
RoaringBitmap資料結構及原理
首先

每個RoaringBitmap(GitHub連結)中都包含一個RoaringArray,名字叫highLowContainer。
highLowContainer儲存了RoaringBitmap中的全部資料。
RoaringArray highLowContainer;這個名字意味著,會將32位的整形(int)拆分成高16位和低16位兩部分(兩個short)來處理。
RoaringArray的資料結構很簡單,核心為以下三個成員:
short[] keys;
Container[] values;
int size;每個32位的整形,高16位會被作為key儲存到short[] keys
Container[] values中的某個Container中。keys和values通過下標一一對應。size則標示了當前包含的key-value pair的數量,即keys和values中有效資料的數量。
keys陣列永遠保持有序,方便二分查詢。
三種Container
下面介紹到的是RoaringBitmap的核心,三種Container。
通過上面的介紹我們知道,每個32位整形的高16位已經作為key儲存在RoaringArray中了,那麼Container只需要處理低16位的資料。
ArrayContainer
static 結構很簡單,只有一個short[] content,將16位value直接儲存。
short[] content始終保持有序,方便使用二分查詢,且不會儲存重複數值。
因為這種Container儲存資料沒有任何壓縮,因此只適合儲存少量資料。
ArrayContainer佔用的空間大小與儲存的資料量為線性關係,每個short為2位元組,因此儲存了N個數據的ArrayContainer佔用空間大致為2N位元組。儲存一個數據佔用2位元組,儲存4096個數據佔用8kb。
根據原始碼可以看出,常量DEFAULT_MAX_SIZE
BitmapContainer
final long[] bitmap;這種Container使用long[]儲存點陣圖資料。我們知道,每個Container處理16位整形的資料,也就是0~65535,因此根據點陣圖的原理,需要65536個位元來儲存資料,每個位元位用1來表示有,0來表示無。每個long有64位,因此需要1024個long來提供65536個位元。
因此,每個BitmapContainer在構建時就會初始化長度為1024的long[]。這就意味著,不管一個BitmapContainer中只儲存了1個數據還是儲存了65536個數據,佔用的空間都是同樣的8kb。
RunContainer
private short[] valueslength;
int nbrruns = 0;RunContainer中的Run指的是行程長度壓縮演算法(Run Length Encoding),對連續資料有比較好的壓縮效果。
它的原理是,對於連續出現的數字,只記錄初始數字和後續數量。即:
- 對於數列
11,它會壓縮為11,0; - 對於數列
11,12,13,14,15,它會壓縮為11,4; - 對於數列
11,12,13,14,15,21,22,它會壓縮為11,4,21,1;
原始碼中的short[] valueslength中儲存的就是壓縮後的資料。
這種壓縮演算法的效能和資料的連續性(緊湊性)關係極為密切,對於連續的100個short,它能從200位元組壓縮為4位元組,但對於完全不連續的100個short,編碼完之後反而會從200位元組變為400位元組。
如果要分析RunContainer的容量,我們可以做下面兩種極端的假設:
- 最好情況,即只存在一個數據或只存在一串連續數字,那麼只會儲存2個
short,佔用4位元組 - 最壞情況,0~65535的範圍內填充所有的奇數位(或所有偶數位),需要儲存65536個
short,128kb
Container效能總結
讀取時間
只有BitmapContainer可根據下標直接定址,複雜度為O(1),ArrayContainer和RunContainer都需要二分查詢,複雜度O(log n)
記憶體佔用
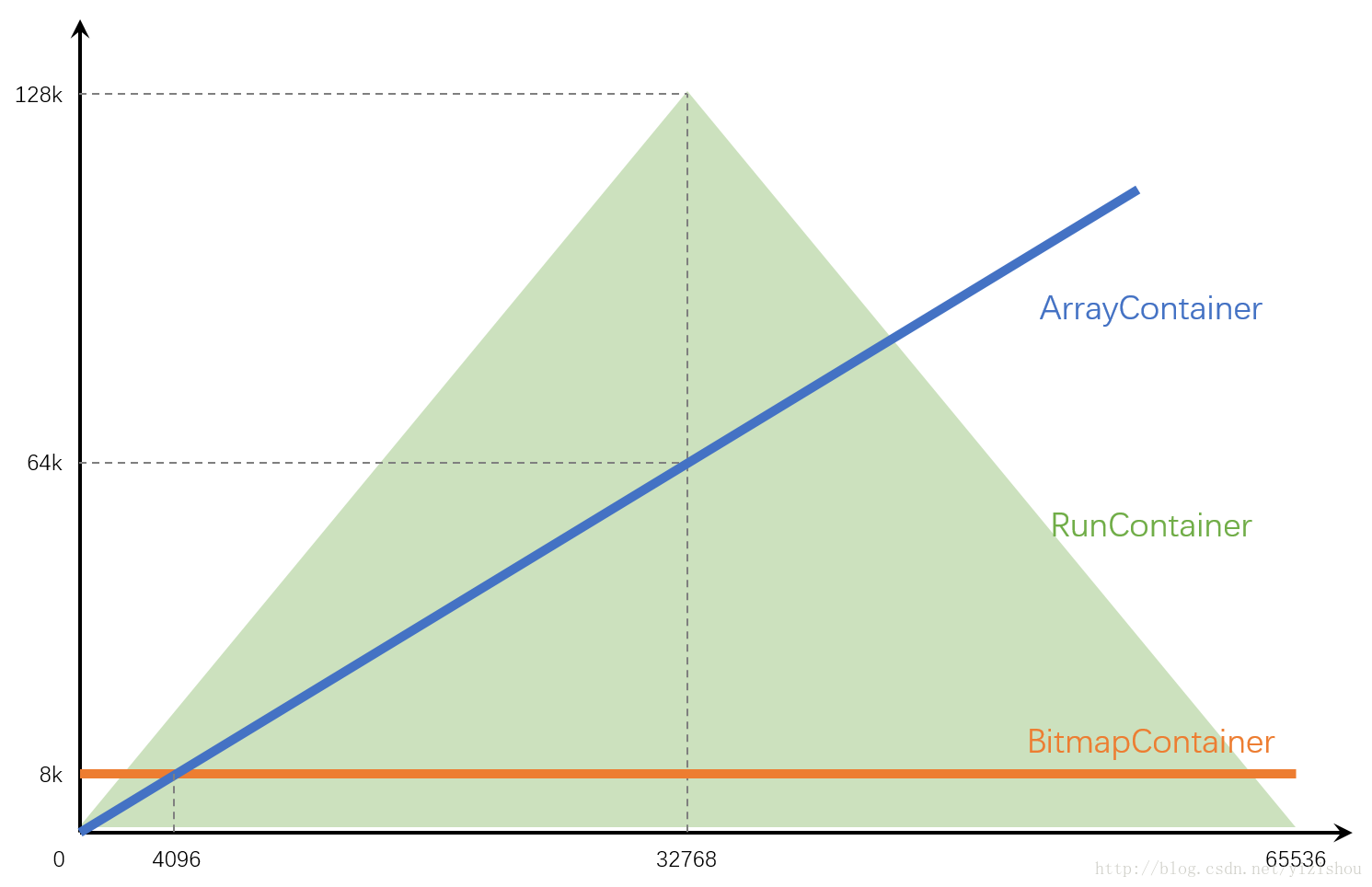
這是我畫的一張圖,大致描繪了各Container佔用空間隨資料量的趨勢。
其中,
- ArrayContainer一直線性增長,在達到4096後就完全比不上BitmapContainer了
- BitmapContainer是一條橫線,始終佔用8kb
- RunContainer比較奇葩,因為和資料的連續性關係太大,因此只能畫出一個上下限範圍。不管資料量多少,下限始終是4位元組;上限在最極端的情況下可以達到128kb。
RoaringBitmap針對Container的優化策略
建立時:
- 建立包含單個值的Container時,選用ArrayContainer
- 建立包含一串連續值的Container時,比較ArrayContainer和RunContainer,選取空間佔用較少的
轉換:
針對ArrayContainer:
- 如果插入值後容量超過4096,則自動轉換為BitmapContainer。因此正常使用的情況下不會出現容量超過4096的ArrayContainer。
- 呼叫runOptimize()方法時,會比較和RunContainer的空間佔用大小,選擇是否轉換為RunContainer。
針對BitmapContainer:
- 如果刪除某值後容量低至4096,則會自動轉換為ArrayContainer。因此正常使用的情況下不會出現容量小於4096的BitmapContainer。
- 呼叫runOptimize()方法時,會比較和RunContainer的空間佔用大小,選擇是否轉換為RunContainer。
針對RunContainer:
- 只有在呼叫runOptimize()方法才會發生轉換,會分別和ArrayContainer、BitmapContainer比較空間佔用大小,然後選擇是否轉換。
以上
相關推薦
RoaringBitmap資料結構及原理
首先 每個RoaringBitmap(GitHub連結)中都包含一個RoaringArray,名字叫highLowContainer。 highLowContainer儲存了RoaringBitmap中的全部資料。 RoaringArray hig
MySQL索引背後的資料結構及原理
摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避免混亂,本文將只關注於BTree索引,因為這是平常使用
圖解 Java 中的資料結構及原理,傻瓜也能看懂!
最近在整理資料結構方面的知識, 系統化看了下Java中常用資料結構, 突發奇想用動畫來繪製資料流轉過程。 主要基於jdk8, 可能會有些特性與jdk7之前不相同, 例如LinkedList LinkedHashMap中的雙向列表不再是迴環的。 HashMap中的單鏈表是尾插, 而不是頭插入等等, 後文
EWAHCompressedBitmap資料結構及原理
本文基於Java版專案javaewah。 首先 首先要知道,EWAHCompressedBitmap是完全基於行程壓縮演算法壓縮的。 結構就是這樣,看起來很簡單。 在構造EWAHCompressedBitmap時,內部會初始化一個Runnin
JAVA常用資料結構及原理分析
java.util包中三個重要的介面及特點:List(列表)、Set(保證集合中元素唯一)、Map(維護多個key-value鍵值對,保證key唯一)。其不同子類的實現各有差異,如是否同步(執行緒安全)、是否有序。 常用類繼承樹: 以下結合原始碼講解常用類實現原理及相互之間
查詢資料結構及Mysql資料庫索引原理(B-/+Tree)
轉載:https://blog.csdn.net/u014800380/article/details/64441164 摘要: 本文內容主要來源於網際網路上主流文章,只是按照個人理解稍作整合,後面附有參考連結。 https://yq.aliyun.co
MySQL索引背後的資料結構及演算法原理
作者 張洋 | 釋出於 2011-10-18 MySQL 索引 B樹 優化 摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型
MySQL索引的資料結構及演算法原理
原文連結:MySQL索引背後的資料結構及演算法原理 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避
MySQL索引背後的資料結構及BTree B+Tree演算法原理
摘要本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避免混亂,本文將只關注於BTree索引
MySQL索引背後的資料結構及演算法原理(employees例項)
摘要 http://blog.codinglabs.org/articles/theory-of-mysql-index.html 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援
轉:MySQL索引背後的資料結構及演算法原理
@rover這個是C++模板 --胡滿超 stack<Postion> path__;這個裡面 ”<> “符號是什麼意思?我在C++語言裡面沒見過呢? 初學者,大神勿噴。
MySQL索引資料結構及演算法原理學習筆記
1、預備知識 (1)儲存介質一般為主存和磁碟 (2)主存(RAM)支援隨機存取,磁碟定址需要定位【磁軌】和【扇區】,對應產生【尋道時間】和【旋轉時間】,因此磁碟的存取速度往往是主存的【幾百分之一】 (3)由於【區域性性原理】的歸納,以及磁碟IO非常耗時
【轉】MySQL索引背後的資料結構及演算法原理
摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避免混亂,本文將只關注於BTree
原理:資料結構-索引 && 應用篇:MySQL索引背後的資料結構及演算法原理詳解
特點簡介: 索引檔案比資料檔案小,可以有效地裝載到記憶體。通過對記憶體索引檔案的查詢定位到記錄,然後通過一次磁碟物件讀取操作就可以獲取到需要搜尋的物件。 靜態索引結構和動態索引結構啥區別? 我認為靜態是指新節點的加入對原有的索引結構不會發生改變,比如:稠密索引直接把新節點
轉MySQL索引背後的資料結構及演算法原理
摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避免混亂,本文將只關注
[轉]MySQL索引背後的資料結構及演算法原理
作者:張洋來源:http://blog.codinglabs.org/articles/theory-of-mysql-index.html 摘要本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索
MySQL索引背後的資料結構及演算法原理----驚歎的深入
摘要 本文以MySQL資料庫為研究物件,討論與資料庫索引相關的一些話題。特別需要說明的是,MySQL支援諸多儲存引擎,而各種儲存引擎對索引的支援也各不相同,因此MySQL資料庫支援多種索引型別,如BTree索引,雜湊索引,全文索引等等。為了避免混亂,本文將只
MySQL索引背後的資料結構及演算法原理(七)
索引選擇性與字首索引既然索引可以加快查詢速度,那麼是不是隻要是查詢語句需要,就建上索引?答案是否定的。因為索引雖然加快了查詢速度,但索引也是有代價的:索引檔案本身要消耗儲存空間,同時索引會加重插入、刪除和修改記錄時的負擔,另外,MySQL在執行時也要消耗資源維護索引,因此索引
TrieTree字典樹資料結構的原理、實現及應用
一、基本知識 字典樹(TrieTree),又稱單詞查詢樹或鍵樹,是一種樹形結構,是一種雜湊樹的變種。典型應用是用於統計和排序大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。它的優點是:最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
使用R語言ggplot2包繪製pathway富集分析氣泡圖(Bubble圖):資料結構及程式碼
氣泡圖是在笛卡爾座標系同加入大小的引數所形成的可以表示三個變數關係的圖例。在對基因完成GO/KEGG分析後,使用氣泡圖可以直觀的展示pathway、pvalue、count之間的關係。下面為使用R語言ggplot2包繪製氣泡圖所需的資料結構及程式碼: 由於筆者常使用read.csv讀取