
簡述ES(ElasticSearch入門簡介)
根據ES的官方文件,可以簡單定義以下3點:
1 .一個分散式的實施文件儲存,每個欄位可以被索引與搜尋
2 .一個分散式實時分析搜尋引擎
3 .可以勝任上百個服務節點的擴充套件,並支援PB級別的結構化或者非結構化資料。
Elasticsearch請求和HTTP請求類似,由以下幾個相同的部件構成
curl -X<VERB>'<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>'-d '<BODY>'
|
VERB |
適當的 HTTP 方法 |
|
PROTOCOL |
http 或者 https`(如果你在 Elasticsearch 前面有一個 `https 代理) |
|
HOST |
Elasticsearch 叢集中任意節點的主機名,或者用 localhost 代表本地機器上的節點。 |
|
PORT |
執行 Elasticsearch HTTP 服務的埠號,預設是 9200 。 |
|
PATH |
API 的終端路徑(例如 _count 將返回叢集中文件數量)。Path 可能包含多個元件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
|
QUERY_STRING |
任意可選的查詢字串引數 (例如 ?pretty 將格式化地輸出 JSON 返回值,使其更容易閱讀) |
|
BODY |
一個 JSON 格式的請求體 (如果請求需要的話) |
ES Restful API GET、POST、PUT、DELETE、HEAD含義:
1)GET:獲取請求物件的當前狀態。
2)POST:改變物件的當前狀態。
3)PUT:建立一個物件。
4)DELETE:銷燬物件。
5)HEAD:請求獲取物件的基礎資訊。
Mysql與Elasticsearch核心概念對比示意圖
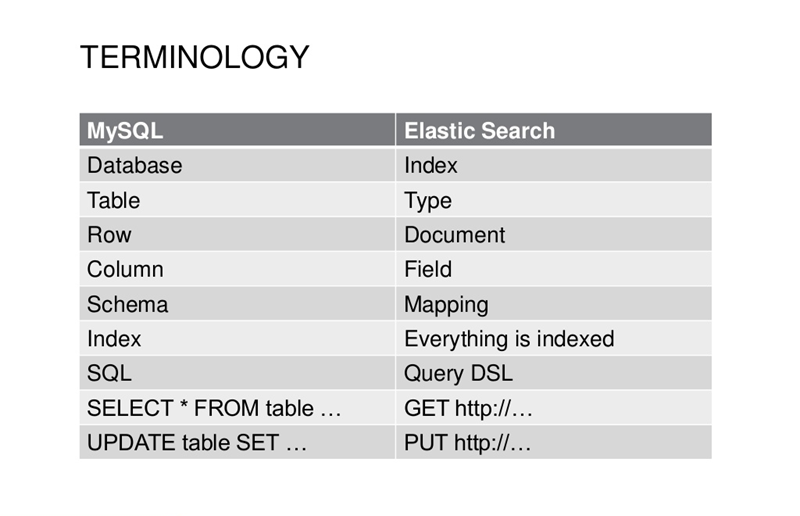
以上表為依據,
ES中的新建文件(在Index/type下)相當於Mysql中(在某Database的Table)下插入一行資料。
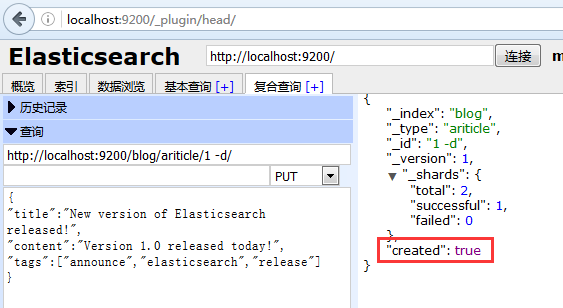
1、新建文件(類似mysql insert插入操作)
http://localhost:9200/blog/ariticle/1 put
{
"title":"New version of Elasticsearch released!",
"content":"Version 1.0 released today!",
"tags":["announce","elasticsearch","release"]
}建立成功如下顯示:
{
- "_index": "blog",
- "_type": "ariticle",
- "_id": "1 -d",
- "_version": 1,
- "_shards": {
- "total": 2,
- "successful": 1,
- "failed": 0
- },
- "created": true
}
2、檢索文件(類似mysql search 搜尋select*操作)
檢索結果如下:
{
- "_index": "blog",
- "_type": "ariticle",
- "_id": "1",
- "_version": 1,
- "found": true,
- "_source": {
- "title": "New version of Elasticsearch released!",
- "content": "Version 1.0 released today!",
- "tags": [
- "announce"
- ,
- "elasticsearch"
- ,
- "release"
- ]
- }
}如果未找到會提示:
{
- "_index": "blog",
- "_type": "ariticle",
- "_id": "11",
- "found": false
}查詢全部文件如下: 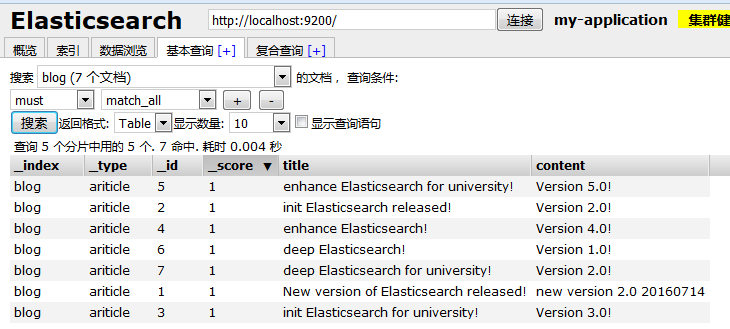
具體某個細節內容檢索,
查詢舉例1:查詢cotent列包含版本為1.0的資訊。
http://localhost:9200/blog/
_search?pretty&q=content:1.0
{
- "took": 2,
- "timed_out": false,
- "_shards": {
- "total": 5,
- "successful": 5,
- "failed": 0
- },
- "hits": {
- "total": 1,
- "max_score": 0.8784157,
- "hits": [
- {
- "_index": "blog",
- "_type": "ariticle",
- "_id": "6",
- "_score": 0.8784157,
- "_source": {
- "title": "deep Elasticsearch!",
- "content": "Version 1.0!",
- "tags": [
- "deep"
- ,
- "elasticsearch"
- ]
- }
- }
- ]
- }
}查詢舉例2:查詢書名title中包含“enhance”欄位的資料資訊:
[[email protected] ~]# curl -XGET 10.200.1.121:9200/blog/ariticle/_search?pretty -d ‘
> { "query" : {
> "term" :
> {"title" : "enhance" }
> }
> }'
{
"took" : 189,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.8784157,
"hits" : [ {
"_index" : "blog",
"_type" : "ariticle",
"_id" : "4",
"_score" : 0.8784157,
"_source" : {
"title" : "enhance Elasticsearch!",
"content" : "Version 4.0!",
"tags" : [ "enhance", "elasticsearch" ]
}
}, {
"_index" : "blog",
"_type" : "ariticle",
"_id" : "5",
"_score" : 0.15342641,
"_source" : {
"title" : "enhance Elasticsearch for university!",
"content" : "Version 5.0!",
"tags" : [ "enhance", "elasticsearch" ]
}
} ]
}
}查詢舉例3:查詢ID值為3,5,7的資料資訊:
[[email protected] ~]# curl -XGET 10.200.1.121:9200/blog/ariticle/_search?pretty -d ‘
{ "query" : {
"terms" :
{"_id" : [ "3", "5", "7" ] }
}
}'
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.19245009,
"hits" : [ {
"_index" : "blog",
"_type" : "ariticle",
"_id" : "5",
"_score" : 0.19245009,
"_source" : {
"title" : "enhance Elasticsearch for university!",
"content" : "Version 5.0!",
"tags" : [ "enhance", "elasticsearch" ]
}
}, {
"_index" : "blog",
"_type" : "ariticle",
"_id" : "7",
"_score" : 0.19245009,
"_source" : {
"title" : "deep Elasticsearch for university!",
"content" : "Version 2.0!",
"tags" : [ "deep", "elasticsearch", "university" ]
}
}, {
"_index" : "blog",
"_type" : "ariticle",
"_id" : "3",
"_score" : 0.19245009,
"_source" : {
"title" : "init Elasticsearch for university!",
"content" : "Version 3.0!",
"tags" : [ "initialize", "elasticsearch" ]
}
} ]
}
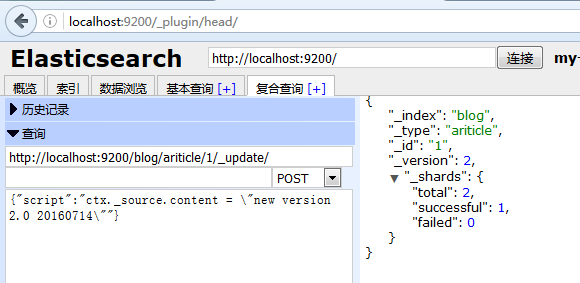
}3、更新文件(類似mysql update操作)
更新後結果顯示:
{
- “_index”: “blog”,
- “_type”: “ariticle”,
- “_id”: “1”,
- “_version”: 2,
- “_shards”: {
- ”total”: 2,
- “successful”: 1,
- “failed”: 0
- }
}
{
- "_index": "blog",
- "_type": "ariticle",
- "_id": "1",
- "_version": 2,
- "found": true,
- "_source": {
- "title": "New version of Elasticsearch released!",
- "content": "new version 2.0 20160714",
- "tags": [
- "announce"
- ,
- "elasticsearch"
- ,
- "release"
- ]
- }
}
```
注意更新文件需要在elasticsearch_win\config\elasticsearch.yml下新增以下內容:
script.groovy.sandbox.enabled: true
script.engine.groovy.inline.search: on
script.engine.groovy.inline.update: on
script.inline: on
script.indexed: on
script.engine.groovy.inline.aggs: on
index.mapper.dynamic: true
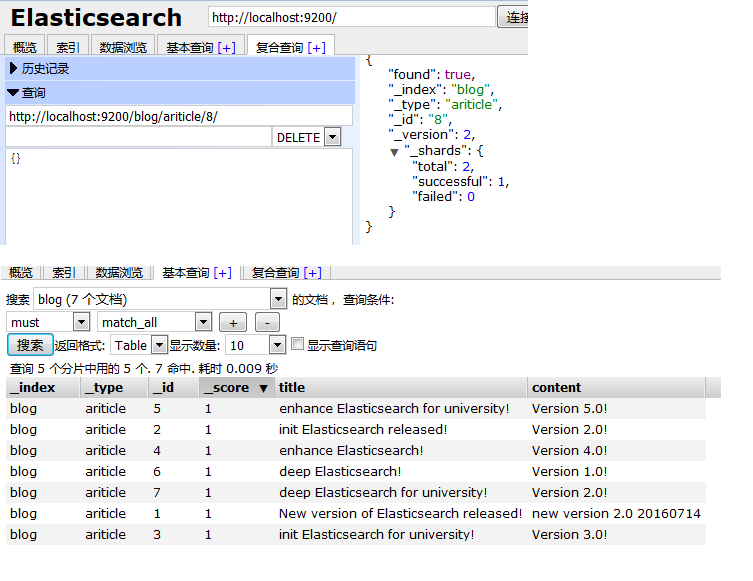
4、刪除文件(類似mysql delete操作)
{
- "found": true,
- "_index": "blog",
- "_type": "ariticle",
- "_id": "8",
- "_version": 2,
- "_shards": {
- "total": 2,
- "successful": 1,
- "failed": 0
- }
}
5、Kibana視覺化分析
5.1、在索引blog上查詢包含”university”欄位的資訊。
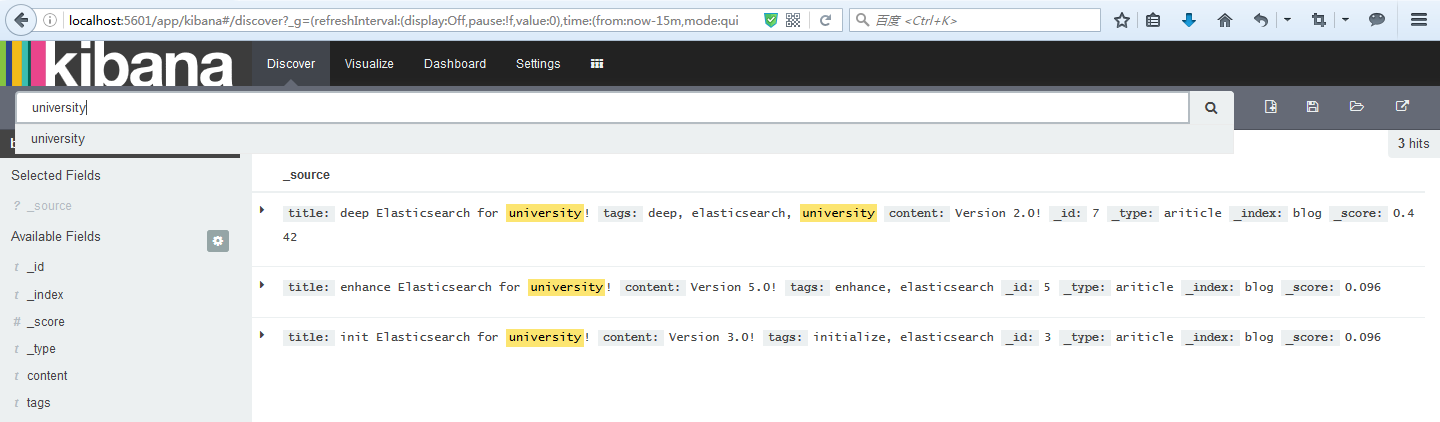
5.2、Kibana多維度分析
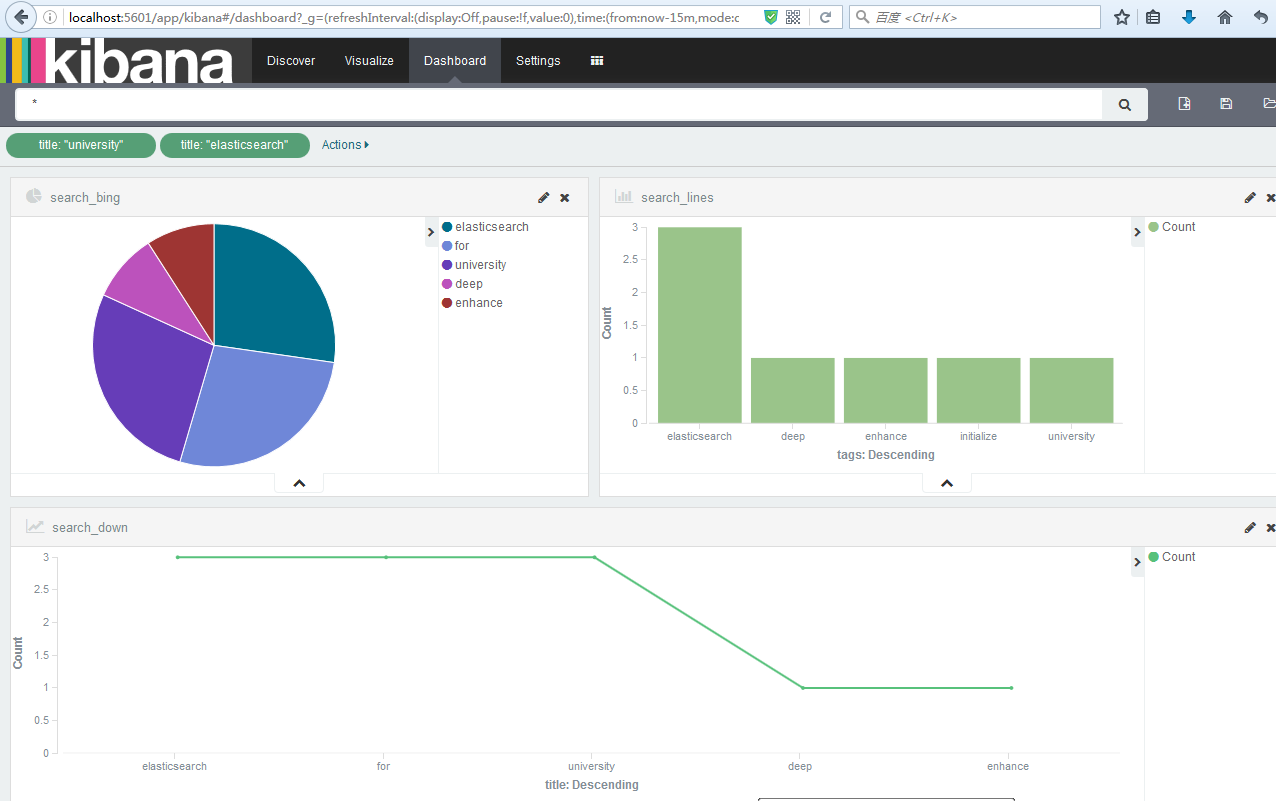
——————————————————————————————————
相關推薦
簡述ES(ElasticSearch入門簡介)
根據ES的官方文件,可以簡單定義以下3點: 1 .一個分散式的實施文件儲存,每個欄位可以被索引與搜尋 2 .一個分散式實時分析搜尋引擎 3 .可以勝任上百個服務節點的擴充套件,並支援PB級別的結構化或者非結構化資料。 Elasticsearch請求和HTTP請求類
ElasticSearch 菜鳥筆記 (一)ElasticSearch 入門簡介
前言 ElasticSearch 是一個高可用開源全文檢索和分析元件。提供儲存服務,搜尋服務,大資料準實時分析等。一般用於提供一些提供複雜搜尋的應用。 ElasticSearch 提供了一套基於restful風格的全文檢索服務元件。前身是compass,直到
ES (Elasticsearch)入門指南
簡介 ES=elaticsearch簡寫, Elasticsearch是一個開源的高擴充套件的分散式全文檢索引擎,它可以近乎實時的儲存、檢索資料;本身擴充套件性很好,可以擴充套件到上百臺伺服器,處理PB級別的資料。 本質上是一個分散式nosql資料庫,允許多臺伺服
ES(Elasticsearch)scroll查詢獲取所有資料的某個欄位
在ElasticSearch中實現分頁查詢的方式有兩種,分別為深度分頁(from-size)和快照分頁(scroll) 快照分頁(scroll) 相對於from和size的分頁來說,使用scro
spark將資料寫入ES(ElasticSearch)終極總結
簡介 spark接入ES可以使用多種方式,常見型別如下。 將Map物件寫入ElasticSearch 將case class 類物件寫入ElasticSearch 將Json的字串寫入ElasticSearch 本文主要介紹將case class 類物件寫入El
ES(elasticsearch)安裝使用
記得 nbsp cast sea grunt blank file flight delayed 首先配置系統參數(各個節點均需要配置) 1. 設置內核參數 vim /etc/sysctl.conf 添加如下內容: fs.file-max=65536 vm.m
Python第二節課(操作系統簡介)
底層 管理 機器碼 感知 隱藏 特點 分析 style for 1.為何要有操作系統 先從操作系統的定義說起,操作系統是協調,管理和控制計算機硬件資源和軟件資源的控制程序。也就是承接我們的軟件應用和硬件調用的中間人。 操作系統位於計算機硬件和應用軟件之間,本質也是一個軟件,
(高版本)ELK(Elasticsearch + Logstash + Kibana)服務服務搭建
服務器 搜索引擎 雲計算 一、ELK是什麽鬼?ELK實際上是三個工具的集合,Elasticsearch + Logstash + Kibana,這三個工具組合形成了一套實用、易用的監控架構,很多公司利用它來搭建可視化的海量日誌分析平臺。1. ElasticSearchElasticSearch是一
二叉樹(樹的簡介)
screens http day 相關性 UC 技術 nsh -m 二叉 樹及相關性質 二叉樹(樹的簡介)
elasticsearch 中文分詞(elasticsearch-analysis-ik)安裝
star 最好 好玩的 failed dex source 在線 3.0 github elasticsearch 中文分詞(elasticsearch-analysis-ik)安裝 下載最新的發布版本 https://github.com/medcl/elasticsea
數字三角形/數塔問題(DP入門題)
cstring scan iostream 動態規劃 bubuko 規劃 pri 技術分享 輸入 有形如下圖所示的數塔,從頂部出發,在每一結點可以選擇向左走或是向右走,一起走到底層,要求找出一條路徑,使路徑上的值最大。 樣例輸入: 5 13 11 8 12 7 26 6
ElasticSearch入門簡介
uil 本地 自動創建 展開 劃線 定義 created 結構 查看 ElasticSearch是基於Apache Lucene的分布式搜索引擎, 提供面向文檔的搜索服務。本文以6.2.3版本為例介紹ElasticSearch的應用。 本文首先介紹ElasticSearch
ELK系列(一):安裝(elasticsearch + logstash + kibana)
minimum 5.6 解壓 通過 stdout you targe 記錄 pat 因為公司使用ELK的緣故,這兩天嘗試在阿裏雲上安裝了下ELK,這裏做個筆記,有興趣的同學可以看下。 先大致介紹下ELK,ELK是三個組件的縮寫,分別是elasticsearch、logsta
關於tf.train.batch和tf.train.string_input_producer的區別(輸入流程簡介)
前面其實對輸入tensorflow資料集的構造和輸入那一塊的認知比較模糊,所以抽了點時間解析了一下官方程式碼。 大概順序如下: 1.輸入所需圖片的地址,然後放到tf.train.string_input_producer中進行管理,注意tf.train.string_input_produc
ELK 環境搭建(Elasticsearch+Logstash+Kibana)
官網下載地址 https://www.elastic.co/cn/downloads 在安裝Elk之前,首先需要檢查jdk環境是不是1.8版本的,這個軟體暫時不相容jdk1.9。 java -version Elasticsearch 在/usr/local/目錄下建立elk資料
Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日誌集中分析平臺
Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日誌集中分析平臺 日誌監控和分析在保障業務穩定執行時,起到了很重要的作用,不過一般情況下日誌都分散在各個生產伺服器,且開發人員無法登陸生產伺服器,這時候就需要一個集中式的日誌收集裝置,對日誌中
史上最全 Zybo-Z7 / Zybo 官方社群學習資料彙總貼(ZYNQ7000入門福音)
官方產品手冊: 1. Zybo-Z7:www.digilent.com.cn/products/product-zybo-z7-20 (點選右側邊欄“使用者手冊”) 2. Zybo(經典版):www.digilent.com.cn/products/prod
sklearn的快速使用之零(Scikit-learn簡介)
Scikit-learn 官網 (scikit-learn.org) 之前在python易筋經系列中我有寫過scipy的筆記[2],scipy是一個開源的基於python的科學計算工具包。基於scipy,目前開發者們針對不同的應用領域已經發展出了為數眾多的分支版本,它們被統一稱為Scikit
ElasticSearch安裝、IK分詞(elasticsearch-analysis-ik)安裝
安裝jdk(一個java的jdk包,如果沒有可以私聊我微信w7752442,備註:php) rpm -ivh jdk-11_linux-x64_bin.rpm 安裝elasticsearch(安裝包地址:https://github.com/medcl/elasticsearch-ana
elk(elasticsearch+logstash+kibana)安裝入坑
關於日誌,大家應該都有所瞭解,日誌的作用是為了排查問題,尤其是突發的問題,或者提供監控報警功能。傳統的日誌監控,都是在生產機上通過命令grep或less等命令查詢日誌檔案,當伺服器叢集,數量多的時候,傳統方式效率低下,無法及時確定問題,難以監控。最近公司打算優化日誌監控,查閱大量資源,發現了一款開源