
Nutch搜尋引擎(第4期)_ Eclipse開發配置
1、環境準備
1.1 本期引言
前三期分別介紹了Nutch與Solr在Linux上面的安裝,並做了簡單的應用,這一期從開發的角度進行,因為我們日常最熟悉的開發環境是Windows,所以本期詳細介紹Windows平臺的Nutch二次開發所需要進行的配置安裝。當我們開發好之後,最後在部署到Linux環境中。
為了方便以後Nutch開發以及軟體安裝的管理,我們對開發環境配置進行如下安排:
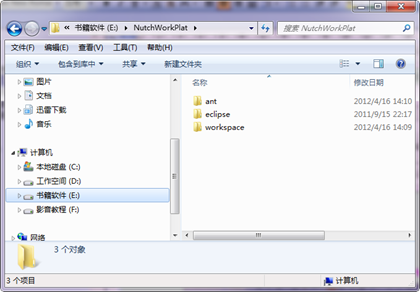
E:/(碟符)
|----cygwin
|----NutchWorkPlat
|----ant
|----solr
|----nutch
|----eclipse
|----tomcat
|----workspace
1.2 環境介紹
本次Nutch二次開發的環境介紹:
- 作業系統:Windows 7 旗艦版
- ANT版本:apache-ant-1.8.3-bin.tar.gz
- JDK版本:jdk-6u31-windows-i586.exe
- Solr版本:apache-solr-3.5.0.zip
- Nutch版本:apache-nutch-1.4-bin.tar.gz
-
Tomcat版本:apache-tomcat-7.0.27.tar.gz
- Eclipse版本:eclipse-jee-indigo-SR1-win32.zip
下面是安裝的Eclipse外掛:
-
IvyDE外掛:
-
Ivy:
- plugins:
-
Ivy:
- org.apache.ivy_2.2.0.final_20100923230623.jar
- org.apache.ivy.eclipse.ant_2.2.0.final_20100923230623.jar
- features:org.apache.ivy.feature_2.2.0.final_20100923230623.jar
-
IvyDE:
- plugins:org.apache.ivyde.eclipse_2.2.0.beta1-201203282058-RELEASE.jar
- features:org.apache.ivyde.feature_2.2.0.beta1-201203282058-RELEASE.jar
- Tomcat外掛:tomcatPluginV33.zip
1.3 JDK安裝配置
雙擊"jdk-6u31-windows-i586.exe"即可進行安裝,我們一路點選Next,預設安裝在C盤,下面是我們安裝完JDK的目錄。
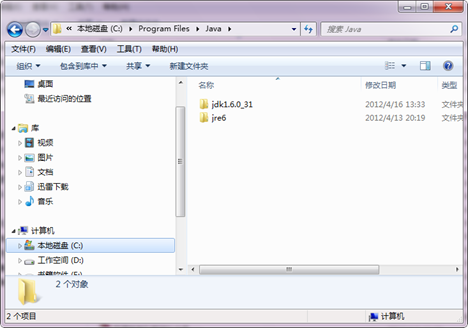
下面配置JAVA環境變數:右擊à我的電腦à屬性à高階系統設定à高階à環境變數。
【新建】
JAVA_HOME=C:\Program Files\Java\jdk1.6.0_31
CLASSPATH=.;% JAVA_HOME %\lib;% JAVA_HOME%\jre\lib
NUTCH_JAVA_HOME=% JAVA_HOME %
【增加】
PATH=……;% JAVA_HOME%\bin; % JAVA_HOME%\jre\bin
第一步:點選"新建",然後變數名寫上"JAVA_HOME",填上上面內容。
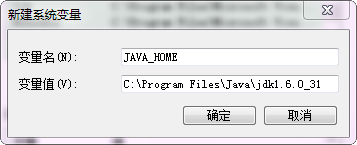
備註:JAVA_HOME的變數值後千萬不能加分號。
第二步:點選"新建",然後變數名寫上"JAVA_HOME",填上上面內容。

備註:要加圓點.表示當前路徑。
第三步:點選"新建",然後變數名寫上"NUTCH_JAVA_HOME",填上上面內容。
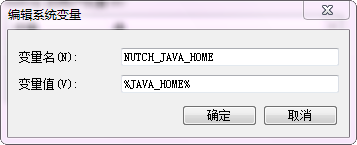
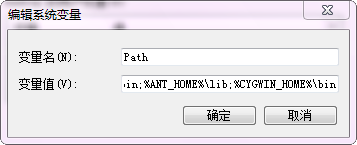
第四步:在系統變數裡找到Path,點選編輯。在後面追加上面內容。
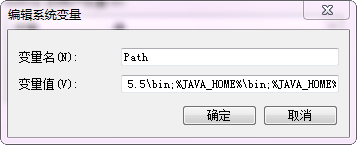
備註:追加時,用";"與前面的值進行分割。
1.4 ANT安裝配置
把"apache-ant-1.8.3-bin.tar.gz"解壓到"E:\NutchWorkPlat"中,並重新命名為"ant"。
下面配置ANT環境變數:右擊à我的電腦à屬性à高階系統設定à高階à環境變數。
【新建】
ANT_HOME= E:\NutchWorkPlat\ant
【增加】
PATH=……;%ANT_HOME%\bin; %ANT_HOME%\lib
第一步:點選"新建",然後變數名寫上"ANT_HOME",填上上面內容。
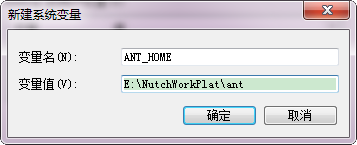
備註:ANT_HOME的變數值後千萬不能加分號。
第二步:在系統變數裡找到Path,點選編輯。在後面追加上面內容。

備註:追加時,用";"與前面的值進行分割。
1.5 IvyDE安裝配置
從官網上把上面所寫的IvyDE的Eclipse外掛下載下來。
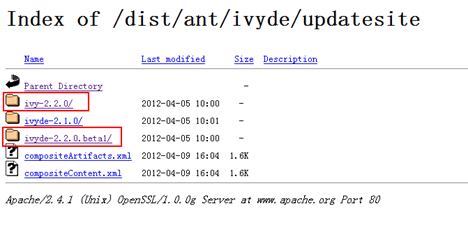
備註:其他網友和官網都只說安裝"ivyde-2.2.0.beta1"即可,但是發現安裝沒有起作用,按照"Eclipse安裝ivyDe外掛"這篇文章成功了。
【ivyde-eclipse】

- ivyde- plugins
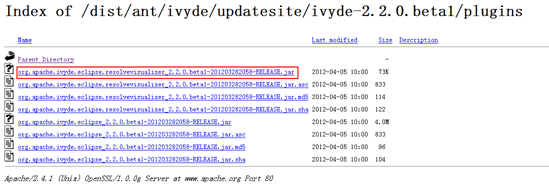
把"org.apache.ivyde.eclipse_2.2.0.beta1-201203282058-RELEASE.jar"複製到Eclipse安裝目錄的"plugins"中。
- ivyde-features
把"org.apache.ivyde.feature_2.2.0.beta1-201203282058-RELEASE.jar"解壓到Eclipse安裝目錄的"features"中。
備註:是解壓之後放到目錄"features"中,而不是直接把jar包放到裡面,不然啟動Eclipse後,開啟WindowàShow ViewàError log後,提示"Unable to find feature.xml in directory"。
【ivy-eclipse】
- ivy- plugins
把"org.apache.ivy.eclipse.ant_2.2.0.final_20100923230623.jar"和"org.apache.ivy_2.2.0.

final_20100923230623.jar"複製到Eclipse安裝目錄的"plugins"中。
- ivy-features

把"org.apache.ivy.feature_2.2.0.final_20100923230623.jar"解壓到Eclipse安裝目錄的"features"中。
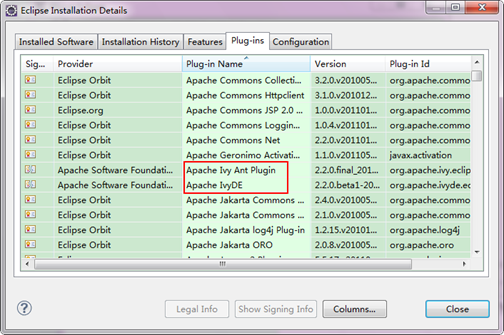
完成以上步驟之後,重啟Eclipse,開啟Windowàpreference對話方塊裡看到ivy一欄;開啟HelpàAbout EclipseàInstallationàPlug-ins列表裡也可以看到兩個ivy,一個ivyDe。
1.5 Tomcat安裝配置
首先安裝Tomcat,把"apache-tomcat-7.0.27.tar.gz"解壓到"E:\NutchWorkPlat"目錄下,並重新命名為"tomcat"。
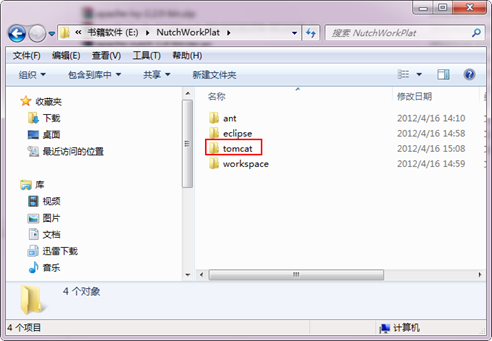
進入"E:\NutchWorkPlat\tomcat\bin"點選"startup.bat",然後出現如下介面。

接著安裝Tomcat的Eclipse外掛,並讓Eclipse與Tomcat結合,把"tomcatPluginV33.zip"後的"com.sysdeo.eclipse.tomcat_3.3.0"複製到"E:\NutchWorkPlat\eclipse\plugins"中,然後重啟Eclipse。
開啟Windowàpreference對話方塊裡看到tomcat一覽,點選tomcat,把剛才解壓的tomcat進行關聯,操作如下。

點選工具欄的"Start Tomcat"即可啟動Tomcat。
然後在Eclipse控制檯會輸出啟動Tomcat的相關資訊。
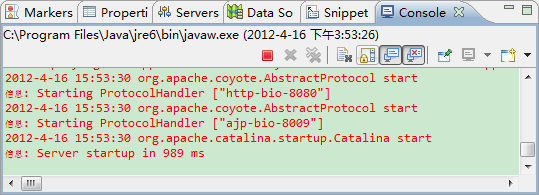
1.6 Cygwin安裝配置
nutch是在hadoop基礎上做的,由於hadoop只在linux上執行,裡面涉及到大量的操作linux程式,所以我們在Windows部署的時候必須先安裝cygwin環境,模擬linux操作。
我們這次安裝cygwin是用安裝包進行安裝,並沒有採用Internet線上安裝。

在上圖所示的對話方塊中,直接點選"下一步",進入如下圖所示的對話方塊:
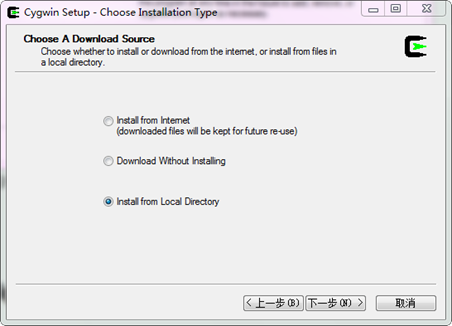
介面出現三種安裝模式:
- Install from Internet,這種模式直接從Internet安裝,適合網速較快的情況;
- Download Without Installing,這種模式只從網上下載Cygwin的元件包,但不安裝;
- Install from Local Directory,這種模式與上面第二種模式對應,當你的Cygwin元件包已經下載到本地,則可以使用此模式從本地安裝Cygwin。
我們這裡選擇第三種"Install from Local Directory"方式進行安裝,然後點選"下一步",進入如下圖所示對話方塊:
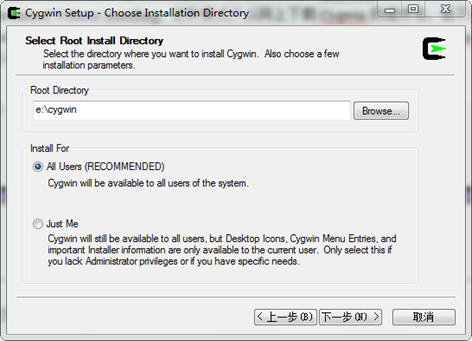
在上圖所示的對話方塊中,設定Cygwin 的安裝目錄,Install For 選擇"All Users",然後點選"下一步",進入如下圖所示對話方塊:

選擇本地安裝包的路徑,然後點選"下一步",進入如下圖所示對話方塊:
點選"確定",進入如下圖所示對話方塊:
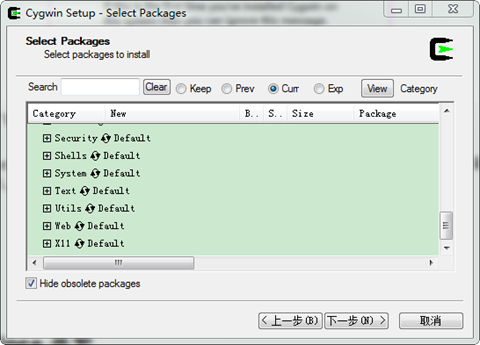
進入"Select Packages"對話方塊後,其實直接點選"下一步",進行預設安裝即可,為了以後再cygwin下面搭建hadoop環境,所以安裝了一些軟體。
- OpenSSL
- sed
- vim
必須保證"Net Category"下的"OpenSSL"被安裝,如下圖所示:

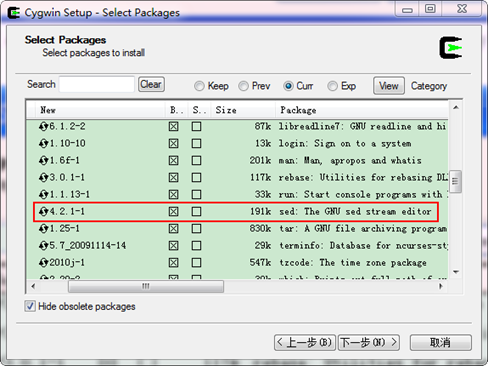
如果還打算在eclipse 上編譯Hadoop,則還必須安裝"Base Category"下的"sed",如
下圖所示:
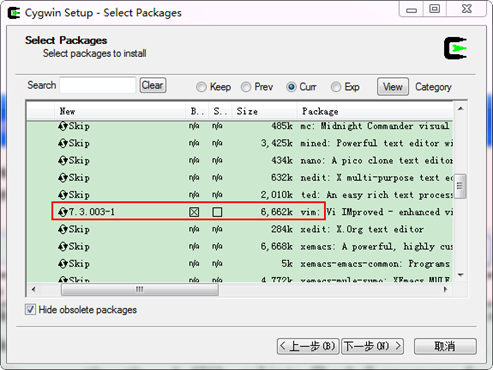
另外,還建議將"Editors Category"下的vim 安裝,以方便在Cygwin 上直接修改配置檔案,如下圖所示:
建議安裝在"Devel Category"下的subversion,如下圖所示:

當完成上述操作後,點選"Select Packages"對話方塊中"下一步",進入Cygwin 安裝包
下載過程,如下圖所示:
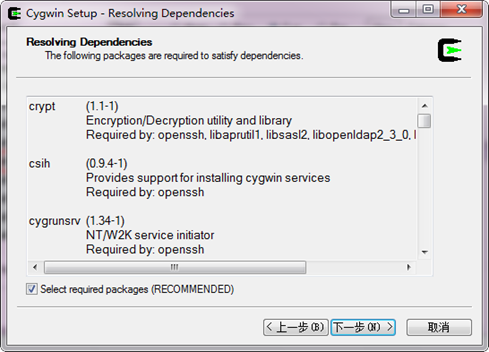
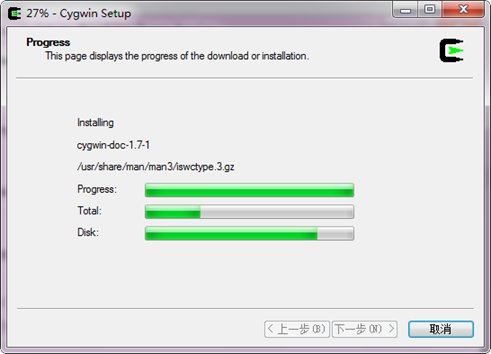
當安裝完後,會自動進入到如下圖所示的對話方塊:
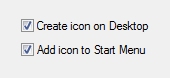
在上圖所示的對話方塊中,選中"Create icon on Desktop",以方便直接從桌面上啟動
Cygwin,然後點選"完成"按鈕。至此,Cgywin 已經安裝完,安裝目錄下的內容如下圖所示:
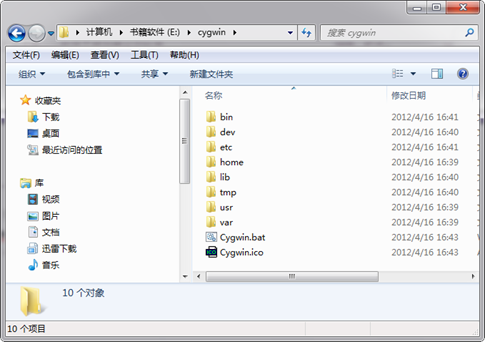
當安裝完Cygwin軟體之後,我們還需要對其設定它的環境變數。
【新建】
CYGWIN_HOME= E:\cygwin
【增加】
PATH=……;% CYGWIN_HOME %\bin
第一步:點選"新建",然後變數名寫上"CYGWIN_HOME",填上上面內容。
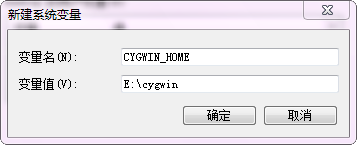
第二步:在系統變數裡找到Path,點選編輯。在後面追加上面內容。
2、Eclipse開發
2.1 Solr部署
第一步:把"apache-solr-3.5.0.zip"解壓到"E:\NutchWorkPlat"目錄下,並命名為"solr"。

第二步:把"E:\NutchWorkPlat\solr\dist"目錄下的"apache-solr-3.5.0.war"重新命名為"solr.war",並把它放到"E:\NutchWorkPlat\tomcat\webapps"目錄下面。
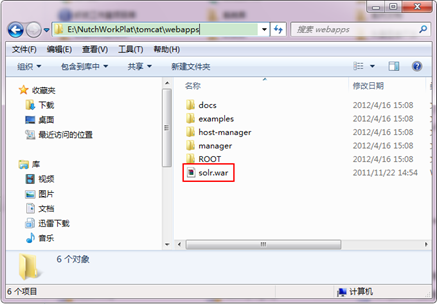
第三步:修改Tomcat配置檔案"E:\NutchWorkPlat\tomcat\conf\server.xml",新增中文編碼支援。
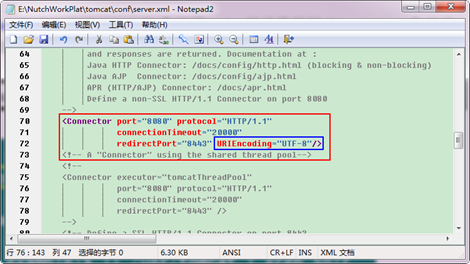
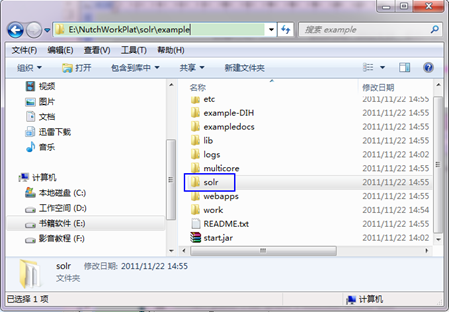
第四步:把"E:\NutchWorkPlat\solr\example"目錄下的"solr"資料夾連同裡面的內容一起復制到"E:\NutchWorkPlat\tomcat"目錄中。
第五步:在"E:\NutchWorkPlat\tomcat\conf\Catalina\localhost"下建立一個"solr.xml"檔案,內容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<Context docBase="E:\NutchWorkPlat\tomcat\webapps\solr.war" debug="0"
crossContext="true" >
<Environment name="solr/home" type="java.lang.String"
value="E:\NutchWorkPlat\tomcat\solr" override="true" />
</Context>
第六步:修改"E:\NutchWorkPlat\tomcat\solr\conf\ solrconfig.xml"找到下面這句話。
<queryResponseWriter
name="velocity"
class="solr.VelocityResponseWriter" enable="${solr.velocity.enabled:true}"/>
把 enable="${solr.velocity.enabled:true}中的true修改為false。
2.2 Nutch匯入
第一步:把"apache-nutch-1.4-bin.tar.gz"解壓到"E:\NutchWorkPlat"目錄下,並重命名為"nutch"。
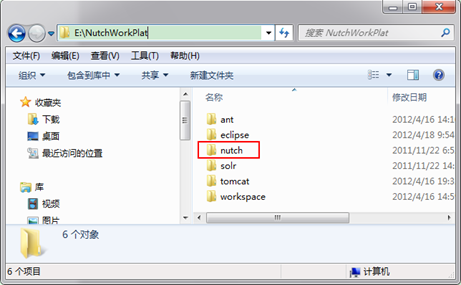
第二步:在eclipse中新建立一個Java Project,名字自己定義為Nutch1.4_V0.1,去掉預設路徑(Use default location)前面的對勾,選擇"E:\NutchWorkPlat\nutch"。其他保持預設,點選"next"。
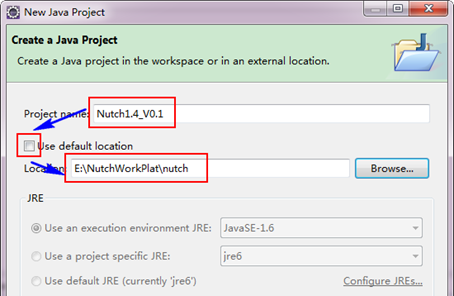
第三步:選擇"Librariesà Add Class Folder...",從列表中選擇"conf",將conf加入到classpath中。
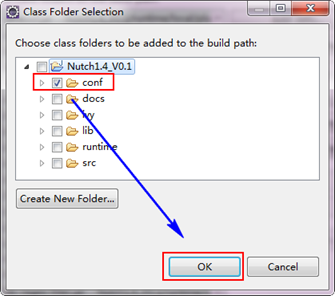
第四步:別著急點"next",選擇"Order and Export",選中"conf",點選"Top",使其置頂,此步驟非常關鍵,置頂之後,點選"Finish"。
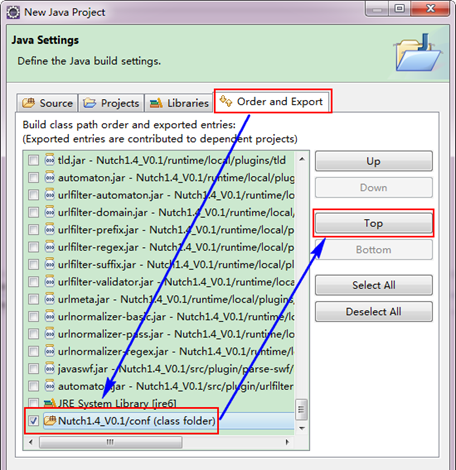
第五步:在"Nutch1.4_V0.1"工程根目錄下面建立"urls"資料夾(與src、conf同級),在裡面在建立一個名為"urls.txt"的檔案,在該檔案裡新增如下內容:
http://www.hebut.edu.cn
http://www.qq.com/
第六步:在"Nutch1.4_V0.1"工程根目錄下的conf資料夾中,編輯"nutch-site.xml",使其內容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>http.agent.name</name>
<value>My Nutch Spider</value>
</property>
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
</property>
</configuration>
備註:其中"http.agent.name"和"plugin.folders"必須設定,不然會出現"Job Failure"。
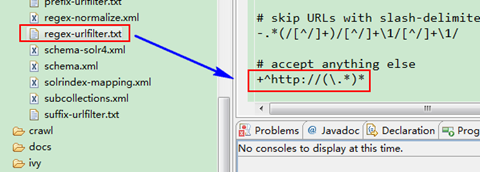
第七步:在"Nutch1.4_V0.1"工程根目錄下的conf資料夾中,編輯"regex-urlfilter.txt",在"# accept anything else"下面輸入:"+^http://(\.*)*",然後儲存。
第八步:經過上面的配置之後,就可以爬去網頁了,選中"Nutch1.4_V0.1"工程右擊選擇"Run AsàRun Configurations",從中找到"Java Application",然後右擊選擇"New",在Main Class選擇"org.apache.nutch.crawl.Crawl",將名字命名為"Crawl"。
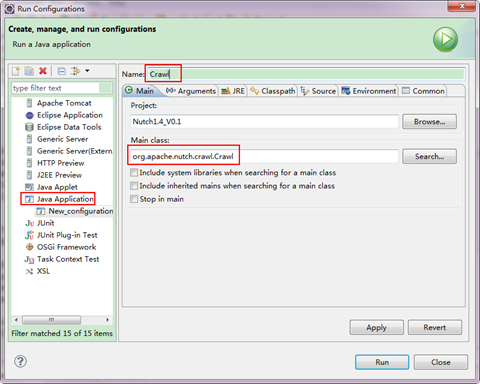
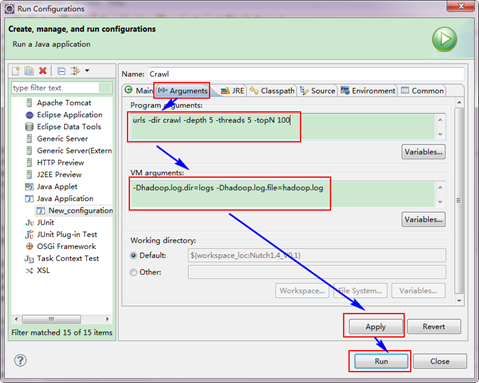
第八步:接著上面在"Arguments"選項卡中按下面進行填寫,然後點選"Apply與Run"。
- Program Arguments:urls -dir crawl -depth 5 -threads 5 -topN 100
- VM arguments:-Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log
2.3 Solr與Nutch結合
通過上面的步驟之後,指定的網頁已經抓取到本地了,現在我們就為我們下載的網頁建立索引。
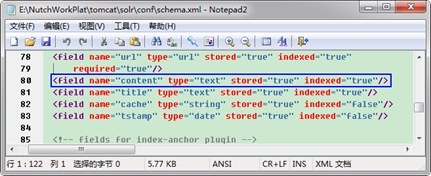
第一步:把"E:\NutchWorkPlat\nutch\conf"下面的"schema.xml"複製到Tomcat的安裝目錄"E:\NutchWorkPlat\tomcat\solr\conf"下,覆蓋掉原檔案。schema.xml設定了索引的欄位,把content項後面的stored="false" 改為 stored="true" 後在搜尋返回值中就會包含含有關鍵字的具體內容。
第二步:點選Eclipse工具欄的"Start Tomcat"即可啟動Tomcat。
備註:如果Tomcat已經起來了,在第一步完成之後,也應該重啟使其有效,如果不起動Tomcat,在建立索引時會失敗。
第三步:經過上面的配置之後,就可以建立索引了,選中"Nutch1.4_V0.1"工程右擊選擇"Run AsàRun Configurations",從中找到"Java Application",然後右擊選擇"New",在Main Class選擇"org.apache.nutch.indexer.solr.SolrIndexer",將其命名為"SolrIndexer"。
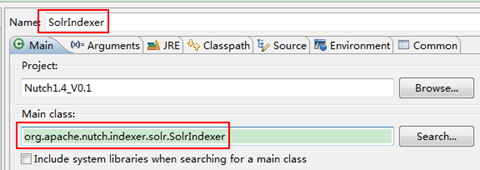
第四步:接著上面在"Arguments"選項卡中按下面進行填寫,然後點選"Apply與Run"。
- Program Arguments:
http://localhost:8080/solr/ crawl/crawldb -linkdb crawl/linkdb crawl/segments/*
- VM arguments:-Dhadoop.log.dir=logs -Dhadoop.log.file=hadoop.log
下面是Eclipse控制檯輸出資訊:
SolrIndexer: starting at 2012-04-18 14:45:41
Adding 352 documents
SolrIndexer: finished at 2012-04-18 14:45:56, elapsed: 00:00:14

下面就是查詢結果,以XML結果顯示。
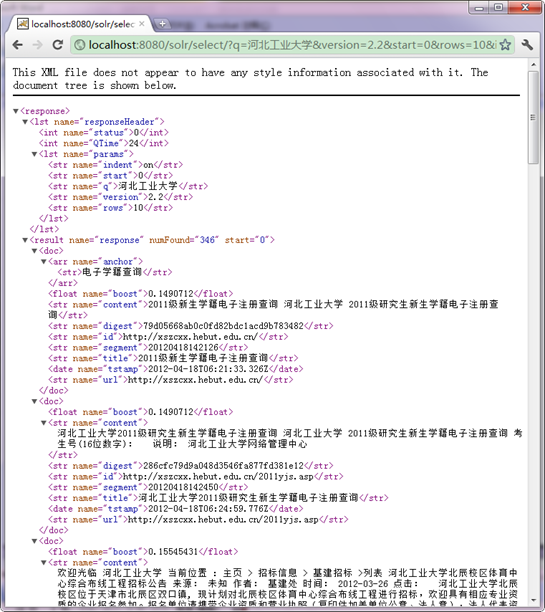
到目前為止,Nutch二次開發的前期工作已經準備完畢,並在上面進行簡單的抓取,後面我們將對Nutch的原始碼以及工作原理相結合進行分析。進一步認識Nutch。
相關推薦
Nutch搜尋引擎(第4期)_ Eclipse開發配置
1、環境準備 1.1 本期引言 前三期分別介紹了Nutch與Solr在Linux上面的安裝,並做了簡單的應用,這一期從開發的角度進行,因為我們日常最熟悉的開發環境是Windows,所以本期詳細介紹Windows平臺的Nutch二次開發所需要進行的配置安裝。當我們開發好之後,最後在部署到Linux環
Nutch搜尋引擎(第3期)_ Nutch簡單應用
1、Nutch命令詳解 Nutch採用了一種命令的方式進行工作,其命令可以是對區域網方式的單一命令也可以是對整個Web進行爬取的分步命令。 要看Nutch的命令說明,可執行"Nutch"命令。 下面是單個命令的說明: crawl crawl是"org.apache
Nutch搜尋引擎(第1期)_ Nutch簡介及安裝
1、Nutch簡介 Nutch是一個由Java實現的,開放原始碼(open-source)的web搜尋引擎。主要用於收集網頁資料,然後對其進行分析,建立索引,以提供相應的介面來對其網頁資料進行查詢的一套工具。其底層使用了Hadoop來做分散式計算與儲存,索引使用了Solr分散式索引框架來做,Solr是一
Nutch搜尋引擎(第2期)_ Solr簡介及安裝
1、Solr簡介 Solr是一個高效能,採用Java5開發,基於Lucene的全文搜尋伺服器。同時對其進行了擴充套件,提供了比Lucene更為豐富的查詢語言,同時實現了可配置、可擴充套件並對查詢效能進行了優化,並且提供了一個完善的功能管理介面,是一款非常優秀的全文搜尋引擎。 Solr最初由CNET
【算法(第4版)】筆記
bsp .com 二維 一個數 數組 png 初始 算法 nbsp 1、在 Java 程序中創建一個數組需要三步: 聲明數組的名字和類型; 創建數組; 初始化數組元素。 2、典型的數組處理代碼。 3、起別名。
平安科技移動開發二隊技術周報(第四期)
移動開發 程序猿 book watch 來看 home 錯誤 去那 this 平安科技移動開發二隊技術周報(第四期) 業界新聞 1)Java 9將於2016年正式公布 Oracle已經宣布了Java 9的時間表。其目標是在2016年9年正式公布
碼農·美妙的數學(第23期)pdf
日常 高中生 不可 存在 下載 file style microsoft 家庭教育 下載地址:網盤下載 本期碼農“鮮閱”文章,透過“阿司匹林銷售”案例和“鑰匙與門”遊戲場景,深刻揭示了致使“數學枯燥乏味”的教育根源。不然,“美妙的數學”一定也會帶給你我一段美好的高中生活。
Linux程式設計(第4版)
時至今日,Linux系統已經從一個個人作品發展為可以用於各種關鍵任務的成熟、高效和穩定的作業系統,因為具備跨平臺、開源、支援眾多應用軟體和網路協議等優點,它得到了各大主流軟硬體廠商的支援,也成為廣大程式設計人員理想的開發平臺。 本書是Linux程式設計領域的經典名著,以簡單易懂、內容全面和示例豐富而受到廣泛
大資料和雲端計算技術週報(第8期):NoSQL特輯
寫在第8期特輯 “大資料” 三個字事實上是個marketing語言,從技術角度看,包括範圍非常廣。計算、儲存、網路都涉及。 為了滿足眾多同學學習和工作的須要。後面社群依據情況逐漸推出專門的分類集錦。希望大家喜歡! 究竟什麼是NoSQL?公眾號一系列
Python學習手冊(第4版) PDF 下載
內容簡介 《Python學習手冊(第4版)》學習Python的主要內建物件型別:數字、列表和字典。使用Python語句建立和處理物件,並且學習Python的通用語法模型。使用函式構造和重用程式碼,函式是Python的基本過程工具。學習Python模組:封裝語句、函式以及其他工具,以便構
java小白自己動手開發一個網站之域名的申請(第4回)
新手小白,大神們看到什麼問題,請多多指出 目錄 域名的申請 域名的申請 之前想做部落格,聽說朋友用的阿里雲的域名很便宜,於是就過去申請了一個 登入賬號就是淘寶的賬號 地址: https://wanwang.al
IPFS官方週報(第11期)870天之後的迴歸
距離2016年5月8日IPFS官方部落格釋出第10期週報已經過去了870天,在2年多時間之後,IPFS官博的週報再次啟動,以下就是IPFS官博週報第11期的內容。 歡迎回到IPFS週報! InterPlanetary File System(IPFS,星際檔案系統)是一種新型的,基於內容
《 Spring 實戰 》(第4版) 讀書筆記
Pxx 表示在書的第 xx 頁。 Spring 框架的核心是 Spring 容器。 1. (P7.) 構造器注入是依賴注入的方式之一。 緊耦合:在 A 類的無參構造器中直接 new 出一個 B 類。 Spring 鬆耦合:在 A 類中使用有參構造器,把 B 類的超類型
IPFS官方最新週刊(第19期)
IPFS週刊第十九期的地址:https://blog.ipfs.io/52-ipfs-weekly-19/ 來源丨×××w.ipfs.cn_中國社群 歡迎來到IPFS週刊 行星際檔案系統(IPFS)是一種新的超媒體分發協議,由內容和身份解決。IPFS支援建立完全分散式應用程式。它旨在
IPFS官方最新週刊(第20期)
翻 譯丨IPFS中國社群:IP君 文章來源丨www.ipfs.cn 原文地址丨https://mp.weixin.qq.com/s/-ddMC0w3n8NdIILXtqzjLQ · IPFS週刊第20期的地址:檢視原文 · 歡迎來到IPFS週刊 行星際檔案系統(IPFS)是
霸屏瀏覽器使用說明書(第4版)
目錄 目錄 更新記錄 適用版本 介紹 遮蔽詳細 顯示遮蔽 按鍵遮蔽(不在列表中的按鍵,將被遮蔽) 功能遮蔽 安裝 使用方法
Java程式設計師面試寶典(第4版)
網站 更多書籍點選進入>> CiCi島 下載 電子版僅供預覽及學習交流使用,下載後請24小時內刪除,支援正版,喜歡的請購買正版書籍 電子書下載(皮皮雲盤-點選“普通下載”) 購買正版 封頁 編輯推薦 揭開知名IT企業面試、筆試
Java 從入門到精通(第4版)第5章 字串
開始講解之前,先列出本章的提綱,如下圖所示: 5.1 String類 5.1.1 宣告字串 String str; 5.1.2 建立字串 String str1 = new String("student"); System.out.println(str1); char
《影象處理、分析與機器視覺》(第4版)閱讀筆記——第四章 影象分析的資料結構
4.1 影象資料表示的層次 共分為四個層次: 最底層的表示:圖示影象(iconic images),由含有原始資料的影象組成,原始資料也就是畫素亮度資料的整數矩陣。(預處理的部分) 第二層的表示:分割影象(segmented images)。 第三層:幾何表示(geo
python學習手冊(第4版) 第十七章 作用域
變數的作用域由變數所在的檔案的位置決定的,而不是由函式呼叫決定的。 模組定義的是全域性作用域,此處的全域性,僅限於此模組;(整個專案的全域性變數,需要藉助於單例) 函式定義的是本地作用域,僅限於函式本身。 LEGB原則: python搜尋4個作用域:本地作用域