
爬取拉勾網,並進行資料分析
拉勾網是現在網際網路招聘比較火熱的一個網站,本篇文章主要是爬取拉勾網“資料分析師”這個崗位,並且對所爬取到的資訊,進行資料分析。
資料採集
拉勾網的崗位資訊主要是用json檔案儲存,在position這個json檔案中,我們找到了所需要的崗位資訊
接著便開始寫爬蟲了:
# -*- coding: UTF-8 -*-
import json
import requests
headers = {
"Cookie": "user_trace_token=20171010163413-cb524ef6-ad95-11e7-85a7-525400f775ce; LGUID=20171010163413-cb52556e-ad95-11e7-85a7-525400f775ce; JSESSIONID=ABAAABAABEEAAJAA71D0768F83E77DA4F38A5772BDFF3E6; _gat=1; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=bzclk.baidu.com; PRE_SITE=http%3A%2F%2Fbzclk.baidu.com%2Fadrc.php%3Ft%3D06KL00c00f7Ghk60yUKm0FNkUsjkuPdu00000PW4pNb00000LCecjM.THL0oUhY1x60UWY4rj0knj03rNqbusK15yDLnWfkuWN-nj0sn103rHm0IHdDPbmzPjI7fHn3f1m3PDnsnH9anDFArH6LrHm3PHcYf6K95gTqFhdWpyfqn101n1csPHnsPausThqbpyfqnHm0uHdCIZwsT1CEQLILIz4_myIEIi4WUvYE5LNYUNq1ULNzmvRqUNqWu-qWTZwxmh7GuZNxTAn0mLFW5HDLP1Rv%26tpl%3Dtpl_10085_15730_11224%26l%3D1500117464%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253D%2525E3%252580%252590%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591%2525E3%252580%252591%2525E5%2525AE%252598%2525E7%2525BD%252591-%2525E4%2525B8%252593%2525E6%2525B3%2525A8%2525E4%2525BA%252592%2525E8%252581%252594%2525E7%2525BD%252591%2525E8%252581%25258C%2525E4%2525B8%25259A%2525E6%25259C%2525BA%2526xp%253Did%28%252522m6c247d9c%252522%29%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D220%26ie%3Dutf8%26f%3D8%26ch%3D2%26tn%3D98010089_dg%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26oq%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26rqlang%3Dcn%26oe%3Dutf8; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F%3Futm_source%3Dm_cf_cpt_baidu_pc; _putrc=347EB76F858577F7; login=true; unick=%E6%9D%8E%E5%87%AF%E6%97%8B; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=63; TG-TRACK-CODE=index_search; _gid=GA1.2.1110077189.1507624453; _ga=GA1.2.1827851052.1507624453; LGSID=20171011082529-afc7b124-ae1a-11e7-87db-525400f775ce; LGRID=20171011082545-b94d70d5-ae1a-11e7-87db-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507444213,1507624453,1507625209,1507681531; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507681548; SEARCH_ID=e420ce4ae5a7496ca8acf3e7a5490dfc; index_location_city=%E5%8C%97%E4%BA%AC" 值得說明的是header()裡面需要新增所有的header資訊,不然拉勾網的反爬蟲會讓程式報錯。

資料清洗
在上面的資料中,我們發現了一些缺失資料以及髒資料,因此,在資料分析之前,首先應該把資料進行清洗。
在資料清洗之前,我把剛剛的txt檔案轉換成CSV UTF-8格式,名字改成英文格式,以便於pycharm的讀取。
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
df=pd.read_csv('C:\\Users\\Administrator\\Desktop\\DataAnalyst .csv')
print(df.head())#讀取前五行
從上面的圖中,我們能看出關於工資方面應該做出處理,這裡只是一個工資的區間,下面我們把工資清理成平均值形式,並且以資料視覺化顯示出來:
df_duplicates=df.drop_duplicates(subset='positionId',keep='first')
def cut_word(word,method):
position=word.find('-')
length=len(word)
if position !=-1:
bottomsalary=word[:position-1]
topsalary=word[position+1:length-1]
else:
bottomsalary=word[:word.upper().find('K')]
topsalary=bottomsalary
if method=="bottom":
return bottomsalary
else:
return topsalary
df_duplicates['topsalary']=df_duplicates.salary.apply(cut_word, method="top")
df_duplicates['bottomsalary']=df_duplicates.salary.apply(cut_word, method="bottom")
df_duplicates['topsalary']=df_duplicates.salary.apply(cut_word,method="top") # apply()函式形式:apply(func,*args,**kwargs),*args相當於元組,**kwargs相當於字典
df_duplicates["bottomsalary"]=df_duplicates.salary.apply(cut_word,method="bottom")#apply()函式作用:用來間接的呼叫一個函式,並把引數傳遞給函式
df_duplicates.bottomsalary.astype('int')# 字串轉為數值型
df_duplicates.topsalary.astype('int')
df_duplicates["avgsalary"]=df_duplicates.apply(lambda x:(int(x.bottomsalary)+int(x.topsalary))/2,axis=1) #lambda是一種函式,舉例:lambda x:x+1,x是引數,x+1是表示式;axis=1表示作用於行
#選出我們想要的內容進行後續分析
df_clean=df_duplicates[['city','companyShortName','companySize','education','positionName','positionLables','workYear','avgsalary','industryField']]
import matplotlib.pyplot as plt
plt.style.use("ggplot") #使用R語言中的ggplot2配色作為繪圖風格,為好看
from matplotlib.font_manager import FontProperties #matplotlib.Font_manager 是一種字型管理工具
zh_font = FontProperties(fname="C:\\WINDOWS\\Fonts\\simsun.ttc")#matplotlib.Font_manager.FontProperties(fname) 是指定一種字型,C:\\WINDOWS\\Fonts\\simsun.ttc 是字型路徑,直接複製到電腦搜尋,你看能不能找到
fig=plt.figure(figsize=(8,5)) #關於繪圖方面,文末放了一個連結,講述的比較詳細
ax=plt.subplot(111)
rect=ax.hist(df_duplicates["avgsalary"],bins=30)
ax.set_title(u'薪酬分佈',fontProperties=zh_font)
ax.set_xlabel(u'K/月',fontProperties=zh_font)
plt.show(plt.xticks(range(5,100,5)) ) #xticks為x軸主刻度和次刻度設定顏色、大小、方向,以及標籤大小。
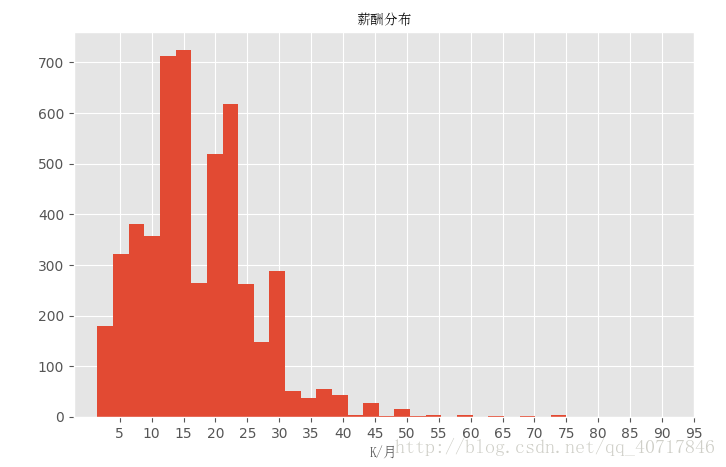
從上面的圖可以看出資料是偏右分佈,其中大多資料集中在10K~20K,也有極少數人獲得高薪。
不同城市的薪酬分佈情況:
ax=df_clean.boxplot(column='avgsalary',by='city',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(zh_font)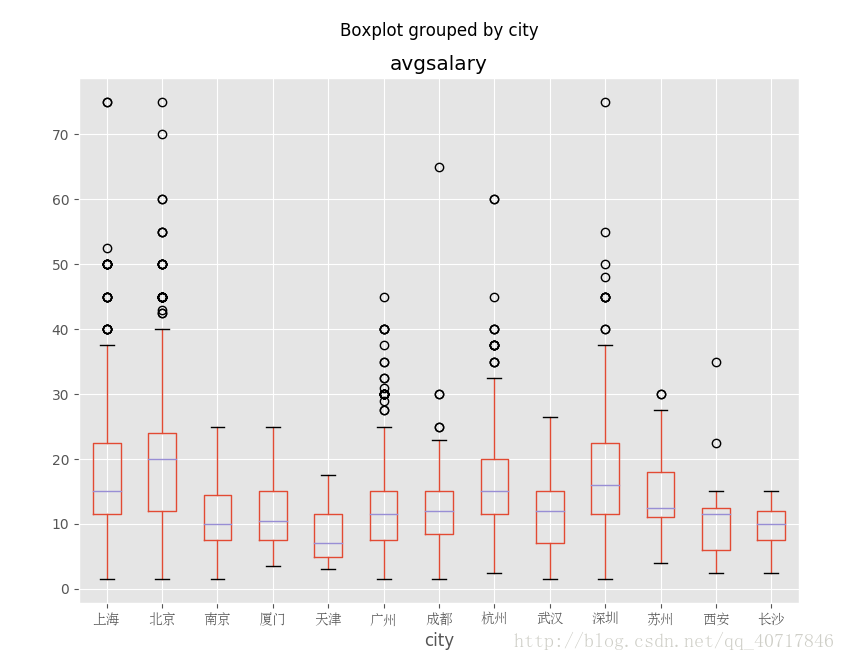
北京市薪酬分佈中位數大約在20k,居全國首位。其次是上海、杭州、深圳,中位數大約為15k左右,而廣州中位數只大約為12k。
不同學歷的薪酬分佈
ax=df_clean.boxplot(column='avgsalary',by='education',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(zh_font)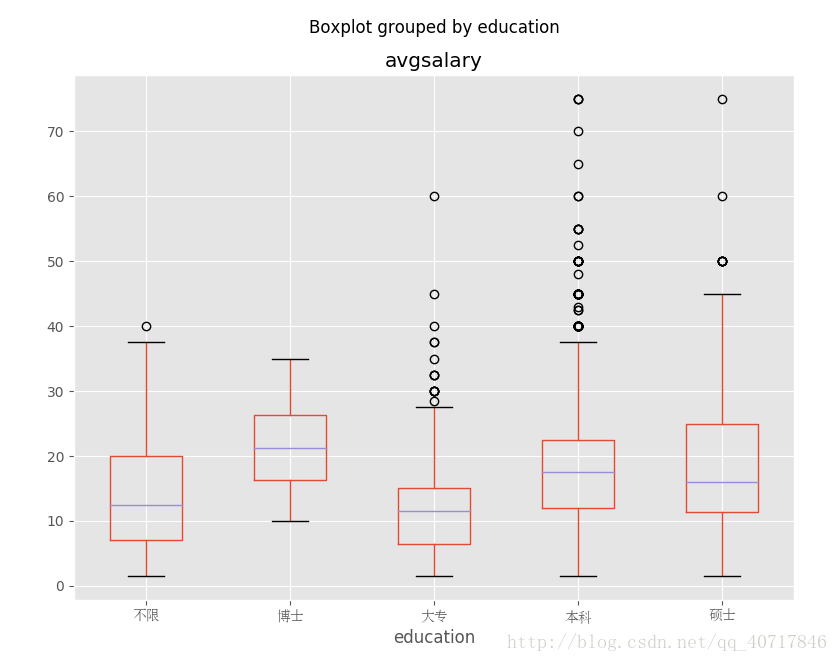
北京上海工作經驗不同薪酬分佈情況
df_bj_sh=df_clean[df_clean['city'].isin(['上海','北京'])]
ax=df_bj_sh.boxplot(column='avgsalary',by=['workYear','city'],figsize=(19,6))
for label_x in ax.get_xticklabels():
label_x.set_fontproperties(zh_font)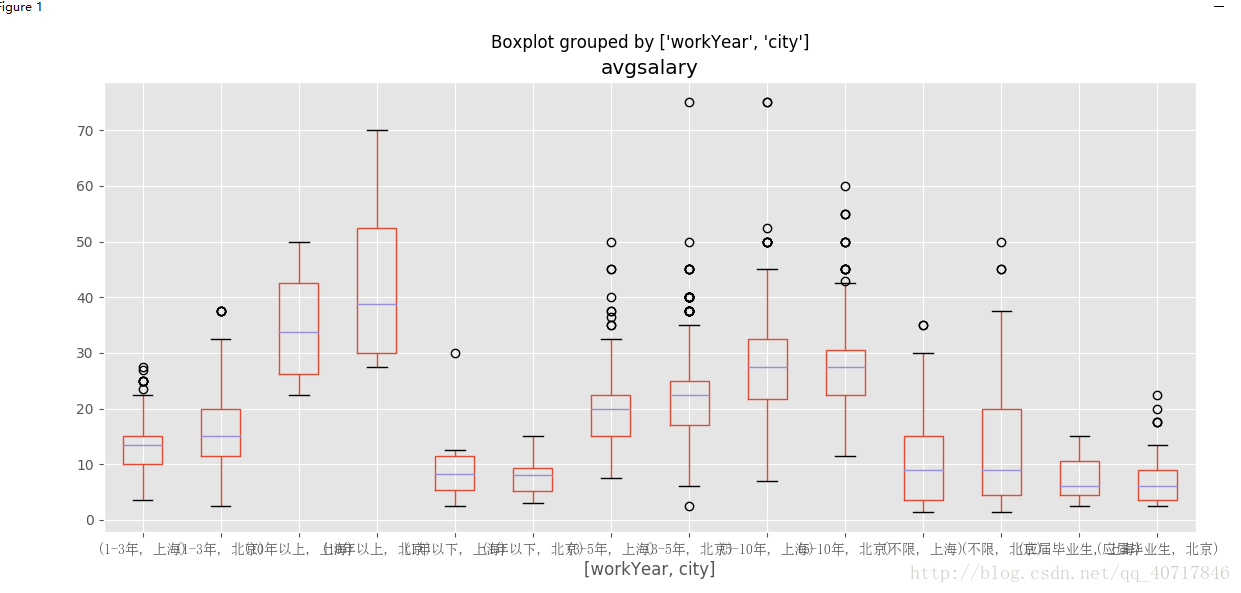
從圖中我們能夠得出,對於工作一年以下的,上海和北京兩個地方薪資基本一致,但是有能力的人在北京能夠得到較高的薪水。對於工作1-3年的人,北京工資的中位數都要比上海的上四分位數要大了。如果你的工作經驗還不大充足,你想好去哪裡發展了嗎?
北上廣深對資料分析職位需求量
def topN(df,n=5):
counts=df.value_counts() #value_counts()統計所有非零元素的個數
return counts.sort_values(ascending=False)[:n] #sort_values()對資料進行排序,ascending是設定升序和降序
df_bj_sh_gz_sz=df_clean[df_clean['city'].isin(['上海','北京','廣州','深圳'])]
df_bj_sh_gz_sz.groupby('city').positionName.apply(topN)city
上海 資料分析師 79
大資料開發工程師 37
資料產品經理 31
大資料工程師 26
高階資料分析師 20
北京 資料分析師 238
資料產品經理 121
大資料開發工程師 69
分析師 49
資料分析 42
廣州 資料分析師 31
需求分析師 23
大資料開發工程師 13
資料分析專員 10
資料分析 9
深圳 資料分析師 52
大資料開發工程師 32
資料產品經理 24
需求分析師 21
大資料架構師 11
Name: positionName, dtype: int64
我們現在可以看出,雖然想抓取的是資料師職位的情況,但得到的是和資料分析相關的職位,自己還是要在獲取資料、資料清理方面多下功夫啊。
不管怎樣我們還是能夠得出來,觀察北上廣深的資料分析師職位數量,還是北京力壓群雄啊。
公司所處行業領域詞雲圖分析
import re #re模組提供了對正則表示式的支援
import jieba as jb
from wordcloud import WordCloud
word_str = ','.join(df_clean['industryField']) # 以','為分隔符,將所有的元素合併成一個新的字串,注意:csv檔案中,單元格之間有逗號。
#對文字進行分詞
word_split = jb.cut(word_str) #精確模式
#使用|作為分隔符
word_split1 = "|".join(word_split)
pattern=re.compile("移動|網際網路|其他|金融|企業|服務|電子商務|O2O|資料|服務|醫療健康|遊戲|社交網路|招聘|生活服務|文化娛樂|旅遊|廣告營銷|教育|硬體|資訊保安")
#匹配所有文字字元;pattern 我們可以理解為一個匹配模式,用re.compile()方法來獲得這個模式
word_w=pattern.findall(word_split1) #搜尋word_split1,以列表形式返回全部能匹配的子串
word_s = str(word_w)
my_wordcloud = WordCloud(font_path="C:\\WINDOWS\\Fonts\\simsun.ttc",width=900,height=400,background_color="white").generate(word_s)
plt.imshow(my_wordcloud)
plt.axis("off") #取出座標軸
plt.show()
如圖所示:對於資料分析這一職位需求量大的主要是在網際網路、移動網際網路、金融、電子商務這些方面,所以找工作的話去這幾個領域獲得職位的機率估計是比較大的。我想這可能還有另一方面的原因:拉勾網本身主要關注的就是網際網路領域,等自己技術成熟了,要爬蟲獲得一份包含所有行業的資料進行一次分析。
分析結論
從總體薪酬分佈情況上,資料分析這一職業工資普遍較高的,大多人是在10k-25之間每月,但這只是拉勾網顯示的工資,具體的就不太清楚了。
從不同城市薪資分佈情況得出,在北京工作的資料分析師工資中位數在20k左右,全國之首。其次是上海、杭州、深圳,如果要發展的話,還是北、上、深、杭比較好啊。
從不同學歷薪資情況得出,學歷越高發展所獲得工資是越高,其中專科生略有劣勢,我想的是資料分析應該對數學有一定要求,畢竟大學是學了數理統計、高等數學還線性代數的。
根據北京上海工作經驗不同薪酬分佈情況,得出如果有些工作經驗去北京比上海獲得的工資要高一些。
分析北上廣深的資料分析師職位需求數量,北京以238個獲得最高。
根據公司所處行業領域詞雲圖分析,對於資料分析師需求量大的行業主要是網際網路、電子商務、金融等領域。
相關推薦
爬取拉勾網,並進行資料分析
拉勾網是現在網際網路招聘比較火熱的一個網站,本篇文章主要是爬取拉勾網“資料分析師”這個崗位,並且對所爬取到的資訊,進行資料分析。 資料採集 拉勾網的崗位資訊主要是用json檔案儲存,在position這個json檔案中,我們找到了所需要的崗位資訊
python爬蟲: 爬取拉勾網職位並分析
0. 前言 本文從拉勾網爬取深圳市資料分析的職位資訊,並以CSV格式儲存至電腦, 之後進行資料清洗, 生成詞雲,進行描述統計和迴歸分析,最終得出結論. 1. 用到的軟體包 Python版本: Python3.6 requests: 下載網
python爬取拉勾網資料並進行資料視覺化
爬取拉勾網關於python職位相關的資料資訊,並將爬取的資料已csv各式存入檔案,然後對csv檔案相關欄位的資料進行清洗,並對資料視覺化展示,包括柱狀圖展示、直方圖展示、詞雲展示等並根據視覺化的資料做進一步的分析,其餘分析和展示讀者可自行發揮和擴充套件包括各種分析和不同的儲存方式等。。。。。 一、爬取和分析
用python爬取拉勾網招聘資訊並以CSV檔案儲存
爬取拉勾網招聘資訊 1、在網頁原始碼中搜索資訊,並沒有搜到,判斷網頁資訊使用Ajax來實現的 2、檢視網頁中所需的資料資訊,返回的是JSON資料; 3、條件為北京+資料分析師的公司一共40087家,而實際拉勾網展示的資料只有 15條/頁 * 30頁 = 450條,所以需要判斷
Python爬取拉勾網招聘資訊並可視化分析
需求: 1:獲取指定崗位的招聘資訊 2:對公司地區,公司待遇,學歷情況,工作經驗進行簡單分析並可視化展示 視覺化分析: 公司地區:柱狀圖,地圖 公司待遇:雲圖 公司-學歷情況:餅圖 公司工作經
爬取拉勾網資訊,翻頁爬取
import requests #這個庫等價於 urllib 和urllib2 import bs4 #作用是用來解析網頁的 import json#主要是一種資料交換格式 import time de
爬取虎嗅網,並對爬取數據進行分析
ror range class index 關於 def mob 文章內容 gin 一、分析背景: 1,為什麽要選擇虎嗅 「關於虎嗅」虎嗅網創辦於 2012 年 5 月,是一個聚合優質創新信息與人群的新媒體平臺。 2,分析內容 分析虎嗅網 5 萬篇文章的基本情況,包括
Python爬蟲基礎教程,手把手教你爬取拉勾網!
一、思路分析: 在之前寫拉勾網的爬蟲的時候,總是得到下面這個結果(真是頭疼),當你看到下面這個結果的時候,也就意味著被反爬了,因為
HttpClient爬取拉勾網招聘資訊
1.匯入jar包 <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>htt
python爬取拉勾網之selenium
重點程式碼解釋: 1.呼叫lxml的etree實現xpath方法呼叫,xpath相對正則比較簡單,可以不在使用Beauitfulsoup定位 from lxml import etree 2.介面的可視話與否,對於你的執行資源只能用減少 opt=webdri
python爬取 拉勾網 網際網路大資料職業情況
爬取拉勾網資訊 資料處理 製圖 所需知識只有一點點(畢竟是個小白): requests基礎部分 json pyecharts wordcloud 接下來開始敲程式碼了,程式碼分成了3個部分:爬取、製圖、生成詞雲 爬取部分: 首先要說明的是,拉勾網有反爬
Python爬蟲:爬取拉勾網資料分析崗位資料
1 JSON介紹 JSON(JavaScript Object Notation)已經成為通過HTTP請求在Web瀏覽器和其他應用程式之間傳送資料的標準格式之一。比CSV格式更加靈活。Json資料格式,非常接近於有效的Pyhton程式碼,其特點是:JSON物件所
Python爬取拉勾網招聘資訊存入資料庫
先抓包分析我們想要獲取的資料,很明顯都是動態資料,所以直接到Network下的XHR裡去找,這裡我們找到具體資料後,就要去尋分析求地址與請求資訊了。還有需要提交的表單資訊分析完畢之後,我們就可以開始寫我們的爬蟲專案了。一.編寫Itemitem編寫比較簡單# 拉鉤職位資訊 cl
Python爬取拉勾網招聘資訊
此程式碼執行建議Python3,省卻中文編碼的麻煩 遇到的幾個問題: (1)拉鉤網的資料是通過js的ajax動態生成,所以不能直接爬取,而是通過post’http://www.lagou.com/jobs/positionAjax.json?needAddt
【圖文詳解】scrapy爬蟲與動態頁面——爬取拉勾網職位資訊(1)
5-14更新 注意:目前拉勾網換了json結構,之前是content - result 現在改成了content- positionResult - result,所以大家寫程式碼的時候要特別注意加上
python爬取拉勾網資料儲存到mysql資料庫
環境:python3 相關包:requests , json , pymysql 思路:1.通過chrome F12找到拉鉤請求介面,分析request的各項引數 2.模擬瀏覽器請求拉鉤介面 3.預設返回的json不是標準格式 ,
Python scrapy 爬取拉勾網招聘資訊
週末折騰了好久,終於成功把拉鉤網的招聘資訊爬取下來了。現在總結一下! 環境: windows 8.1 + python 3.5.0 首先使用 scrapy 建立一個專案: E:\mypy> scrapy startproject lgjob 建立後目錄結構:
python 爬取豆瓣電影評論,並進行詞雲展示及出現的問題解決辦法
本文旨在提供爬取豆瓣電影《我不是藥神》評論和詞雲展示的程式碼樣例 1、分析URL 2、爬取前10頁評論 3、進行詞雲展示 1、分析URL 我不是藥神 短評 第一頁url https://movie.douban.com/subject/26752088/comments?start=0&limit=2
scrapy爬取拉勾網python職位+Mysql+視覺化
在進行爬取目標網站中為遇到一個問題,爬取5頁資料之後會出錯,設定了每一次請求的隨機超時間10-20->time.sleep(random.randint(10, 20)),同樣會被拉勾網禁止請求資料,可能被輕度判定為爬取,所以可以設定每一次的隨機超時間為20-30秒,就可以解決這個問題。
python3 利用requests爬取拉勾網資料
學習python,瞭解了一點爬蟲的知識,成功的對拉勾網的招聘資訊進行了爬取,將爬取心得記錄下來,和大家一起學習進步。 準備工作: python3 requests pandas 谷歌瀏覽器(或者火狐瀏覽器、qq瀏覽器)