
組合方法(ensemble method) 與adaboost提升方法
組合方法:
我們分類中用到很多經典分類演算法如:SVM、logistic 等,我們很自然的想到一個方法,我們是否能夠整合多個演算法優勢到解決某一個特定分類問題中去,答案是肯定的!
通過聚合多個分類器的預測來提高分類的準確率。這種技術稱為組合方法(ensemble method) 。組合方法由訓練資料構建一組基分類器,然後通過對每個基分類器的預測進行權重控制來進行分類。
考慮25個二元分類組合,每個分類誤差是0.35 ,如果所有基分類器都是相互獨立的(即誤差是不相關的),則在超過一半的基分類器預測錯誤組合分類器才會作出錯誤預測。這種情況下的組合分類器的誤差率:

下圖對角線表示所有基分類器都是等同的情況,實線是基分類器獨立時情況。

組合分類器效能優於單個分類器必須滿足兩個條件:(1)基分類器之間是相互獨立的 (2) 基分類器應當好於隨機猜測分類器。實踐上很難保證基分類器之間完全獨立,但是在基分類器輕微相關情況下,組合方法可以提高分類的準確率。
組合方法分為兩類:(from http://scikit-learn.org/stable/modules/ensemble.html)
Two families of ensemble methods are usually distinguished:
-
In averaging methods, the driving principle is to build several estimators independently and then to average their predictions. On average, the combined estimator is usually better than any of the single base estimator because its variance is reduced.
-
By contrast, in boosting methods, base estimators are built sequentially and one tries to reduce the bias of the combined estimator. The motivation is to combine several weak models to produce a powerful ensemble.
先介紹強可學習與弱可學習,如果存在一個多項式的學習演算法能夠學習它並且正確率很高,那麼就稱為強可學習,相反弱可學習就是學習的正確率僅比隨機猜測稍好。
提升方法有兩個問題:1. 每一輪如何改變訓練資料的權重或概率分佈 2. 如何將弱分類器整合為強分類器。
很樸素的思想解決提升方法中的兩個問題:第1個問題-- 提高被前一輪弱分類器錯誤分類的權值,而降低那些被正確分類樣本權值 ,這樣導致結果就是 那些沒有得到正確分類的資料,由於權值加重受到後一輪弱分類器的更大關注。 第2個問題 adaboost 採取加權多數表決方法,加大分類誤差率小的弱分類器的權值,使其在表決中起到較大的作用,相反較小誤差率的弱分類的權值,使其在表決中較小的作用。
具體說來,整個Adaboost 迭代演算法就3步:
- 初始化訓練資料的權值分佈。如果有N個樣本,則每一個訓練樣本最開始時都被賦予相同的權重:1/N。
- 訓練弱分類器。具體訓練過程中,如果某個樣本點已經被準確地分類,那麼在構造下一個訓練集中,它的權重就被降低;相反,如果某個樣本點沒有被準確地分類,那麼它的權重就得到提高。然後,權重更新過的樣本集被用於訓練下一個分類器,整個訓練過程如此迭代地進行下去。
- 將各個訓練得到的弱分類器組合成強分類器。各個弱分類器的訓練過程結束後,加大分類誤差率小的弱分類器的權重,使其在最終的分類函式中起著較大的決定作用,而降低分類誤差率大的弱分類器的權重,使其在最終的分類函式中起著較小的決定作用。換言之,誤差率低的弱分類器在最終分類器中佔的權重較大,否則較小。
Adaboost演算法流程
給定一個訓練資料集T={(x1,y1), (x2,y2)…(xN,yN)},其中例項 ,而例項空間
,而例項空間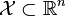 ,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練資料中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練資料中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
Adaboost的演算法流程如下:
- 步驟1. 首先,初始化訓練資料的權值分佈。每一個訓練樣本最開始時都被賦予相同的權重:1/N。
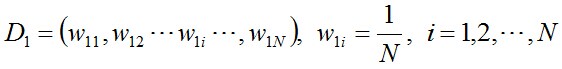
- 步驟2. 進行多輪迭代,用m = 1,2, ..., M表示迭代的第多少輪
a. 使用具有權值分佈Dm的訓練資料集學習,得到基本分類器:
b. 計算Gm(x)在訓練資料集上的分類誤差率
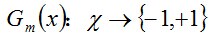
c. 計算Gm(x)的係數,am表示Gm(x)在最終分類器中的重要程度(目的:得到基本分類器在最終分類器中所佔的權重):由上述式子可知,Gm(x)在訓練資料集上的誤差率em就是被Gm(x)誤分類樣本的權值之和。
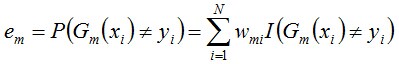
d. 更新訓練資料集的權值分佈(目的:得到樣本的新的權值分佈),用於下一輪迭代由上述式子可知,em <= 1/2時,am >= 0,且am隨著em的減小而增大,意味著分類誤差率越小的基本分類器在最終分類器中的作用越大。
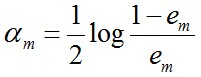
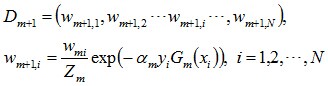
使得被基本分類器Gm(x)誤分類樣本的權值增大,而被正確分類樣本的權值減小。就這樣,通過這樣的方式,AdaBoost方法能“聚焦於”那些較難分的樣本上。
其中,Zm是規範化因子,使得Dm+1成為一個概率分佈:
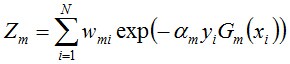
- 步驟3. 組合各個弱分類器
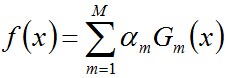
從而得到最終分類器,如下:
在《統計學習方法》p140頁有一個實際計算的例子可以自己計算熟悉演算法過程。
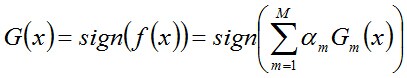
Adaboost的誤差界
通過上面的例子可知,Adaboost在學習的過程中不斷減少訓練誤差e,直到各個弱分類器組合成最終分類器,那這個最終分類器的誤差界到底是多少呢
事實上,Adaboost 最終分類器的訓練誤差的上界為:
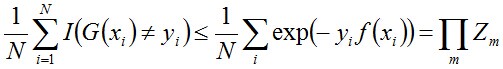
下面,咱們來通過推導來證明下上述式子。
當G(xi)≠yi時,yi*f(xi)<0,因而exp(-yi*f(xi))≥1,因此前半部分得證。
關於後半部分,別忘了:
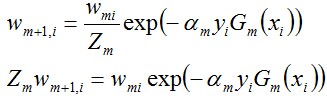
整個的推導過程如下:
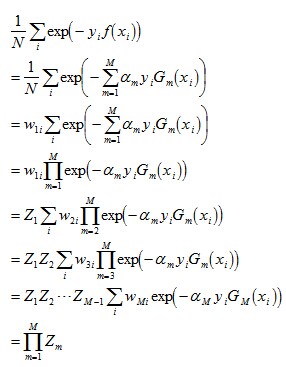
這個結果說明,可以在每一輪選取適當的Gm使得Zm最小,從而使訓練誤差下降最快。接著,咱們來繼續求上述結果的上界。
對於二分類而言,有如下結果:
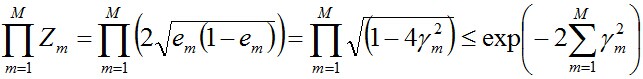
其中,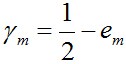
繼續證明下這個結論。
由之前Zm的定義式跟本節最開始得到的結論可知:
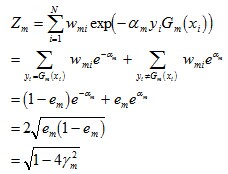
而這個不等式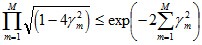
值得一提的是,如果取γ1, γ2… 的最小值,記做γ(顯然,γ≥γi>0,i=1,2,...m),則對於所有m,有:
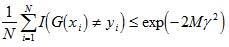
這個結論表明,AdaBoost的訓練誤差是以指數速率下降的。另外,AdaBoost演算法不需要事先知道下界γ,AdaBoost具有自適應性,它能適應弱分類器各自的訓練誤差率 。在統計學習方法第八章 中有關於這部分比較詳細的講述可以參考!!
在一個簡單資料集上的adaboost 的實現(來自機器學習實戰)
from numpy import*
def loadSimpData():
datMat = matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq =='lt':
retArray[dataMatrix[:,dimen]<= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0 ; bestStump = {} ; bestClasEst = mat(zeros((m,1)))
minError = inf
for i in range(n):
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax- rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j)* stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat]=0
weightedError = D.T *errArr
# print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEst
if __name__ == "__main__":
D = mat(ones((5,1))/5)
datMat,classLabels = loadSimpData()
buildStump(datMat, classLabels, D)
adaBoostTrainDS(datMat, classLabels, 10)
輸出結果:
D: [[ 0.2 0.2 0.2 0.2 0.2]]
classEst: [[-1. 1. -1. -1. 1.]]
aggClassEst: [[-0.69314718 0.69314718 -0.69314718 -0.69314718 0.69314718]]
total error: 0.2
D: [[ 0.5 0.125 0.125 0.125 0.125]]
classEst: [[ 1. 1. -1. -1. -1.]]
aggClassEst: [[ 0.27980789 1.66610226 -1.66610226 -1.66610226 -0.27980789]]
total error: 0.2
D: [[ 0.28571429 0.07142857 0.07142857 0.07142857 0.5 ]]
classEst: [[ 1. 1. 1. 1. 1.]]
aggClassEst: [[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]]
total error: 0.0
參考:統計學習方法、機器學習實戰、http://blog.csdn.net/v_july_v/article/details/40718799
相關推薦
組合方法(ensemble method) 與adaboost提升方法
組合方法: 我們分類中用到很多經典分類演算法如:SVM、logistic 等,我們很自然的想到一個方法,我們是否能夠整合多個演算法優勢到解決某一個特定分類問題中去,答案是肯定的! 通過聚合多個分類器的預測來提高分類的準確率。這種技術稱為組合方法(ensemble metho
簡單易學的機器學習演算法——整合方法(Ensemble Method)
一、整合學習方法的思想前面介紹了一系列的演算法,每個演算法有不同的適用範圍,例如有處理線性可分問題的,有處理線性不可分問題。在現實世界的生活中,常常會因為“集體智慧”使得問題被很容易解決,那麼問題來了,
統計學習方法c++實現之七 提升方法--AdaBoost
std learn 次數 比較 cal 算法 eat pre predict 提升方法--AdaBoost 前言 AdaBoost是最經典的提升方法,所謂的提升方法就是一系列弱分類器(分類效果只比隨機預測好一點)經過組合提升最後的預測效果。而AdaBoost提升方法是在每次
Java方法的定義與使用(方法過載)
方法過載指的是:方法名稱相同,引數的型別或個數不同。 範例:實現方法過載 public class TestDemo{ public static void main(String[] agrs){ //此時將根據引數的型別或個數的不同執行不同的方法
《統計學習方法》第八章-提升方法 學習總結
在《統計學習方法》中第八章提升方法,包括四節,第一節介紹AdaBoost、第二節介紹AdaBoost的誤差、第三節介紹從前向分佈演算法來實現AdaBoost、第四節介紹提升樹。 第一節 提升方法AdaBoost演算法 第一節首先介紹了AdaBoost的思
統計學習方法 李航 提升方法
博客 不能 不為 href sdn 發的 asn 思想 求和 很好理解,就是將一些基本的性能一般的弱分類器組合起來,來構成一個性能較好的強分類器;這其中如果數據一樣的話那不是每次訓練出的分類器就都一樣了嘛,所以在每次訓練後要根據訓練結果來改變數據的權重;還有一個關鍵點
提升方法:Adaboost演算法與證明
這基本就是關於《統計學習方法》的筆記,當然自己會記的讓人容易讀懂,為了加深記憶,證明都證了兩遍,便於加深理解還是打算寫在部落格裡好了。接下來會先介紹什麼是提示方法,再介紹Adaboost演算法,接著會給個書上的例子,最後再給出一些推導(由於之前是寫過的但是沒儲存好,所以這次有的部分就貼上
Ubuntu下提升當前用戶權限到root權限的坑與出坑方法
sudo www. ubuntu 多次 edi alt 刷新 重新登錄 無法 由於使用gedit過程中很多時候權限不足,想到將普通用戶的權限提升為root權限的用戶。經過問百度,有博客說通過修改"/etc/passwd"文件,提升用戶權限。如博客:https://blog.
有效提升直播平臺的人氣與收益的方法,幾步即可造就千萬級大直播平臺!
裏的 來講 建立 操作 真人秀 入口 cto 慢慢 技術分享 精品薦讀!詳細講述如何有效增長提升直播平臺人氣與收益! 幾步造就千萬級大主播,提升直播平臺人氣收益就要靠這些! 現在人都在看直播,也都在玩直播,大家每天關註的新聞中,有40%左右的內容都會涉及到直播,仔細分析市場
Struts xml中Action的method與路徑的三種匹配方法
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
整合學習與提升方法
提升:在隨機森林中我們通過構建T1 ...... Tn的的Ñ棵決策樹然後取這Ñ棵決策樹的平均得到一個總的森林,由於這是對每棵樹取平均,不存在哪棵樹重要,哪棵不重要的說法。現在我們換一種思路,給出這ñ棵樹的權值,即第T(k + 1)= a1T1 + ...... + akTk,這棵樹的係數第
提升方法AdaBoost演算法
1、提升方法 提升方法就是從弱學習演算法出發,反覆學習,得到一系列弱分類器(又稱為基本分類器),然後組合弱分類器,構成一個強分類器。大多數提升的方法都是改變訓練資料的的概率分佈(訓練資料的權值分佈)。 2、提升方法相關問題 (1)在每一輪如何改變訓
提升方法(Adaboost)
提升(boosting)方法是一種常用的統計學習方法,應用廣泛且有效。在分類問題中,它通過改變訓練樣本的權重,學習多個分類器,並將這些分類器進行線性組合,提高分類的效能。 基本思想:對於分類問題而言,給定一個訓練樣本集,求比較粗糙的分類規則(弱分類器)
提升方法:GBDT、XGBOOST、AdaBoost
提升 (boosting) 方法是一種常用的統計學習方法,應用廣泛且有效,在分類問題中,它通過改變訓練樣本的權重,學習多個分類器,並將這些分類器進行線性組合,提高分類器效能。 GBDT 我們知道隨機森林的決策樹分別取樣建立, 相對獨立。 那
提升方法:前向分步演算法與提升樹
這篇內容為《統計學習方法》的學習筆記,也看過其他書和培訓班的視訊ppt等,但是感覺都是離不開《統計學習方法》這本書,還是這本書讀起來乾淨利落(雖然有很少的地方有點暈)。 接下來首先介紹加法模型和前向分步演算法,接著介紹提升樹,最後補充梯度提升方法。 1、加法模型和前向分步演算法
php中使用while、each與list函式組合遍歷二維陣列的方法
在php中,系統為程式設計師提供了包括for迴圈、foreach()語句以及while、each與list函式組合遍歷陣列的三種方法。其中,由於for迴圈只能對索引值是連續的索引陣列進行遍歷而不能成為遍歷陣列的首選方法。而while、each與list函式組
設計模式與動態語言 之 模板方法(Template Method)
模板方法(Template Method): 屬行為型模式,最常用,最簡便意圖: [b]定義一個操作中的演算法骨架,而將一些步驟延遲到子類中。TempeleteMethod使得子類可以不改變一個演算法的結構即可重定義該演算法的某些特定步驟。[/b]動機: 多種輸出模板適用:
Boosting(提升方法)和AdaBoost
發現 更新 這樣的 做的 stat element 操作 for 簡單 集成學習(ensemble learning)通過構建並結合多個個體學習器來完成學習任務,也被稱為基於委員會的學習。 集成學習構建多個個體學習器時分兩種情況:一種情況是所有的個體學習器都是同一種類型的
機器學習——提升方法AdaBoost演算法,推導過程
0提升的基本方法 對於分類的問題,給定一個訓練樣本集,求比較粗糙的分類規則(弱分類器)要比求精確的分類的分類規則(強分類器)容易的多。提升的方法就是從弱分類器演算法出發,反覆學習,得到一系列弱分類器(又稱為基本分類器),然後組合這些弱分類器,構成一個強分類器。大多數的提升方法都是改變訓練資料集的概率分佈
Java靜態方法 與 非靜態方法(實例方法)的區別
外部類 允許 靜態成員 靜態 成員 訪問 靜態成員變量 ava 實例方法 靜態方法與實例方法的異同 1.在外部類 調用靜態方法時,有兩種方式:(1)類名.靜態方法()(2)類的對象.靜態方法() ;也就是說調用靜態方法時可以不用創建對象。 調用實例