
分庫分表利器——sharding-sphere
背景
得不到的東西讓你徹夜難眠,沒有嘗試過的技術讓我躍躍欲試。
本著殺雞焉用牛刀的準則,我們倡導夠用就行,不跟風,不盲從。
所以,結果就是我們一直沒有真正使用分庫分表。曾經好幾次,感覺沒有分庫分表(起碼要分表),專案就做不下去了,但是由於跨部門、工具約束、專案被砍等各種原因最終都偃旗息鼓,乖乖的搞單表加索引去了。
應該是沒有及時同步公司內部知識庫的原因,過去的幾次分庫分表的嘗試也是讓人哭笑不得。公司內部流傳著一件上古神器,可以解決分表問題。
既然是上古神器,那麼使用的流程肯定也是非常原始。沒錯,因為是基於windows系統寫的一個桌面程式,所以必須到windows平臺安裝執行,而公司絕大多數已經不用windows系統了。針對這個問題,有兩個解決方式,一種是找桌上型電腦,一種是安裝虛擬機器。
我選擇了後者,畢竟自己安裝,獨立自主,可以隨心所欲的操作。好了,環境算是有了,這時候肯定要有個教程,畢竟口口相傳這種模式會隨著時間的推移慢慢變得不好使了,尤其是使用場景不多的情況下。
開啟教程的那一刻,彷彿拿到的是易筋經這樣的武功祕籍,裡面只有幾張內功心法似的截圖,要想參透,全靠自己領悟。
睜大眼睛,在放大縮小拖拽各種操作中,領會截圖的真正含義,生怕出現像漏看“欲練此功,必先自宮”的下半句“如不自宮,也能成功”帶來的慘痛教訓經歷。
每一步都很小心,然後點選相應的神奇按鈕。一通操作,Duang,分表就完成了,而且連相應的ibatis檔案都生成好了。你需要做的就是在程式碼裡面呼叫相應介面就好了。
可以想見,作為上古神器,自有其光芒的地方,但是可能因為年久失修,所以理解上會有些難度。雖然一通操作猛如虎,但是回頭讓你再詳述下具體的流程可能已經忘得差不多了。
後來,在部門內部是有小夥伴專門研究過並做了分享,但是鑑於使用場景不多,所以沒有引起大家過多的關注。公司內部也有其他部門引進或者自研出了更好的工具,但是沒有參加分享,所以也是一度擱置。
這次的專案按照老大一貫擴充套件性的做法,應該是要做分表的了,沒成想,初步過方案的時候說分啥表,現在的量級單表完全夠用。好吧,雖然表沒分成,但是接觸到了分表利器sharding-sphere。
sharding-sphere
簡介
Sharding-Sphere是一套開源的分散式資料庫中介軟體解決方案組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar這3款相互獨立的產品組成。他們均提供標準化的資料分片、讀寫分離、柔性事務和資料治理功能,可適用於如Java同構、異構語言、容器、雲原生等各種多樣化的應用場景。
官網
Github
三大核心模組分別是Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar。
Sharding-JDBC
定位為輕量級Java框架,在Java的JDBC層提供的額外服務。 它使用客戶端直連資料庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全相容JDBC和各種ORM框架。
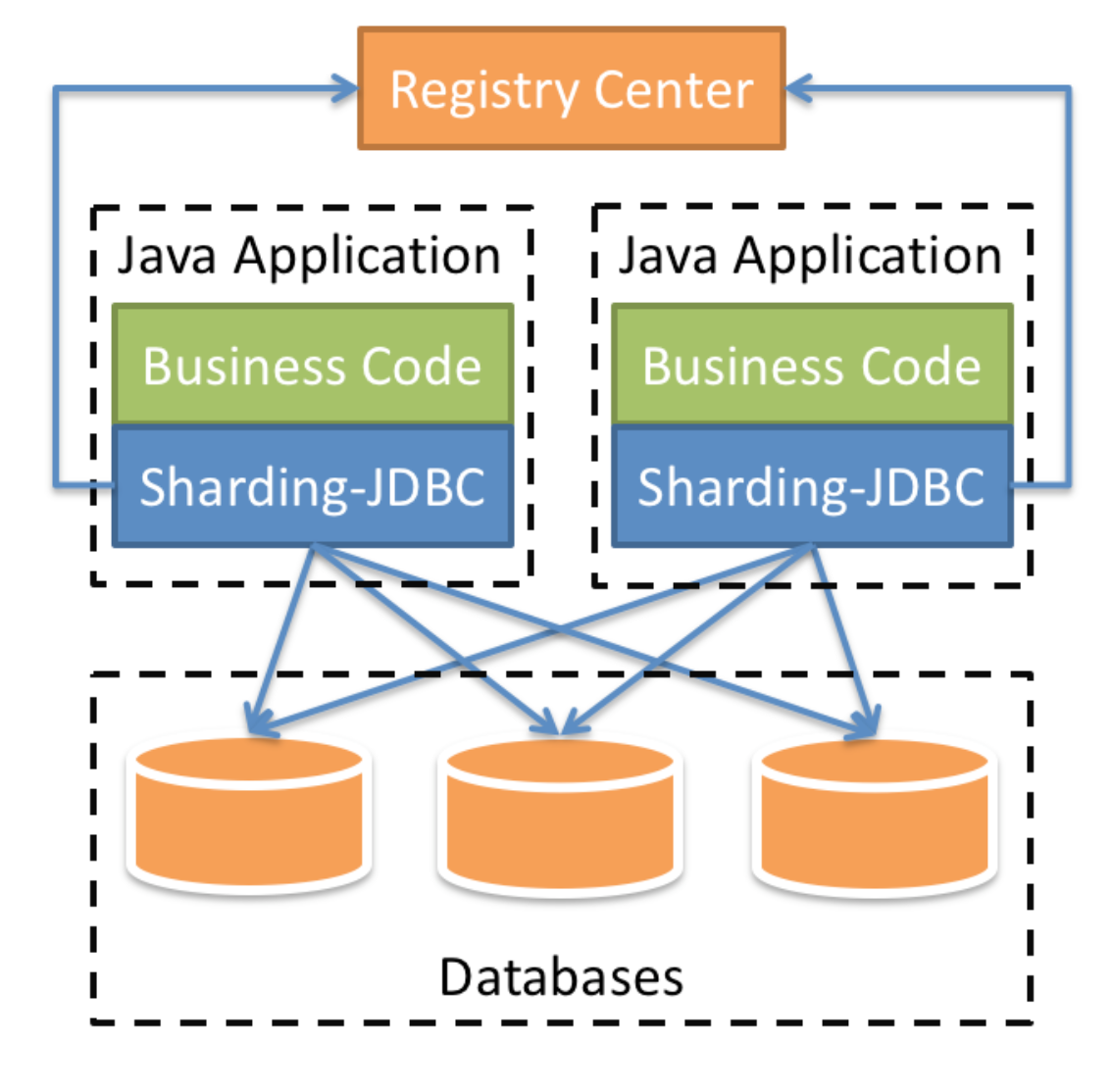
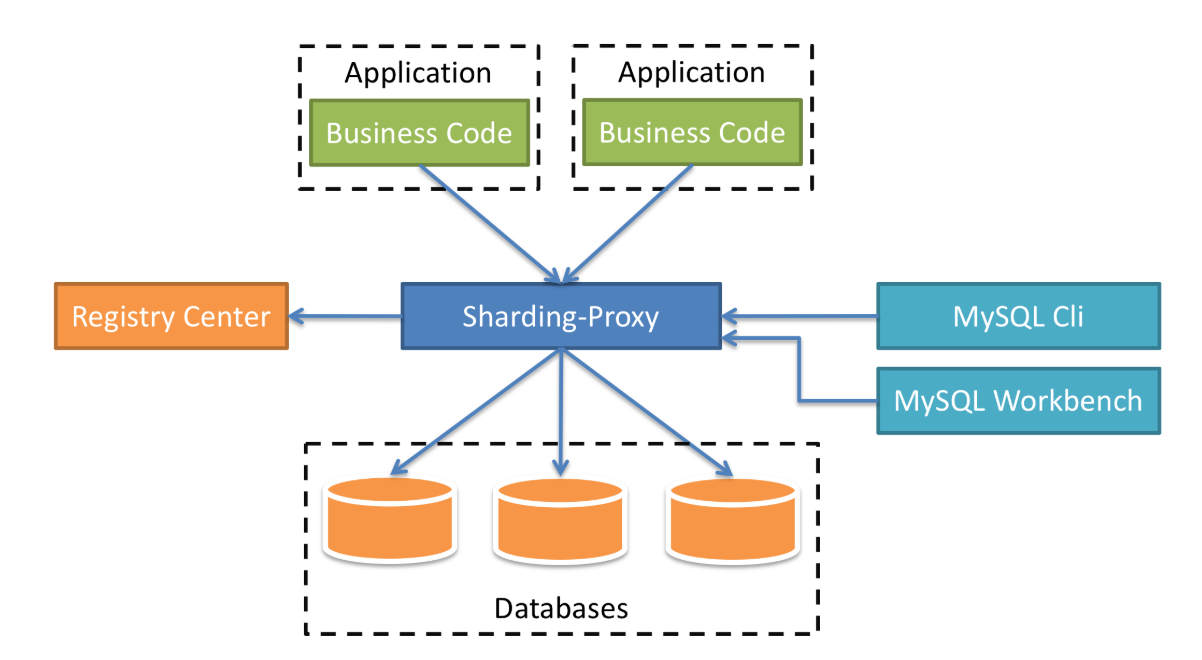
Sharding-Proxy
定位為透明化的資料庫代理端,提供封裝了資料庫二進位制協議的服務端版本,用於完成對異構語言的支援。 目前先提供MySQL版本,它可以使用任何相容MySQL協議的訪問客戶端(如:MySQL Command Client, MySQL Workbench等)操作資料,對DBA更加友好。
Sharding-Sidecar
定位為Kubernetes或Mesos的雲原生資料庫代理,以DaemonSet的形式代理所有對資料庫的訪問。 通過無中心、零侵入的方案提供與資料庫互動的的齧合層,即Database Mesh,又可稱資料網格。

sharding-sphere-example
在Github上分別有三個專案,分別是sharding-sphere、sharding-sphere-doc和sharding-sphere-example。從字面就可以看出每個專案是做什麼的。
既然是要入門,那就clone下sharding-sphere-example這個專案。
1、克隆專案
在命令列執行git clone https://github.com/sharding-sphere/sharding-sphere-example.git
完成後,就可以看到sharding-sphere-example專案,匯入intellij idea中。
2、編譯專案
進入專案根目錄下,編譯專案。
我這邊下載的專案sharding-sphere.version是3.0.0.M2-SNAPSHOT,編譯的時候一直報該版本找不到,無法下載,去中央倉庫也沒有找到。
想著可能要本地編譯打包,所以就換成了3.0.0.M1版本,編譯通過。
3、配置資料來源
因為是本機測試,所以在本地配置mysql資料庫。

4、編寫資料分片程式碼
sharding-sphere-example專案中有基於不同場景包括spring-boot、jpa、mybatis的具體分庫分表的例項程式碼。
本文主要結合sharding-sphere官方文件給出的資料分片程式碼講解如何實現分庫分表的。
測試類ShardingDataSource(自建測試類,來源http://shardingsphere.io/document/current/cn/manual/sharding-jdbc/usage/sharding/)
package practice;
import io.shardingsphere.core.api.ShardingDataSourceFactory;
import io.shardingsphere.core.api.config.ShardingRuleConfiguration;
import io.shardingsphere.core.api.config.TableRuleConfiguration;
import io.shardingsphere.core.api.config.strategy.InlineShardingStrategyConfiguration;
import io.shardingsphere.example.jdbc.fixture.DataRepository;
import org.apache.commons.dbcp.BasicDataSource;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ConcurrentHashMap;
public class ShardingDataSource {
public static void main(String[] args) throws SQLException {
ShardingDataSource shardingDataSource = new ShardingDataSource();
DataSource dataSource = shardingDataSource.sharding();
new DataRepository(dataSource).demo();
}
public DataSource sharding() throws SQLException {
// 配置真實資料來源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第一個資料來源
BasicDataSource dataSource1 = new BasicDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://127.0.0.1:3306/ds0");
dataSource1.setUsername("root");
dataSource1.setPassword("root");
dataSourceMap.put("ds0", dataSource1);
// 配置第二個資料來源
BasicDataSource dataSource2 = new BasicDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://127.0.0.1:3306/ds1");
dataSource2.setUsername("root");
dataSource2.setPassword("root");
dataSourceMap.put("ds1", dataSource2);
// 配置Order表規則
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable("t_order");
orderTableRuleConfig.setActualDataNodes("ds${0..1}.t_order${0..1}");
// 配置分庫 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_item_id", "t_order_item${order_item_id % 2}"));
// 配置分片規則
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 配置order_item表規則...
TableRuleConfiguration orderItemTableRuleConfig = new TableRuleConfiguration();
orderItemTableRuleConfig.setLogicTable("t_order_item");
orderItemTableRuleConfig.setActualDataNodes("ds${0..1}.t_order_item${0..1}");
shardingRuleConfig.getTableRuleConfigs().add(orderItemTableRuleConfig);
// 獲取資料來源物件
return ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), new Properties());
}
}注意
1、程式碼中類似"ds\({0..1}.t_order\){0..1}"成為行表示式,形如"\({ expression }或\)->{ expression }"。該表示式可用於配置資料節點和配置分片演算法。
${begin..end}表示範圍區間,即表示從begin到end個
${[unit1, unit2, unit_x]}表示列舉值
2、orderTableRuleConfig.setActualDataNodes("ds\({0..1}.t_order\){0..1}");
這裡表示的是使用行表示式配置資料節點即資料庫分別是ds0、ds1,表分別是t_order0、t_order1。
該表達的等價組合是:ds0.t_order0, ds0.t_order1, ds1.t_order0, ds1.t_order1。
3、orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order${order_id % 2}"));
這裡表示的是使用行表示式配置分片演算法。該行表示針對t_order表中的元素按照order_id模2將不同的元素放進不同的表中。
比如order_id=5,5%2=1,則放入t_order1中
order_id=6, 6%2=0, 則放入t_order0中
4、除此以外還要一些類似"邏輯表"這樣的概念,可以到官方文件自行查詢。
工具類DataRespository(該類來源sharding-sphere-example專案)
/*
* Copyright 2016-2018 shardingsphere.io.
* <p>
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
* </p>
*/
package io.shardingsphere.example.jdbc.fixture;
import io.shardingsphere.core.api.HintManager;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class DataRepository {
private final DataSource dataSource;
public DataRepository(final DataSource dataSource) {
this.dataSource = dataSource;
}
public void demo() throws SQLException {
createTable();
insertData();
System.out.println("1.Query with EQUAL--------------");
queryWithEqual();
System.out.println("2.Query with IN--------------");
queryWithIn();
System.out.println("3.Query with Hint--------------");
queryWithHint();
System.out.println("4.Drop tables--------------");
dropTable();
System.out.println("5.All done-----------");
}
private void createTable() throws SQLException {
execute("CREATE TABLE IF NOT EXISTS t_order (order_id BIGINT NOT NULL AUTO_INCREMENT, user_id INT NOT NULL, status VARCHAR(50), PRIMARY KEY (order_id))");
execute("CREATE TABLE IF NOT EXISTS t_order_item (order_item_id BIGINT NOT NULL AUTO_INCREMENT, order_id BIGINT NOT NULL, user_id INT NOT NULL, PRIMARY KEY (order_item_id))");
}
private void insertData() throws SQLException {
for (int i = 1; i < 10; i++) {
long orderId = insertAndGetGeneratedKey("INSERT INTO t_order (user_id, status) VALUES (10, 'INIT')");
execute(String.format("INSERT INTO t_order_item (order_id, user_id) VALUES (%d, 10)", orderId));
orderId = insertAndGetGeneratedKey("INSERT INTO t_order (user_id, status) VALUES (11, 'INIT')");
execute(String.format("INSERT INTO t_order_item (order_id, user_id) VALUES (%d, 11)", orderId));
}
}
private long insertAndGetGeneratedKey(final String sql) throws SQLException {
long result = -1;
try (
Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement()) {
statement.executeUpdate(sql, Statement.RETURN_GENERATED_KEYS);
try (ResultSet resultSet = statement.getGeneratedKeys()) {
if (resultSet.next()) {
result = resultSet.getLong(1);
}
}
}
return result;
}
private void queryWithEqual() throws SQLException {
String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id=?";
try (
Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
preparedStatement.setInt(1, 10);
printQuery(preparedStatement);
}
}
private void queryWithIn() throws SQLException {
String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id IN (?, ?)";
try (
Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
preparedStatement.setInt(1, 10);
preparedStatement.setInt(2, 11);
printQuery(preparedStatement);
}
}
private void queryWithHint() throws SQLException {
String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id";
try (
HintManager hintManager = HintManager.getInstance();
Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
hintManager.addDatabaseShardingValue("t_order", "user_id", 11);
printQuery(preparedStatement);
}
}
private void printQuery(final PreparedStatement preparedStatement) throws SQLException {
try (ResultSet resultSet = preparedStatement.executeQuery()) {
while (resultSet.next()) {
System.out.print("order_item_id:" + resultSet.getLong(1) + ", ");
System.out.print("order_id:" + resultSet.getLong(2) + ", ");
System.out.print("user_id:" + resultSet.getInt(3));
System.out.println();
}
}
}
private void dropTable() throws SQLException {
execute("DROP TABLE t_order_item");
execute("DROP TABLE t_order");
}
private void execute(final String sql) throws SQLException {
try (
Connection connection = dataSource.getConnection();
Statement statement = connection.createStatement()) {
statement.execute(sql);
}
}
}注意
1、createTable
該方法會根據配置的資料節點表示式建立分表。這裡分別建立t_order和t_order_item兩張邏輯表。
2、insertData
該方法同樣根據配置的資料分片表達書建立資料
3、queryWithEqual等方法
這些方法是不同的查詢場景,有精確查詢也有範圍查詢
4、queryWithHint
該方法比較特殊。
通過解析SQL語句提取分片鍵列與值並進行分片是Sharding-Sphere對SQL零侵入的實現方式。若SQL語句中沒有分片條件,則無法進行分片,需要全路由。
好比queryWithHint這個方法中的"String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id";"就沒有包含路由資訊,即where
條件語句中沒有order_id和user_id的資訊。
所以該方法中通過強制指定路由資訊進行路由。"hintManager.addDatabaseShardingValue("t_order", "user_id", 11);"這裡執行user_id為11的條件,通過這個條件也可以推測出是隻會路由到ds1庫中(11%2=1)。
5、dropTable
該方法用於清理現場,將所有表和表資料清除。
5、執行結果
執行完程式碼,控制檯列印
1.Query with EQUAL--------------
2.Query with IN--------------
3.Query with Hint--------------
4.Drop tables--------------
5.All done-----------
執行程式碼前,只有兩個資料庫ds0,ds1,執行程式碼後得到結果如下圖所示
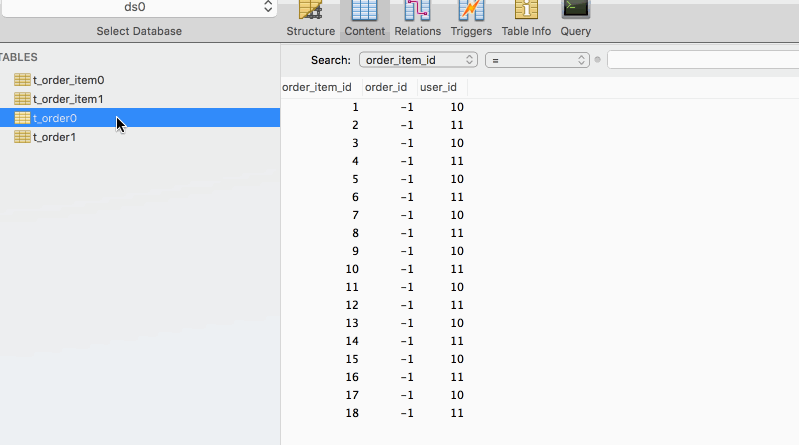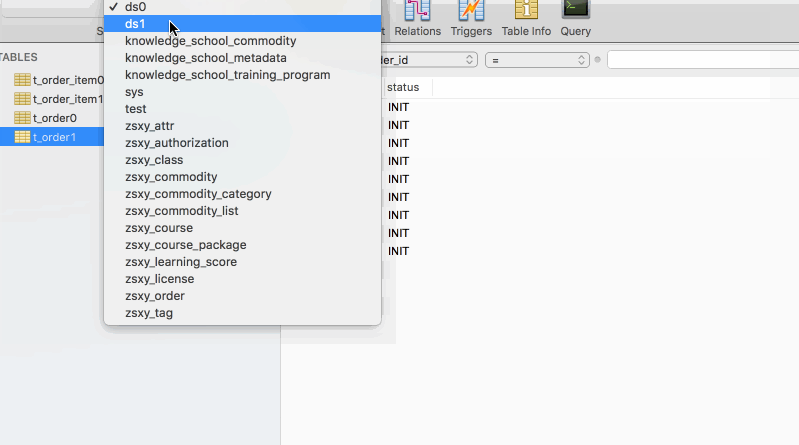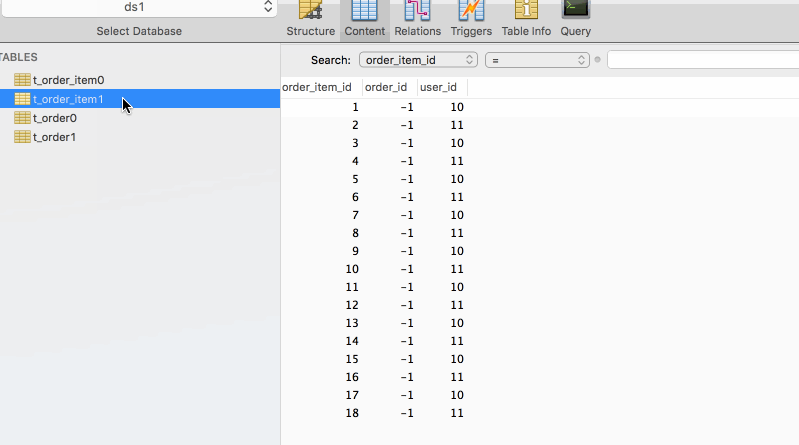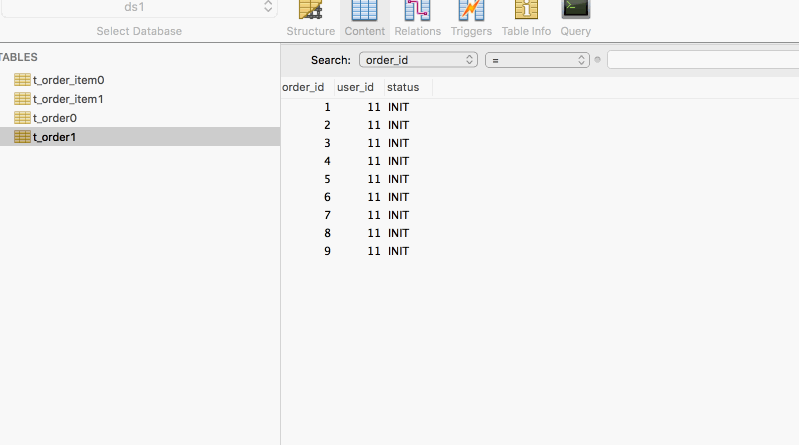
小結
sharding-sphere是一天非常強大的分散式資料庫中介軟體解決方法。
有簡單易懂的行表示式用於配置資料節點和資料分片演算法。
有自己的諸多大殺器,比如強制路由等。
官方文件齊全,例項程式碼專案case較全,能夠在較短時間完成分庫分表。
本篇通過一個簡單的demo程式碼,大致瞭解了sharding-sphere(主要是sharding-jdbc)的基本玩法,後續有時間可以學習下底層的設計和實現原理。
如果您覺得閱讀本文對您有幫助,請點一下“推薦”按鈕,您的“推薦”將是我最大的寫作動力!如果您想持續關注我的文章,請掃描二維碼,關注JackieZheng的微信公眾號,我會將我的文章推送給您,並和您一起分享我日常閱讀過的優質文章。

相關推薦
分庫分表利器——sharding-sphere
背景 得不到的東西讓你徹夜難眠,沒有嘗試過的技術讓我躍躍欲試。 本著殺雞焉用牛刀的準則,我們倡導夠用就行,不跟風,不盲從。 所以,結果就是我們一直沒有真正使用分庫分表。曾經好幾次,感覺沒有分庫分表(起碼要分表),專案就做不下去了,但是由於跨部門、工具約束、專案被砍等各種原因最終都偃旗息鼓,乖乖的搞單表加索引去
【分庫分表】sharding-jdbc + spring boot對大表進行分庫分表
一、前言 最近小編跳槽了,剛好入職了一家移動網際網路公司。非常的幸運。來新公司後的第一個專案就是對通知服務進行優化改進,其中,一個業務就是當用戶登入的時候,就會登入訪問通知表,根據使用者id載入通知資訊。由於通知量已經上億了,在查詢的時候是非常慢的。
【分庫分表】sharding-jdbc—分片策略
==> Preparing: select id,order_id,unique_no,quantity,is_active,inserttime,updatetime from t_order_items where is_active = 1 AND order_id in ( ? , ? , ?
分庫分表框架Sharding-jdbc以及分散式worker:Elastic-job的使用與踩坑
一、為什麼要使用Sharding 在當今網際網路企業中,資料成倍增長是一個很頭疼的問題。由於資料庫中一張表存入的資料越多,對資料庫操作的資料就越慢。但是我們如果根據指定的分庫分表策略,將資料分散的到不同的表上,我們查詢時,根據全域性主鍵,只掃某個庫的某一張表,這樣即
資料庫分庫分表(sharding)(一)——基本思想、拆分策略和拆分所帶來的問題
資料庫分庫分表(sharding)(一) 目的:我覺得學習一項技術,必須知道它的原理,尤其是這項技術的目的所在,為啥要用它!資料庫分庫分表的用處:資料庫中的資料量不一定是可控的,在未進行分庫分表的情況下,隨著時間和業務的發展,資料庫中的表會越來越多,表中的資料量
資料量大了一定要分表,分庫分表元件Sharding-JDBC入門與專案實戰
最近專案中不少表的資料量越來越大,並且導致了一些資料庫的效能問題。因此想借助一些分庫分表的中介軟體,實現自動化分庫分表實現。調研下來,發現`Sharding-JDBC`目前成熟度最高並且應用最廣的`Java分庫分表的客戶端元件`。本文主要介紹一些Sharding-JDBC核心概念以及生產環境下的實戰指南,旨在
分庫分表神器 Sharding-JDBC,幾千萬的資料你不搞一下?
今天我們介紹一下 `Sharding-JDBC`框架和快速的搭建一個分庫分表案例,為講解後續功能點準備好環境。 ### **一、Sharding-JDBC 簡介** `Sharding-JDBC` 最早是噹噹網內部使用的一款分庫分表框架,到2017年的時候才開始對外開源,這幾年在大量社
Sharding-Sphere 3.X 與spring與mybatis集成(分庫分表)demo
sharding jdbc 分庫分表最近在弄這個sharding-sphere,公司內部分庫分表是在此業務代碼上進行邏輯分庫分表,但是這種總是不好,也調研了幾款分庫分表中間件、mycat、網易cetus、阿裏DRDS、這幾種就是背景強大,大公司經過大量的實戰,成熟度很高,而框架sharding-sphere比
Sharding-Sphere 3.X 與spring與mybatis整合(分庫分表)demo
最近在弄這個sharding-sphere,公司內部分庫分表是在此業務程式碼上進行邏輯分庫分表,但是這種總是不好,也調研了幾款分庫分表中介軟體、mycat、網易cetus、阿里DRDS、這幾種就是背景強大,大公司經過大量的實戰,成熟度很高,而框架sharding-sphere
數據庫分庫分表中間件 Sharding-JDBC 源碼分析 —— SQL 解析(六)之刪除SQL
java 後端 架構 數據庫 中間件關註微信公眾號:【芋道源碼】有福利:RocketMQ / MyCAT / Sharding-JDBC 所有源碼分析文章列表RocketMQ / MyCAT / Sharding-JDBC 中文註釋源碼 GitHub 地址您對於源碼的疑問每條留言都將得到認真回復。甚至不知道如
數據庫分庫分表中間件 Sharding-JDBC 源碼分析 —— 分布式主鍵
java 後端 架構 數據庫 中間件關註**微信公眾號:【芋道源碼】**有福利:RocketMQ / MyCAT / Sharding-JDBC 所有源碼分析文章列表RocketMQ / MyCAT / Sharding-JDBC 中文註釋源碼 GitHub 地址您對於源碼的疑問每條留言都將得到認真回復。甚至
數據庫分庫分表(sharding)系列
使用 版權 支持 tar 策略 ofo sdn 數據源 鏈接 博客專欄http://blog.csdn.net/column/details/sharding.html 相關閱讀: 數據庫分庫分表(sharding)系列(五) 一種支持自由規劃無須數據遷移和修改路由代碼
資料庫分庫分表(sharding)系列(五) 一種支援自由規劃無須資料遷移和修改路由程式碼的Sharding擴容方案(轉)...
作為一種資料儲存層面上的水平伸縮解決方案,資料庫Sharding技術由來已久,很多海量資料系統在其發展演進的歷程中都曾經歷過分庫分表的Sharding改造階段。簡單地說,Sharding就是將原來單一資料庫按照一定的規則進行切分,把資料分散到多臺物理機(我們稱之為Shard)上儲存,從
資料庫分庫分表 sharding 系列 四 多資料來源的事務處理
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
資料庫分庫分表 sharding 系列 五 一種支援自由規劃無須資料遷移和修改路由程式碼的Sharding擴容方案
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
資料庫分庫分表(sharding)系列(三) 關於使用框架還是自主開發以及sharding實現層面的考量 資料庫分庫分表(sharding)系列(二) 全域性主鍵生成策略 資料庫分庫分表(sharding)系列(一) 拆分實施策略和示例演示
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
使用Sharding-Proxy進行分庫分表
Sharding-Proxy的使用 1、官網下載 sharding-jdbc的官網http://shardingsphere.io/document/current/cn/manual/sharding-proxy/usage/ 下載完進入conf檔案如下:
Spring Boot 結合 Sharding-Jdbc做分庫分表示例
對於一些大系統,資料庫資料量很大,業務量特別大的時候,而我們的資料庫及表的對於大資料量的時候,處理的效能就不容樂觀,這個時候我們就需要對我們的資料和表做分庫分表處理了。一般分庫分表都會採用資料庫中介軟體,像Mycat這種中介軟體,它幫我們做資料來源,路由對映控制。而今天介紹的Sharding
資料庫分庫分表 sharding 系列 三 關於使用框架還是自主開發以及sharding實現層面的考量
當團隊對系統業務和資料庫進行了細緻的梳理,確定了切分方案後,接下來的問題就是如何去實現切分方案了,目前在sharding方面有不少的開源框架和產品可供參考,同時很多團隊也會選擇自主開發實現,而不管是選擇框架還是自主開發,都會面臨一個在哪一層上實現sharding邏輯的問題,本文
分庫分表框架cobar,cobar-client,tddl,sharding-JDBC
前一段時間研究阿里的分庫框架cobar-client,cobar-client是基於ibatis的SqlMapClientTemplate進行了一層薄薄的封裝,分裝成CobarSqlMapClientTemplate,在使用者在CRUD的時候可以透明的進行操作,算是現在大多公司分庫的一個成熟解決方