
linux程序-執行緒-協程上下文環境的切換與實現
一:程序-執行緒-協程簡介
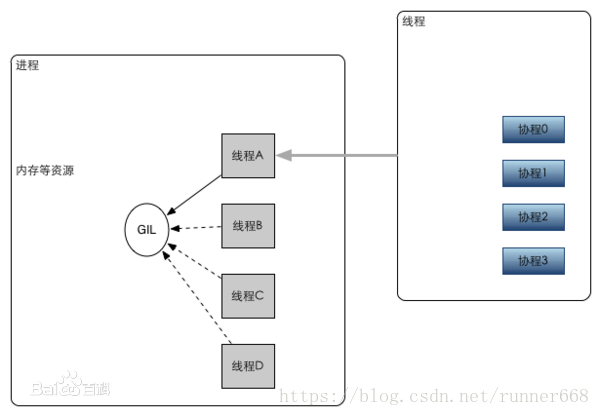
程序和執行緒的主要區別是:程序獨享地址空間和資源,執行緒則共享地址空間和資源,多執行緒就是多棧。
1、程序
程序是具有一定獨立功能的程式關於某個資料集合上的一次執行活動,程序是系統進行資源分配和排程的一個獨立單位。每個程序都有自己的獨立記憶體空間,不同程序通過程序間通訊來通訊。由於程序比較重量,佔據獨立的記憶體,所以上下文程序間的切換開銷(棧、暫存器、虛擬記憶體、檔案控制代碼等)比較大,但相對比較穩定安全。
2、執行緒
執行緒是程序的一個實體,是CPU排程和分派的基本單位,它是比程序更小的能獨立執行的基本單位.執行緒自己基本上不擁有系統資源,只擁有一點在執行中必不可少的資源(如程式計數器,一組暫存器和棧),但是它可與同屬一個程序的其他的執行緒共享程序所擁有的全部資源。執行緒間通訊主要通過共享記憶體,上下文切換很快,資源開銷較少,但相比程序不夠穩定容易丟失資料。
3、協程
協程是一種使用者態的輕量級執行緒,協程的排程完全由使用者控制。協程擁有自己的暫存器上下文和棧。協程排程切換時,將暫存器上下文和棧儲存到其他地方,在切回來的時候,恢復先前儲存的暫存器上下文和棧,直接操作棧則基本沒有核心切換的開銷,可以不加鎖的訪問全域性變數,所以上下文的切換非常快。
排程程序排程,切換程序上下文,包括分配的記憶體,包括資料段,附加段,堆疊段,程式碼段,以及一些表格。
執行緒排程,切換執行緒上下文,主要切換堆疊,以及各暫存器,因為同一個程序裡的執行緒除了堆疊不同。
協程又稱為輕量級執行緒,每個協程都自帶了一個棧,可以認為一個協程就是一個函式和這個存放這個函式執行時資料的棧,這個棧非常小,一般只有幾十kb。
什麼是協程
wikipedia 的定義:協程是一個無優先順序的子程式排程元件,允許子程式在特點的地方掛起恢復。
執行緒包含於程序,協程包含於執行緒。只要記憶體足夠,一個執行緒中可以有任意多個協程,但某一時刻只能有一個協程在執行,多個協程分享該執行緒分配到的計算機資源。
為什麼需要協程
簡單引入
就實際使用理解來講,協程允許我們寫同步程式碼的邏輯,卻做著非同步的事,避免了回撥巢狀,使得程式碼邏輯清晰。code like this:
co(function*(next){
let [err,data]=yield fs.readFile("./test.txt",next);//非同步讀檔案[err 非同步 指令執行之後,結果並不立即顯現的操作稱為非同步操作。及其指令執行完成並不代表操作完成。
協程是追求極限效能和優美的程式碼結構的產物。
一點歷史
起初人們喜歡同步程式設計,然後發現有一堆執行緒因為I/O卡在那裡,併發上不去,資源嚴重浪費。
然後出了非同步(select,epoll,kqueue,etc),將I/O操作交給核心執行緒,自己註冊一個回撥函式處理最終結果。
然而專案大了之後程式碼結構變得不清晰,下面是個小例子。
async_func1("hello world",func(){
async_func2("what's up?",func(){
async_func2("oh ,friend!",func(){//todo something})})})於是發明了協程,寫同步的程式碼,享受著非同步帶來的效能優勢。
程式執行是需要的資源:
- cpu
- 記憶體
- I/O (檔案、網路,磁碟(記憶體訪問不在一個層級,忽略不計))
協程的實現原理(非同步實現)
libco 一個C++協程庫實現
libco原始碼檔案一共11個,其中一個是彙編程式碼,其餘是C++,閱讀起來相對較容易。
在C++裡面實現協程要解決的問題有如下幾個:
- 何時掛起協程?何時喚醒協程?
- 如何掛起、喚醒協程,如何保護協程執行時的上下文?
- 如何封裝非同步操作?
前期知識準備
- 現代作業系統是分時作業系統,資源分配的基本單位是程序,CPU排程的基本單位是執行緒。
- C++程式執行時會有一個執行時棧,一次函式呼叫就會在棧上生成一個record
- 執行時記憶體空間分為全域性變數區(存放函式,全域性變數),棧區,堆區。棧區記憶體分配從高地址往低地址分配,堆區從低地址往高地址分配。
- 下一條指令地址存在於指令暫存器IP,ESP寄存值指向當前棧頂地址,EBP指向當前活動棧幀的基地址。
- 發生函式呼叫時操作為:將引數從右往左依次壓棧,將返回地址壓棧,將當前EBP暫存器的值壓棧,在棧區分配當前函式區域性變數所需的空間,表現為修改ESP暫存器的值。
- 協程的上下文包含屬於他的棧區和暫存器裡面存放的值。
何時掛起,喚醒協程?
如開始介紹時所說,協程是為了使用非同步的優勢,非同步操作是為了避免IO操作阻塞執行緒。那麼協程掛起的時刻應該是當前協程發起非同步操作的時候,而喚醒應該在其他協程退出,並且他的非同步操作完成時。
如何掛起、喚醒協程,如何保護協程執行時的上下文?
協程發起非同步操作的時刻是該掛起協程的時刻,為了保證喚醒時能正常執行,需要正確儲存並恢復其執行時的上下文。
所以這裡的操作步驟為:
- 儲存當前協程的上下文(執行棧,返回地址,暫存器狀態)
- 設定將要喚醒的協程的入口指令地址到IP暫存器
- 恢復將要喚醒的協程的上下文
二:什麼是上下文切換
即使是單核CPU也支援多執行緒執行程式碼,CPU通過給每個執行緒分配CPU時間片來實現這個機制。時間片是CPU分配給各個執行緒的時間,因為時間片非常短,所以CPU通過不停地切換執行緒執行,讓我們感覺多個執行緒時同時執行的,時間片一般是幾十毫秒(ms)。
CPU通過時間片分配演算法來迴圈執行任務,當前任務執行一個時間片後會切換到下一個任務。但是,在切換前會儲存上一個任務的狀態,以便下次切換回這個任務時,可以再次載入這個任務的狀態,從任務儲存到再載入的過程就是一次上下文切換。
程序切換分兩步
1.切換頁目錄以使用新的地址空間
2.切換核心棧和硬體上下文。
對於linux來說,執行緒和程序的最大區別就在於地址空間。
對於執行緒切換,第1步是不需要做的,第2是程序和執行緒切換都要做的。所以明顯是程序切換代價大
執行緒上下文切換和程序上下問切換一個最主要的區別是執行緒的切換虛擬記憶體空間依然是相同的,但是程序切換是不同的。這兩種上下文切換的處理都是通過作業系統核心來完成的。核心的這種切換過程伴隨的最顯著的效能損耗是將暫存器中的內容切換出。
另外一個隱藏的損耗是上下文的切換會擾亂處理器的快取機制。簡單的說,一旦去切換上下文,處理器中所有已經快取的記憶體地址一瞬間都作廢了。還有一個顯著的區別是當你改變虛擬記憶體空間的時候,處理的頁表緩衝(processor’s Translation Lookaside Buffer (TLB))或者相當的神馬東西會被全部重新整理,這將導致記憶體的訪問在一段時間內相當的低效。但是線上程的切換中,不會出現這個問題。
四:上線文切換的實質
對於執行緒或者協程來說切換的本質都是堆疊地址的儲存和恢復。
大概的切換流程如下:
X86 32 Bists
SS --> 選擇子--->段描述表-->(段限,段基址)
CR3 --->頁目錄,頁表
ESP-->
EBP--> ESP,EBP 正式 堆疊指標暫存器。
變數通過ESP,EBP 兩個指標 加偏移量訪問。
五:比較
1、程序多與執行緒比較
執行緒是指程序內的一個執行單元,也是程序內的可排程實體。執行緒與程序的區別:
1) 地址空間:執行緒是程序內的一個執行單元,程序內至少有一個執行緒,它們共享程序的地址空間,而程序有自己獨立的地址空間
2) 資源擁有:程序是資源分配和擁有的單位,同一個程序內的執行緒共享程序的資源
3) 執行緒是處理器排程的基本單位,但程序不是
4) 二者均可併發執行
5) 每個獨立的執行緒有一個程式執行的入口、順序執行序列和程式的出口,但是執行緒不能夠獨立執行,必須依存在應用程式中,由應用程式提供多個執行緒執行控制
2、協程多與執行緒進行比較
1) 一個執行緒可以多個協程,一個程序也可以單獨擁有多個協程,這樣python中則能使用多核CPU。
2) 執行緒程序都是同步機制,而協程則是非同步
3) 協程能保留上一次呼叫時的狀態,每次過程重入時,就相當於進入上一次呼叫的狀態
4) 協程是使用者級的任務排程,執行緒是核心級的任務排程。
5) 執行緒是被動排程的,協程是主動排程的。
補充協程上下文環境的切換
協程
協程是一種程式設計元件,可以在不陷入核心的情況進行上下文切換。如此一來,我們就可以把協程上下文物件關聯到fd,讓fd就緒後協程恢復執行。
當然,由於當前地址空間和資源描述符的切換無論如何需要核心完成,因此協程所能排程的,只有在同一程序(執行緒)中的不同上下文而已。
我們在核心裡實行上下文切換的時候,其實是將當前所有暫存器儲存到記憶體中,然後從另一塊記憶體中載入另一組已經被儲存的暫存器。對於圖靈機來說,當前狀態暫存器意味著機器狀態——也就是整個上下文。其餘內容,包括棧上記憶體,堆上物件,都是直接或者間接的通過暫存器來訪問的。 但是請仔細想想,暫存器更換這種事情,似乎不需要進入核心態麼。事實上我們在使用者態切換的時候,就是用了類似方案。也就是說協程是在使用者態儲存暫存器狀態的!作為推論:在單個執行緒中執行的協程,可以視為單執行緒應用。這些協程,在未執行到特定位置(基本就是阻塞操作)前,是不會被搶佔,也不會和其他CPU上的上下文發生同步問題的。因此,一段協程程式碼,中間沒有可能導致阻塞的呼叫,執行在單個執行緒中。那麼這段內容可以被視為同步的。
我們經常可以看到某些協程應用,一啟動就是數個程序。這並不是跨程序排程協程。一般來說,這是將一大群fd分給多個程序,每個程序自己再做fd-協程對應排程。
基於就緒通知的協程框架(epool本身是同步的)
- 協程
- 首先需要包裝read/write,在發生read的時候檢查返回。如果是EAGAIN,那麼將當前協程標記為阻塞在對應fd上,然後執行排程函式。
- 排程函式需要執行epoll(或者從上次的返回結果快取中取資料,減少核心陷入次數),從中讀取一個就緒的fd。如果沒有,上下文應當被阻塞到至少有一個fd就緒。
- 查詢這個fd對應的協程上下文物件,並排程過去。
- 當某個協程被排程到時,他多半應當在排程器返回的路上——也就是read/write讀不到資料的時候。因此應當再重試讀取,失敗的話返回1。
- 如果讀取到資料了,直接返回。
這樣,非同步的資料讀寫動作,在我們的想像中就可以變為同步的。而我們知道同步模型會極大降低我們的程式設計負擔。
我們經常可以看到某些協程應用,一啟動就是數個程序。這並不是跨程序排程協程。一般來說,這是將一大群fd分給多個程序,每個程序自己再做fd-協程對應排程。
基於就緒通知的協程框架
- 首先需要包裝read/write,在發生read的時候檢查返回。如果是EAGAIN,那麼將當前協程標記為阻塞在對應fd上,然後執行排程函式。
- 排程函式需要執行epoll(或者從上次的返回結果快取中取資料,減少核心陷入次數),從中讀取一個就緒的fd。如果沒有,上下文應當被阻塞到至少有一個fd就緒。
- 查詢這個fd對應的協程上下文物件,並排程過去。
- 當某個協程被排程到時,他多半應當在排程器返回的路上——也就是read/write讀不到資料的時候。因此應當再重試讀取,失敗的話返回1。
- 如果讀取到資料了,直接返回。
這樣,非同步的資料讀寫動作,在我們的想像中就可以變為同步的。而我們知道同步模型會極大降低我們的程式設計負擔。
C/C++怎麼實現協程
作為一個C++後臺開發,我知道像go, lua之類的語言在語言層面上提供了協程的api,但是我比較關心C++下要怎麼實現這一點,下面的討論都是從C/C++程式設計師的角度來看協程的問題的。
boost和騰訊都推出了相關的庫,語言層面沒有提供這個東西。我近期閱讀了微信開源的libco協程庫,協程核心要解決幾個問題:
1. 協程怎麼切換? 這個是最核心的問題,有很多trick可以做到這點,libco的做法是利用glibc中ucontext相關呼叫儲存執行緒上下文,然後用swapcontext來切換協程上下文,libco的實現中對swapcontext的彙編實現做了一些刪減和改動,所以在效能上會比C庫的swapcontext提升1個數量級。
2. IO阻塞了怎麼辦?試想在一個多協程的執行緒裡,一個阻塞IO由一個協程發起,那麼整個執行緒都阻塞了,別的協程也拿不到CPU資源,多個協程在一起等著IO的完成。libco中的做法是利用同名函式+dlsym來hook socket族的阻塞IO,比如read/write等,劫持了系統呼叫之後把這些IO註冊到一個epoll的事件迴圈中,註冊完之後把協程yield掉讓出cpu資源,在IO完成的時候resume這個協程,這樣其實把網路IO的阻塞點放在了epoll上,如果epoll沒有就緒fd,那其實在超時時間內epoll還是阻塞的,只是把阻塞的粒度縮小了,本質上其實還是用epoll非同步回撥來解決網路IO問題的。那麼問題來了,對於一些沒有fd的一些重IO(比如大規模資料庫操作)要怎麼處理呢?答案是:libco並沒有解決這個問題,而且也很難解決這個問題,首先要明確的一點是我們的目的是讓使用者只是僅僅呼叫了一個同步IO而已,不希望使用者感知到呼叫IO的時候其實協程讓出了cpu資源,按libco的思路一種可能的方法是,給所有重IO的api都hook掉,然後往某個非同步事件庫裡丟這個IO事件,在非同步事件返回的時候再resume協程。這裡的難點是可能存在的重IO這麼多,很難寫成一個通用的庫,只能根據業務需求來hook掉需要的呼叫,然後協程的編寫中依然可以以同步的方式呼叫這些IO。從以上可能的做法來看協程很難去把所有阻塞呼叫都hook掉,所以libco很聰明的只把socket族的相關呼叫給hook掉,這樣可以libco就成為一個通用的網路層面的協程庫,可以很容易移植到現有的程式碼中進行改造,但是也讓libco適用場景侷限於如rpc風格的proxy/logic的場景中。在我的理解裡,阻塞IO讓出cpu是協程要解決的問題,但是不是協程本身的性質,從實現上我們可以看出我們還是在用非同步回撥的方式在解決這個問題,和協程本身無關。
3. 如果一個協程沒有發起IO,但是一直佔用CPU資源不讓出資源怎麼辦?無解,所以協程的編寫對使用場景很重要,程式設計師對協程的理解也很重要,協程不適合於處理重cpu密集計算(耗時),只要某個協程即一直佔用著執行緒的資源就是不合理的,因為這樣做不到一個合理的併發,多執行緒同步模型由OS來排程併發,不存在說一個併發點需要讓出資源給另一個,而協程在編寫的時候cpu資源的讓出是由程式設計師來完成的,所以協程程式碼的編寫需要程式設計師對協程有比較深刻的理解。最極端的例子是程式設計師在協程裡寫個死迴圈,好,這個執行緒的所有協程都可以歇歇了。
協程有什麼好處
說了這麼多協程,協程的好處到底是啥?為什麼要使用協程?
1. 協程極大的優化了程式設計師的程式設計體驗,同步程式設計風格能快速構建模組,並易於複用,而且有非同步的效能(這個看具體庫的實現),也不用陷入callback hell的深坑。
2. 第二點也是我最近一直在糾結的一點,協程到底有沒有效能提升?
1)從多執行緒同步模型切到協程來看,首先很明確的效能提升點在於同步到非同步的切換,libco中把阻塞的點全部放到了epoll執行緒中,而協程執行緒並不會發生阻塞。其次是協程的成本比執行緒小,執行緒受棧空間限制,而協程的棧空間由使用者控制,而且實現協程需要的輔助資料結構很少,佔用的記憶體少,那麼就會有更大的容量,比如可以輕鬆開10w個協程,但是很難說開10w個執行緒。另外一個問題是很多人拿執行緒上下文切換比協程上下文切換開銷大來推出協程模型比多執行緒併發模型效能優這點,這個問題我糾結了很久。對於這個問題,我先做一個簡單的具體抽象:在不考慮阻塞的情況下,假設8核的cpu,不考慮搶佔中斷優先順序等因素,100個任務併發執行,100個執行緒併發和10個執行緒每個執行緒10個協程併發對比兩者都可以把cpu資源利用起來,對OS來說,前者100個執行緒參與cpu排程,後者10個執行緒參與cpu排程,後者還有額外的協程切換排程,先考慮執行緒切換的上下文,根據Linux核心排程器CFS的演算法,每個執行緒拿到的時間片是動態的,程序數在分配的時間片在可變區間的情況下會直接影響到執行緒時間片的長短,所以100個執行緒每個執行緒的時間片在一定條件下會要比10個執行緒情況下的要短,也就意味著在相同時間裡,前者的上下文切換次數是比後者要多的,所以可以得出一個結論:協程併發模型比多執行緒同步模型在一定條件下會減少執行緒切換次數(時間片有固定的範圍,如果超出這個範圍的邊界則執行緒的時間片無差異),增加了協程切換次數,由於協程的切換是由程式設計師自己排程的,所以很難說協程切換的代價比省去的執行緒切換代價小,合理的方式應該是通過測試工具在具體的業務場景得出一個最好的平衡點。
2)從非同步回撥模型切到協程模型來看,從一些已有協程庫的實現來看,協程的同步寫法卻有非同步效能其實還是非同步回撥在支撐這個事情,所以我認為協程模型是在非同步模型之上的東西,考慮到本身協程上下文切換的開銷(其實很小)和資料結構呼叫的一些開銷,理論上協程是比非同步回撥的效能要稍微差一點,但是可以處於幾乎持平的效能,因為協程實現的代價非常小。
3)從一些非同步驅動庫的角度來看協程的話,因為非同步框架把程式碼封裝到很多個小類裡面,然後串起來,這中間會涉及相當多的記憶體分配,而資料大都在離散的堆記憶體裡面,而協程風格的程式碼,可以簡單理解為一個簡潔的連續空間的棧記憶體池,輔助資料結構也很少,所以協程可能會比厚重的封裝效能會更好一些,但是這裡的前提是,協程庫能實現非同步驅動庫所需要的功能,並把它封裝到同步呼叫裡。
相關推薦
linux程序-執行緒-協程上下文環境的切換與實現
一:程序-執行緒-協程簡介程序和執行緒的主要區別是:程序獨享地址空間和資源,執行緒則共享地址空間和資源,多執行緒就是多棧。1、程序程序是具有一定獨立功能的程式關於某個資料集合上的一次執行活動,程序是系統進行資源分配和排程的一個獨立單位。每個程序都有自己的獨立記憶體空間,不同程
程序執行緒協程區別
現在多程序多執行緒已經是老生常談了,協程也在最近幾年流行起來。python中有協程庫gevent,py web框架tornado中也用了gevent封裝好的協程。本文主要介紹程序、執行緒和協程三者之間的區別。 一、概念 1、程序 程序是具有一定獨立功能的程式關於某個資料集合上的一次執
python 程序 執行緒 協程
併發與並行:並行是指兩個或者多個事件在同一時刻發生;而併發是指兩個或多個事件在同一時間間隔內發生。在單核CPU下的多執行緒其實都只是併發,不是並行。 程序是系統資源分配的最小單位,程序的出現是為了更好的利用CPU資源使到併發成為可能。程序由作業系統排程。 執行緒的出現是為了降低
python網路基礎之程序,執行緒,協程
程序,協程,執行緒的一些總結 # 1.程序:作業系統分配資源的基本單元,multiprocess模組提供了Process類來代表一個程序物件,這個物件可以理解為是一個獨立的程序,可以執行另外的事情 # 建立程序時,只需要傳入一個執行函式和函式的引數,建立一個 Process 例項,用
程序,執行緒,協程的對比
1.程序是資源分配的單位 2.執行緒是作業系統排程的單位 3.程序切換需要的資源最大,效率低 4.執行緒切換需要的資源一般,效率一般 5.協程切換任務資源很小,效率高 6.多程序,多執行緒根據cpu核數不一樣可能是並行的,但是協程是在一個執行緒中,所以是併發 協程(coroutines)
程序&執行緒&協程
程序:程式的一次執行,在系統內有獨立的地址空間、記憶體,以管理獨立的程式執行、切換。不同程序通過程序間通訊來通訊,由於程序比較重量,佔據獨立的記憶體,所以上下文程序間的切換開銷(棧、暫存器、虛擬記憶體、
python# 程序/執行緒/協程 # IO:同步/非同步/阻塞/非阻塞 # greenlet gevent # 事件驅動與非同步IO # Select\Poll\Epoll非同步IO 以及selector
# 程序/執行緒/協程 # IO:同步/非同步/阻塞/非阻塞 # greenlet gevent # 事件驅動與非同步IO # Select\Poll\Epoll非同步IO 以及selectors模組 # Python佇列/RabbitMQ佇列 ###########
程序/執行緒/協程/管程/纖程 筆記
下面是『雜談』,以前的我不重視基本概念。現在就需要惡補了。 認識CPU 百度百科 中央處理器(CPU,Central Processing Unit)是一塊超大規模的積體電路,是一臺計算機的運算核心(Core)和控制核心( Control Uni
關於Python的程序執行緒協程之大話多程序多執行緒
大話多程序多執行緒 “程序——資源分配的最小單位,執行緒——程式執行的最小單位” 程序: 是程式執行時的一個例項,即它是程式已經執行到課中程度的資料結構的彙集。從核心的觀點看
python 多程序/多執行緒/協程 同步非同步
這篇主要是對概念的理解: 1、非同步和多執行緒區別:二者不是一個同等關係,非同步是最終目的,多執行緒只是我們實現非同步的一種手段。非同步是當一個呼叫請求傳送給被呼叫者,而呼叫者不用等待其結果的返回而可以做其它的事情。實現非同步可以採用多執行緒技術或則交給另外的程序來處理。多執行緒的好處,比較容易的實現了 非
python爬蟲——多執行緒+協程(threading+gevent)
以下摘自這篇文章:https://blog.csdn.net/qq_23926575/article/details/76375337 在爬蟲中廣泛運用的多執行緒+協程的解決方案,親測可提高效率至少十倍以上。 本文既然提到了執行緒和協程,我覺得有必要在此對程序、執行緒、協程做一個簡單的對
go語言對映map的執行緒協程安全問題
見程式碼中註釋: package main import ( "fmt" "sync" ) func main() { m := map[string]int{"a":1, "b":2, "c":3, "d":4, "e"
Linux程序執行緒實驗
實驗1 程序 1.目的 通過觀察、分析實驗現象,深入理解程序及程序在排程執行和記憶體空間等方面的特點,掌握在POSIX 規範中fork和kill系統呼叫的功能和使用。 實驗前準備 學習man 命令的用法,通過它檢視fork 和kill 系統呼叫的
多執行緒——Java中繼承Thread類與實現Runnable介面的區別
執行緒我只寫過繼承Thread類的,後來知道java多執行緒有三種方式,今天首先比較一下常用的繼承Thread類和實現Runnable介面的區別。 按著Ctrl鍵進入Thread之後,發現Thread
Python程序,執行緒以及協程對比
執行緒:一份程式碼資源有多個箭頭同時執行 程序:拷貝多份程式碼資源中只存在一個箭頭(執行緒)來執行 協程 : 利用程式的阻塞或者暫停時間完成多工 即:資源分配的程式碼是程序,而執行程式碼的是執行緒, 可以理解為程序是工廠的一條流水線,其中執行緒就是流水線上的工人。 協程利用閒散時間加班的有志
python中多執行緒,多程序,多協程概念及程式設計上的應用
1, 多執行緒 執行緒是程序的一個實體,是CPU進行排程的最小單位,他是比程序更小能獨立執行的基本單位。 執行緒基本不擁有系統資源,只佔用一點執行中的資源(如程式計數器,一組暫存器和棧),但是它可以與同屬於一個程序的其他執行緒共享全部的資源。 提高程式的執行速率
python中多執行緒,多程序,多協程概念及程式設計上的應用!
1, 多執行緒 執行緒是程序的一個實體,是 CPU進行排程的最小單位,他是比程序更小能獨立執行的基本單位。 執行緒基本不擁有系統資源,只佔用一點執行中的資源(如程式計數器,一組暫存器和棧),但是它可以與同屬於一個程序的其他執行緒共享全部的資源。 提高程式的執行速率,上下文切換快
多執行緒、程序池、協程
程序池 #!/usr/bin/env python # -*- coding:utf-8 -*- from lxml import etree #import threading # multiprocessing.dummy 是多程序類庫裡裡的一個多執行緒模組,有一
併發程式設計中死鎖、遞迴鎖、程序/執行緒池、協程TCP伺服器併發等知識點
1、死鎖 定義; 類似兩個人分別被囚禁在兩間房子裡,A手上拿著的是B囚禁房間的鑰匙,而B拿著A的鑰匙,兩個人都沒法出去,沒法給對方開鎖,進而造成死鎖現象。具體例子程式碼如下: # -*-coding:utf-8 -*- from threading import Thread,Lock,RLoc
Linux 多執行緒和多程序的區別(小結)
最近學習Linux,看到“hairetz的專欄”的帖子不錯,特轉來大家一起學習。 很想寫點關於多程序和多執行緒的東西,我確實很愛他們。但是每每想動手寫點關於他們的東西,卻總是求全心理作祟,始終動不了手。 今天終於下了決心,寫點東西,以後可以再修修補補也無妨。一.為何需要多程序(或者多執行緒),為何需