
Unicode與多字符集簡介
多字符集:又稱ANSI字符集,多國語言的字符集,但是,其有一個致命的缺點,就是當編碼改變時,ANSI字符集無法將多國的編碼形式放在一起,會出現亂碼。
比如:中國的編碼就是有兩個,GB2312和BIG-5,簡體字使用的是GB2312,繁體字使用的是BIG-5。
很明顯,由於編碼形式的不同,多國語言的編碼放在一起就會出現問題,也就是會出現亂碼。這時候,就有了Unicode編碼的出現了。
Unicode:從字面意思就可以瞭解到,Unicode是統一編碼。
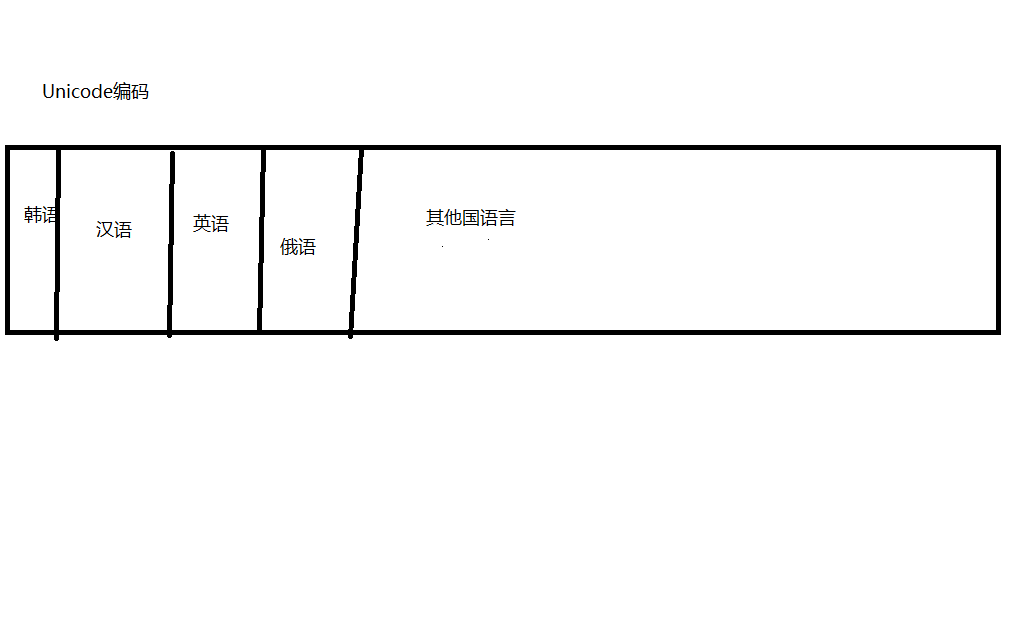
Unicode編碼,將各國語言放在如上的一個65535的列表中,這樣寫入時,就算將不同地區的文字放入,也不會出現亂碼。
兩者的其他區別(VS):
多字符集又稱為窄字元,佔一個位元組。
Unicode又稱為寬位元組,佔兩個位元組。
在VS中只用_T()函式即可自適應。
相關推薦
Unicode與多字符集簡介
多字符集:又稱ANSI字符集,多國語言的字符集,但是,其有一個致命的缺點,就是當編碼改變時,ANSI字符集無法將多國的編碼形式放在一起,會出現亂碼。 比如:中國的編碼就是有兩個,GB2312和BIG-5,簡體字使用的是GB2312,繁體字使用的是BIG-5。很明
unicode WCHAR 與多字符集char相互轉換
多字符集轉UNICODE字符集: //mbs(char) to wcs (CString) //多字符集轉為UNICODE字符集 CString mbs2wcs(LPCSTR mbstr) { CString cstr = L""; size_t aLen = str
UNICODE與多位元組字符集的區別及轉換
一、一點歷史 在計算機中字元通常並不是儲存為影象,每個字元都是使用一個編碼來表示的,而每個字元究竟使用哪個編碼代表,要取決於使用哪個字符集(charset)。 在最初的時候,Internet上只有一種字符集——ANSI的ASCII字符集,它使用7 bits來表示一個字元
unicode與多位元組工程,char與WCHAR_T轉化
#include<string>//標準C++; string tp; wchar_t *s; char *d; tp=s; d=tp.c_str(); 也可使用WideCharToString(wchar_t * Source
MFC中Unicode與多位元組編碼中遇到的CString與char或char*的轉化問題
博主在MFC初期是遇到了一個初學MFC的人很多都會遇到的一個基本問題: 就是Unicode或多位元組字符集下CString和Char的轉化問題。其實這種問題解決的方式很簡單,兩種基本形式記住即可: 1.unicode下,轉換字串形式為_T("HelloWorld"
CString與char*轉換(Unicode和多位元組字符集)
一、使用多位元組字符集 1.CString轉char* (1)傳給未分配記憶體的const char* (LPCTSTR)指標. CString cstr="ABC"; const char* ch
java中的Executors簡介與多執行緒在網站上逐步優化的運用案例
提供Executor的工廠類 忽略了自定義的ThreadFactory、callable和unconfigurable相關的方法 newFixedxxx:在任意時刻,最多有nThreads個執行緒在處理task;如果所有執行緒都在執行時來了新的任務,它會被扔
VS下使用多字符集編碼和Unicode字符集編碼的總結
編寫MFC程式的時候,總遇到字符集轉換的問題,這裡總結一下,方便大家使用。 在多位元組字符集編碼下,設定如下環境: 這時CString與char陣列是可以互相轉換的,而如果改成“使用Unicode字符集”,設定如下: 原來的程式碼就會報很多錯誤,諸如: error C2664: “Cxx
字符集問題(Unicode變為多位元組即能解決)
嚴重性 程式碼 說明 專案 檔案 行 禁止顯示狀態 錯誤 C2664 “void ATL::CStringT<wchar_t,StrTraitMFC<wchar_t,ATL::ChTraitsCRT<wchar
VC++的多字符集和unicode字符集轉換大全(CString轉char*等)
_T的意思是通知編譯器,自行進行字串的多位元組/Unicode轉換。 而L表示,該字串為Unicode版本。http://www.blogjava.net/neumqp/archive/2006/03/09/34504.html 先區別一下字元陣列和字元指標變數 (1)字元陣列
MFC中,Unicode和多位元組字符集下 CString和char的轉化
1.unicode下,轉換字串形式為_T("HelloWorld"); 2.MBCS下,轉換字串的形式為"HelloWorld" 多位元組字符集 (MBCS) 是一種替代 Unicode 以支援無法用單位元組表示的字符集(如日文和中文)的方法。為國際市場程式設計時應考慮
字符集與字元編碼簡介(轉)
我們知道,計算機只能識別諸如0101這樣的二進位制數,於是人們必須以二進位制資料與計算機進行互動,或者先將人類使用的字元按一定規則轉換為二進位制數。 那什麼是字元呢?在計算機領域,我們把諸如文字、標點符號、圖形符號、數字等統稱為字元。而由字元組成的集合則成為字符集,字符集由於
Unicode和多位元組字符集 (MBCS)
最近在使用VS2008編寫一個MFC的工程專案,裡面在專案屬性中字符集的設定中編碼方式有“使用UNICODE”和“使用多位元組”兩種字符集,有時候編譯出錯,更改字符集選項,編譯就通過,於是對這兩種產生了疑問,下面通過一篇轉載的文章向大家介紹一下這兩種方式。 總結一下:
使用Unicode(寬位元組字符集)以及_T與L
關於_T及L _T 會根據你工程的設定自動轉換UNICODE和非UNICODE. L 就是轉為UNICODE Visual C++裡邊定義字串的時候,用_T來保證相容性,是一種資料型別,但是它不會產生結果,被編譯系統的預處理系統來解釋,VC支援ascii和unicode
Python單行註釋與多行註釋
單行 全局 速度 無法 第三方 本質 特性 最小 利用 >>> print "hello,world"hello,world>>> 2+24#單行註釋 """每行代碼的後面可以加上分號,但是不會有任何作用,除非同一行還有更多的代碼,
多進程與多線程
self 睡眠 數據集 另一個 工作 time 表示 print run 什麽是進程? 進程就是一個程序在一個數據集上的一次動態執行過程。 進程一般由程序、數據集、進程控制塊三部分組成。我們編寫的程序用來描述進程要完成哪些功能以及如何完成;數據集則是程序在執行過程中所需要使
ontimer 與多線程
font cas mfc 同時 size run 開啟 exe int 一般來說,在MFC中開啟一個UI線程可以用以下代碼: m_pCameraThread = AfxBeginThread(RUNTIME_CLASS(CCameraThread)); if (!m_pC
8.繼承、覆蓋、重載與多態
auto 區別 再次 cor c++ java接口 睡覺 它的 其中 1. 繼承 1.1 繼承的概念 1.1.1 概念 繼承是java面向對象編程技術的一塊基石,因為它允許創建分等級層次的類。 繼承就是子類繼承父類的特征和行為,使得子類對象(實例)具有父類的實例域和方法,或
PHP面向對象詳解:繼承、封裝與多態
gets key copy nes col 成員變量 ret 封裝 文字 首先,在解釋面向對象之前先解釋下什麽是面向對象? [面向對象]1、什麽是類? 具有相同屬性(特征)和方法(行為)的一系列個體的集合,類是一個抽象的概念2、什麽是對象?從類中拿到的具有具體屬性值得個體,
[面向對象雜談]接口與多態
定義變量 img 面向對象編程 oop 陌生 繼承 工作 中學 mage 人總是很忙的,但是一個人就是一個人,不存在分身術。 假設有個人王大柱,他是光明中學的校長,還是光明村的村委會成員,同時還是他兒子的父親。 那麽我們可以這麽想:王大柱是一個類的具體的實現對象,這類名叫“