
tensorflow載入資料的三種方式
Tensorflow資料讀取有三種方式:
- Preloaded data: 預載入資料
- Feeding: Python產生資料,再把資料餵給後端。
- Reading from file: 從檔案中直接讀取
這三種有讀取方式有什麼區別呢? 我們首先要知道TensorFlow(TF)是怎麼樣工作的。
TF的核心是用C++寫的,這樣的好處是執行快,缺點是呼叫不靈活。而Python恰好相反,所以結合兩種語言的優勢。涉及計算的核心運算元和執行框架是用C++寫的,並提供API給Python。Python呼叫這些API,設計訓練模型(Graph),再將設計好的Graph給後端去執行。簡而言之,Python的角色是Design,C++是Run。
一、預載入資料:
import tensorflow as tf
# 設計Graph
x1 = tf.constant([2, 3, 4])
x2 = tf.constant([4, 0, 1])
y = tf.add(x1, x2)
# 開啟一個session --> 計算y
with tf.Session() as sess:
print sess.run(y)二、python產生資料,再將資料餵給後端
說明:在這裡x1, x2只是佔位符,沒有具體的值,那麼執行的時候去哪取值呢?這時候就要用到import tensorflow as tf # 設計Graph x1 = tf.placeholder(tf.int16) x2 = tf.placeholder(tf.int16) y = tf.add(x1, x2) # 用Python產生資料 li1 = [2, 3, 4] li2 = [4, 0, 1] # 開啟一個session --> 喂資料 --> 計算y with tf.Session() as sess: print sess.run(y, feed_dict={x1: li1, x2: li2})
sess.run()中的feed_dict引數,將Python產生的資料餵給後端,並計算y。這兩種方案的缺點:
1、預載入:將資料直接內嵌到Graph中,再把Graph傳入Session中執行。當資料量比較大時,Graph的傳輸會遇到效率問題。
2、用佔位符替代資料,待執行的時候填充資料。
前兩種方法很方便,但是遇到大型資料的時候就會很吃力,即使是Feeding,中間環節的增加也是不小的開銷,比如資料型別轉換等等。最優的方案就是在Graph定義好檔案讀取的方法,讓TF自己去從檔案中讀取資料,並解碼成可使用的樣本集。
三、從檔案中讀取,簡單來說就是將資料讀取模組的圖搭好
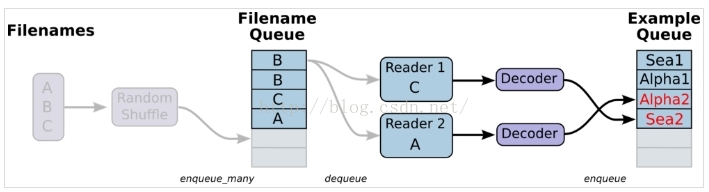
1、準備資料,構造三個檔案,A.csv,B.csv,C.csv
$ echo -e "Alpha1,A1\nAlpha2,A2\nAlpha3,A3" > A.csv
$ echo -e "Bee1,B1\nBee2,B2\nBee3,B3" > B.csv
$ echo -e "Sea1,C1\nSea2,C2\nSea3,C3" > C.csv2、單個Reader,單個樣本
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一個先入先出佇列和一個QueueRunner,生成檔名佇列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定義Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定義Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
#example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 執行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #建立一個協調器,管理執行緒
threads = tf.train.start_queue_runners(coord=coord) #啟動QueueRunner, 此時檔名佇列已經進隊。
for i in range(10):
print example.eval(),label.eval()
coord.request_stop()
coord.join(threads)
Alpha1 A2
Alpha3 B1
Bee2 B3
Sea1 C2
Sea3 A1
Alpha2 A3
Bee1 B2
Bee3 C1
Sea2 C3
Alpha1 A2
解決方案:用tf.train.shuffle_batch,那麼生成的結果就能夠對應上。
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一個先入先出佇列和一個QueueRunner,生成檔名佇列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定義Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定義Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 執行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #建立一個協調器,管理執行緒
threads = tf.train.start_queue_runners(coord=coord) #啟動QueueRunner, 此時檔名佇列已經進隊。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
3、單個Reader,多個樣本,主要也是通過tf.train.shuffle_batch來實現
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()會多加了一個樣本佇列和一個QueueRunner。
#Decoder解後資料會進入這個佇列,再批量出隊。
# 雖然這裡只有一個Reader,但可以設定多執行緒,相應增加執行緒數會提高讀取速度,但並不是執行緒越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)說明:下面這種寫法,提取出來的batch_size個樣本,特徵和label之間也是不同步的
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()會多加了一個樣本佇列和一個QueueRunner。
#Decoder解後資料會進入這個佇列,再批量出隊。
# 雖然這裡只有一個Reader,但可以設定多執行緒,相應增加執行緒數會提高讀取速度,但並不是執行緒越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval(), label_batch.eval()
coord.request_stop()
coord.join(threads)
['Alpha1'
'Alpha2' 'Alpha3' 'Bee1' 'Bee2'] ['B3' 'C1' 'C2' 'C3' 'A1']
['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3'] ['C1' 'C2' 'C3' 'A1' 'A2']
['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1'] ['C2' 'C3' 'A1' 'A2' 'A3']
4、多個reader,多個樣本
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定義了多種解碼器,每個解碼器跟一個reader相連
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader設定為2
# 使用tf.train.batch_join(),可以使用多個reader,並行讀取資料。每個Reader使用一個執行緒。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
tf.train.batch與tf.train.shuffle_batch函式是單個Reader讀取,但是可以多執行緒。tf.train.batch_join與tf.train.shuffle_batch_join可設定多Reader讀取,每個Reader使用一個執行緒。至於兩種方法的效率,單Reader時,2個執行緒就達到了速度的極限。多Reader時,2個Reader就達到了極限。所以並不是執行緒越多越快,甚至更多的執行緒反而會使效率下降。5、迭代控制,設定epoch引數,指定我們的樣本在訓練的時候只能被用多少輪
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
#num_epoch: 設定迭代數
filename_queue = tf.train.string_input_producer(filenames, shuffle=False,num_epochs=3)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定義了多種解碼器,每個解碼器跟一個reader相連
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader設定為2
# 使用tf.train.batch_join(),可以使用多個reader,並行讀取資料。每個Reader使用一個執行緒。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=1)
#初始化本地變數
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop():
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
except tf.errors.OutOfRangeError:
print('Epochs Complete!')
finally:
coord.request_stop()
coord.join(threads)
coord.request_stop()
coord.join(threads)
在迭代控制中,記得新增
tf.initialize_local_variables(),官網教程沒有說明,但是如果不初始化,執行就會報錯。=========================================================================================對於傳統的機器學習而言,比方說分類問題,[x1 x2 x3]是feature。對於二分類問題,label經過one-hot編碼之後就會是[0,1]或者[1,0]。一般情況下,我們會考慮將資料組織在csv檔案中,一行代表一個sample。然後使用佇列的方式去讀取資料
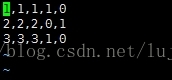
說明:對於該資料,前三列代表的是feature,因為是分類問題,後兩列就是經過one-hot編碼之後得到的label
使用佇列讀取該csv檔案的程式碼如下:
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一個先入先出佇列和一個QueueRunner,生成檔名佇列
filenames = ['A.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定義Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定義Decoder
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1, col2, col3])
label = tf.pack([col4,col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=2, capacity=200, min_after_dequeue=100, num_threads=2)
# 執行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #建立一個協調器,管理執行緒
threads = tf.train.start_queue_runners(coord=coord) #啟動QueueRunner, 此時檔名佇列已經進隊。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
輸出結果如下:
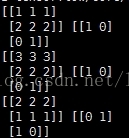
說明:
record_defaults = [[1], [1], [1], [1], [1]]相關推薦
vue-cli專案路由懶載入的三種方式
閒嘮嗑幾句 今天公司有新的專案要開展,需要重新部署新的專案,所以說以前好多忘記的東西,又得重新撿起來一遍,配置路由的時候發現還是使用的普通的使用require懶載入路由,所以在檢視文件和資料後又重新總結了一遍,以加深記憶和方便下次查閱。 一、使用import非同步引入
JS非同步載入的三種方式
非同步載入又叫非阻塞載入,瀏覽器在下載執行js的同時,還會繼續進行後續頁面的處理。主要有三種方式。 方法一:也叫Script DOM Element (function(){ var scriptEle = document.createElement("script"); script
tensorflow載入資料的三種方式 之 TF生成資料的方法
Tensorflow資料讀取有三種方式: Preloaded data: 預載入資料 Feeding: Python產生資料,再把資料餵給後端。 Reading from file: 從檔案中直接讀取 具體可以參考:極客學院的資料讀取 這裡介紹下:
tensorflow載入資料的三種方式
Tensorflow資料讀取有三種方式: Preloaded data: 預載入資料Feeding: Python產生資料,再把資料餵給後端。Reading from file: 從檔案中直接讀取 這三種有讀取方式有什麼區別呢? 我們首先要知道TensorFlow(TF)
TensorFlow基礎3:資料讀取的三種方式
‘在講述在TensorFlow上的資料讀取方式之前,有必要了解一下TensorFlow的系統架構,如下圖所示: TensorFlow的系統架構分為兩個部分: 前端系統:提供程式設計模型,負責構造計算圖; 後端系統:提供執行時環境,負責執行計算圖。
tensorflow載入資料的幾種方式
http://wiki.jikexueyuan.com/project/tensorflow-zh/how_tos/reading_data.html#QueueRunner http://wiki.jikexueyuan.com/project/tensorflow-zh
struts2資料載入到頁面的三種方式
sruts2的資料共享的三種方式: 在web專案中都是使用域物件來共享資料。 struts2提供給開發者使用域物件來共享資料的方法一共有三種。 6.1 第一種方式 ServletActionContext類 getRequest() : 獲取request物件 getReq
TensorFlow中讀取影象資料的三種方式
本文面對三種常常遇到的情況,總結三種讀取資料的方式,分別用於處理單張圖片、大量圖片,和TFRecorder讀取方式。並且還補充了功能相近的tf函式。 1、處理單張圖片 我們訓練完模型之後,常常要用圖片測試,有的時候,我們並不需要對很多影象做測試,可能就是幾張甚至一張。這種情況下沒有必要用佇列機制。
ASP.NET中 C#訪問資料庫用三種方式顯示資料表
第一種方式:使用DataReader從資料庫中每次提取一條資料,用迴圈遍歷表 下面是我寫的一個例子: &nbs
TensorFlow載入資料的方式
tensorflow作為符號程式設計框架,需要先構建資料流圖,再讀取資料,然後再進行訓練。tensorflow提供了以下三種方式來載入資料: 預載入資料(preloaded data):在tensorflow圖中定義常量或變數來儲存所有資料 填充資料(feeding):Pytho
JS資料交換的三種方式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> <script> //第一個思
MyBatis 延遲載入的三種載入方式深入,你get了嗎?
延遲載入 延遲載入對主物件都是直接載入,只有對關聯物件是延遲載入。 延遲載入可以減輕資料庫的壓力, 延遲載入不可是一條SQL查詢多表資訊,這樣構不成延遲載入,會形成直接載入。 延遲載入分為三種類型: 1.直接載入 執行完主物件之後,直接執行關聯物件。 2.侵入式載入 在執行主物
vue webpack 懶載入三種方式
const router = new Router({ routes: [ { path:
vue+element ui專案總結點(一)select、Cascader級聯選擇器、encodeURI、decodeURI轉碼解碼、一級mockjs用法、路由懶載入三種方式
不多說上程式碼: <template> <div class="hello"> <h1>{{ msg }}</h1> <p>Element UI簡單Cascader級聯選擇器使用</p> <
讓分割槽表和資料產生關聯的三種方式
目錄 總結: 方式一:上傳資料後新增分割槽alter add: 方式二:上傳資料後修復msck: 方式三:建立資料夾後load資料到分割槽: 總結: 總結: 讓分割槽表和資料產生關聯的方式有三種: ①先在HDFS上建立分割槽的目錄,並上傳資料到該目錄
Mysql 刪除資料表的三種方式
刪除程度可從強到弱如下排列: 1. drop table tb; drop 是直接將表格刪除,無法找回。例如刪除 user 表: drop table user; 2. truncate (table) tb; truncate 是刪除表中所有資
利用Vim進行資料夾對比的三種方式
前言 最近經常使用vim, 心血來潮想研究了一下如何用Vim進行程式碼merge. 在Windows下有Beyond Compare和WinMerge等軟體,可以比較兩個目錄結構及檔案內容的異同,並以圖形介面的形式呈現給使用者。Vim有的vimdiff可以進行檔
【Android】一、Progress進度條實現的三種方式:主執行緒實現,Service載入,動態建立
前言 更新版本,上傳資料到服務端,都是需要進度顯示的,Android進度顯示兩種方式 ProgressDialog 和 ProgressBar 新版本中ProgressDialog不被推薦使用,所以專案採用ProgressBar 分為三種實現方式: 1、MainAct
前端資料流檔案下載三種方式
1、直接使用get請求方式進行下載: window.open(`${url}?${qs.stringify(param)}`, '_blank'); 2、使用form 表單post請求進行下載: const postDownloadFile = (action, param) =>
struts2獲取前臺傳遞過來的資料的三種方式
struts2獲取前臺傳遞過來的資料可以通過屬性驅動和模型驅動兩種方式獲得。 屬性驅動 1、使用變數的方式 前臺: action: action中要獲得前臺傳遞過來的account和password兩個引數的資料。那麼就必須在action中設定和前臺na