
高可用Hadoop平臺-Flume NG實戰圖解篇
1.概述
今天補充一篇關於Flume的部落格,前面在講解高可用的Hadoop平臺的時候遺漏了這篇,本篇部落格為大家講述以下內容:
- Flume NG簡述
- 單點Flume NG搭建、執行
- 高可用Flume NG搭建
- Failover測試
- 截圖預覽
下面開始今天的部落格介紹。
2.Flume NG簡述
Flume NG是一個分散式,高可用,可靠的系統,它能將不同的海量資料收集,移動並存儲到一個數據儲存系統中。輕量,配置簡單,適用於各種日誌收集,並支援Failover和負載均衡。並且它擁有非常豐富的元件。Flume NG採用的是三層架構:Agent層,Collector層和Store層,每一層均可水平拓展。其中Agent包含Source,Channel和Sink,三者組建了一個Agent。三者的職責如下所示:
- Source:用來消費(收集)資料來源到Channel元件中
- Channel:中轉臨時儲存,儲存所有Source元件資訊
- Sink:從Channel中讀取,讀取成功後會刪除Channel中的資訊
下圖是Flume NG的架構圖,如下所示:

圖中描述了,從外部系統(Web Server)中收集產生的日誌,然後通過Flume的Agent的Source元件將資料傳送到臨時儲存Channel元件,最後傳遞給Sink元件,Sink元件直接把資料儲存到HDFS檔案系統中。
3.單點Flume NG搭建、執行
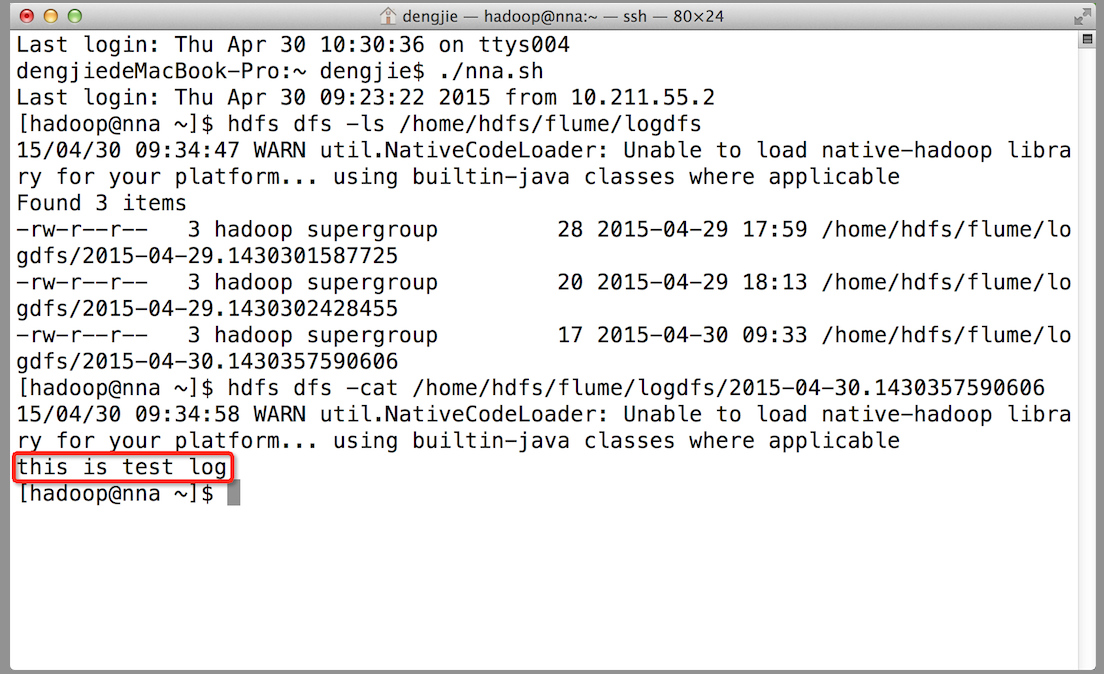
我們在熟悉了Flume NG的架構後,我們先搭建一個單點Flume收集資訊到HDFS叢集中,由於資源有限,本次直接在之前的高可用Hadoop叢集上搭建Flume。
場景如下:在NNA節點上搭建一個Flume NG,將本地日誌收集到HDFS叢集。
3.1基礎軟體
在搭建Flume NG之前,我們需要準備必要的軟體,具體下載地址如下所示:
JDK由於之前在安裝Hadoop叢集時已經配置過,這裡就不贅述了,若需要配置的同學,可參考《配置高可用的Hadoop平臺》。
3.2安裝與配置
- 安裝
首先,我們解壓flume安裝包,命令如下所示:
[[email protected] ~]$ tar -zxvf apache-flume-1.5.2-bin.tar.gz
- 配置
環境變數配置內容如下所示:
export FLUME_HOME=/home/hadoop/flume-1.5.2 export PATH=$PATH:$FLUME_HOME/bin
flume-conf.properties
#agent1 name agent1.sources=source1 agent1.sinks=sink1 agent1.channels=channel1 #Spooling Directory #set source1 agent1.sources.source1.type=spooldir agent1.sources.source1.spoolDir=/home/hadoop/dir/logdfs agent1.sources.source1.channels=channel1 agent1.sources.source1.fileHeader = false agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = timestamp #set sink1 agent1.sinks.sink1.type=hdfs agent1.sinks.sink1.hdfs.path=/home/hdfs/flume/logdfs agent1.sinks.sink1.hdfs.fileType=DataStream agent1.sinks.sink1.hdfs.writeFormat=TEXT agent1.sinks.sink1.hdfs.rollInterval=1 agent1.sinks.sink1.channel=channel1 agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d #set channel1 agent1.channels.channel1.type=file agent1.channels.channel1.checkpointDir=/home/hadoop/dir/logdfstmp/point agent1.channels.channel1.dataDirs=/home/hadoop/dir/logdfstmp
flume-env.sh
JAVA_HOME=/usr/java/jdk1.7
注:配置中的目錄若不存在,需提前建立。
3.3啟動
啟動命令如下所示:
flume-ng agent -n agent1 -c conf -f flume-conf.properties -Dflume.root.logger=DEBUG,console
注:命令中的agent1表示配置檔案中的Agent的Name,如配置檔案中的agent1。flume-conf.properties表示配置檔案所在配置,需填寫準確的配置檔案路徑。
3.4效果預覽
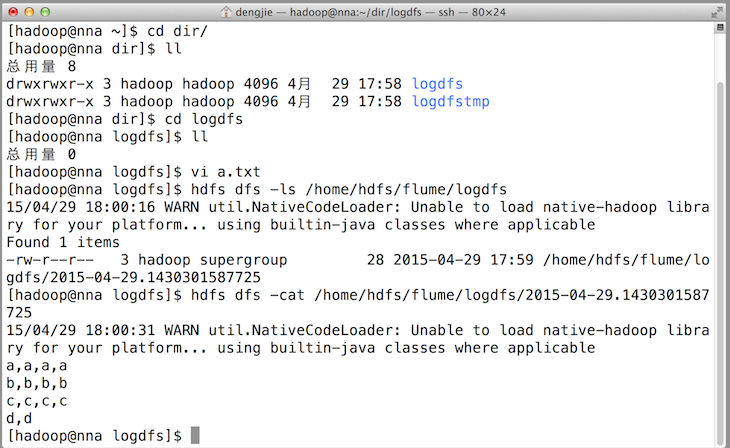
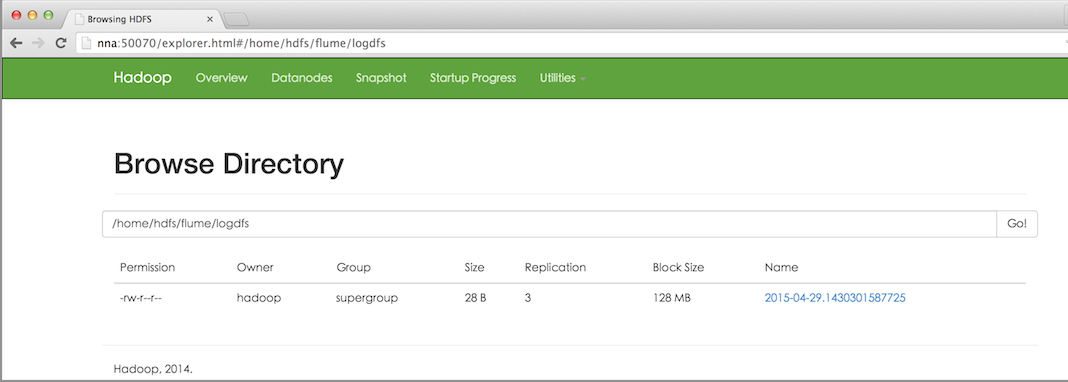
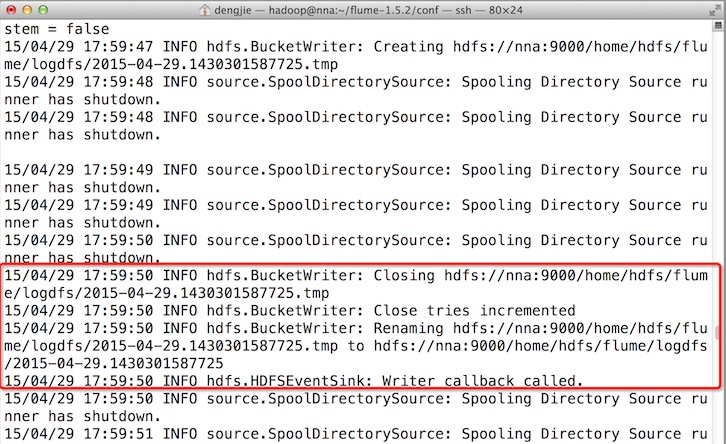
之後,成功上傳後本地目的會被標記完成。如下圖所示:

4.高可用Flume NG搭建
在完成單點的Flume NG搭建後,下面我們搭建一個高可用的Flume NG叢集,架構圖如下所示:
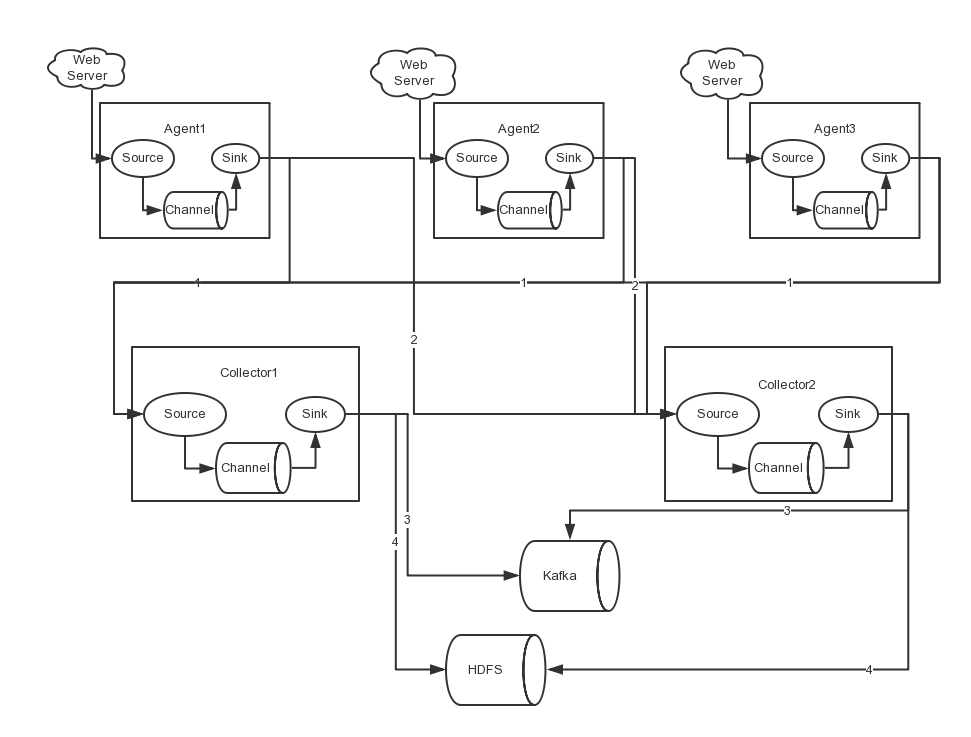
圖中,我們可以看出,Flume的儲存可以支援多種,這裡只列舉了HDFS和Kafka(如:儲存最新的一週日誌,並給Storm系統提供實時日誌流)。
4.1節點分配
Flume的Agent和Collector分佈如下表所示:
| 名稱 | HOST | 角色 |
| Agent1 | 10.211.55.14 | Web Server |
| Agent2 | 10.211.55.15 | Web Server |
| Agent3 | 10.211.55.16 | Web Server |
| Collector1 | 10.211.55.18 | AgentMstr1 |
| Collector2 | 10.211.55.19 | AgentMstr2 |
圖中所示,Agent1,Agent2,Agent3資料分別流入到Collector1和Collector2,Flume NG本身提供了Failover機制,可以自動切換和恢復。在上圖中,有3個產生日誌伺服器分佈在不同的機房,要把所有的日誌都收集到一個叢集中儲存。下面我們開發配置Flume NG叢集
4.2配置
在下面單點Flume中,基本配置都完成了,我們只需要新新增兩個配置檔案,它們是flume-client.properties和flume-server.properties,其配置內容如下所示:
- flume-client.properties
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2 #set gruop agent1.sinkgroups = g1 #set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /home/hadoop/dir/logdfs/test.log agent1.sources.r1.interceptors = i1 i2 agent1.sources.r1.interceptors.i1.type = static agent1.sources.r1.interceptors.i1.key = Type agent1.sources.r1.interceptors.i1.value = LOGIN agent1.sources.r1.interceptors.i2.type = timestamp # set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = nna agent1.sinks.k1.port = 52020 # set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = nns agent1.sinks.k2.port = 52020 #set sink group agent1.sinkgroups.g1.sinks = k1 k2 #set failover agent1.sinkgroups.g1.processor.type = failover agent1.sinkgroups.g1.processor.priority.k1 = 10 agent1.sinkgroups.g1.processor.priority.k2 = 1 agent1.sinkgroups.g1.processor.maxpenalty = 10000
注:指定Collector的IP和Port。
- flume-server.properties
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1 #set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = nna a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = NNA a1.sources.r1.channels = c1 #set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/home/hdfs/flume/logdfs a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=1 a1.sinks.k1.channel=c1 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
注:在另一臺Collector節點上修改IP,如在NNS節點將繫結的物件有nna修改為nns。
4.3啟動
在Agent節點上啟動命令如下所示:
flume-ng agent -n agent1 -c conf -f flume-client.properties -Dflume.root.logger=DEBUG,console
注:命令中的agent1表示配置檔案中的Agent的Name,如配置檔案中的agent1。flume-client.properties表示配置檔案所在配置,需填寫準確的配置檔案路徑。
在Collector節點上啟動命令如下所示:
flume-ng agent -n a1 -c conf -f flume-server.properties -Dflume.root.logger=DEBUG,console
注:命令中的a1表示配置檔案中的Agent的Name,如配置檔案中的a1。flume-server.properties表示配置檔案所在配置,需填寫準確的配置檔案路徑。
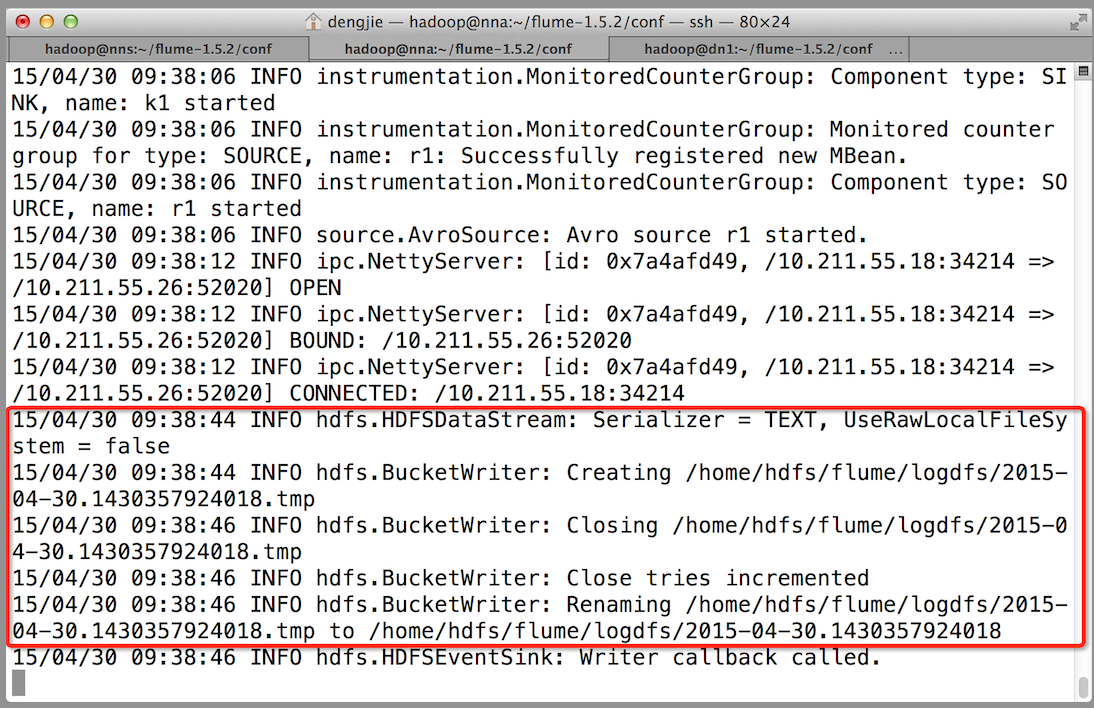
5.Failover測試
下面我們來測試下Flume NG叢集的高可用(故障轉移)。場景如下:我們在Agent1節點上傳檔案,由於我們配置Collector1的權重比Collector2大,所以Collector1優先採集並上傳到儲存系統。然後我們kill掉Collector1,此時有Collector2負責日誌的採集上傳工作,之後,我們手動恢復Collector1節點的Flume服務,再次在Agent1上次檔案,發現Collector1恢復優先級別的採集工作。具體截圖如下所示:
- Collector1優先上傳

- HDFS叢集中上傳的log內容預覽
- Collector1宕機,Collector2獲取優先上傳許可權

- 重啟Collector1服務,Collector1重新獲得優先上傳的許可權
6.截圖預覽
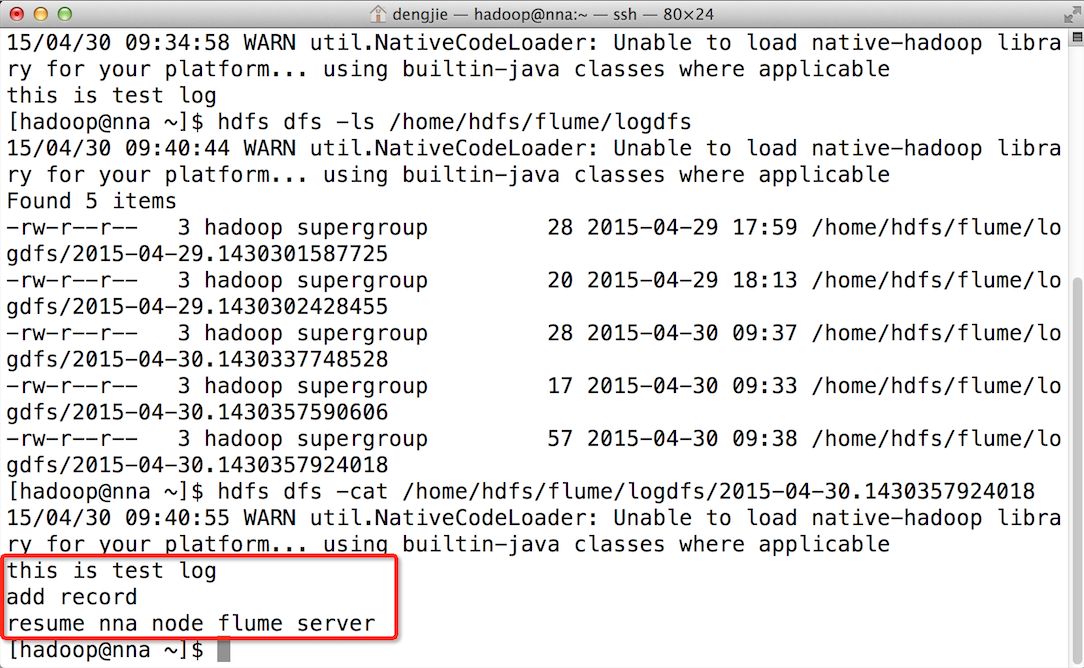
下面為大家附上HDFS檔案系統中的截圖預覽,如下圖所示:
- HDFS檔案系統中的檔案預覽

- 上傳的檔案內容預覽
7.總結
在配置高可用的Flume NG時,需要注意一些事項。在Agent中需要繫結對應的Collector1和Collector2的IP和Port,另外,在配置Collector節點時,需要修改當前Flume節點的配置檔案,Bind的IP(或HostName)為當前節點的IP(或HostName),最後,在啟動的時候,指定配置檔案中的Agent的Name和配置檔案的路徑,否則會出錯。
8.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!
相關推薦
高可用Hadoop平臺-Flume NG實戰圖解篇
1.概述 今天補充一篇關於Flume的部落格,前面在講解高可用的Hadoop平臺的時候遺漏了這篇,本篇部落格為大家講述以下內容: Flume NG簡述 單點Flume NG搭建、執行 高可用Flume NG搭建 Failover測試 截圖預覽 下面開始今天的部落格介紹。 2.F
高可用Hadoop平臺-啟航
1.概述 在上篇部落格中,我們搭建了《配置高可用Hadoop平臺》,接下來我們就可以駕著Hadoop這艘巨輪在大資料的海洋中遨遊了。工欲善其事,必先利其器。是的,沒錯;我們開發需要有開發工具(IDE);本篇文章,我打算講解如何搭建和使用開發環境,以及編寫和講解WordCount這個例子,給即將在Hado
keepalived高可用集群技術介紹及實戰演練
keepalived一、Keepalived是什麽 Keepalived的作用是檢測服務器的狀態,如果有一臺web服務器宕機,或工作出現故障,Keepalived將檢測到,並將有故障的服務器從系統中剔除,同時使用其他服務器代替該服務器的工作,當服務器工作正常後Keepalived自動將服務器加入到服務器群中,
keepalived 高可用問題及企業解決方案實戰
gin 實現 gre keepalive then shel 接管 問題 方案 keepalived 實現服務器級別的接管,比如nginx 宕機了 不會接管,可以寫shell 腳本實現,當nginx 掛了,把keepalived 停掉while truedo if [ ‘p
高可用集群之keepalived+lvs實戰-技術流ken
ipa 日誌記錄 apach 之前 使用 多個 eas pos dmi 1.keepalived簡介 lvs在我之前的博客《高負載集群實戰之lvs負載均衡-技術流ken》中已經進行了詳細的介紹和應用,在這裏就不再贅述。這篇博文將把lvs與keepalived相結合使用,在實
Proxmox VE搭配Ceph儲存組建高可用虛擬化平臺
隨著項專案的增多,對測試環境的需求越來越大,今天研發要幾臺測試環境,明天測試也要幾臺測試環境,連產品都要測試環境了,咱們運維也得有自己的測試環境,之前搭建的exsi已經滿足不了需求了。 手頭資源有限,所以這裡先用三臺機器組
[Hadoop] CentOS7 安裝flume-ng-1.6.0-cdh5.7.0
1. Flume 安裝部署 根據官方文件描述,市面上的Flume主流版本有兩個:0.9.x and 1.x。這兩個版本差異非常非常大,舊版本已經被淘汰了,要用的話就使用新版本。當然本文中既定版本為cd
一鍵配置高可用Hadoop叢集(hdfs HA+zookeeper HA)
準備環境 3臺節點,主節點 建議 2G 記憶體,兩個從節點 1.5G記憶體, 橋接網路 關閉防火牆 配置ssh,讓節點之間能夠相互 ping 通 準備 軟體放到 autoInstall 目錄下,已存放 hadoop-2.9.0.tar.g
基於zookeeper的高可用Hadoop HA叢集安裝
1.Hadoop叢集方式介紹 1.1 hadoop1.x和hadoop2.x都支援的namenode+secondarynamenode方式 優點:搭建環境簡單,適合開發者模式下除錯程式 缺點:namenode作為很重
均衡負載方式搭建高可用的flume-ng環境寫入資訊到hadoop和kafka
應用場景為多臺agent推送本地日誌資訊到hadoop,由於agent和hadoop叢集處在不同的網段,資料量較大時可能出現網路壓力較大的情況,所以我們在hadoop一側的網段中部署了兩臺flume collector機器,將agent的資料傳送到collector上進行分
Flume 學習筆記之 Flume NG高可用集群搭建
哈哈 process bind under hdf ora chan lsp max Flume NG高可用集群搭建: 架構總圖: 架構分配: 角色 Host 端口 agent1 hadoop3 52020 collect
高可用flume-ng搭建
flume一、概述1.通過搭建高可用flume來實現對數據的收集並存儲到hdfs上,架構圖如下:二、配置Agent1.cat flume-client.properties#name the components on this agent 聲明source、channel、sink的名稱 a1.sou
Flume NG高可用叢集搭建詳解(基於flume-1.7.0)
1、Flume NG簡述 Flume NG是一個分散式,高可用,可靠的系統,它能將不同的海量資料收集,移動並存儲到一個數據儲存系統中。輕量,配置簡單,適用於各種日誌收集,並支援 Failover和負載均衡。並且它擁有非常豐富的元件。Flume NG採用的是三層架構:Agent層,Collecto
Flume NG高可用叢集搭建
軟體版本: CentOS 6.7 hadoop-2.7.4 apache-flume-1.6.0 一、Flume NG簡述 Flume 是 Cloudera 提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統。 Flume將採集到的檔案,sock
配置高可用的Hadoop平臺
1.概述 在Hadoop2.x之後的版本,提出瞭解決單點問題的方案--HA(High Available 高可用)。這篇部落格闡述如何搭建高可用的HDFS和YARN,執行步驟如下: 建立hadoop使用者 安裝JDK 配置hosts 安裝SSH 關閉防火牆 修改時區 ZK(安裝,啟動,
flume ng高可用部署
一、flume簡介 flume是一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸系統,Flume支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單的處理,並寫到各類資料接受方(可定製)的能力。Flume1.x版
15套java架構師、集群、高可用、高可擴展、高性能、高並發、性能優化、Spring boot、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式項目實戰視頻教程
mycat 擴展 並發解決方案 入門到 -1 高端 資料 src nio * { font-family: "Microsoft YaHei" !important } h1 { background-color: #006; color: #FF0 } 15套java
java架構師課程、性能調優、高並發、tomcat負載均衡、大型電商項目實戰、高可用、高可擴展、數據庫架構設計、Solr集群與應用、分布式實戰、主從復制、高可用集群、大數據
慢查詢 主從復制 難題 jms 整合 大數 數據庫設計 企業級 nginx網站 15套Java架構師詳情 * { font-family: "Microsoft YaHei" !important } h1 { background-color: #006; color:
京東618:商城交易平臺的高可用架構之路
資源 系統 定位問題 修復 tle 峰值 網絡 寫入 差異 據騰訊科技報道,6月18日零點,京東全民年中購物節拉開了高潮的序幕。第一個小時的銷售額超過去年同期的250%。從淩晨開始的海量訂單讓6月1日就拉開序幕的京東年中購物節奏出最強音,大量用戶瞬間湧入,峰值訂單被不斷刷新
15套java互聯網架構師、高並發、集群、負載均衡、高可用、數據庫設計、緩存、性能優化、大型分布式 項目實戰視頻教程
二階 並發 支持 線程並發 important http 系統架構 四十 mongodb入門 * { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架構師、集群、高可用、高可擴