
mysql實現分表
專案開發中,我們的資料庫資料越來越大,隨之而來的是單個表中資料太多。以至於查詢書讀變慢,而且由於表的鎖機制導致應用操作也搜到嚴重影響,出現了資料庫效能瓶頸。
當出現這種情況時,我們可以考慮分表,即將單個數據庫表進行拆分,拆分成多個數據表,然後使用者訪問的時候,根據一定的演算法,讓使用者訪問不同的表,這樣資料分散到多個數據表中,減少了單個數據表的訪問壓力。提升了資料庫訪問效能。
我們可以進行簡單的設想:現在有一個表products儲存產品資訊,現在有100萬用戶線上訪問,就要進行至少100萬次請求,現在我們如果將它分成100個表即products0~~products99,那麼利用一定的演算法我們就分擔了單個表的訪問壓力,每個表只有1萬個請求(當然,這是理想情況下!)
實現mysql 分表的關鍵在於:設計良好的演算法來確定"什麼時候情況下訪問什麼(哪個)表"。
下面我們先來實現一個簡單的mysql分表演示:這裡使用MERGE分表法
1,建立一個完整表儲存著所有的成員資訊
create table member( id bigint auto_increment primary key, name varchar(20), sex tinyint not null default '0' )engine=myisam default charset=utf8 auto_increment=1;
加入點資料:
insert into member(id,name,sex) values (1,'jacson','0');
insert into member(name,sex) select name,sex from member;
第二條語句多執行幾次就有了很多資料。
2,下面我們進行分表:這裡我們分兩個表tb_member1,tb_member2
DROP table IF EXISTS tb_member1;
create table tb_member1(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; DROP table IF EXISTS tb_member2;
create table tb_member2(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; //建立tb_member2也可以用下面的語句 create table tb_member2 like tb_member1;
3,建立主表tb_member
DROP table IF EXISTS tb_member;
create table tb_member(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MERGE UNION=(tb_member1,tb_member2) INSERT_METHOD=LAST CHARSET=utf8 AUTO_INCREMENT=1 ;
檢視一下tb_member表的結構:desc tb_member;
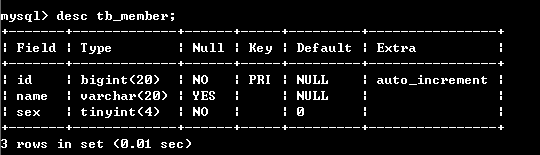
4,接下來,我們把資料分到兩個分表中去:
insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0;
insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1;
檢視一下主表的資料:select * from tb_member;
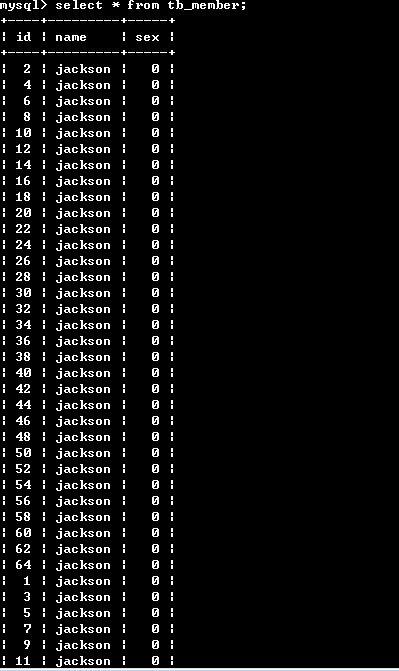
注意:總表只是一個外殼,存取資料發生在一個一個的分表裡面。
ps:建立主表時可能會出現下面的錯誤:
ERROR 1168 (HY000): Unable to open underlying table which is differently defined
or of non-MyISAM type or doesn't exist
若遇到上面這種錯誤,一般從兩方面來排查:(從這兩方面一般可以解決這個問題,本人也遇到了。)
1,檢視上面的分表資料庫引擎是不是MyISAM.
2,檢視分表與指標的欄位定義是否一致。
分表的大概過程和步驟就是這樣的,下面我們來看看分表的演算法實現:
假設現在有一個應用系統可能會有100億的使用者量,另外一個表一般儲存量在不超過100萬的時候基本能保持良好效能,計算下來,我們需要1萬張表,即分表為1萬個表。
我們可以設計成:user_0~user_9999
在使用者表裡面我們有唯一的標示是使用者id,我們尅設計一個小演算法來實現使用者id與訪問表名的對應:
function getTable($id)
{
return 'user_'.sprintf('%d',($id >>20));
}
解釋一下:($id >> 20)表示將向右移位20位,(向右移動一位標示減少一半),printf('%d',$data)標示將資料按照十進位制輸出。
即id為1~1048575(2的20次冪-1)時均訪問user_0,1048576~2097152時訪問user_1,以此類推.....
那麼問題來了,如果使用者更多怎麼辦,現在需要一個可擴充套件的方法:
function getTable($id,$bit,$seed){ return 'user_'.sprintf('%0{$bit}d',($id >> $seed));}其中:$id為使用者id,$bit標示表字尾的位數,$seed表示要移位的位數即:單個表能儲存的記錄條數。這樣就可以任意分表了。總結: 其實上面我們介紹的是水平分表的實施方法,還存在另一種方法叫做:垂直分表 垂直分表: 舉例說明,在一個部落格系統中,文章標題,作者,分類,建立時間等,是變化頻率慢,查詢次數多,而且最好有很好的實時性的資料,我們把它叫做冷資料。而部落格的瀏覽量,回覆數等,類似的統計資訊,或者別的變化頻率比較高的資料,我們把它叫做活躍資料。
我們進行縱向分表後:
1,儲存引擎的使用不同,冷資料使用MyIsam 可以有更好的查詢資料。活躍資料,可以使用Innodb ,可以有更好的更新速度。
2,對冷資料進行更多的從庫配置,因為更多的操作是查詢,這樣來加快查詢速度。對熱資料,可以相對有更多的主庫的橫向分表處理。
3,對於一些特殊的活躍資料,也可以考慮使用memcache ,redis之類的快取,等累計到一定量再去更新資料庫.
相關推薦
mysql實現分表
專案開發中,我們的資料庫資料越來越大,隨之而來的是單個表中資料太多。以至於查詢書讀變慢,而且由於表的鎖機制導致應用操作也搜到嚴重影響,出現了資料庫效能瓶頸。當出現這種情況時,我們可以考慮分表,即將單個數據庫表進行拆分,拆分成多個數據表,然後使用者訪問的時候,根據一定的演算法,
MySQL Merge引擎實現分表
mysql 分表 merge存儲引擎 Merge引擎是一組MyISAM表的組合,組合的分表結構必須完全相同,Merge表本身沒有數據,對Merge表的操作實際上都是對子表的操作,只是對APP來說是透明的,在插入的時候默認是插入到最後一張表上,也可以指定插入到第一張表上,Merger表實際上只是多個
實現MySQL分庫分表備份的腳本
linux 運維 linux運維工程師1)準備測試數據:通過寫腳本批量建庫建表並插入測試數據。[root@aliyun scripts]# cat ceshi.sh #/bin/bashPATH="/usr/local/mysql/bin:$PATH" #定
使用淘寶中介軟體cobar實現mysql分庫分表
cobar 編譯安裝配置筆記 https://github.com/alibaba/cobar windows下使用eclipse匯入cobar專案,eclipse File -> Import -> Git https://github.com/alibab
使用Mysql Merge儲存引擎實現分表
對於資料量很大的一張表,i/o效率底下,分表勢在必行! 使用程式分,對不同的查詢,分配到不同的子表中,是個解決方案,但要改程式碼,對查詢不透明。 好在MySQL 有兩個解決方案: Partition(分割槽,在mysql 5.1.中實現) 和 Mysql Merge
mysql資料庫分表及實現---MERGE分表法
檢視一下tb_member表的結構:desc tb_member; 4,接下來,我們把資料分到兩個分表中去: insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0; insert into tb_me
mysql資料庫分表及實現
專案開發中,我們的資料庫資料越來越大,隨之而來的是單個表中資料太多。以至於查詢書讀變慢,而且由於表的鎖機制導致應用操作也搜到嚴重影響,出現了資料庫效能瓶頸。 當出現這種情況時,我們可以考慮分表,即將單個數據庫表進行拆分,拆分成多個數據表,然後使用者訪問的時候,根據一
你們要的MyCat實現MySQL分庫分表來了
❝ 藉助MyCat來實現MySQL的分庫分表落地,沒有實現過的,或者沒了解過的可以看看 ❞ 前言 在之前寫過一篇關於mysql分庫分表的文章,那篇文章只是給大家提供了一個思路,但是回覆下面有很多說是細節問題沒有提到。所以咔咔就在出了這篇文章。 本文只是針對其中的一個細節而已,比如如何落地MySQL的分庫分表,
MySQL分庫分表備份腳本
數據庫備份數據庫腳本[[email protected]/* */ script]# cat store_backup.sh #!/bin/shMYUSER=rootMYPASS=qwe123SOCKET=/data/3306/mysql.sockMYLOGIN="mysql -u$MYUSER
MySQL分庫分表方案
人員 有趣的 而不是 其他 代理 延時 分片 -o 得到 1. MySQL分庫分表方案 1.1. 問題: 1.2. 回答: 1.2.1. 最好的切分MySQL的方式就是:除非萬不得已,否則不要去幹它。 1.2.2. 你的SQL語句不再是聲明式的(declarativ
mysql 垂直分表技術的實戰演練,有實戰代碼。
主表 實戰 AD tab 進行 輸入 case 多個 兩張 垂直分表技術 垂直分割指的是:表的記錄並不多,但是字段卻很長,表占用空間很大,檢索表的時候需要執行大量的IO,嚴重降低了性能。這時需要把大的字段拆分到另一個表,並且該表與原表是一對一的關系。 1,垂直分表技術首先要
mysql 分庫分表(水平切割和垂直切割)
edi redis 就是 什麽 AR tail 創建 god 分割 分表是分散數據庫壓力的好方法。 分表,最直白的意思,就是將一個表結構分為多個表,然後,可以再同一個庫裏,也可以放到不同的庫。 當然,首先要知道什麽情況下,才需要分表。個人覺得單表記錄條數達到百萬到千萬級別時
【分庫、分表】MySQL分庫分表方案
分表 性能 正常 事先 AD 現在 新用戶 我們 java 一、Mysql分庫分表方案 1.為什麽要分表: 當一張表的數據達到幾千萬時,你查詢一次所花的時間會變多,如果有聯合查詢的話,我想有可能會死在那兒了。分表的目的就在於此,減小數據庫的負擔,縮短查詢時間。 mys
MySQL分庫分表
ref 點擊 ace 技術 HERE atom hash 部分 function 相關文章: 1、 使用Spring AOP實現MySQL數據庫讀寫分離案例分析 2、MySQL5.6 數據庫主從(Master/Slave)同步安裝與配置詳解 3、MySQL主從復制的常
MySQL 分庫分表方案,總結的非常好!
導致 一個 磁盤空間 所有 bsp 功能 編程 從庫 框架 前言 公司最近在搞服務分離,數據切分方面的東西,因為單張包裹表的數據量實在是太大,並且還在以每天60W的量增長。 之前了解過數據庫的分庫分表,讀過幾篇博文,但就只知道個模糊概念, 而且現在回想起來什麽都是模模糊糊的
oracle遷移到mysql分庫分表方案之——ogg(goldengate)
apply columns version alt ML -c testing name sam 之前文章主要介紹了oracle 遷移到mysql,主要是原表原結構遷移,但是實際運維中會發現,到mysql以後需要分庫和分表的拆分操作,這個時候,用ogg來做,也是很強大好用的
MySQL的分表與分區
創建 alter 讀寫 created 例如 mysq 不能 eth art MySQL分表分區是解決大數據量導致MySQL性能低下的兩種方法。 什麽是MySQL分表 從表面意思上看,MySQL分表就是將一個表分成多個表,數據和數據結構都有可能會變。MySQL分表分為垂直分
利用Sharding-Jdbc實現分表
利用Sharding-Jdbc實現分表 由 匿名 (未驗證) 提交於 2018-07-25 15:50:57 132 次瀏覽 閒來無事,喜歡研究一些自己未接觸過的技術~ 看到了噹噹開源的Sharding-JDBC元件,它可以在幾乎不修改程式碼的情況下完成
mysql資料庫分表時,使用mybatis動態設定表名
mybatis中傳遞引數一般使用#{},但是當引數是表名時#{}就會報錯。這是為啥呢? 這是因為#{ } 解析為一個 JDBC 預編譯語句(prepared statement)的引數標記符。 簡單來講:select * from user_#{tableVersion} 會被解析為
mysql實現成績表中成績的排名
有這樣的一個表: 如果兩個分數相同,則兩個分數排名(Rank)相同平分後的下一個名次應該是下一個連續的整數值。 因此,名次之間不應該有“間隔”! 此時有2種方法: 第一: select grade, (select count(distinct grade) from class3 w