
RocketMQ原理(3)——水平擴充套件及負載均衡詳解
https://zhuanlan.zhihu.com/p/25140744
RocketMQ是一個分散式具有高度可擴充套件性的訊息中介軟體。本文旨在探索在broker端,生產端,以及消費端是如何做到橫向擴充套件以及負載均衡的。
Broker端水平擴充套件
Broker負載均衡
Broker是以group為單位提供服務。一個group裡面分master和slave,master和slave儲存的資料一樣,slave從master同步資料(同步雙寫或非同步複製看配置)。
通過nameserver暴露給客戶端後,只是客戶端關心(註冊或傳送)一個個的topic路由資訊。路由資訊中會細化為message queue的路由資訊。而message queue會分佈在不同的broker group。所以對於客戶端來說,分佈在不同broker group的message queue為成為一個服務叢集,但客戶端會把請求分攤到不同的queue。
而由於壓力分攤到了不同的queue,不同的queue實際上分佈在不同的Broker group,也就是說壓力會分攤到不同的broker程序,這樣訊息的儲存和轉發均起到了負載均衡的作用。
Broker一旦需要橫向擴充套件,只需要增加broker group,然後把對應的topic建上,客戶端的message queue集合即會變大,這樣對於broker的負載則由更多的broker group來進行分擔。
並且由於每個group下面的topic的配置都是獨立的,也就說可以讓group1下面的那個topic的queue數量是4,其他group下的topic queue數量是2,這樣group1則得到更大的負載。
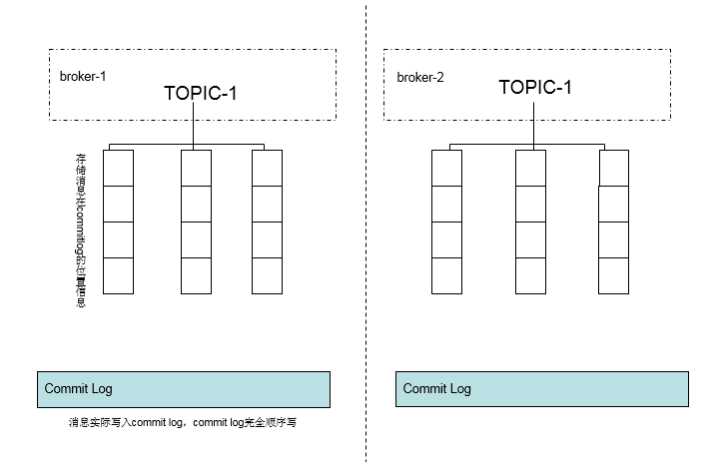
commit log
雖然每個topic下面有很多message queue,但是message queue本身並不儲存訊息。真正的訊息儲存會寫在CommitLog的檔案,message queue只是儲存CommitLog中對應的位置資訊,方便通過message queue找到對應儲存在CommitLog的訊息。
不同的topic,message queue都是寫到相同的CommitLog 檔案,也就是說CommitLog完全的順序寫。
具體如下圖:
Producer
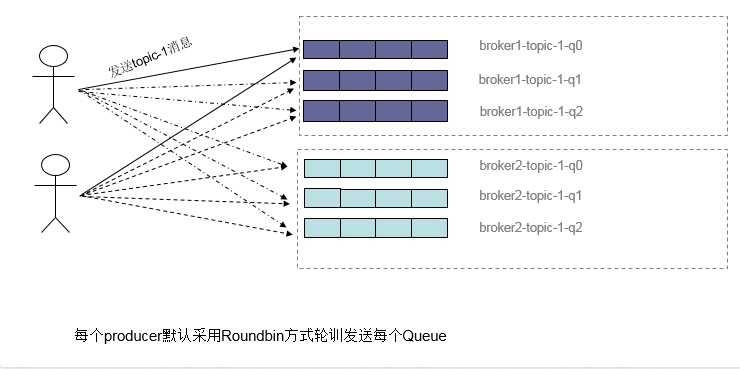
Producer端,每個例項在發訊息的時候,預設會輪詢所有的message queue傳送,以達到讓訊息平均落在不同的queue上。而由於queue可以散落在不同的broker,所以訊息就傳送到不同的broker下,如下圖:
Consumer負載均衡
叢集模式
在叢集消費模式下,每條訊息只需要投遞到訂閱這個topic的Consumer Group下的一個例項即可。RocketMQ採用主動拉取的方式拉取並消費訊息,在拉取的時候需要明確指定拉取哪一條message queue。
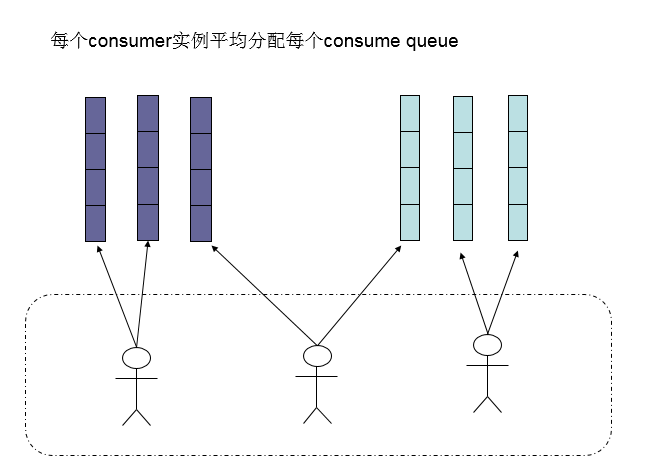
而每當例項的數量有變更,都會觸發一次所有例項的負載均衡,這時候會按照queue的數量和例項的數量平均分配queue給每個例項。
預設的分配演算法是AllocateMessageQueueAveragely,如下圖:
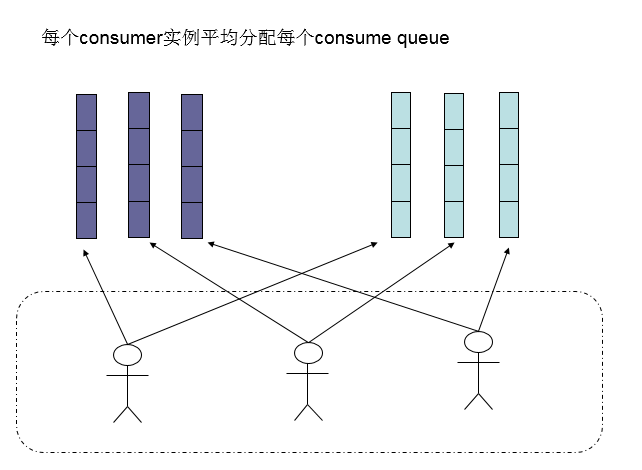
還有另外一種平均的演算法是AllocateMessageQueueAveragelyByCircle,也是平均分攤每一條queue,只是以環狀輪流分queue的形式,如下圖:
需要注意的是,叢集模式下,queue都是隻允許分配只一個例項,這是由於如果多個例項同時消費一個queue的訊息,由於拉取哪些訊息是consumer主動控制的,那樣會導致同一個訊息在不同的例項下被消費多次,所以演算法上都是一個queue只分給一個consumer例項,一個consumer例項可以允許同時分到不同的queue。
通過增加consumer例項去分攤queue的消費,可以起到水平擴充套件的消費能力的作用。而有例項下線的時候,會重新觸發負載均衡,這時候原來分配到的queue將分配到其他例項上繼續消費。
但是如果consumer例項的數量比message queue的總數量還多的話,多出來的consumer例項將無法分到queue,也就無法消費到訊息,也就無法起到分攤負載的作用了。所以需要控制讓queue的總數量大於等於consumer的數量。
廣播模式
由於廣播模式下要求一條訊息需要投遞到一個消費組下面所有的消費者例項,所以也就沒有訊息被分攤消費的說法。
在實現上,其中一個不同就是在consumer分配queue的時候,會所有consumer都分到所有的queue。

相關推薦
RocketMQ原理(3)——水平擴充套件及負載均衡詳解
https://zhuanlan.zhihu.com/p/25140744 RocketMQ是一個分散式具有高度可擴充套件性的訊息中介軟體。本文旨在探索在broker端,生產端,以及消費端是如何做到橫向擴充套件以及負載均衡的。 Broker端水平擴充套件 Broke
RocketMQ——水平擴充套件及負載均衡詳解
原文:http://jaskey.github.io/blog/2016/12/19/rocketmq-rebalance/RocketMQ是一個分散式具有高度可擴充套件性的訊息中介軟體。本文旨在探索在broker端,生產端,以及消費端是如何做到橫向擴充套件以及負載均衡的。B
筆試面試(3)阿里巴巴2014筆試題詳解(9月22北京)
第一部分 單選題(前10題,每題2分;後10題,每題3分。選對得滿分,選錯倒扣1分,不選得0分) 1、一次記憶體訪問,SSD硬碟訪問和SATA硬碟隨機訪問的時間分別是() A、幾微秒,幾毫秒,幾十毫秒B、幾十納秒,幾十毫秒,幾十毫秒 C、幾十納秒
Tomcat安裝、配置、優化及負載均衡詳解
error png cache 新的 ip地址 ace ppa 不同步 工作目錄 一、常見JavaWeb服務器 1、WebLogic:是BEA公司的產品、WebSphereAS:是IBM公司的產品、JBossAS:紅帽公司的產品,可以自行了解 2、Tomcat服務器:S
RSA演算法原理——(3)RSA加解密過程及公式論證
個人分類: 演算法 上期(RSA簡介及基礎數論知識)為大家介紹了:互質、尤拉函式、尤拉定理、模反元素 這四個數論的知識點,而這四個知識點是理解RSA加密演算法的基石,忘了的同學可以快速的回顧一遍。 三、RSA加解密過程及公式論證 今天的內容主要分為三
RocketMQ原理(4)——訊息ACK機制及消費進度管理
https://zhuanlan.zhihu.com/p/25265380 consumer的每個例項是靠佇列分配來決定如何消費訊息的。那麼消費進度具體是如何管理的,又是如何保證訊息成功消費的(RocketMQ有保證訊息肯定消費成功的特性(失敗則重試)? 本文將詳細解
理解Web應用程式的程式碼結構和執行原理(3)
1、理解Web應用程式的執行原理和機制 Web應用程式是基於瀏覽器/伺服器模式(也稱B/S架構)的應用程式,它開發完成後,需要部署到Web伺服器上才能正常執行,與使用者互動的客戶端是網頁瀏覽器。 瀏覽器負責顯示來自伺服器的資料和接受使用者的輸入資料,也
linux學習筆記(3):vim及輸入輸出
vim的模式 命令模式:瀏覽檔案,臨時更改vim的工作模式,對文字批量處理 插入模式:對檔案內容進行編輯 退出模式:退出vim模式 vim命令模式 1.vim幫助 方法1: vim :help 方法2 vimtutor 2.vim工作引數設定 臨時設定 :set 引數資訊 :s
挑戰408——組成原理(3)——原碼,補碼,反碼
計算機中的資料分為數值資料和非數值型資料(如聲音,影象等等)。我們接下來主要談的是數值型資料。 在現實的生活中,數值資料主要分為實數和整數兩大類,在計算機中,整數用定點數表示,實數用浮點數表示,而所有帶符號的整形都用補碼錶示。目前通用計算機中浮點數大多數採用IEEE754標準,其中尾數採
web前端(3)—— html標籤及web頁面結構
本節內容簡單介紹下html都有哪些標籤 還是百度首頁,檢視原始碼看看: 我把原始碼複製下來另存為html檔案裡: 注意:網頁檔案的字尾都是html或者htm 我這用的pycharm編輯器(Python編輯器,也可以
編譯原理(3)---語法分析
導讀 1。文法 (1)分類 (2)上下文無關文法 (3)語法樹 2。自上而下語法分析 (1)自上而下面臨的兩大問題 (2)預測分析 (3)怎樣實現預測分析 (4)LL(1)文法 3。自下而上語法分析 (1)直觀算符優先分析法 (2)規範歸約與算符優先文法 (3)優先函式 4。L
FPGA設計千兆乙太網MAC(3)——資料快取及位寬轉換模組設計與驗證
1 `timescale 1ns / 1ps 2 3 module tx_buffer_tb( ); 4 5 parameter USER_CLK_CYC = 10, 6 ETH_CLK_CYC = 8, 7 RST_TIM = 3;
機器學習與Tensorflow(3)—— 機器學習及MNIST資料集分類優化
一、二次代價函式 1. 形式: 其中,C為代價函式,X表示樣本,Y表示實際值,a表示輸出值,n為樣本總數 2. 利用梯度下降法調整權值引數大小,推導過程如下圖所示: 根據結果可得,權重w和偏置b的梯度跟啟用函式的梯度成正比(即啟用函式的梯度越大,w和b的大小調整的越快,訓練速度
Spring核心技術原理-(3)-Spring歷史版本變遷和如今的生態帝國
前幾篇: 前兩篇從Web開發史的角度介紹了我們在開發的時候遇到的一個個坑,然後一步步衍生出Spring Ioc和Spring AOP的概念雛形。Spring從2004年第一個正式版1.0 Final Released發展至今,儼然已經成為了一個生態帝國
機器學習數學原理(3)——生成型學習演算法
機器學習數學原理(3)——生成型學習演算法 在上一篇博文中我們通過廣義線性模型匯出了針對二分類的Sigmoid迴歸模型以及針對多項分類的Softmax迴歸模型,需要說明的是,這兩種演算法模型都屬於判別學習演算法,而這篇博文主要分析了與之區別的生成型學習演算法。生成型學習演算法與判別學
雜記(3)chrome擴充套件程式開發之在目標頁面執行JS指令碼
一、背景說明在雜記(2)中,我們寫了JS指令碼在chrome瀏覽器的開發者模式console頁面執行,用於搶bus票,但這個指令碼有個弊端是當頁面重新整理後,指令碼會自動清除,無法再執行,如何解決呢?我們可以開發一個chrome外掛,啟動這個外掛,當chrome瀏覽器一開啟目
python自動化測試(3)- 自動化框架及工具
➜ src git:(master) ✗ python basic_demo.py test_isupper (__main__.TestStringMethods) ... init by setUp... FAIL end by tearDown... test_split (__main_
【OpenStack】OpenStack原理(一)——OpenStack發展及架構
OpenStack發展過程2010年7月,RackSpace和美國國家航空航天局合作合作,分別貢獻出RackSpace雲檔案平臺程式碼和NASA Nebula平臺程式碼,OpenStack由此誕生(Austin版)。2011年2月,OpenStack社群釋出了Bexar版,
做一個詞頻統計程式,該程式具有以下功能 基本要求: (1)可匯入任意英文文字檔案 (2)統計該英文檔案中單詞數和各單詞出現的頻率(次數),並能將單詞按字典順序輸出。 (3)將單詞及頻率寫入檔案。
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileReader; import java.io.FileWriter; import java.io.IOExcep
Android framework回顧(3)binder利用及IBinder BpRefbase IInterface INTERFACE 之間關係
status_t AudioSystem::setStreamVolumeIndex(audio_stream_type_t stream, int index, audio_devices_t device){ const sp<IAudioPolicySe