會相繼啟動起來,但是在YARN中你啟動DataNode必須要去各個節點依次執行啟動命令。當然你也可以自己寫啟動指令碼,不去各個節點重複執行命令。 下面貼出啟動命令:
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start datanode3.2 MapReduce安裝與配置 MapReduce其中需要配置安裝的地方是ResourceManager與NodeManager的安裝與配置。 1:ResourceManager的配置 ResourceManager與NameNode一樣,都是單獨在一個機器節點上,對ResourceManager的配置主要是在yarn-site.xml中進行配置的。可配置的屬性主要包括主機與埠號,還有排程器的配置。
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>linux-c0001:8032</value>
<description>the host is the hostname of the ResourceManager and the port is the port on
which the clients can talk to the Resource Manager. </description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>linux-c0001:8031</value>
<description>host is the hostname of the resource manager and
port is the port on which the NodeManagers contact the Resource Manager.
</description>
</property>
<!-- for scheduler -->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>linux-c0001:8030</value>
<description>host is the hostname of the resourcemanager and port is the port
on which the Applications in the cluster talk to the Resource Manager.
</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<description>In case you do not want to use the default scheduler</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value></value>
<description>the local directories used by the nodemanager</description>
</property>
<!-- for nodemanager -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>10240</value>
<description>the amount of memory on the NodeManager in GB</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/app-logs</value>
<description>directory on hdfs where the application logs are moved to </description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value></value>
<description>the directories used by Nodemanagers as log directories</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run </description>
</property>
</configuration>2:NodeManager的配置 NodeManager主要是配置計算節點上的對計算資源的控制和對外的埠號,它的配置也在yarn-site.xml中進行配置,所以這裡的配置檔案和上面貼出的配置檔案程式碼是完全一樣的,在這裡就不再次貼上檔案具體內容。 3:mapreduce的配置 mapreduce的配置主要是在mapred-site.xml中,用來指明計算框架的版本(Hadoop/YARN)還有計算的中間資料位置等。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.cluster.temp.dir</name>
<value></value>
</property>
<property>
<name>mapreduce.cluster.local.dir</name>
<value></value>
</property>
</configuration>$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager$HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start nodemanager6:JobHistory的啟動
JobHistory服務主要是負責記錄叢集中曾經跑過的任務,對完成的任務檢視任務執行期間的詳細資訊。一般JobHistory都是啟動在執行任務的節點上,即NodeManager節點上。如果不對JobHistory的配置進行修改,那麼直接可以在NodeManager所在節點上執行啟動命令即可,具體啟動命令如下:
$HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh start historyserver --config $HADOOP_CONF_DIR
啟動了之後就可以在叢集執行任務頁面檢視具體的job history,通過點選每個任務條目的左後history連結就可以檢視具體的任務細節。具體的截圖如下:
四 關閉叢集
當叢集升級或者需要重啟叢集的時候,就需要執行關閉命令。分別關閉NameNode與DataNode,然後關閉ResourceManager與NodeManager。但是在關閉的時候可能會遇到no namenode to stop或者no resourcemanager to stop的問題。這是因為YARN在關閉的時候,它會首先獲取當前系統中的YARN相關執行程序的ID,如果沒有則就會爆出上述兩個問題。但是系統中明明執行這YARN相關程序,為何還是會說沒有程序stop。這是因為當YARN執行起來之後,執行中的程序ID會儲存在/tmp資料夾下,而/tmp檔案會定期刪除檔案,這就導致YARN停止指令碼無法找到YARN相關程序的ID,導致不能停止。 兩個解決方案,第一個就是使用kill命令,而第二個則是修改YARN的程序ID的存放資料夾目錄。五 附錄
相關推薦
【Hadoop】YARN詳解與安裝指南
一 背景介紹 自從Hadoop推出以來,在大資料計算上得到廣泛使用。其他分散式計算框架也出現,比如spark等。隨著Hadoop的使用和研究越來越透徹,它暴漏出來的問題也越來越明顯。比如NameNode的單點故障,任務排程器JobTracker的單點故障和效能瓶頸
【Unity3D】簡單詳解 Protobuf 案例 從下載到安裝和使用
Protobuf介紹 Protocol Buffers是Google的一種資料交換的格式,一種輕量&高效的結構化資料儲存格式。可以用於結構化資料序列化(序列化)。由於它是二進位制的格式,比使用xml,Json進行資料交換快很多。 下面開始講解使用整個過程:
【基礎進階】URL詳解與URL編碼
// This function creates a new anchor element and uses location // properties (inherent) to get the desired URL data. Some String // operations are use
【springmvc】@RequestParam詳解以及加與不加的區別
以前寫controller層的時候都是預設帶上 @RequestParam 的, 今天發現不加@RequestParam 也能接收到引數 下面我們來區分一下加與不加的區別 這裡有兩種寫法 @RequestMapping("/list") public String
【docker虛擬化技術】dockerfile詳解與實踐
什麼是dockerfile? Dockerfile是為基於已有映象快速構建docker image(映象)而設計的,當你使用docker build命令的時候,docker 會讀取當前目錄下的命名為Dockerfile(首字母大寫)的純文字檔案並執行裡面的指令構建出
python web框架【補充】http詳解
既然 普通 pytho 又是 大學 響應頭 httpwatch 新的 pri 當你在瀏覽器地址欄敲入“http://www.cnblogs.com/”,然後猛按回車,呈現在你面前的,將是博客園的首頁了(這真是廢話,你會認為這是理所當然的)。作為一個開發者,尤其是web
【轉】Vue-詳解設置路由導航的兩種方法: <router-link :to="..."> 和router.push(...)
name app query outer 參數 size 命名 字符 適用於 一、<router-link :to="..."> to裏的值可以是一個字符串路徑,或者一個描述地址的對象。例如: // 字符串 <router-link to="apple
Grunt學習筆記【3】---- filter詳解
add 行處理 class 一個 特殊 col filter詳解 很多 https 本文主要講配置任務中的filter,包括使用默認fs.Stats方法名和自定義過濾函數。 通過設置filter屬性可以實現一些特殊處理邏輯。例如:要清理某個文件夾下的所有空文件夾,這時使用c
【Hadoop】在Ubuntu系統下安裝Hadoop單機/偽分布式安裝
multi .cn 編輯器 重新 偽分布式 sources edit 信息 情況 Ubuntu 14.10 前方有坑: 由於之前的分布式系統電腦帶不動,所以想換一個偽分布式試一試。用的是Virtualbox + Ubuntu 14.10 。結果遇到了 apt-get 源無
【NLP】Transformer詳解
傳送門:【NLP】Attention原理和原始碼解析 自Attention機制提出後,加入attention的Seq2seq模型在各個任務上都有了提升,所以現在的seq2seq模型指的都是結合rnn和attention的模型,具體原理可以參考傳送門的文章。之後google又提出瞭解決sequence to s
【Hadoop】在Ubuntu系統下安裝Spark
clas 進行 運行 輸出結果 oca .com 修改 我們 with Spark 版本:spark-2.4.0-bin-without-hadoop.tgz 下載地址:http://spark.apache.org/downloads.html 下載的時候註意一下,需要
【Hadoop】yarn的資源排程
yarn的資源排程 yarn的資源排程 前言 三種主要排程器 排程策略對比 yarn的資源排程 前言 Hadoop作為分散式計算平臺,從叢集計算的角度分析,Hadoop可以將底層的計算資源整合後統
【資料庫】jdbc詳解
轉載:https://www.cnblogs.com/erbing/p/5805727.html 一、相關概念 1.什麼是JDBC JDBC(Java Data Base Connectivity,java資料庫連線)是一種用於執行SQL語句的Java API,可以為多種關係資料庫提供統一訪問,它由
【Nginx】Nginx詳解
一、什麼是Nginx? Nginx是一個使用c語言開發的高效能的http伺服器及反向代理伺服器。Nginx是一款高效能的http 伺服器/反向代理伺服器及電子郵件(IMAP/POP3)代理伺服器。由俄羅斯的程式設計師Igor Syso
【乾貨】SIFT-Workstation 下載與安裝 不跳過每一個細節部分
SIFT-Workstation.ova 下載地址https://digital-forensics.sans.org/community/download-sift-kit ova是虛擬機器的格式,直接用虛擬機器開啟,可以
【java】ArrayList詳解
事實證明,你看完語法書之後,也不一定能寫出來程式碼,還需要不斷的來練習~ —— 小明醬lmx? ArrayList簡介 ArrayList是一個其容量能夠動態增長的動態陣列。它繼承了AbstractList,實現了List、RandomAccess, Clon
【轉載】meta 詳解,html5 meta 標籤日常設定
meta 詳解,html5 meta 標籤日常設定 <!DOCTYPE html> <!-- 使用 HTML5 doctype,不區分大小寫 --> <html lang="zh-cmn-Hans"> <!-- 更
【Android】 BroadcastReceiver詳解
1.Android廣播機制概述 Android廣播分為兩個方面:廣播發送者和廣播接收者,通常情況下,BroadcastReceiver指的就是廣播接收者(廣播接收器)。廣播作為Android元件間的通訊方式,可以使用的場景如下:1)同一app內部的同一組件內的訊息通訊(單個或多個執行緒之間); 2)同一a
【推薦】演算法詳解
感覺不錯的一些文章推薦下!!! 並查集詳解 ★★★★★ 動態規劃詳解 ★★★★★ 位運算藝術(一) 拓撲排序 最小生成樹-Prim演算法和Kruskal演算法 最短路徑——SPFA演算法 最短路演算法
【JMeter】04 詳解jmeter執行緒組
文章目錄 一、執行緒組 二、執行緒組的三種類型 1、 setup thread group 應用場景舉例: 2、teardown thread group 應用場景舉例: