
Spark Streaming從Flume Poll資料案例實戰和內幕原始碼解密
本博文內容主要包括以下幾點內容:
1、Spark Streaming on Polling from Flume實戰
2、Spark Streaming on Polling from Flume原始碼
一、推模式(Flume push SparkStreaming)與拉模式(SparkStreaming poll Flume)比較 :
採用推模式:推模式的理解就是Flume作為快取,存有資料。監聽對應埠,如果服務可以連結,就將資料push過去。(簡單,耦合要低),缺點是SparkStreaming 程式沒有啟動的話,Flume端會報錯,同時可能會導致Spark Streaming 程式來不及消費的情況。
採用拉模式:拉模式就是自己定義一個sink,SparkStreaming自己去channel裡面取資料,根據自身條件去獲取資料,穩定性好。
二、Flume poll 實戰:
1.Flume poll 配置
2、將下載後的三個jar包放入Flume安裝lib目錄:
3、配置Flume conf環境引數:
首先進入此入境
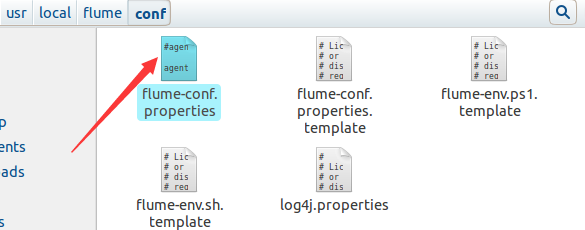
接下來在此檔案中的sink1中新增此內容:
agent1.sinks.sink1.type = org.apache.spark.streaming.flume.sink.SparkSink
agent1.sinks.sink1.hostname = Master
agent1.sinks 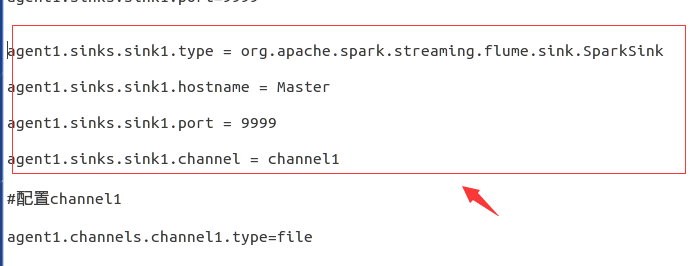
三、編寫程式碼:
public class SkarkStreamingPollDataFromFlume {
public static void main(String[] args) {
/*
* 第一步:配置SparkConf:
* 1,至少2條執行緒:因為Spark Streaming應用程式在執行的時候,至少有一條
* 執行緒用於不斷的迴圈接收資料,並且至少有一條執行緒用於處理接受的資料(否則的話無法
* 有執行緒用於處理資料,隨著時間的推移,記憶體和磁碟都會不堪重負);
* 2,對於叢集而言,每個Executor一般肯定不止一個Thread,那對於處理Spark Streaming的
* 應用程式而言,每個Executor一般分配多少Core比較合適?根據我們過去的經驗,5個左右的
* Core是最佳的(一個段子分配為奇數個Core表現最佳,例如3個、5個、7個Core等);
*/ 啟動HDFS叢集:
啟動執行Flume:
啟動eclipse下的應用程式:
copy測試檔案hellospark.txt到Flume flume-conf.properties配置檔案中指定的/usr/local/flume/tmp/TestDir目錄下:
隔24秒後可以在eclipse程式控制臺中看到上傳的檔案單詞統計結果。
四:原始碼分析:
1、建立createPollingStream (FlumeUtils.scala ):
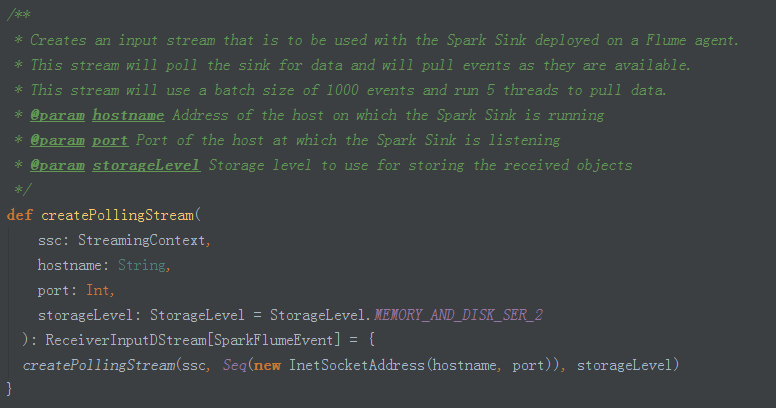
2、引數配置:預設的全域性引數,private 級別配置無法修改:
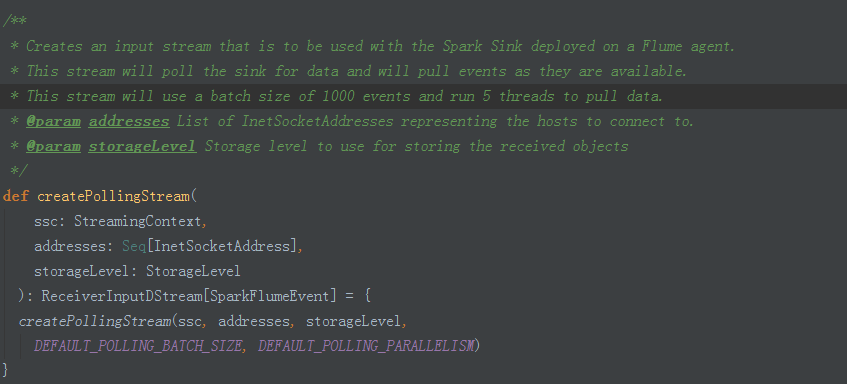
3、建立FlumePollingInputDstream物件
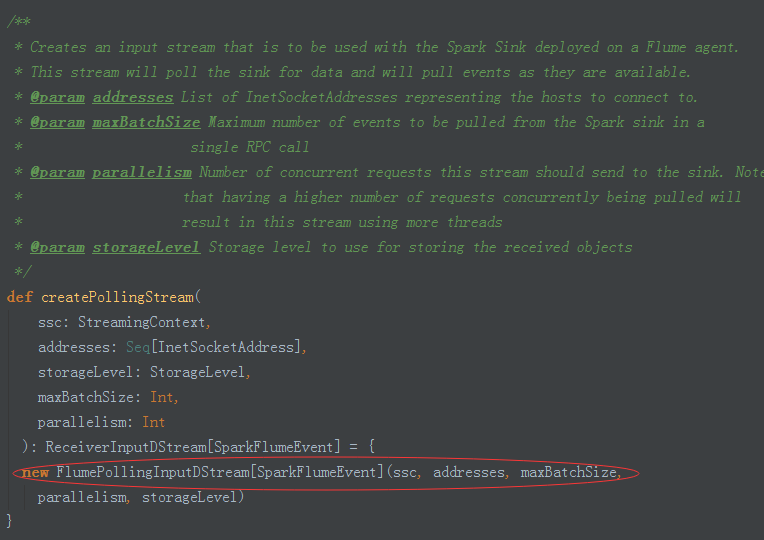
4、繼承自ReceiverInputDstream並覆寫getReciver方法,呼叫FlumePollingReciver介面:
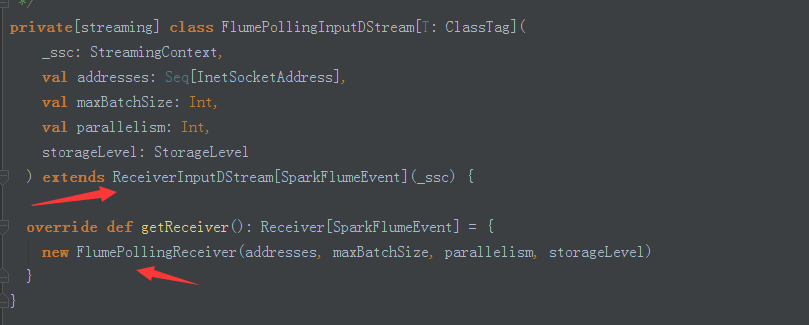
5、ReceiverInputDstream 構建了一個執行緒池,設定為後臺執行緒;並使用lazy和工廠方法建立執行緒和NioClientSocket(NioClientSocket底層使用NettyServer的方式)
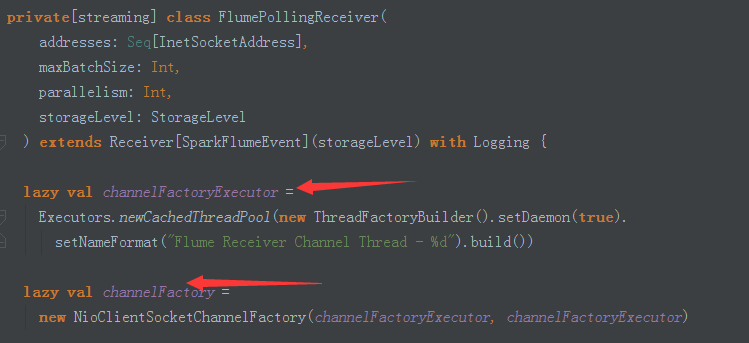
6、receiverExecutor 內部也是執行緒池;connections是指連結分散式Flume叢集的FlumeConnection實體控制代碼的個數,執行緒拿到實體控制代碼訪問資料。

7、啟動時建立NettyTransceiver,根據並行度(預設5個)迴圈提交FlumeBatchFetcher
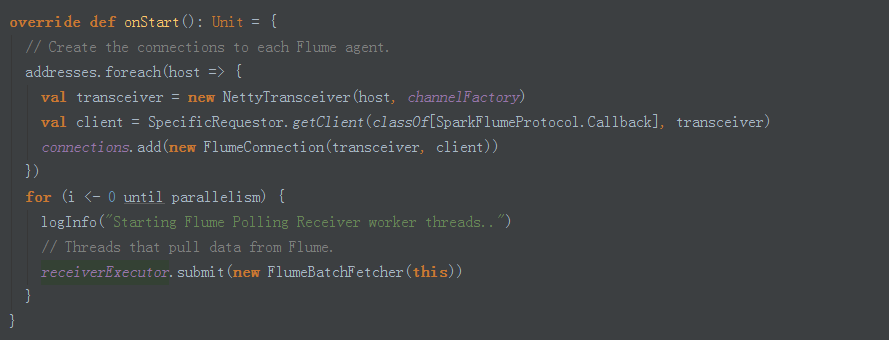
8、FlumeBatchFetcher run方法中從Receiver中獲取connection連結控制代碼ack跟訊息確認有關
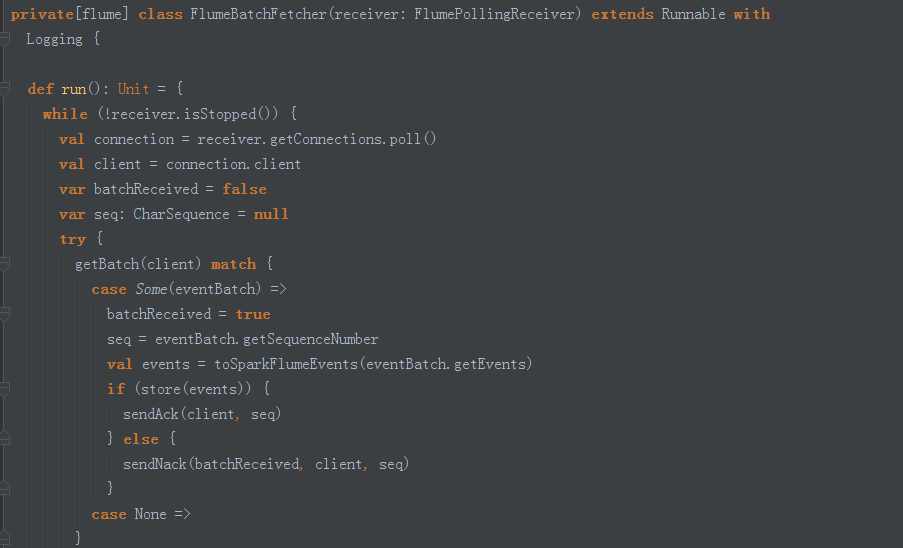
9、獲取一批一批資料方法
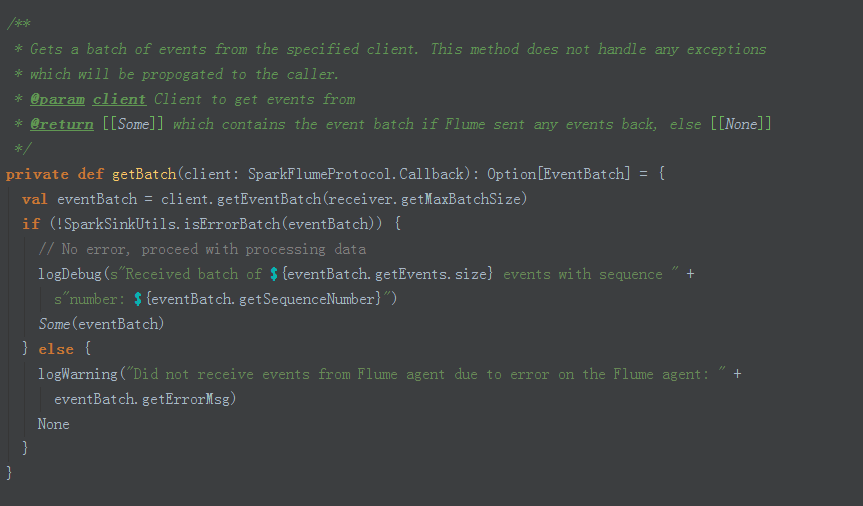
補充說明:
使用Spark Streaming可以處理各種資料來源型別,如:資料庫、HDFS,伺服器log日誌、網路流,其強大超越了你想象不到的場景,只是很多時候大家不會用,其真正原因是對Spark、spark streaming本身不瞭解。
博文內容源自DT大資料夢工廠Spark課程。相關課程內容視訊可以參考:
百度網盤連結:http://pan.baidu.com/s/1slvODe1(如果連結失效或需要後續的更多資源,請聯絡QQ460507491或者微訊號:DT1219477246 獲取上述資料)。
相關推薦
Spark Streaming從Flume Poll資料案例實戰和內幕原始碼解密
本博文內容主要包括以下幾點內容: 1、Spark Streaming on Polling from Flume實戰 2、Spark Streaming on Polling from Flume原始碼 一、推模式(Flume push SparkStre
大資料IMF傳奇行動絕密課程第87課:Flume推送資料到Spark Streaming案例實戰和內幕原始碼解密
Flume推送資料到Spark Streaming案例實戰和內幕原始碼解密 1、Flume on HDFS案例回顧 2、Flume推送資料到Spark Streaming實戰 3、原理繪圖剖析 一、配置.bashrc vi ~/.bashrc
第87課:Flume推送資料到SparkStreaming案例實戰和內幕原始碼解密--flume安裝篇
1、 下載flume 老師提供的包 2、 安裝 vi/etc/profile exportFLUME_HOME=/usr/local/apache-flume-1.6.0-bin exportPATH=.:$PATH:$JAVA_HOME/bin:$HADOOP
第91課:SparkStreaming基於Kafka Direct案例實戰和內幕原始碼解密 java.lang.ClassNotFoundException 踩坑解決問題詳細內幕版本
第91課:SparkStreaming基於Kafka Direct案例實戰和內幕原始碼解密 /* * *王家林老師授課http://weibo.com/ilovepains */ 每天晚上20:00YY頻道現場授課頻道68917580 1、作業內容:SparkS
Spark Streaming整合flume(Poll方式和Push方式)
flume作為日誌實時採集的框架,可以與SparkStreaming實時處理框架進行對接,flume實時產生資料,sparkStreaming做實時處理。 Spark Streaming對接FlumeNG有兩種方式,一種是FlumeNG將訊息Push推給Spark Streaming,還
0073 spark streaming從埠接受資料進行實時處理的方法
一,環境 Windows_x64 系統 Java1.8 Scala2.10.6 spark1.6.0 hadoop2.7.5 IDEA IntelliJ 2017.2 nmap工具(用到其中的nc
SparkStreaming 從Flume Poll資料
1.官網資料 2.需要下載相關依賴到flume的lib中 3.配置flume的配置檔案 #agent1表示代理名稱 agent1.sources=source1 agent1.sinks=sink1 agent1.channels=channel1 #配置source
Spark Streaming整合flume實戰
Spark Streaming對接Flume有兩種方式 Poll:Spark Streaming從flume 中拉取資料 Push:Flume將訊息Push推給Spark Streaming 1、安裝flume1.6以上 2、下載依賴包 spark-streaming
spark筆記之Spark Streaming整合flume實戰
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.
spark Streaming 直接消費Kafka資料,儲存到 HDFS 實戰程式設計實踐
最近在學習spark streaming 相關知識,現在總結一下 主要程式碼如下 def createStreamingContext():StreamingContext ={ val sparkConf = new SparkConf().setAppName("
Spark Streaming從Kafka中獲取資料,並進行實時單詞統計,統計URL出現的次數
1、建立Maven專案 2、啟動Kafka 3、編寫Pom檔案 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.or
Spark Streaming從Kafka中獲取數據,並進行實時單詞統計,統計URL出現的次數
scrip 發送消息 rip mark 3.2 umt 過程 bject ttr 1、創建Maven項目 創建的過程參考:http://blog.csdn.net/tototuzuoquan/article/details/74571374 2、啟動Kafka A:安裝ka
spark streaming從指定offset處消費Kafka數據
tpc asi 4.2 nes 配置 sof 我們 erl examples spark streaming從指定offset處消費Kafka數據 2017-06-13 15:19 770人閱讀 評論(2) 收藏 舉報 分類: spark(5) 原文地址:htt
PK2227-Spark Streaming實時流處理項目實戰
con ans filesize strip for 新年 感覺 post pre PK2227-Spark Streaming實時流處理項目實戰 新年伊始,學習要趁早,點滴記錄,學習就是進步! 隨筆背景:在很多時候,很多入門不久的朋友都會問我:我是從其他語言轉到程序
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記三之銘文升級版
聚集 配置文件 ssi path fig rect 擴展 str 控制臺 銘文一級: Flume概述Flume is a distributed, reliable, and available service for efficiently collecting(收集),
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記五之銘文升級版
環境變量 local server 節點數 replicas conn 配置環境 park 所有 銘文一級: 單節點單broker的部署及使用 $KAFKA_HOME/config/server.propertiesbroker.id=0listenershost.name
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記九之銘文升級版
file sin ssi 右上角 result map tap 核心 內容 銘文一級: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { th
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十之銘文升級版
state 分鐘 mooc 系統數據 使用 連接 var style stream 銘文一級: 第八章:Spark Streaming進階與案例實戰 updateStateByKey算子需求:統計到目前為止累積出現的單詞的個數(需要保持住以前的狀態) java.lang.I
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十五之銘文升級版
spa for 序列 html art mat div pre paths 銘文一級:[木有筆記] 銘文二級: 第12章 Spark Streaming項目實戰 行為日誌分析: 1.訪問量的統計 2.網站黏性 3.推薦 Python實時產生數據 訪問URL->IP
【慕課網實戰】Spark Streaming實時流處理項目實戰筆記十六之銘文升級版
.so zook orm 3.1 date nta highlight org 結果 銘文一級: linux crontab 網站:http://tool.lu/crontab 每一分鐘執行一次的crontab表達式: */1 * * * * crontab -e */1