
Lucene基礎(四)-- 結合資料庫使用
需求
很多時候我們在用資料庫的需要使用模糊查詢,我們一般會使用like語句來做,然而這樣的做的效率不是很多(很抱歉我們親自去測,很多都這麼說的),那麼使用Lucene來檢索的話,效率會高很多。
lucene結合資料庫步驟
- 寫一段傳統的JDBC程式,將每條的使用者資訊從資料庫讀取出來
- 針對每條使用者記錄,建立一個lucene document
Document doc = new Document();
並根據你的需要,將使用者資訊的各個欄位對應luncene document中的field 進行新增,如:
doc.add(new Field(“NAME”,”USERNAME”,Field.Store.YES,Field.Index.UN_TOKENIZED));
然後將該條doc加入到索引中, 如: luceneWriter.addDocument(doc);
這樣就建立了lucene的索引庫 - 編寫對索引庫的搜尋程式(看lucene文件),通過對lucene的索引庫的查詢,你可以快速找到對應記錄的ID
- 通過ID到資料庫中查詢相關記錄
注意
在索引的過程中,可以使用增量的方式建立索引,這樣對已經索引的記錄不在建立索引。實現思路:儲存上次(lasttime)的新增時候的id,在建立索引的時候,值查詢這個id之後的記錄進行索引,更新這個記錄下來的id,在資料庫資料修改時候,針對這個資料製作索引的修改
操作例項
package lucene_demo05;
import java.io.IOException;
import java.sql.Connection;
import 索引之後就可以拿到需要id,這個時候按id查詢資料庫的記錄,就快多了。
思考
這是對單表的資料進行索引,當我們的業務複雜的是,需要的資料通常是多個表聯合查詢的結果,我們的索引是如何建立?
- 使用檢視,對多表建立檢視,在檢視上面建立索引?
- 還是單表索引,只是把聯合查詢化解,在lucene的索引中使用多次查詢,找到目標,在資料庫查詢?
和資料使用的時候 ,索引到底是和資料庫資料相關聯的,還是和結果集相關聯的?
寫測試程式發現,應該是索引在資料結果集上面的。
測試如下:
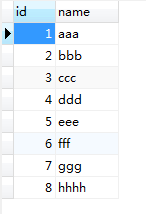
t_user 表

t_user_teacher 表
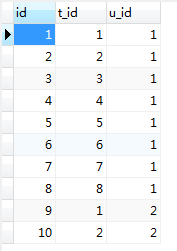
t_teacher 表
package lucene_demo05;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
*
* Lucene與資料庫結合使用
*
* @author YipFun
*/
public class LuceneDemo06 {
private static final String driverClassName="com.mysql.jdbc.Driver";
private static final String url="jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf-8";
private static final String username="****";
private static final String password="****";
private static final Version version = Version.LUCENE_4_9;
private Directory directory = null;
private DirectoryReader ireader = null;
private IndexWriter iwriter = null;
private IKAnalyzer analyzer;
private Connection conn;
public LuceneDemo06() {
directory = new RAMDirectory();
}
public IndexSearcher getSearcher(){
try {
if(ireader==null) {
ireader = DirectoryReader.open(directory);
} else {
DirectoryReader tr = DirectoryReader.openIfChanged(ireader) ;
if(tr!=null) {
ireader.close();
ireader = tr;
}
}
return new IndexSearcher(ireader);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public Connection getConnection(){
if(this.conn == null){
try {
Class.forName(driverClassName);
conn = DriverManager.getConnection(url, username, password);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
return conn;
}
private IKAnalyzer getAnalyzer(){
if(analyzer == null){
return new IKAnalyzer();
}else{
return analyzer;
}
}
public void createIndex(){
Connection conn = getConnection();
ResultSet rs = null;
PreparedStatement pstmt = null;
if(conn == null){
System.out.println("get the connection error...");
return ;
}
String sql = "select "+
"u.id as uid,"+
"u.name as uname,"+
"u.psd as upsd,"+
"u.email as uemail,"+
"u.tel as utel,"+
"t.id as tid,"+
"t.name as tname "+
"from t_user u , t_user_teacher ut ,t_teacher t "+
"where u.id=ut.u_id and ut.t_id= t.id ";
try {
pstmt = conn.prepareStatement(sql);
rs = pstmt.executeQuery();
IndexWriterConfig iwConfig = new IndexWriterConfig(version, getAnalyzer());
iwConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
iwriter = new IndexWriter(directory,iwConfig);
while(rs.next()){
int id = rs.getInt("uid");
String name = rs.getString("uname");
String psd = rs.getString("upsd");
int tid = rs.getInt("tid");
String tname = rs.getString("tname");
Document doc = new Document();
doc.add(new TextField("uid", id+"",Field.Store.YES));
doc.add(new TextField("uname", name+"",Field.Store.YES));
doc.add(new TextField("upsd", psd+"",Field.Store.YES));
doc.add(new TextField("tid", tid+"",Field.Store.YES));
doc.add(new TextField("tname", tname+"",Field.Store.YES));
iwriter.addDocument(doc);
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
if(iwriter != null)
iwriter.close();
rs.close();
pstmt.close();
if(!conn.isClosed()){
conn.close();
}
} catch (IOException e) {
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public void searchByTerm(String field,String keyword,int num) throws InvalidTokenOffsetsException{
IndexSearcher isearcher = getSearcher();
Analyzer analyzer = getAnalyzer();
//使用QueryParser查詢分析器構造Query物件
QueryParser qp = new QueryParser(version,
field,analyzer);
//這句所起效果?
qp.setDefaultOperator(QueryParser.OR_OPERATOR);
try {
Query query = qp.parse(keyword);
ScoreDoc[] hits;
//注意searcher的幾個方法
hits = isearcher.search(query, null, num).scoreDocs;
System.out.println("the ids is =");
for (int i = 0; i < hits.length; i++) {
Document doc = isearcher.doc(hits[i].doc);
System.out.print(doc.get("uid")+" ");
}
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InvalidTokenOffsetsException {
LuceneDemo06 ld = new LuceneDemo06();
ld.createIndex();
ld.searchByTerm("tname", "aaa", 100);
}
}搜尋教師為aaa的學生的Id
結果:
載入擴充套件詞典:ext.dic
載入擴充套件停止詞典:stopword.dic
the ids is =
1 2 總結 : 所以使用索引多表的時候直接索引結果集或者檢視是可以實現
相關推薦
Lucene基礎(四)-- 結合資料庫使用
需求 很多時候我們在用資料庫的需要使用模糊查詢,我們一般會使用like語句來做,然而這樣的做的效率不是很多(很抱歉我們親自去測,很多都這麼說的),那麼使用Lucene來檢索的話,效率會高很多。 lucene結合資料庫步驟 寫一段傳統的JDBC程式,將
Java基礎(四)java連線資料庫
Java 連線 MySQL和Java 連線 Oracle資料庫的一些基本總結: 1.Java 連線 MySQL資料庫 //整體封裝寫為一個方法(後續補上) public class MysqlDemo { //引入Jdbc驅動及資料庫地址URL final String Jd
Flask零基礎到專案實戰(四)SQLAlchemy資料庫(一)
文章來源—知了課堂的課件 一、SQLAlchemy簡介 flask_sqlalchemy是一套ORM框架。 ORM(Object Relationship Mapping):模型關係對映 ORM的好處:可以讓我們操作資料庫跟操作類的物件一樣。一個表可
Linux基礎(四)
har jid work 區號 linu watch worker eof -1 一、系統監控 1.用top命令實時監測CPU、內存、硬盤狀態 效果類似Windows的任務管理器,默認每5秒刷新一下屏幕上的顯示結果。 [[email protected]/*
mysql基礎(四)用戶權限管理和root密碼恢復
mysqlmysql用戶由用戶和主機名組成,[email protected]/* */,mysql的用戶和權限信息存儲在mysql庫中 mysql數據庫表: user #用戶賬號、全局權限 db #庫級別權限 host #主機 tables_priv
mysql基礎(四)之索引
name 根據 正是 而不是 方案 加速 .com mtab 技術 索引簡介: 1、普通索引 普通索引(由關鍵字KEY或INDEX定義的索引)的唯一任務是加快對數據的訪問速度。因此,應該只為那些最經常出現在查詢條件 (WHEREcolumn=)或排序條件
JS基礎(四)運算符
訪問 數據 js基礎 必須 減法 delete 異或 函數 按位與 一.比較運算符 1.== : 判斷兩邊值是否相等 2.>= : 判斷左邊的值是否大於或等於右邊的值 3.<= : 判斷左邊邊的值是否小於或等於右邊的值 4.> : 判斷
SQL基礎(四):SQL命令
版本 數據庫應用 ges odi 改變 sql per 測試 數據類型 1、CREATE INDEX 語句 CREATE INDEX 語句用於在表中創建索引。在不讀取整個表的情況下,索引使數據庫應用程序可以更快地查找數據。 索引:在表中創建索引,以便更加快速高效地查
java並發基礎(四)--- 取消與關閉
rime ole out sys 類型 interrupt 來看 方法 發出 《java並發編程實戰》的第7章是任務的取消與關閉。我覺得這一章和第6章任務執行同樣重要,一個在行為良好的軟件和勉強運行的軟件之間的最主要的區別就是,行為良好的軟件能很完善的處理失敗、關閉和取
3D數學基礎(四)四元數和歐拉角
transform 推薦 中間 應該 它的 轉變 編輯器 最簡 組件 一、四元數 四元數本質上是個高階復數,可視為復數的擴展,表達式為y=a+bi+cj+dk。在說矩陣旋轉的時候提到了它,當然四元數在Unity裏面主要作用也在於此。在Unity編輯器中的Transfor
計算機網絡基礎(四)——數據鏈路層和網絡層協議及設備
數據鏈路層 路由器 一、數據鏈路層 位於網絡層與物理層之間1、功能 -- 數據鏈路的建立、維護與拆除 --幀包裝、幀傳輸、幀同步 --幀的差錯恢復 --流量控制 2.以太網 -- 以太網工作在數據鏈路層。我們平常使用的局域網就是以太網。 --以太網采用CSMA/C
Kotlin基礎(四)Lambda編程
構造 引用 元素 允許 其他 create text 顯示 tag Lambda編程 一、Lambda表達式和成員引用 一)Lambda表達式語法 1 //註意與Java8中的區別 2 val sum={ x:Int,y:Int -> x+y } 3
Hadoop 框架基礎(四)
釋放 top gem orien 系統啟動 -s blog 希望 記錄 ** Hadoop 框架基礎(四) 上一節雖然大概了解了一下 mapreduce,徒手抓了海膽,不對,徒手寫了 mapreduce 代碼,也運行了出來。但是沒有做更深入的理解和探討。 那麽…… 本節
路由交換基礎(四)——ACL訪問控制列表
per not 由器 地址 同時 擴展 數據包 而不是 需要 一、ACL1.作用訪問控制列表(Access Control List),是路由器和交換機接口的指令列表,用來控制端口進出的數據包。ACL可以過濾網絡中的流量,是控制訪問的一種網絡技術手段。配置ACL後,可以限制
Java基礎(四)
抽象類 使用 發生 註意 方法 類實例化 類方法 內容 大寫字母 一、方法 1、方法的定義 方法也叫函數,就是一個能獨立完成某個功能的一段代碼。方法可以看作一個整體。 語法: 修飾符 返回類型 方法名字(數據類型 變量名,數據類型 變量名,……[形式參數(0個到n
MySQL數據庫基礎(四)——MySQL數據庫創建實例
MySQL 數據庫 基礎 MySQL數據庫基礎(四)——MySQL數據庫創建實例 一、創建數據庫 1、創建數據庫 創建數據庫,指定數據庫的默認字符集為utf8。create database schoolDB default character set utf8;連接數據庫,客戶端必須選擇UTF8
JAVA基礎(四)面試題
Java基礎 Java程序員面試 面試題: 構造代碼塊,構造方法,靜態代碼的優先級? 靜態代碼塊>構造代碼塊>構造方法 面試題: overload和override的區別?overload:方法重載方法名一樣,參數不同,和返回值沒有關系參數不同:1)參數個數不同2)參數類型不同over
shell腳本基礎(四)
shell一、shell中的函數 函數就是把一段代碼整理到了一個小單元中,並給這個小單元起一個名字,當用到這段代碼時直接調用這個小單元的名字即可。 1、函數格式 function f_name() { command } 函數必須要放在腳本最前面。 2、shell函數實例 實例1: [root
密碼學基礎(四)算法的安全性
區塊鏈兄弟區塊鏈技術社區區塊鏈兄弟社區,區塊鏈技術專業問答先行者,中國區塊鏈技術愛好者聚集地作者:於中陽來源:區塊鏈兄弟原文鏈接:http://www.blockchainbrother.com/article/83著權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請註明出處。算法的安全性根據被破譯的難易
Linux基礎(四)——訊號量與PV操作
在計算機作業系統中,PV操作是程序管理中的難點。1、基本含義 什麼是訊號量?訊號量(semaphore)的資料結構為一個值和一個指標,指標指向等待該訊號量的下一個程序。訊號量的值與相應資源的使用情況有關。當它的值大於0時,表示當前可用資源的