
Apache Spark 2.3.0 重要特性介紹
文章標題
Introducing Apache Spark 2.3
Apache Spark 2.3 介紹
Now Available on Databricks Runtime 4.0
現在可以在Databrcks Runtime 4.0上使用。
作者介紹
文章正文:
Today we are happy to announce the availability of Apache Spark 2.3.0 on Databricks as part of its Databricks Runtime 4.0. We want to thank the Apache Spark community for all their valuable contributions to Spark 2.3 release.
今天,我們很高興地

Continuing with the objectives to make Spark faster, easier, and smarter, Spark 2.3 marks a major milestone for Structured Streaming by introducing low-latency continuous processing and stream-to-stream joins; boosts PySpark by improving performance with pandas UDFs; and runs on Kubernetes clusters by providing native support for Apache Spark applications.
In addition to extending new functionality to SparkR, Python, MLlib, and GraphX, the release focuses on usability, stability, and refinement, resolving over 1400 tickets. Other salient features from Spark contributors include:
In this blog post, we briefly summarize some of the high-level features and improvements, and in the coming days, we will publish in-depth blogs for these features. For a comprehensive list of major features across all Spark components and JIRAs resolved, read the
1、Continuous Stream Processing at Millisecond Latencies
Structured Streaming in Apache Spark 2.0 decoupled micro-batch processing from its high-level APIs for a couple of reasons. First, it made developer’s experience with the APIs simpler: the APIs did not have to account for micro-batches. Second, it allowed developers to treat a stream as an infinite table to which they could issue queries as they would a static table.
However, to provide developers with different modes of stream processing, we introduce a new millisecond low-latency mode of streaming: continuous mode.
Under the hood, the structured streaming engine incrementally executed query computations in micro-batches, dictated by a trigger interval, with tolerable latencies suitable for most real-world streaming applications.
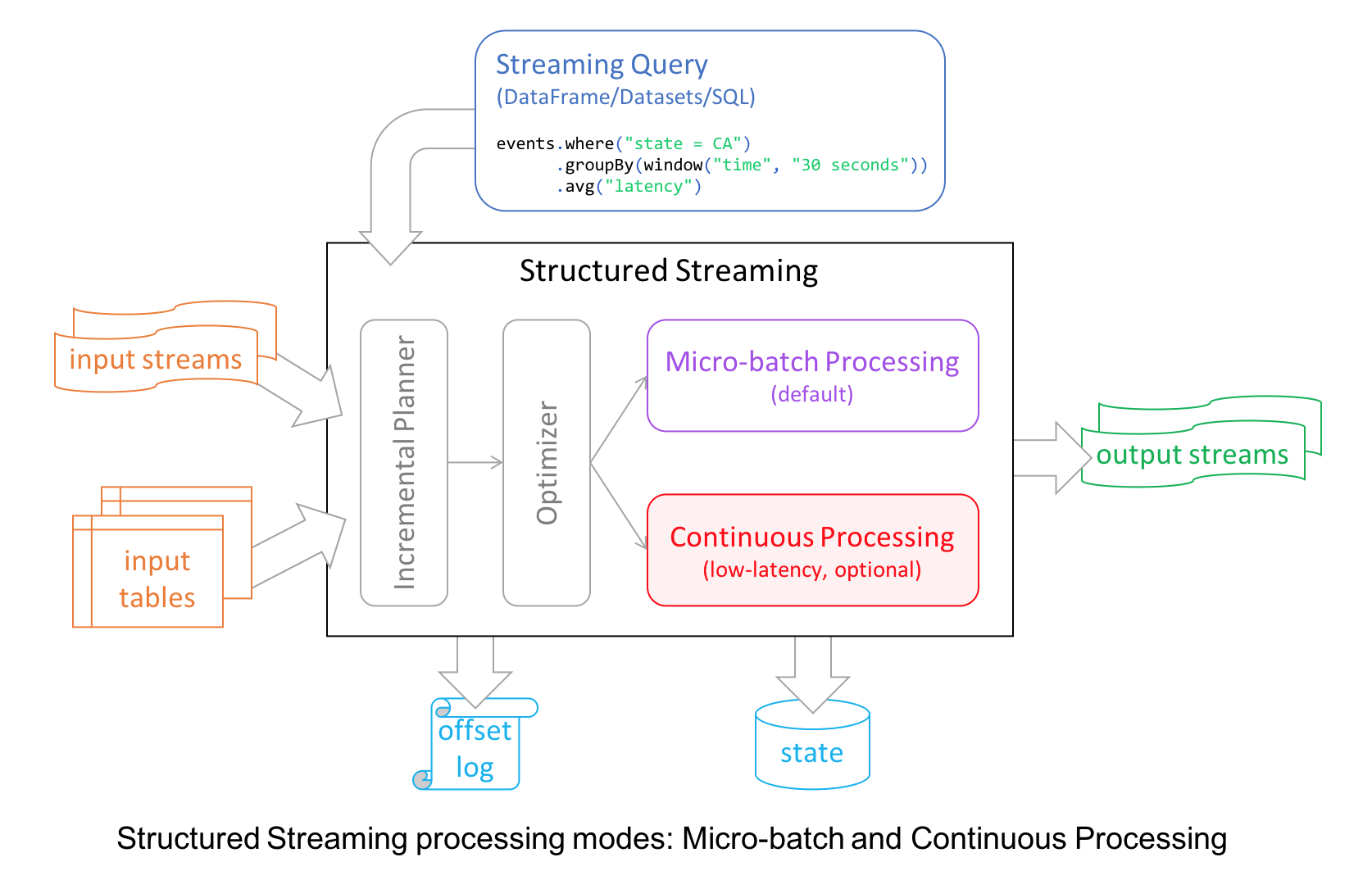
For continuous mode, instead of micro-batch execution, the streaming readers continuously poll source and process data rather than read a batch of data at a specified trigger interval. By continuously polling the sources and processing data, new records are processed immediately upon arrival, as shown in the timeline figure below, reducing latencies to milliseconds and satisfying low-level latency requirements.

As for operations, it currently supports map-like Dataset operations such as projections or selections and SQL functions, with the exception of current_timestamp(), current_date() and aggregate functions. As well as supporting Apache Kafka as a source and sink, continuous mode currently supports console and memory as sinks, too.
Now developers can elect either mode—continuous or micro-batching—depending on their latency requirements to build real-time streaming applications at scale while benefiting from the fault-tolerance and reliability guarantees that Structured Streaming engine affords.
In short, the continuous mode in Spark 2.3 is experimental and it offers the following:
- end-to-end millisecond low latencies
- provides at-least-once guarantees.
- supports map-like Dataset operations
In this technical blog on Continuous Processing mode, we illustrate how to use it, its merits, and
how developers can write continuous streaming applications with millisecond low-latency requirements.
2、Stream-to-Stream Joins
While Structured Streaming in Spark 2.0 has supported joins between a streaming DataFrame/Dataset and a static one, this release introduces the much awaited stream-to-stream joins, both inner and outer joins for numerous real-time use cases.
The canonical use case of joining two streams is that of ad-monetization. For instance, an impression stream and an ad-click stream share a common key (say, adId) and relevant data on which you wish to conduct streaming analytics, such as, which adId led to a click.
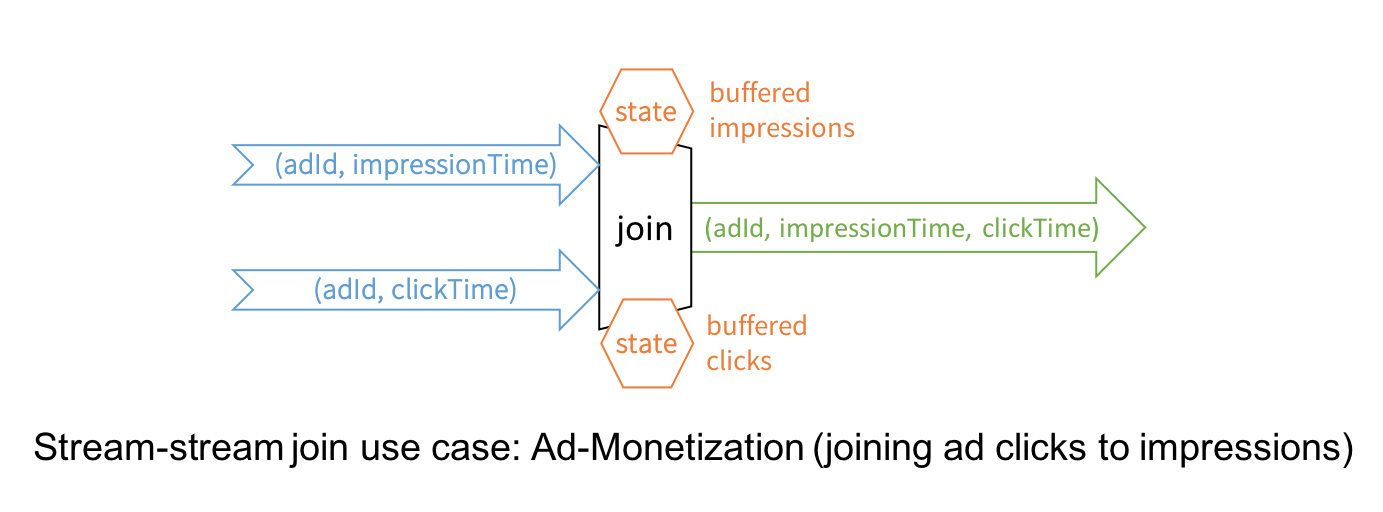
While conceptually the idea is simple, stream-to-stream joins resolve a few technical challenges. For example, they:
- handle delayed data by buffering late events as streaming “state” until matching event is found from the other stream
- limit the buffer from growing and consuming memory with watermarking, which allows tracking of event-time and accordingly clearing of old state
- allow a user to control the tradeoff between the resources consumed by state and the maximum delay handled by the query
- maintain consistent SQL join semantics between static joins and streaming joins
In this technical blog, we dive deeper into streams-to-stream joins.
3、Apache Spark and Kubernetes
No surprise that two popular open source projects Apache Spark and Kubernetes combine their functionality and utility to provide distributed data processing and orchestration at scale. In Spark 2.3, users can launch Spark workloads natively on a Kubernetes cluster leveraging the new Kubernetes scheduler backend. This helps achieve better resource utilization and multi-tenancy by enabling Spark workloads to share Kubernetes clusters with other types of workloads.
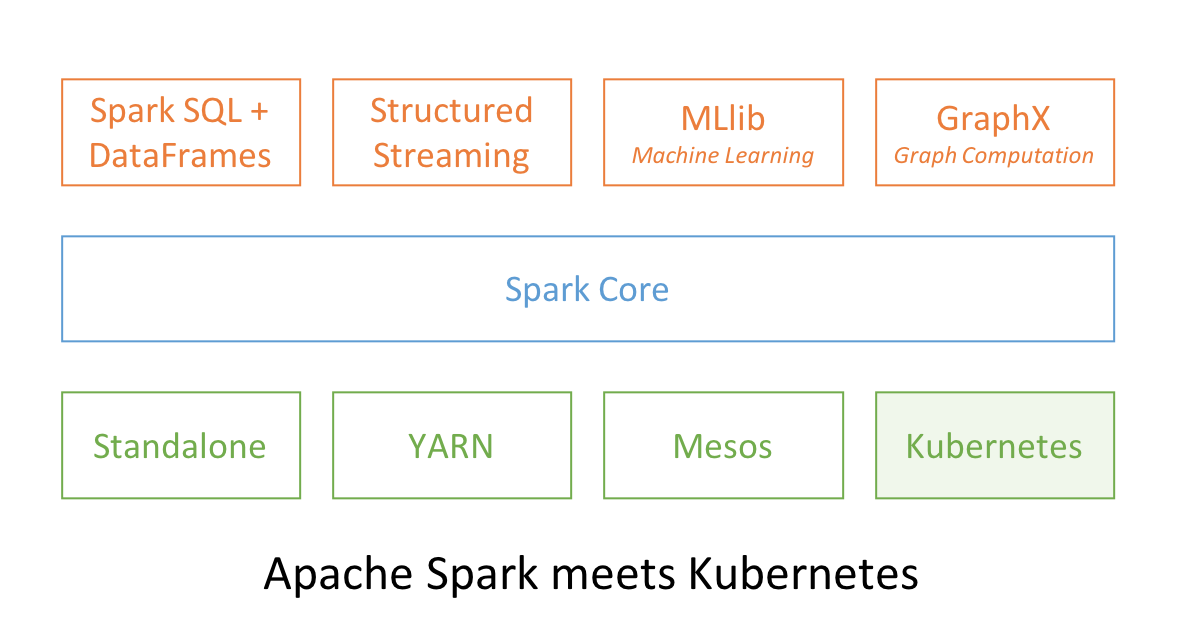
Also, Spark can employ all the administrative features such as Resource Quotas, Pluggable Authorization, and Logging. What’s more, it’s as simple as creating a docker image and setting up the RBAC to start employing your existing Kubernetes cluster for your Spark workloads.
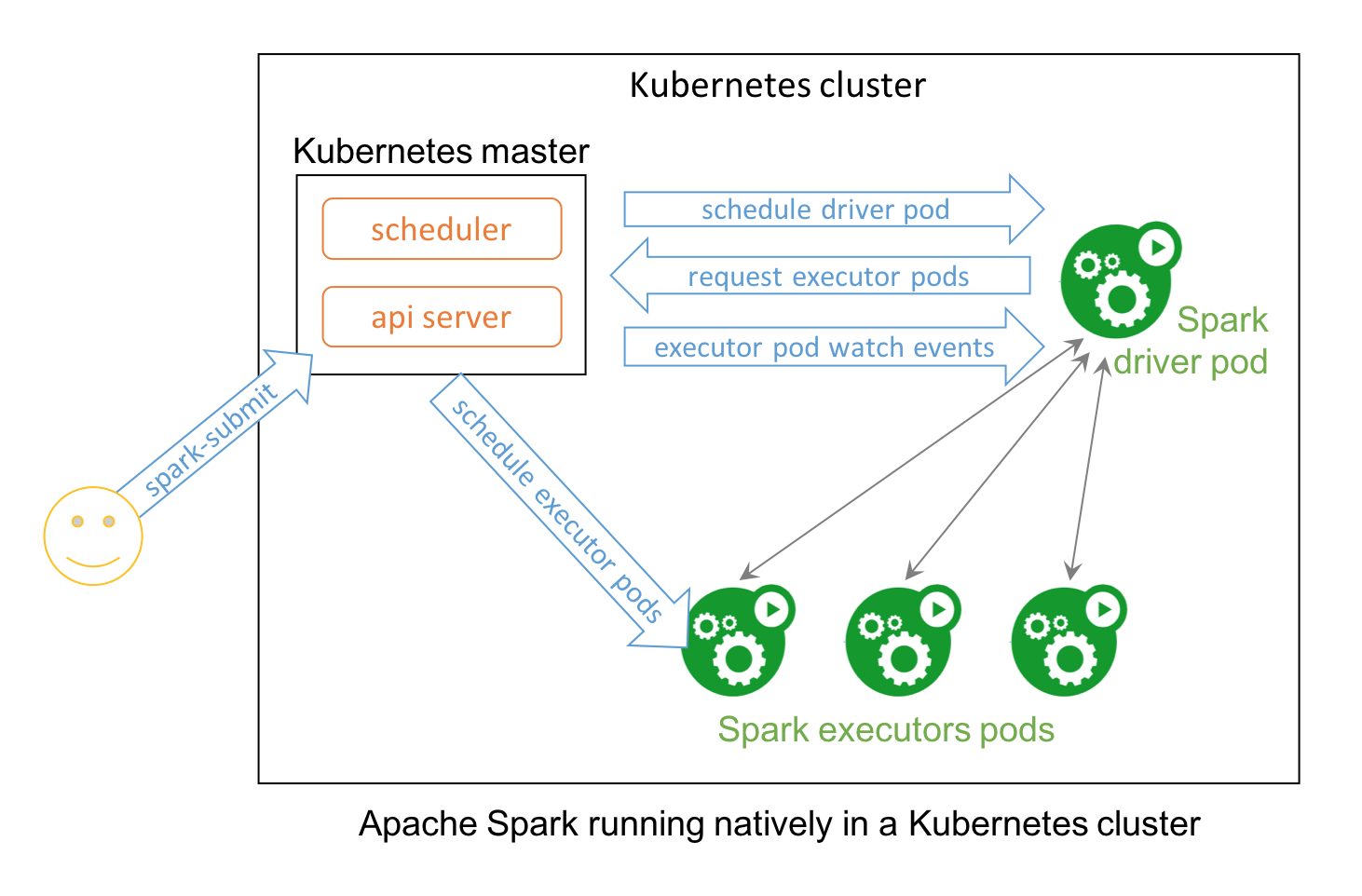
This technical blog explains how you can use Spark natively with Kubernetes and how to get involved in this community endeavor.
4、Pandas UDFs for PySpark
Pandas UDFs, also called Vectorized UDFs, is a major boost to PySpark performance. Built on top of Apache Arrow, they afford you the best of both worlds—the ability to define low-overhead, high-performance UDFs and write entirely in Python.
In Spark 2.3, there are two types of Pandas UDFs: scalar and grouped map. Both are now available in Spark 2.3. Li Jin of Two Sigma had penned an earlier blog, explaining their usage through four examples: Plus One, Cumulative Probability, Subtract Mean, Ordinary Least Squares Linear Regression.
Running some micro benchmarks, Pandas UDFs demonstrate orders of magnitude better performance than row-at-time UDFs.
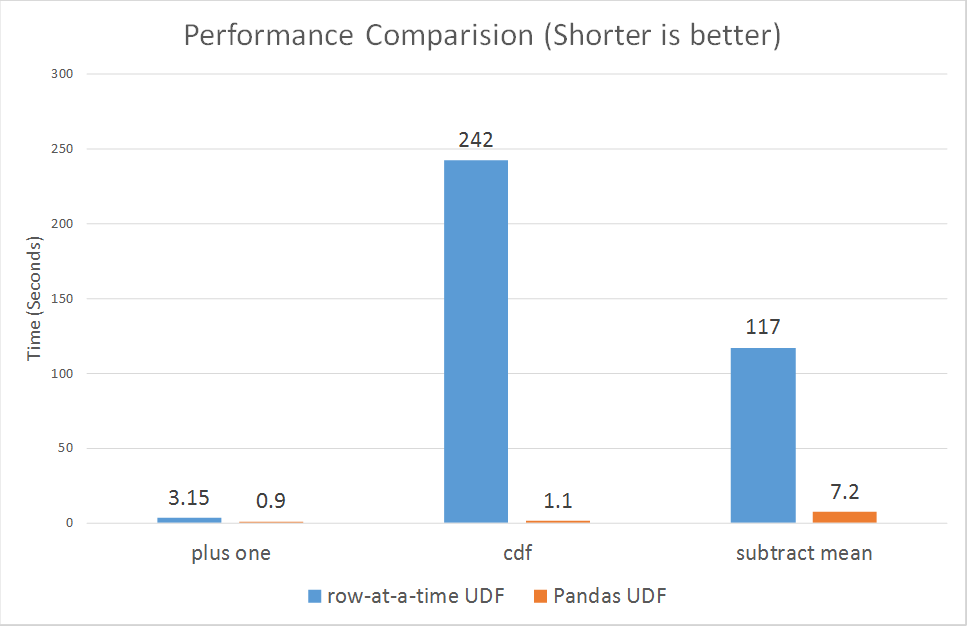
According to Li Jin and other contributors, they plan to introduce support for Pandas UDFs in aggregations and window functions, and its related work can be tracked in SPARK-22216.
5、MLlib Improvements
Spark 2.3 includes many MLlib improvements for algorithms and features, performance and scalability, and usability. We mention three highlights.
First, for moving MLlib models and Pipelines to production, fitted models and Pipelines now work within Structured Streaming jobs. Some existing Pipelines will require modifications to make predictions in streaming jobs, so look for upcoming blog posts on migration tips.
Second, to enable many Deep Learning image analysis use cases, Spark 2.3 introduces an ImageSchema [SPARK-21866] for representing images in Spark DataFrames, plus utilities for loading images from common formats.
And finally, for developers, Spark 2.3 introduces improved APIs in Python for writing custom algorithms, including a UnaryTransformer for writing simple custom feature transformers and utilities for automating ML persistence for saving and loading algorithms. See this blog post for details.
參考文獻:
相關推薦
Apache Spark 2.3.0 重要特性介紹
文章標題 Introducing Apache Spark 2.3 Apache Spark 2.3 介紹 Now Available on Databricks Runtime 4.0 現在可以在Databrcks Runtime 4.0上使用。 作者介紹 文章正文: Today we a
Apache Spark 2.3 重要特性介紹
情況 緩存 panda image author cluster 所有 分析方法 deep 為了繼續實現 Spark 更快,更輕松,更智能的目標,Spark 2 3 在許多模塊都做了重要的更新,比如 Structured Streaming 引入了低延遲的連續處理(cont
kylin_異常_01_java.io.FileNotFoundException: /developer/apache-kylin-2.3.0-bin/tomcat/conf/.keystore
hadoop bstr store iat path ioe .proto https class 一、異常現象 kylin安裝完,啟動後,控制正常,kylin後臺也能正常訪問。但是去看kylin的日誌,卻發現報錯了: SEVERE: Failed to load
Apache Spark 2.3 運行在Kubernete實戰
https llb pen message vbs token CMF spa ive 下載源代碼,並解壓下載地址 tar -zxvf v2.3.2.tar.gz 編譯 cd spark-2.3.2 build/mvn install -DskipTests buil
Apache CouchDB 2.3.0 釋出,文件資料庫
Apache CouchDB 2.3.0 已釋出,Apache CouchDB 是一個面向文件的資料庫管理系統。它提供以 JSON 作為資料格式的 REST 介面來對其進行操作,並可以通過檢視來操縱文件的組織和呈現。CouchDB 是 Apache 基金會的頂級開源專案。
Spark 2.3.0+Kubernetes應用程式部署
Spark2.3.0+Kubernetes應用程式部署Spark可以執行在Kubernetes管理的叢集中,利用Native Kubernetes排程的特點已經被加入Spark。目前Kubernetes排程是實驗性的,在未來的版本中,Spark在配置、容器映像、入口可能會有
windows10下使用spark-2.3.0-bin-without-hadoop相關問題
1、啟動spark-shell報錯:Error: A JNI error has occurred, please check your installation and try again Exception in thread "main" java.lang.NoCla
Hadoop-3.0.0 + spark-2.3.0 +storm-1.2.1 的安裝心得
因為前段時間比賽用到spark,而實驗室叢集的spark版本還是1.6,帶來了不少麻煩,於是便想著把叢集的Hadoop和spark更新一下版本,另外,因為專案需要,再補裝個storm,一邊日後要用。說句題外話。spark,storm,Hadoop三者取首字母是SSH,這讓我想
Apache Spark 2.2.0新特性介紹(轉載)
端到端 clas flat ket 性能 保序回歸 rime day 工作 這個版本是 Structured Streaming 的一個重要裏程碑,因為其終於可以正式在生產環境中使用,實驗標簽(experimental tag)已經被移除。在流系統中支持對任意狀態進行操作;
Apache Spark 2.4 正式釋出,重要功能詳細介紹
本文中文原文:https://www.iteblog.com/archives/2448.htm
Spark Release 2.3.0 版本釋出新特性和優化
Apache Spark 2.3.0是2.x系列中的第四個版本。此版本增加了對結構化流中的連續處理以及全新的Kubernetes Scheduler後端的支援。其他主要更新包括新的DataSource和結構化Streaming v2 API,以及一些PySpark效能增強。此
Apache Flink 1.3.0正式發布及其新功能介紹
space str either update sse ant 新功能 sid ask 下面文檔是今天早上翻譯的,因為要上班,時間比較倉促,有些部分沒有翻譯,請見諒。 2017年06月01日兒童節 Apache Flink 社區正式發布了 1.3.0 版本。此版本經歷了四個
Servlet 2.0 && Servlet 3.0 新特性
ack amp 特性 call all callback 如何 nbsp let 概念:透傳。 Callback 在異步線程中是如何使用的。?? Servlet 2.0 && Servlet 3.0 新特性 Servlet 2.0 &a
Apache Spark 2.2.0 中文文檔 - SparkR (R on Spark) | ApacheCN
機器學習 matrix ren mes 網頁 eve growth ear 統計 SparkR (R on Spark) 概述 SparkDataFrame 啟動: SparkSession 從 RStudio 來啟動 創建 SparkDataFrames 從本地
Apache Spark 2.0三種API的傳說:RDD、DataFrame和Dataset
sensor json數據 query 答案 內存 table 引擎 library spark Apache Spark吸引廣大社區開發者的一個重要原因是:Apache Spark提供極其簡單、易用的APIs,支持跨多種語言(比如:Scala、Java、Python和R
APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
new limit runtime font blank eth epo rmi syn What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If yo
scala spark-streaming整合kafka (spark 2.3 kafka 0.10)
obj required word 錯誤 prope apache rop sta move Maven組件如下: <dependency> <groupId>org.apache.spark</groupId> <
java8下spark-streaming結合kafka程式設計(spark 2.3 kafka 0.10)
前面有說道spark-streaming的簡單demo,也有說到kafka成功跑通的例子,這裡就結合二者,也是常用的使用之一。 1.相關元件版本 首先確認版本,因為跟之前的版本有些不一樣,所以才有必要記錄下,另外仍然沒有使用scala,使用java8,spark 2.0.0,kafk
【譯】Apache spark 2.4:內建 Image Data Source的介紹
Apache spark 2.4:內建 Image Data Source的介紹 [原文連結](https://databricks.com/blog/2018/12/10/introducing-built-in-image-data-source-in-apache-spark-2-4.html)
3臺機器配置spark-2.1.0叢集
一. 環境介紹 三臺主機,主機名和ip分別為: ubuntu1 10.3.19.171 ubuntu2 10.3.19.172 ubuntu3 10.3.19.173 三臺主機的登入使用者名稱是bigdata,home目錄是/home/bigdata 現在三臺主機上部