
遷移學習應用(一)
最近對遷移學習比較感興趣,連續讀了幾篇和遷移學習相關的文章。本次部落格首先來總結幾篇遷移學習在NLP領域的應用。
NIPS(美國高階研究計劃局)2005年給遷移學習一個比價有代表性的解釋:transfer learning emphasizes the transfer of knowledge across domains, tasks, and distributions that are similar but not the same。總的來說,我感覺遷移學習更像是一種思想,所謂“遷移”的含義,就是使用其他領域(也叫做source領域)的知識來幫助目標領域(也叫做target領域)的學習。根據遷移學習具體不同的實現方法,遷移學習可以分為:1 基於樣本的學習;2 基於特徵的學習;3 基於引數的學習;4 基於相關性的學習。
一般來說,在NLP領域最常用的方法就是基於引數的學習,即在不同的任務領域中共享網路結構。最簡單的遷移學習就是pre-training策略(比方說word2vec),即把無監督生成的詞向量直接遷移到其他的有監督的任務中去,包括之前部落格中提到的multi-task方法,其實都運用到了遷移學習的思想。
今天要介紹的第一篇paper題目叫做《Universal Language Model Fine-tuning for Text Classification》來自於2018年的ACL。整個模型如下圖所示:
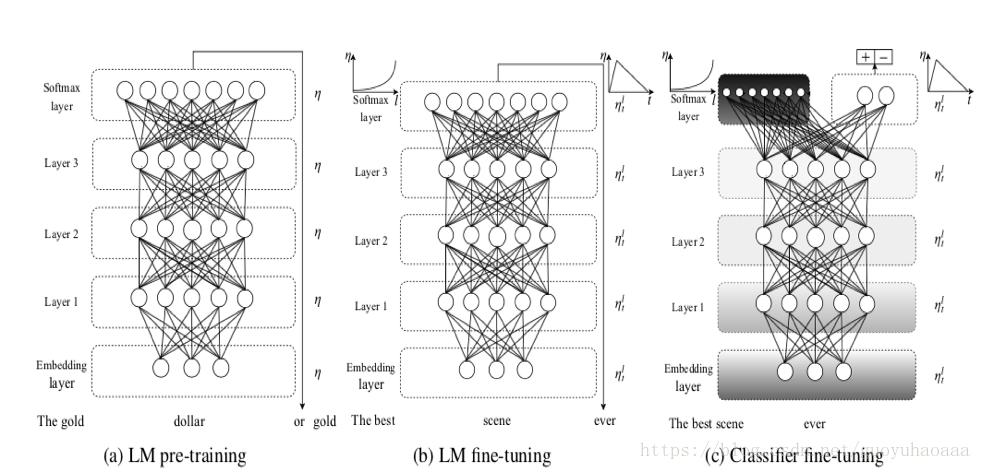
其中的LM指代的就是Language Model,其實就是簡單的多層LSTM網路(圖中的例項是三層)。這個論文所說的遷移學習體現在兩個方面:1 不同任務的遷移學習(LM和Classification);2 不同domain資料的遷移學習(圖中的LM pre-training 和 LM fine-tuning)
可以看出整個模型框架分為了三個階段:
a) LM pre-training。在該階段就是使用不同domain中的資料進行預訓練;
b) LM fine-tuning。在該階段就是是使用目標domain中的資料進行整個網路的fine-tuning操作,但是作者在該階段fine-tuning的時候採用了2種策略:
1 Discriminative fine-tuning,即對layer1,layer2和layer3採用不同的學習速率,layer3是最後一層學習速率為
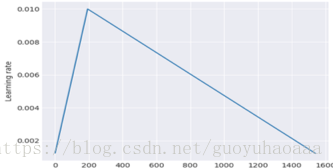
2 Slanted triangular learning rates,因為神經網路的訓練都是以epoch為單位進行的,這種方法就是每一個epoch都會對學習速率有一個修正,具體的修正公式如下:
其中,T是總的迭代次數,t是當前的迭代次數,是轉折比例,是最大的學習速率。整個學習速率的影象如下所示:
c) Classifier fine-tuning。可以看出,在該階段就是使用domain中的有標註資料進行分類器的訓練,就是把layer3的LSTM的輸出變數進行一系列的變換操作,最後輸入分類器的形式就是 ,就是最後一時刻的輸出向量,那麼在對分類器進行訓練的時候,除了Discriminative fine-tuning和Slanted triangular learning rates技術。為了避免全部fine-tuning導致網路對之前學到的general知識的遺忘,還使用了一種被稱之為Gradual unfreezing的方法,從後往前(從layer3到layer1方向)以epoch為單位進行逐步的新增。第一個epoch只把最後一層解凍,接下來每過一個epoch就把一個多餘的網路層加入到解凍集合中去。由於後面的網路更多的是specific資訊,前面的網路包含的更多general資訊,這樣的方式可以最大的幅度儲存(a)、(b)階段學習到的資訊。
其實整個模型是比價簡單、清晰的,作者最大的貢獻在於其提出了Discriminative fine-tuning、Slanted triangular learning rates和Gradual unfreezing這三種訓練技巧。
第二篇介紹的論文題目叫做《Learned in Translation: Contextualized Word Vectors》,發表在了2017年的NIPS上。它也運用到了遷移學習思想,整個思想模式如下所示:
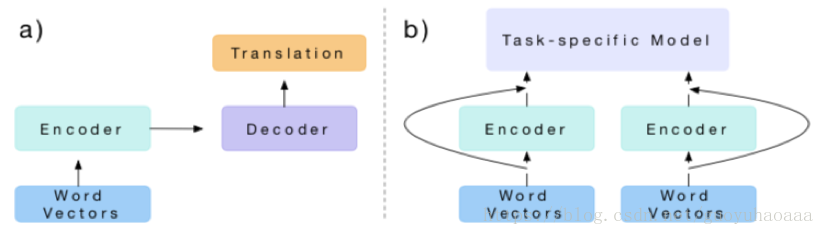
其實思想很簡單,主要運用到了不同任務的遷移方法,a圖代表的是source任務,b代表的是target任務。從圖中就可以看到a圖就是一個機器翻譯的模型,b圖利用了a任務下訓練出來的encoder進行進一步的task-specific的訓練。
下面先來講一下a任務的具體方法,假設源句子序列為,目標句子序列,使用代表詞序列的Glove向量表示,在encoder使用的是2層的bi-LSTM稱之為MT-LSTM,即。在decoder中使用的是2層單向的LSTM,其預測計算公式如下: