
二、基本演算法之DFS、BFS和A*
圖中節點的遍歷和搜尋是老生常談的話題,這裡藉由python的networkx庫,複習一下之前的BFS和DFS,並對A*做一些理解。
1.BFS 廣度優先搜尋
其基本思想是優先從當前節點的鄰居節點開始搜尋,如果搜尋不到,再搜尋鄰居的鄰居。其在演算法設計的時候,主要考慮節點的標記和鄰居的儲存
利用全域性變數time進行計時,在pre列表中儲存每個節點的父節點。
整體流程如下:
(i)從G中任取一個節點i,檢查是否訪問過了(可以通過檢查相應的pre元素是否為-1)
(ii)初始化:將節點i放入一個雙端佇列visit_list
(Ⅲ)檢驗佇列是否為空,不為空,則從左邊取一個節點,將其尚未訪問的所有鄰居放入雙端佇列中(從右端放入),並設定鄰居節點的父節點(假設為j)即pre[j]=i;如果佇列為空,則演算法結束
執行的結果是import networkx as nx from collections import deque def BFS_visit(i,G=nx.Graph(),visit_time=[],pre=[]): global time visit_list=deque() visit_list.append(i) while visit_list: visit=visit_list.popleft() print visit time=time+1 visit_time[visit-1]=time for node in G: if G.has_edge(visit,node) and visit_time[node-1]==-1 and node not in visit_list: visit_list.append(node) pre[node-1]=visit def BFS(G=nx.Graph()): pre=[] visit_time=[] i=1 components=0 while i<=G.number_of_nodes(): pre.append(-1) visit_time.append(-1) i=i+1 for node in G.nodes(): if pre[node-1]==-1: BFS_visit(node,G,visit_time,pre) components=components+1 print 'components',components time=0 G=nx.Graph() G.add_edges_from([(1,2),(1,3),(2,4),(2,5),(3,6),(4,8),(5,8),(3,7)]) BFS(G)

2.DFS 寬度優先搜尋
其基本思想是隨機鄰居節點訪問,如果鄰居節點都訪問過了,則回溯到其父節點,直到圖中所有節點都被訪問過了。
在visit_time中儲存了每個節點訪問的時間(從1開始),為了檢驗在圖中有多少個環存在,特地設定了全域性變數cycle_number,當從當前節點j搜尋其鄰居節點r時,如果發現鄰居節點r已經被訪問過了則存在環(這裡假設沒有自環存在)
整體過程:
(i)從圖中任取節點i,如果節點i沒有被訪問,則到ii,否則如果圖中所有節點都被訪問過了則退出
(ii)將i設為訪問過節點,尋找i的直接鄰居r,如果鄰居j沒有被訪問過,則將j的父節點設為r,並且重複ii
import networkx as nx
def DFS_visit(i,j,G=nx.Graph(),visit_time=[],pre=[]):
global time
global cycle_number
time=time+1
visit_time[j-1]=time
r=1
while r<=G.number_of_nodes():
if(G.has_edge(j,r) and visit_time[r-1]==-1):
pre[r-1]=j
DFS_visit(j,r,G,visit_time,pre)
elif(G.has_edge(j,r) and visit_time[r-1]!=-1 and visit_time[r-1]-1>visit_time[j-1]):
cycle_number=cycle_number+1
r=r+1
def DFS(G=nx.Graph()):
global cycle_number
visit_time=[]
pre=[]
i=1
while i<=G.number_of_nodes():
visit_time.append(-1)
pre.append(0)
i=i+1
print visit_time
i=1
components=0
while (i<=G.number_of_nodes() and visit_time[i-1]==-1):
DFS_visit(0,i,G,visit_time,pre)
components=components+1
i=i+1
visit_list=[]
i=1
while i<=G.number_of_nodes():
j=0
while j<G.number_of_nodes():
if visit_time[j]==i:
visit_list.append(j+1)
break
j=j+1
i=i+1
print 'visit order:',visit_time
print 'depth visit:',visit_list
print 'parent node:',pre
print 'components=',components
print 'cycle_number',cycle_number
cycle_number=0
time=0
G=nx.Graph()
G.add_edges_from([(1,2),(1,3),(2,4),(2,5),(3,6),(4,8),(5,8),(3,7)])
DFS(G)
來自1986年的一篇論文P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths in graphs. IEEE Trans. Syst. Sci. and Cybernetics, SSC-4(2):100-107。
A*搜尋演算法
A*搜尋演算法,俗稱A星演算法,作為啟發式搜尋演算法中的一種,這是一種在圖形平面上,有多個節點的路徑,求出最低通過成本的演算法。常用於遊戲中的NPC的移動計算,或線上遊戲的BOT的移動計算上。該演算法像Dijkstra演算法一樣,可以找到一條最短路徑;也像BFS一樣,進行啟發式的搜尋。
A*演算法最為核心的部分,就在於它的一個估值函式的設計上:
f(n)=g(n)+h(n)
其中f(n)是每個可能試探點的估值,它有兩部分組成:
一部分,為g(n),它表示從起始搜尋點到當前點的代價(通常用某結點在搜尋樹中的深度來表示)。
另一部分,即h(n),它表示啟發式搜尋中最為重要的一部分,即當前結點到目標結點的估值,
h(n)設計的好壞,直接影響著具有此種啟發式函式的啟發式演算法的是否能稱為A*演算法。
一種具有f(n)=g(n)+h(n)策略的啟發式演算法能成為A*演算法的充分條件是:
1、搜尋樹上存在著從起始點到終了點的最優路徑。
2、問題域是有限的。
3、所有結點的子結點的搜尋代價值>0。
4、h(n)=<h*(n) (h*(n)為實際問題的代價值)。
當此四個條件都滿足時,一個具有f(n)=g(n)+h(n)策略的啟發式演算法能成為A*演算法,並一定能找到最優解。
對於一個搜尋問題,顯然,條件1,2,3都是很容易滿足的,而條件4: h(n)<=h*(n)是需要精心設計的,由於h*(n)顯然是無法知道的,所以,一個滿足條件4的啟發策略h(n)就來的難能可貴了。
不過,對於圖的最優路徑搜尋和八數碼問題,有些相關策略h(n)不僅很好理解,而且已經在理論上證明是滿足條件4的,從而為這個演算法的推廣起到了決定性的作用。且h(n)距離h*(n)的呈度不能過大,否則h(n)就沒有過強的區分能力,演算法效率並不會很高。對一個好的h(n)的評價是:h(n)在h*(n)的下界之下,並且儘量接近h*(n)。
A*演算法和DFS、BFS有著較深關係,其中的g(n)和h(n)作為兩個不同的代價,在DFS的搜尋中,其關注的主要是鄰居節點與當前節點的距離開銷,此時可將g(n)認為是0;而在BFS中進行分層搜尋時,以層次距離為主,此時可將h(n)認為是0。而且,當h(n)認為是0,則轉換為單點源距離計算。
此外,對於f(n)的計算還有一些變種,例如f(n)=w*g(n)+(1-w)*h(n)、f(n)=g(n)+h(n)+h(n-1)等。(可以看到變種一個是增加維度,一個是修改計算比例)。
這裡,對一個例項進行說明和實現:
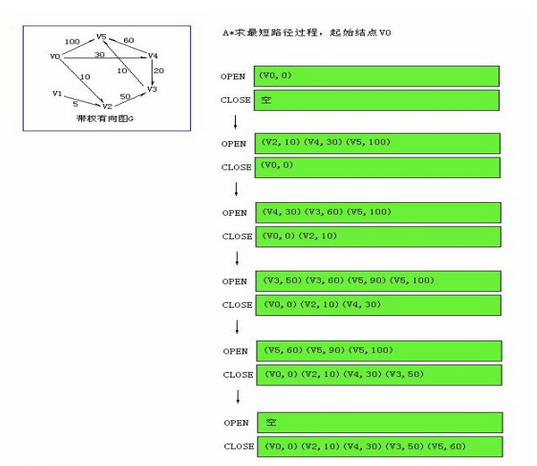
為了便於看到路徑的形成,這裡在python中用了兩個列表,其中不僅儲存了當前節點編號和權重,還儲存了其前驅節點,這樣也方便最後輸出路徑。
過程:
1.初始化列表open和close,將起點元素存入open中,其中open用來儲存探索列表而close則儲存訪問列表
2.如果open不為空,則取出open的第一個元素,並轉到2;如果open為空,則結束
3.取出第一個元素後,刪除open中和第一個元素有相同目的節點的元素,並且對其鄰居進行遍歷,如果該鄰居不在close中,則存入open中
4.對open中的節點按照f(n)大小進行升序排序,並轉到2
import networkx as nx
def Not_in(node, close_list=[]):
for item in close_list:
if item[0]==node:
return False
return True
def A_search(i,k,G=nx.DiGraph()):
open_list=[]
close_list=[]
open_list.append((i,0,0))
while open_list:
item=open_list[0]
del open_list[0]
boo=1
while(boo and open_list):
i=0
boo=0
while i<len(open_list):
if open_list[i][0]==item[0]:
del open_list[i]
boo=1
i=i+1
close_list.append(item)
if item[0]==k:
print 'open_list',open_list
print 'close_list',close_list
break
for node in G.nodes():
if G.has_edge(item[0],node) and Not_in(node,close_list):
weight=G.get_edge_data(item[0],node)['weight']+item[2]
open_list.append((node,item[0],weight))
open_number=len(open_list)
i=1
while i<=open_number:
j=0
while j<=open_number-i-1:
if open_list[j+1][2]<open_list[j][2]:
item=open_list[j]
open_list[j]=open_list[j+1]
open_list[j+1]=item
j=j+1
i=i+1
G=nx.DiGraph()
G.add_weighted_edges_from([(0,5,100),(0,2,10),(0,4,30),(1,2,5),(2,3,50),(3,5,10),(4,3,20),(4,5,60)])
A_search(0,5,G)

可以清楚的看到5<-3<-4<-0,總計開銷為60
相關參考和推薦:
相關推薦
二、基本演算法之DFS、BFS和A*
圖中節點的遍歷和搜尋是老生常談的話題,這裡藉由python的networkx庫,複習一下之前的BFS和DFS,並對A*做一些理解。 1.BFS 廣度優先搜尋 其基本思想是優先從當前節點的鄰居節點開始搜尋,如果搜尋不到,再搜尋鄰居的鄰居。
紅黑樹-RBT(二、基本操作之左旋)
都是 spa 左旋 class body 節點 圖片 如果 info 一、左旋 1、當在含有n個關鍵字的紅黑樹上運行時,TREE-INSERT和TREE-DELETE操作對樹作了修改,結果可能違反(一、紅黑樹--》2、定義)中給出的紅黑樹的性質,為了保持這些性質,就要改
【Git、GitHub、GitLab】二 Git基本命令之建立Git倉庫
上一篇文章學習了Git的安裝與最小配置:【Git、GitHub、GitLab】一 Git安裝與Git最小配置 文章目錄 建立Git倉庫 建立Git倉庫 有兩種方式可以建立Git倉庫
C語言資料結構與演算法之深度、廣度優先搜尋
一、深度優先搜尋(Depth-First-Search 簡稱:DFS) 1.1 遍歷過程: (1)從圖中某個頂點v出發,訪問v。 (2)找出剛才第一個被頂點訪問的鄰接點。訪問該頂點。以這個頂點為新的頂點,重複此步驟,直到訪問過的頂點沒有未被訪問過的頂點為止。 (3)返回到
排序演算法之冒泡、選擇、快速、插入
基本資料型別的賦值過程:值傳遞(傳遞的是值得拷貝) 資料交換的三種形式: 不需要第三方變數 a = a+b b = a-b a = a-b 引用第三方變數 temp = a a = b b = tem
基礎演算法之vector、回溯
基礎演算法之vector、回溯 一.vector vector介紹 vector的常用方法 1.初始化 2.模擬棧 3.模擬佇列 4.遍歷 5.插入指定元素 6.刪除指定元素
二、JAVA知識點之HashMap、TreeMap、紅黑樹——精髓
4、JAVA中HashMap和TreeMap什麼區別?低層資料結構是什麼? 1)、使用層次上的區別: HashMap: a)、陣列+連結串列儲存key-value,1.8加入紅黑樹(優化連結串列查詢過長的問題) b)、允許null作為key和value,key不可以重複,value允許重複 c
【數字影象處理系列二】基本概念:亮度、對比度、飽和度、銳化、解析度
本系列python版本:python3.5.4 本系列opencv-python版本:opencv-python3.4.2.17 本系列使用的開發環境是jupyter notebook,是一個python的互動式開發環境,測試十分方便,並集成了vim
linux常用基本命令之使用者、許可權管理(一)
簡介 ⽤戶是Unix/Linux系統⼯作中重要的⼀環,⽤戶管理包括⽤戶與組賬號的管理。在Unix/Linux系統中,不論是由本機或是遠端登入系統,每個系統都必須擁有⼀個賬號,並且對於不同的系統資源擁有不同的使⽤許可權。Unix/Linux系統中的root賬號通常
JAVA常用演算法之冒泡、選擇、快速
排序:對一組資料進行從小到大(或從大到小)的順序排列。 排序演算法有很多種,這裡介紹Java中面試經常出現的三種排序方式:冒泡、選擇、快速。 冒泡: 顧明思義,是氣泡從液體的底部到頂部的過程,就像串糖葫蘆一樣,先決定最下面的資料。在演算法的過程中是把一組資
機器學習提升演算法之Adaboost、GB、GBDT與XGBoost演算法
一、提升演算法概論 Boosting(提升)是一族可將弱學習器提升為強學習器的演算法。提升演算法基於這樣一種思想:對於一個複雜的任務,將多個專家的判斷總和得出的結果要比任何一個專家單獨的判斷好。這族演算法的工作機制類似:先從初始訓練集訓練出一個基學習器,再根據基學習器表現
深入學習排序演算法之穩定性、比較次數、交換次數探討
在學習排序演算法時,出於效率考慮,經常容易看到演算法的穩定性、比較次數及交換次數研究。特別是考試或者公司筆試題,經常出現這樣的題目。由於排序演算法有很多種,平時提出大家才能說出個大概,
JavaScript 演算法之最好、最壞時間複雜度分析
上一篇文章中介紹了複雜度的分析,相信小夥伴們對常見程式碼的時間或者空間複雜度肯定能分析出來了。 思考測試 話不多說,出個題目考考大家,分析下面程式碼的時間複雜度(ps: 雖然說並不會這麼寫) function find(n, x, arr) { let ind = -1;
python排序演算法 之 選擇、冒泡、插入排序
1.選擇排序 給定一個列表,一趟遍歷記錄最小的數,放到第一個位置,再一趟遍歷記錄剩餘列表中最小的數,繼續放置…… 1.每趟選出一個最小的,得到其索引,然後把該值和該趟的起始值作交換 該趟最小值在確定的位置,每趟比上一趟比較的資料少一個,資料從前減少
線性收斂的隨機優化演算法之 SAG、SVRG(隨機梯度下降)
梯度下降法大家族(BGD,SGD,MBGD) 批量梯度下降法(Batch Gradient Descent) 批量梯度下降法,是梯度下降法最常用的形式,具體做法也就是在更新引數時使用所有的樣本來進行更新 隨機梯度下降法(Stochastic Gradient Descent) 隨機
Elasticsearch java api 基本使用之增、刪、改、查
主要參考el的java官方文件:https://www.elastic.co/guide/en/elasticsearch/client/java-api/1.7/generate.html 一篇部落格:http://www.cnblogs.com/huangfox/p/3
圖論算法之DFS與BFS
nod pty pop 直觀 遍歷 必須掌握 取出 二分 最短 概述(總) DFS是算法中圖論部分中最基本的算法之一。對於算法入門者而言,這是一個必須掌握的基本算法。它的算法思想可以運用在很多地方,利用它可以解決很多實際問題,但是深入掌握其原理是我們靈活運用它的關鍵所在
Python基礎知識進階(五---2)----程序基本結構、簡單分支、異常處理、三大實例分析、基本循環結構、通用循環構造方法、死循環嵌套循環、布爾表達式
方法 算法 嵌套 構造方法 決策樹 輸入 繼續 實例 控制 上一篇隨筆寫的內容有點多了,決定分成兩節,不然自己看的時候也頭疼。 三者最大實例: 分支結構可以改變程序的控制流,算法不再是單調的一步步順序執行。 假設:以找出三個數字中最大者的程序設計為例。
數據結構之DFS與BFS
存儲 reat pac name 無向圖 using style 頂點 分享 深度搜索(DFS) and 廣度搜索(BFS) 代碼如下: 1 #include "stdafx.h" 2 #include<iostream> 3
三十六、python學習之Flask框架: 藍圖和單元測試
一、藍圖和單元測試: 1.藍圖: 隨著flask程式越來越複雜,我們需要對程式進行模組化的處理,之前學習過python的模組化管理,於是針對一個簡單的flask程式進行模組化處理 名詞解釋: 高內聚,低耦合: 所謂高內聚是指一個軟體模組是由相關性很強的程式碼組成,