
C/C++ 程式編譯與連結的過程詳解(靜態連結)
我們知道一個程式的執行需要經過編譯和連結兩個階段,其過程究竟是怎樣的呢?
程式的編譯階段分為以下幾個步驟,分別是預編譯、編譯、彙編、生成二進位制可重定向檔案(.o)。
預編譯: 首先是原始碼檔案xxx.c和相關的標頭檔案被預編譯器編譯成一個.i檔案。對於C++程式來說,原始碼的副檔名可能是.cpp或.cxx,標頭檔案的副檔名是.hpp,而編譯後的副檔名是.ii。
第一步的預編譯過程相當於如下指令:
gcc -E hello.c -o hello.i 或 cpp hello.c > hello.i.
預編譯過程做的事情:處理所有以#開頭的預編譯指令,刪除註釋,新增行號和檔名標識,保留所有的#pragma編譯器指令(因為編譯器要使用它們)。編譯:進行語法分析、詞法分析和語義分析,並且將程式碼優化後產生相應的彙編程式碼檔案(ASCLL檔案),即.s 檔案。這個過程是整個程式構建的核心部分,也是最複雜的部分之一。
相當於如下指令:
gcc -S hello.i -o hello.s彙編:通過不同平臺(Windows、Linux)的彙編器將彙編程式碼翻譯成機器碼,即生成二進位制可重定向檔案(.o)。
相當於指令:
as hello.s -o hello.o 或 gcc -c hello.s -o hello.o
或者使用gcc命令將原始檔一部生成目標檔案:
gcc -c hello.c -o hello.o
何為二進位制可重定向檔案(.o)?為什麼是可重定向檔案?
二進位制可重定向檔案包含二進位制程式碼和資料,其形式可以在連結時與其他二進位制可重定向檔案合併起來,由連結器產生一個可執行目標檔案。
一個典型的二進位制可重定向檔案格式如下圖:我自己編寫了兩個檔案:
mian.c
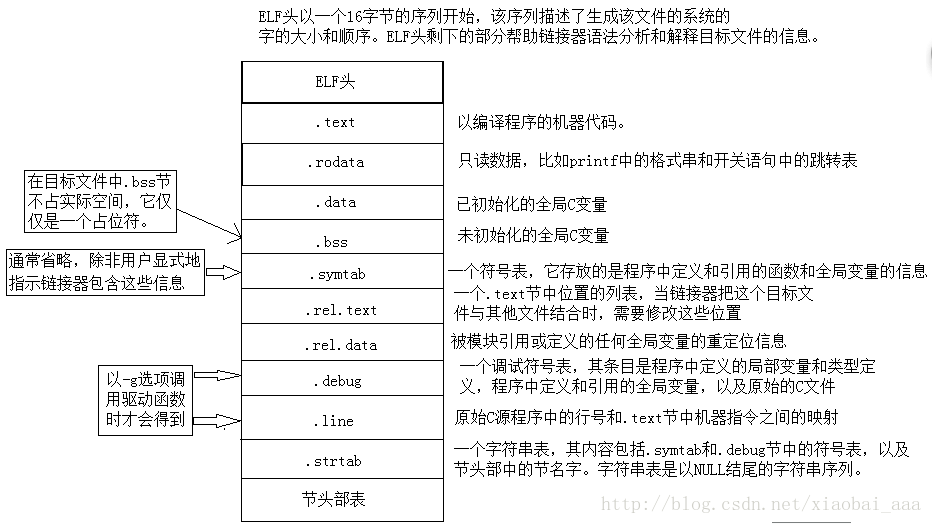
#include <stdio.h>
int sum(int, int);
int main.c
{
int a = 10;
int b = 20;
printf("sum=%d\n", sum(a, b));
return 0;
}a.c
int sum(int x, int y)
{
return x + y;
}用命令
gcc -c main.c a.c 生成.o檔案,並用命令objdump -t main.o去檢視生成的符號表,如下圖所示:
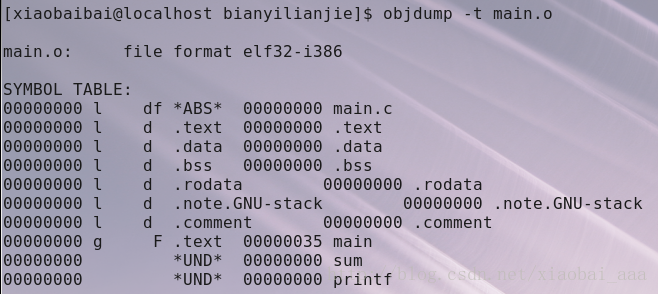
那為什麼是可重定向呢?
在編譯階段編譯器和彙編器會生成每個檔案的符號表,符號表中存放的是由程式產生的符號,比如函式名,變數名等,從上圖可以看出,編譯器沒有給符號分配正確的地址(圖中地址全為0000 0000),所以在程式碼段計算機指令無法找到相應的變數或函式的地址,因此,二進位制可重定向檔案是無法執行的。所以二進位制可重定向檔案得等到重定向以後才成為可執行檔案。
程式的連結階段可分為兩個步驟:
第一步:連結器首先將多個.o 檔案相應的段進行合併,建立對映關係並且去合併符號表。進行符號解析(符號解析的目的是讓所有符號的引用找到該符號的定義,如上圖中UND後面的符號),符號解析完成後就是給符號分配虛擬地址。
第二步:將分配好的虛擬地址與符號表中的定義的符號一一對應起來,使其成為正確的地址,是程式碼段的指令可以根據符號的地址執行相應的操作,最後由連結器生成可執行檔案。
相關推薦
C/C++ 程式編譯與連結的過程詳解(靜態連結)
我們知道一個程式的執行需要經過編譯和連結兩個階段,其過程究竟是怎樣的呢? 程式的編譯階段分為以下幾個步驟,分別是預編譯、編譯、彙編、生成二進位制可重定向檔案(.o)。 預編譯: 首先是原始碼檔案xxx.c和相關的標頭檔案被預編譯器編譯成一個.i檔案。
c語言連結串列詳解(超詳細)
連結串列是一種常見的基礎資料結構,結構體指標在這裡得到了充分的利用。連結串列可以動態的進行儲存分配,也就是說,連結串列是一個功能極為強大的陣列,他可以在節點中定義多種資料型別,還可以根據需要隨意增添,刪除,插入節點。連結串列都有一個頭指標,一般以head來表示,存放的是一個地
元資料與資料治理|Apache Atlas安裝過程詳解(初步版本)
Apache Atlas安裝過程詳解 一
Apache Hadoop1.1.1+Apache Oozie3.3.2搭建安裝過程詳解(親測)
寫在前面: 最近需要定製的原因,需要將原來Cloudera版本的Hadoop更改為Apache版本的Hadoop和Oozie,對官方文件的學習,發現Hadoop1.1.1和Oozie3.3.2的組合比較好,所以,經過幾天的搭建,終於成功了,現在把心得分享出來,希望給需要的朋
C/C++編譯和連結過程詳解 (重定向表,匯出符號表,未解決符號表)
詳解link 有 些人寫C/C++(以下假定為C++)程式,對unresolved external link或者duplicated external simbol的錯誤資訊不知所措(因為這樣的錯誤資訊不能定位到某一行)。或者對語言的一些部分不知道為什麼要(或者不要)這樣那樣設計。瞭解本文之後, 或許會有
c/c++預處理過程詳解(二)之條件編譯及預定義的巨集
未經博主同意不得私自轉載!不準各種形式的貼上複製本文及盜圖! 首先對於上篇文章中巨集定義的補充: (1)#define NAME"zhangyuncong" 程式中有"NAME"則,它會不會被替換呢? (2)#define 0x abcd 可以嗎?也就是說,可不可以用不是
C++ 編譯,執行過程 詳解。
要更深入瞭解C++, 必須要知道一個程式從開始到結束都幹了些什麼, 怎麼幹的。 所以我從C++編譯到執行過程,解析下程式是怎麼跑的。 首先,初略的說一下之前C++的編譯過程,C++編譯過程包括預編譯-》彙編-》編譯-》連結。稱為一個可執行檔案
順序表的建立和初始化過程詳解(C語言實現)
順序表存放資料的特點和陣列這種資料型別完全吻合,因此順序表的實現使用的是陣列。需要注意的是,使用陣列實現順序表時,一定要預先申請足夠大的記憶體空間,避免因儲存空間不足,造成資料溢位,導致不必要的程式錯誤甚至崩潰。 在建立順序表時,除了預先申請記憶體空間,還需要實時記錄順序表的長度和順序表本身申請的記憶體大
Shapley演算法解決舞伴問題過程詳解(C++實現)
舞伴問題是這樣的:有 n 個男孩與 n 個女孩參加舞會,每個男孩和女孩均交給主持一個名單,寫上他(她)中意的舞伴名字。無論男孩還是女孩,提交給主持人的名單都是按照偏愛程度排序的,排在前面的都是他們最中意的舞伴。試問主持人在收到名單後,是否可以將他們分成 n 對,使每個人都能和他們中意的舞伴結對跳舞?為了避免舞
軟體開發,標準化流水線式開發的實施構想 Internet 服務匯流排 嵌入式通用行業應用平臺的靈魂和搭建 快速原型開發模式在實際開發過程中的應用 公用物件請求代理(排程)程式體系結構(CORBA) UML軟體設計基礎(UML圖詳解) (篇01)企業如何軟體商業化? (篇02)企業如何軟體商業化? 在
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
C語言面向物件程式設計:繼承詳解(2)
在 C 語言面向物件程式設計(一)裡說到繼承,這裡再詳細說一下。 C++ 中的繼承,從派生類與基類的關係來看(出於對比 C 與 C++,只說公有繼承): 派生類內部可以直接使用基類的 public 、protected 成員(包括變數
js 程式執行與順序實現詳解
轉自:http://www.jb51.net/article/36755.htm 函式的宣告和呼叫 JavaScript是一種描述型指令碼語言,由瀏覽器進行動態的解析與執行。函式的定義方式大體有以下兩種,瀏覽器對於不同的方式有不同的解析順序。 程式碼如下: 複製程式碼 程式碼如下
AVL樹插入刪除演算法詳解(有圖) -- C++語言實現
一:AVL樹介紹 AVL樹本質上還是一棵二叉搜尋樹,它的特點是: 1.本身首先是一棵二叉搜尋樹。 2.帶有平衡條件:每個結點的左右子樹的高度之差的絕對值(平衡因子)最多為1。在本文中用分別用-1,0,1定義左邊樹高,等高,右邊樹高。平衡因子用m_bf表示。 也就是說,AV
解除安裝安裝Node.js與npm過程詳解
下面記錄一下在本地 Windwos 環境用 vagrant 搭建的虛擬機器(Homestaead)和生產環境阿里雲 CentOS 系統安裝 Node.js 的步驟,以及 npm 安裝依賴的不同之處。 使用原始碼編譯的方式安裝 node.js.首先將機子上的 Node.js
OGRE啟動過程詳解(OGRE HelloWorld程式原理解析)
平:本文比較系統深入的講述了OGRE啟動的全過程。我感覺不適合OGRE入門使用。不過我寫的挺好的。 本文介紹 OGRE 3D 1.9 程式的啟動過程,即從程式啟動到3D圖形呈現,背後有哪些OGRE相關的程式碼被執行。會涉及的OGRE類包括: Root
C/C++高精度運算(大整數運算)詳解(含壓位)
1.高精度加法1.1 高精度加法 高精度運算的基本運算就是加和減。和算數的加減規則一樣,模擬豎式計算,考慮錯位運算與進位處理。下面是我老師給的程式碼,目前比網上其他的程式碼要精簡和巧妙。#include <cstdio> #include <c
asp.net打包過程詳解(WEB程式也能打包)
{ base.Install(stateSaver); StreamWriter sw2=System.IO.File.CreateText(Context.Parameters["des"].ToString()+"WebSystem.url"); //Context.Parameters["des"]
深度學習-卷積神經網路CNN-BN(Batch Normalization) 原理與使用過程詳解
前言 Batch Normalization是由google提出的一種訓練優化方法。參考論文:Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shif
C++函式指標例項詳解(篇四)
#include <iostream> using namespace std ; typedef const double* (*FUN[3])(const double *, int) ; const double* call_001(const do
GCC編譯系統基本過程詳解
GCC編譯驅動程式,將源程式hello.c翻譯為一個可執行目標檔案hello過程,分為四個階段; 下面是我總結的思維導圖,比純文字的好理解一點。 第一階段,預處理階段;前處理器(cpp)根據以