
Azkaban簡介和使用
概述
為什麼需要工作流排程系統
l 一個完整的資料分析系統通常都是由大量任務單元組成:
shell指令碼程式,java程式,mapreduce程式、hive指令碼等
l 各任務單元之間存在時間先後及前後依賴關係
l 為了很好地組織起這樣的複雜執行計劃,需要一個工作流排程系統來排程執行;
例如,我們可能有這樣一個需求,某個業務系統每天產生20G原始資料,我們每天都要對其進行處理,處理步驟如下所示:
1、 通過Hadoop先將原始資料同步到HDFS上;
2、 藉助MapReduce計算框架對原始資料進行轉換,生成的資料以分割槽表的形式儲存到多張Hive表中;
3、 需要對Hive中多個表的資料進行JOIN處理,得到一個明細資料Hive大表;
4、 將明細資料進行復雜的統計分析,得到結果報表資訊;
5、 需要將統計分析得到的結果資料同步到業務系統中,供業務呼叫使用。
工作流排程實現方式
簡單的任務排程:直接使用linux的crontab來定義;
複雜的任務排程:開發排程平臺
或使用現成的開源排程系統,比如ooize、azkaban等
常見工作流排程系統
市面上目前有許多工作流排程器
在hadoop領域,常見的工作流排程器有Oozie, Azkaban,Cascading,Hamake等
各種排程工具特性對比
下面的表格對上述四種hadoop工作流排程器的關鍵特性進行了比較,儘管這些工作流排程器能夠解決的需求場景基本一致,但在設計理念,目標使用者,應用場景等方面還是存在顯著的區別,在做技術選型的時候,可以提供參考
|
特性 |
Hamake |
Oozie |
Azkaban |
Cascading |
|
工作流描述語言 |
XML |
XML (xPDL based) |
text file with key/value pairs |
Java API |
|
依賴機制 |
data-driven |
explicit |
explicit |
explicit |
|
是否要web容器 |
No |
Yes |
Yes |
No |
|
進度跟蹤 |
console/log messages |
web page |
web page |
Java API |
|
Hadoop job排程支援 |
no |
yes |
yes |
yes |
|
執行模式 |
command line utility |
daemon |
daemon |
API |
|
Pig支援 |
yes |
yes |
yes |
yes |
|
事件通知 |
no |
no |
no |
yes |
|
需要安裝 |
no |
yes |
yes |
no |
|
支援的hadoop版本 |
0.18+ |
0.20+ |
currently unknown |
0.18+ |
|
重試支援 |
no |
workflownode evel |
yes |
yes |
|
執行任意命令 |
yes |
yes |
yes |
yes |
|
Amazon EMR支援 |
yes |
no |
currently unknown |
yes |
Azkaban與Oozie對比
對市面上最流行的兩種排程器,給出以下詳細對比,以供技術選型參考。總體來說,ooize相比azkaban是一個重量級的任務排程系統,功能全面,但配置使用也更復雜。如果可以不在意某些功能的缺失,輕量級排程器azkaban是很不錯的候選物件。
詳情如下:
u 功能
兩者均可以排程mapreduce,pig,java,指令碼工作流任務
兩者均可以定時執行工作流任務
u 工作流定義
Azkaban使用Properties檔案定義工作流
Oozie使用XML檔案定義工作流
u 工作流傳參
Azkaban支援直接傳參,例如${input}
Oozie支援引數和EL表示式,例如${fs:dirSize(myInputDir)}
u 定時執行
Azkaban的定時執行任務是基於時間的
Oozie的定時執行任務基於時間和輸入資料
u 資源管理
Azkaban有較嚴格的許可權控制,如使用者對工作流進行讀/寫/執行等操作
Oozie暫無嚴格的許可權控制
u 工作流執行
Azkaban有兩種執行模式,分別是soloserver mode(executor server和web server部署在同一臺節點)和multi server mode(executor server和web server可以部署在不同節點)
Oozie作為工作流伺服器執行,支援多使用者和多工作流
u 工作流管理
Azkaban支援瀏覽器以及ajax方式操作工作流
Oozie支援命令列、HTTP REST、Java API、瀏覽器操作工作流
Azkaban介紹
Azkaban是由Linkedin開源的一個批量工作流任務排程器。用於在一個工作流內以一個特定的順序執行一組工作和流程。Azkaban定義了一種KV檔案格式來建立任務之間的依賴關係,並提供一個易於使用的web使用者介面維護和跟蹤你的工作流。
它有如下功能特點:
² Web使用者介面
² 方便上傳工作流
² 方便設定任務之間的關係
² 排程工作流
² 認證/授權(許可權的工作)
² 能夠殺死並重新啟動工作流
² 模組化和可插拔的外掛機制
² 專案工作區
² 工作流和任務的日誌記錄和審計
Azkaban安裝部署
準備工作
Azkaban Web伺服器
azkaban-web-server-2.5.0.tar.gz
Azkaban執行伺服器
azkaban-executor-server-2.5.0.tar.gz
MySQL
目前azkaban只支援 mysql,需安裝mysql伺服器,本文件中預設已安裝好mysql伺服器,並建立了 root使用者,密碼 root.
下載地址:http://azkaban.github.io/downloads.html
安裝
將安裝檔案上傳到叢集,最好上傳到安裝 hive、sqoop的機器上,方便命令的執行
在當前使用者目錄下新建 azkabantools目錄,用於存放源安裝檔案.新建azkaban目錄,用於存放azkaban執行程式
azkaban web伺服器安裝
解壓azkaban-web-server-2.5.0.tar.gz
命令: tar –zxvf azkaban-web-server-2.5.0.tar.gz
將解壓後的azkaban-web-server-2.5.0 移動到 azkaban目錄中,並重新命名 webserver
命令: mv azkaban-web-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-web-server-2.5.0 server
azkaban 執行服器安裝
解壓azkaban-executor-server-2.5.0.tar.gz
命令:tar –zxvf azkaban-executor-server-2.5.0.tar.gz
將解壓後的azkaban-executor-server-2.5.0 移動到 azkaban目錄中,並重新命名 executor
命令:mv azkaban-executor-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-executor-server-2.5.0 executor
azkaban指令碼匯入
解壓: azkaban-sql-script-2.5.0.tar.gz
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz
將解壓後的mysql 指令碼,匯入到mysql中:
進入mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source/home/hadoop/azkaban-2.5.0/create-all-sql-2.5.0.sql;
建立SSL配置
參考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
執行此命令後,會提示輸入當前生成 keystor的密碼及相應資訊,輸入的密碼請勞記,資訊如下:
輸入keystore密碼:
再次輸入新密碼:
您的名字與姓氏是什麼?
[Unknown]:
您的組織單位名稱是什麼?
[Unknown]:
您的組織名稱是什麼?
[Unknown]:
您所在的城市或區域名稱是什麼?
[Unknown]:
您所在的州或省份名稱是什麼?
[Unknown]:
該單位的兩字母國家程式碼是什麼
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown,L=Unknown, ST=Unknown, C=CN 正確嗎?
[否]: y
輸入<jetty>的主密碼
(如果和 keystore 密碼相同,按回車):
再次輸入新密碼:
完成上述工作後,將在當前目錄生成 keystore 證書檔案,將keystore 考貝到 azkaban web伺服器根目錄中.如:cp keystore azkaban/server
配置檔案
注:先配置好伺服器節點上的時區
1、先生成時區配置檔案Asia/Shanghai,用互動式命令 tzselect 即可
2、拷貝該時區檔案,覆蓋系統本地時區配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
azkaban web伺服器配置
進入azkaban web伺服器安裝目錄 conf目錄
v 修改azkaban.properties檔案
命令vi azkaban.properties
內容說明如下:
|
#Azkaban Personalization Settings azkaban.name=Test #伺服器UI名稱,用於伺服器上方顯示的名字 azkaban.label=My Local Azkaban #描述 azkaban.color=#FF3601 #UI顏色 azkaban.default.servlet.path=/index # web.resource.dir=web/ #預設根web目錄 default.timezone.id=Asia/Shanghai #預設時區,已改為亞洲/上海 預設為美國 #Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager #使用者許可權管理預設類 user.manager.xml.file=conf/azkaban-users.xml #使用者配置,具體配置參加下文 #Loader for projects executor.global.properties=conf/global.properties # global配置檔案所在位置 azkaban.project.dir=projects # database.type=mysql #資料庫型別 mysql.port=3306 #埠號 mysql.host=localhost #資料庫連線IP mysql.database=azkaban #資料庫例項名 mysql.user=root #資料庫使用者名稱 mysql.password=root #資料庫密碼 mysql.numconnections=100 #最大連線數 # Velocity dev mode velocity.dev.mode=false # Jetty伺服器屬性. jetty.maxThreads=25 #最大執行緒數 jetty.ssl.port=8443 #Jetty SSL埠 jetty.port=8081 #Jetty埠 jetty.keystore=keystore #SSL檔名 jetty.password=123456 #SSL檔案密碼 jetty.keypassword=123456 #Jetty主密碼與 keystore檔案相同 jetty.truststore=keystore #SSL檔名 jetty.trustpassword=123456 # SSL檔案密碼 # 執行伺服器屬性 executor.port=12321 #執行伺服器埠 # 郵件設定 [email protected] #傳送郵箱 mail.host=smtp.163.com #傳送郵箱smtp地址 mail.user=xxxxxxxx #傳送郵件時顯示的名稱 mail.password=********** #郵箱密碼 [email protected] #任務失敗時傳送郵件的地址 [email protected] #任務成功時傳送郵件的地址 lockdown.create.projects=false # cache.directory=cache #快取目錄 |
v azkaban 執行伺服器executor配置
進入執行伺服器安裝目錄conf,修改azkaban.properties
vi azkaban.properties
|
#Azkaban default.timezone.id=Asia/Shanghai #時區 # Azkaban JobTypes 外掛配置 azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 外掛所在位置 #Loader for projects executor.global.properties=conf/global.properties azkaban.project.dir=projects #資料庫設定 database.type=mysql #資料庫型別(目前只支援mysql) mysql.port=3306 #資料庫埠號 mysql.host=192.168.20.200 #資料庫IP地址 mysql.database=azkaban #資料庫例項名 mysql.user=root #資料庫使用者名稱 mysql.password=root #資料庫密碼 mysql.numconnections=100 #最大連線數 # 執行伺服器配置 executor.maxThreads=50 #最大執行緒數 executor.port=12321 #埠號(如修改,請與web服務中一致) executor.flow.threads=30 #執行緒數 |
v 使用者配置
進入azkaban web伺服器conf目錄,修改azkaban-users.xml
vi azkaban-users.xml 增加 管理員使用者
|
<azkaban-users> <user username="azkaban" password="azkaban" roles="admin" groups="azkaban" /> <user username="metrics" password="metrics" roles="metrics"/> <user username="admin" password="admin" roles="admin,metrics" /> <role name="admin" permissions="ADMIN" /> <role name="metrics" permissions="METRICS"/> </azkaban-users> |
啟動
web伺服器
在azkaban web伺服器目錄下執行啟動命令
bin/azkaban-web-start.sh
注:在web伺服器根目錄執行
或者啟動到後臺
nohup bin/azkaban-web-start.sh 1>/tmp/azstd.out 2>/tmp/azerr.out &
執行伺服器
在執行伺服器目錄下執行啟動命令
bin/azkaban-executor-start.sh
注:只能要執行伺服器根目錄執行
啟動完成後,在瀏覽器(建議使用谷歌瀏覽器)中輸入https://伺服器IP地址:8443 ,即可訪問azkaban服務了.在登入中輸入剛才新的戶用名及密碼,點選 login.
Azkaban實戰
Azkaba內建的任務型別支援command、java
Command型別單一job示例
1、建立job描述檔案
vi command.job
|
#command.job type=command command=echo 'hello' |
2、將job資原始檔打包成zip檔案
zip command.job
3、通過azkaban的web管理平臺建立project並上傳job壓縮包
首先建立project
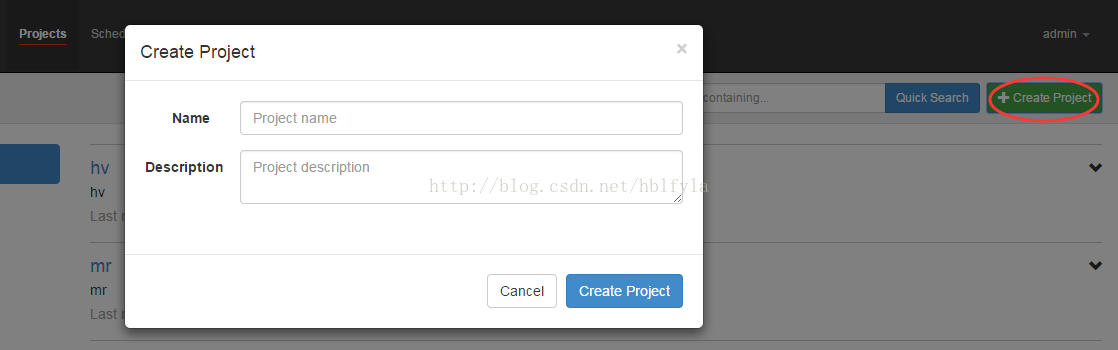
上傳zip包

4、啟動執行該job

Command型別多job工作流flow
1、建立有依賴關係的多個job描述
第一個job:foo.job
|
# foo.job type=command command=echo foo |
第二個job:bar.job依賴foo.job
|
# bar.job type=command dependencies=foo command=echo bar |
2、將所有job資原始檔打到一個zip包中
3、在azkaban的web管理介面建立工程並上傳zip包
4、啟動工作流flow
HDFS操作任務
1、建立job描述檔案
|
# fs.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz |
2、將job資原始檔打包成zip檔案
3、通過azkaban的web管理平臺建立project並上傳job壓縮包
4、啟動執行該job
MAPREDUCE任務
Mr任務依然可以使用command的job型別來執行
1、建立job描述檔案,及mr程式jar包(示例中直接使用hadoop自帶的examplejar)
|
# mrwc.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout |
2、將所有job資原始檔打到一個zip包中

3、在azkaban的web管理介面建立工程並上傳zip包
4、啟動job
HIVE指令碼任務
l 建立job描述檔案和hive指令碼
Hive指令碼: test.sql
|
use default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ','; load data inpath '/aztest/hiveinput' into table aztest; create table azres as select * from aztest; insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest; |
Job描述檔案:hivef.job
|
# hivef.job type=command command=/home/hadoop/apps/hive/bin/hive -f 'test.sql' |
2、將所有job資原始檔打到一個zip包中
3、在azkaban的web管理介面建立工程並上傳zip包
4、啟動job
相關推薦
Azkaban簡介和使用
概述 為什麼需要工作流排程系統 l 一個完整的資料分析系統通常都是由大量任務單元組成: shell指令碼程式,java程式,mapreduce程式、hive指令碼等 l 各任務單元之間存在時間先後及前後依賴關係 l 為了很好地組織起這樣的複雜執行計劃,需
工作流排程系統Azkaban的簡介和使用
1 概述 1.1 為什麼需要工作流排程系統 l 一個完整的資料分析系統通常都是由大量任務單元組成: shell指令碼程式,java程式,mapreduce程式、hive指令碼等 l 各任務單元之間存在時間先後及前後依賴關係 l 為了很好地組織起這樣的複雜
工作流調度系統Azkaban的簡介和使用
download 版本 role edi 數據分析 訪問 label rec test 1 概述 1.1 為什麽需要工作流調度系統 l 一個完整的數據分析系統通常都是由大量任務單元組成: shell腳本程序,java程序,mapreduce程序、hive腳本等 l 各任
day1 python簡介和入門
back argv 安裝gcc www 導入 urn 16px 利用 表示 Linux的yum依賴自帶Python,為防止錯誤,此處更新其實就是再安裝一個Python: 安裝Python 1、下載安裝包 https://www.python.
KBEngine warring項目源碼閱讀(一) 項目簡介和註冊登錄
urn 創建 ges input alt 接下來 F12 .com name 首先介紹下warring項目,是kbe自帶的一個演示示例,大部分人了解kbe引擎也是從warring項目開始的。 項目地址:https://github.com/kbengine/kbengine
Python自學之路【第一篇】:Python簡介和入門
youtube 通用 too 互聯網公司 python腳本 bar strong 重裝 排行 Python前世今生 python的創始人為吉多·範羅蘇姆(Guido van Rossum)。1989年的聖誕節期間,吉多·範羅蘇姆為了在阿姆斯特丹打發時間,決心開發一個新的腳本
Rust 1.7.0 匹配器 match 的簡介和使用
let 滿足 選擇 多個 efault msg i++ pretty article 使用過正則表達式的人應該都知道 matcher ,通過 matcher 匹配器運算正則表達式,完畢一系列的匹配規則。 在Rust 中 沒有 switch 語句。mat
從零開始玩轉JMX(一)——簡介和Standard MBean
pos cor csdn comm art order clas post tex 從零開始玩轉JMX(一)——簡介和Standard MBeanJMX超詳細解讀 參考資料JMX整理JMX簡介http://blog.csdn.net/DryKillLogic/articl
redis學習--簡介和安裝
key-value shel 解壓 過去 內存 下載 local 完成 test 1.redis介紹: Redis 與其他 key - value 緩存產品有以下三個特點: Redis支持數據的持久化,可以將內存中的數據保存在磁盤中,重啟的時候可以再次加載進行使用。 Re
Compser簡介和初體驗
命令 pos 調用 資源 發郵件 再次 https 分享 images 什麽是composer Composer是PHP依賴管理工具。 依賴:比如運行A需要B,運行B又需要C,我們就說A依賴於B,B依賴於C。 Compoer的由來 PHP之前的類管理: php開發者
(一)Solr——簡介和安裝配置
str 服務 開源項目 一個 war prop post 沒有 系統安裝 1. solr簡介 1.1 Solr是什麽 Solr是apache的頂級開源項目,它是使用java開發 ,基於lucene的全文檢索服務器。 Solr和lucene的版本是同步更新的,最新的版本
seaJS簡介和完整實例
化工 area 初始化 完成 har 自動 end href out 什麽是 seaJS ? 和requireJS相似的,seaJS 也是用JavaScript編寫的JS框架,主要功能是可以按不同的先後依賴關系對 JavaScript 等文件的進行加載工作,可簡單理解為J
Linux的企業-Cgconfig簡介和相關限制
cgconfig 簡介 相關限制 一.簡介 Cgroups是control groups的縮寫,是Linux內核提供的一種可以限制、記錄、隔離進程組(process groups)所使用的物理資源(如:cpu,memory,IO等等)的機制。最初由google的工程師提出,後來被整合進
MyBatis原理簡介和小試牛刀
batis dao 讀取 區別 ons 目的 ktr als config 在我看來mybatis的原理與hibernate在某些方面是一致的,先回顧一下Hibernate原理(原理主要上是要掌握並理解下列六個對象: Hibernate中重要的六個對象: Configura
DNS服務簡介和配置詳解
dns基本原理 dns簡介 dns服務配置過程 DNS服務簡介和配置詳解1、什麽是DNS? DNS( Domain Name System)是“域名系統”的英文縮寫,是一種組織成域層次結構的計算機和網絡服務命名系統,使用的是UDP協議的53號端口,它用於TCP/IP網絡,它所提供的服務是用來將主機
Python之路【第一篇】:Python簡介和入門
源碼 world 網絡服務 換行 編程風格 大小寫 utf8 編譯安裝 比較 python簡介: 一、什麽是python Python(英國發音:/ pa θ n/ 美國發音:/ pa θɑ n/),是一種面向對象、直譯式的計算機程序語言。 每一門語言都有自己的哲學: py
Cgroup blkio簡介和測試(使用fio測試)
diff 了解 ont 電梯 iostat tmpfs del let dev Cgroup blkio簡介和測試(使用fio測試) 因需要對docker鏡像內的進程對磁盤讀寫的速度進行限制,研究了下Cgroup blkio,並使用fio對其iops/bps限速進行測試。
各個JSON技術的簡介和優劣
pan ns-3 json轉換 出錯 如果 算法 spa 出現問題 項目 各個JSON技術的簡介和優劣 (這裏只介紹各自優點和缺點,具體用法,請大家到網上去查找) 特別是fastJaso用法。這裏介紹的不錯: https://www.cnblog
Elasticsearch簡介和安裝對比
特殊 字段 tree apache 查看 端口 blog work 分布式搜索 各位小夥伴,又到了本期分享大數據技術的時間,本次給大夥帶來的是Elasticsearch這個技術,閑話不多聊,我們開始進入正題。 一、什麽是elasticsearch Elasticsearc
linux nftables簡介和基礎操作
語法 用戶態 新規 數據包 name chain 地址 lac 版本 一、什麽是nftables? nftables 是新的數據包分類框架,新的linux防火墻管理程序,旨在替代現存的 {ip,ip6,arp,eb}_tables。簡而言之:它在 Linux 內核版本高於