
URL原理、URL編碼、URL特殊字元
通常如果一樣東西需要編碼,說明這樣東西並不適合傳輸。原因多種多樣,如Size過大,包含隱私資料,對於Url來說,之所以要進行編碼,是因為Url中有些字元會引起歧義。
例如,Url引數字串中使用key=value鍵值對這樣的形式來傳參,鍵值對之間以&符號分隔,如/s?q=abc&ie=utf-8。如果你的value字串中包含了=或者&,那麼勢必會造成接收Url的伺服器解析錯誤,因此必須將引起歧義的&和=符號進行轉義,也就是對其進行編碼。
又如,Url 的編碼格式採用的是ASCII碼,而不是Unicode,這也就是說你不能在Url中包含任何非ASCII字元,例如中文。否則如果客戶端瀏覽器和服務端瀏覽器支援的字符集不同的情況下,中文可能會造成問題。
Url編碼的原則:就是使用安全的字元(沒有特殊用途或者特殊意義的可列印字元)去表示那些不安全的字元。
預備知識:URI是統一資源標識的意思,通常我們所說的URL只是URI的一種。
典型URL的格式如下所示。下面提到的URL編碼,實際上應該指的是URI編碼。
foo://example.com:8042/over/there?name=ferret#nose
\__/ \_______________/\_________/\__________/\__/
| | | | |scheme authority path query fragment
哪些字元需要編碼
RFC3986文件規定,URL 中只允許包含英文字母(a-zA-Z)、數字(0-9)、-_.~ 4個特殊字元以及所有保留字元。RFC3986文件對Url的編解碼問題做出了詳細的建議,指出了哪些字元需要被編碼才不會引起Url語義的轉變,以及對為什麼這些字元需要編碼做出了相應的解釋。
US-ASCII字符集中沒有對應的可列印字元:Url中只允許使用可列印字元。US-ASCII碼中的10-7F位元組全都表示控制字元,這些字元都不能直接出現在Url中。同時,對於80-FF位元組(ISO-8859-1),由於已經超出了US-ACII定義的位元組範圍,因此也不可以放在Url中。
保留字元:URL 可以劃分成若干個元件,協議、主機、路徑等。有一些字元(:/?#[]@)是用作分隔不同元件的。
例如:冒號用於分隔協議和主機,/用於分隔主機和路徑,?用於分隔路徑和查詢引數,等等。還有一些字元(!$&'()*+,;=)用於在每個元件中起到分隔作用的,如=用於表示查詢引數中的鍵值對,&符號用於分隔查詢多個鍵值對。當元件中的普通資料包含這些特殊字元時,需要對其進行編碼。
RFC3986中指定了以下字元為保留字元:! * ' ( ) ; : @ & = + $ , / ? # [ ]
不安全字元:還有一些字元,當他們直接放在URL中的時候,可能會引起解析程式的歧義。這些字元被視為不安全字元,原因有很多。
- 空格:Url在傳輸的過程,或者使用者在排版的過程,或者文字處理程式在處理Url的過程,都有可能引入無關緊要的空格,或者將那些有意義的空格給去掉。
- 引號以及<>:引號和尖括號通常用於在普通文字中起到分隔Url的作用
- #:通常用於表示書籤或者錨點
- %:百分號本身用作對不安全字元進行編碼時使用的特殊字元,因此本身需要編碼
- {}|\^[]`~:某一些閘道器或者傳輸代理會篡改這些字元
需要注意的是,對於Url中的合法字元,編碼和不編碼是等價的,但是對於上面提到的這些字元,如果不經過編碼,那麼它們有可能會造成Url語義的不同。因此對於Url而言,只有普通英文字元和數字,特殊字元$-_.+!*'()還有保留字元,才能出現在未經編碼的Url之中。其他字元均需要經過編碼之後才能出現在Url中。
但是由於歷史原因,目前尚存在一些不標準的編碼實現。例如對於~符號,雖然RFC3986文件規定,對於波浪符號~,不需要進行Url編碼,但是還是有很多老的閘道器或者傳輸代理會進行編碼。
URL編碼遵循下列規則: 每對name/value由&;符分開;每對來自表單的name/value由=符分開。如果使用者沒有輸入值給這個name,那麼這個name還是出現,只是無值。任何特殊的字元(就是那些不是簡單的七位ASCII,如漢字)將以百分符%用十六進位制編碼,當然也包括象 =,&;,和 % 這些特殊的字元。其實url編碼就是一個字元ascii碼的十六進位制。不過稍微有些變動,需要在前面加上“%”。比如“\”,它的ascii碼是92,92的十六進位制是5c,所以“\”的url編碼就是%5c。那麼漢字的url編碼呢?很簡單,看例子:“胡”的ascii碼是-17670,十六進位制是BAFA,url編碼是“%BA%FA”。
防止sql注入。URL編碼平時是用不到的,因為IE會自動將輸入到位址列的非數字字母轉換為url編碼。曾有人提出資料庫名字裡帶上“#”以防止被下載,因為IE遇到#就會忽略後面的字母。破解方法很簡單——用url編碼%23替換掉#。也可以使用 “雙URL編碼”
如何對 URL 中的非法字元進行編碼
URL 編碼通常也被稱為 百分號編碼(Url Encoding,also known as percent-encoding),是因為它的編碼方式非常簡單,使用%百分號加上兩位的字元——0123456789ABCDEF——代表一個位元組的十六進位制形式。Url編碼預設使用的字符集是US-ASCII。例如a在US-ASCII碼中對應的位元組是0x61,那麼Url編碼之後得到的就是%61,我們在位址列上輸入http://g.cn/search?q=%61%62%63,實際上就等同於在google上搜索abc了。又如@符號在ASCII字符集中對應的位元組為0x40,經過Url編碼之後得到的是%40。
對於非ASCII字元,需要使用ASCII字符集的超集進行編碼得到相應的位元組,然後對每個位元組執行百分號編碼。對於Unicode字元,RFC文件建議使用utf-8對其進行編碼得到相應的位元組,然後對每個位元組執行百分號編碼。如"中文"使用UTF-8字符集得到的位元組為0xE4 0xB8 0xAD 0xE6 0x96 0x87,經過Url編碼之後得到"%E4%B8%AD%E6%96%87"。
如果某個位元組對應著ASCII字符集中的某個非保留字元,則此位元組無需使用百分號表示。例如"Url編碼",使用UTF-8編碼得到的位元組是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由於前三個位元組對應著ASCII中的非保留字元"Url",因此這三個位元組可以用非保留字元"Url"表示。最終的Url編碼可以簡化成"Url%E7%BC%96%E7%A0%81" ,當然,如果你用"%55%72%6C%E7%BC%96%E7%A0%81"也是可以的。
由於歷史的原因,有一些Url編碼實現並不完全遵循這樣的原則,下面會提到。
Javascript中的escape, encodeURI和encodeURIComponent的區別
JavaScript中提供了3對函式用來對Url編碼以得到合法的Url,它們分別是escape / unescape, encodeURI / decodeURI和encodeURIComponent / decodeURIComponent。由於解碼和編碼的過程是可逆的,因此這裡只解釋編碼的過程。
這三個編碼的函式——escape,encodeURI,encodeURIComponent——都是用於將不安全不合法的Url字元轉換為合法的Url字元表示,它們有以下幾個不同點。
安全字元不同:
下面列出了這三個函式的安全字元(即函式不會對這些字元進行編碼)
- escape(69個):*/@+-._0-9a-zA-Z
- encodeURI(82個):!#$&'()*+,/:;[email protected]_~0-9a-zA-Z
- encodeURIComponent(71個):!'()*-._~0-9a-zA-Z
相容性不同:escape函式是從Javascript 1.0的時候就存在了,其他兩個函式是在Javascript 1.5才引入的。但是由於Javascript 1.5已經非常普及了,所以實際上使用encodeURI和encodeURIComponent並不會有什麼相容性問題。
對Unicode字元的編碼方式不同:這三個函式對於ASCII字元的編碼方式相同,均是使用百分號+兩位十六進位制字元來表示。但是對於Unicode字元,escape的編碼方式是%uxxxx,其中的xxxx是用來表示unicode字元的4位十六進位制字元。這種方式已經被W3C廢棄了。但是在ECMA-262標準中仍然保留著escape的這種編碼語法。encodeURI和encodeURIComponent則使用UTF-8對非ASCII字元進行編碼,然後再進行百分號編碼。這是RFC推薦的。因此建議儘可能的使用這兩個函式替代escape進行編碼。
適用場合不同:encodeURI被用作對一個完整的URI進行編碼,而encodeURIComponent被用作對URI的一個元件進行編碼。從上面提到的安全字元範圍表格來看,我們會發現,encodeURIComponent編碼的字元範圍要比encodeURI的大。我們上面提到過,保留字元一般是用來分隔URI元件(一個URI可以被切割成多個元件,參考預備知識一節)或者子元件(如URI中查詢引數的分隔符),如:號用於分隔scheme和主機,?號用於分隔主機和路徑。由於encodeURI操縱的物件是一個完整的的URI,這些字元在URI中本來就有特殊用途,因此這些保留字元不會被encodeURI編碼,否則意義就變了。
元件內部有自己的資料表示格式,但是這些資料內部不能包含有分隔元件的保留字元,否則就會導致整個URI中元件的分隔混亂。因此對於單個元件使用encodeURIComponent,需要編碼的字元就更多了。
表單提交
當Html的表單被提交時,每個表單域都會被Url編碼之後才在被髮送。由於歷史的原因,表單使用的Url編碼實現並不符合最新的標準。例如對於空格使用的編碼並不是%20,而是+號,如果表單使用的是Post方法提交的,我們可以在HTTP頭中看到有一個Content-Type的header,值為application/x-www-form-urlencoded。大部分應用程式均能處理這種非標準實現的Url編碼,但是在客戶端Javascript中,並沒有一個函式能夠將+號解碼成空格,只能自己寫轉換函式。還有,對於非ASCII字元,使用的編碼字符集取決於當前文件使用的字符集。例如我們在Html頭部加上
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />這樣瀏覽器就會使用gb2312去渲染此文件(注意,當HTML文件中沒有設定此meta標籤,則瀏覽器會根據當前使用者喜好去自動選擇字符集,使用者也可以強制當前網站使用某個指定的字符集)。當提交表單時,Url編碼使用的字符集就是gb2312。
之前在使用Aptana(為什麼專指aptana下面會提到)遇到一個很迷惑的問題,就是在使用encodeURI的時候,發現它編碼得到的結果和我想的很不一樣。下面是我的示例程式碼:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
</head>
<body>
<script type="text/javascript">
document.write(encodeURI("中文"));
</script>
</body>
</html>執行結果輸出%E6%B6%93%EE%85%9F%E6%9E%83。顯然這並不是使用UTF-8字符集進行Url編碼得到的結果(在Google上搜索"中文",Url中顯示的是%E4%B8%AD%E6%96%87)。
所以我當時就很質疑,難道encodeURI還跟頁面編碼有關,但是我發現,正常情況下,如果你使用gb2312進行Url編碼也不會得到這個結果的才是。後來終於被我發現,原來是頁面檔案儲存使用的字符集和Meta標籤中指定的字符集不一致導致的問題。Aptana的編輯器預設情況下使用UTF-8字符集。也就是說這個檔案實際儲存的時候使用的是UTF-8字符集。但是由於Meta標籤中指定了gb2312,這個時候,瀏覽器就會按照gb2312去解析這個文件,那麼自然在"中文"這個字串這裡就會出錯,因為"中文"字串用UTF-8編碼過後得到的位元組是0xE4 0xB8 0xAD 0xE6 0x96 0x87,這6個位元組又被瀏覽器拿gb2312去解碼,那麼就會得到另外三個漢字"涓枃"(GBK中一個漢字佔兩個位元組),這三個漢字在傳入encodeURI函式之後得到的結果就是%E6%B6%93%EE%85%9F%E6%9E%83。因此,encodeURI使用的還是UTF-8,並不會受到頁面字符集的影響。
對於包含中文的Url的處理問題,不同瀏覽器有不同的表現。例如對於IE,如果你勾選了高階設定"總是以UTF-8傳送Url",那麼Url中的路徑部分的中文會使用UTF-8進行Url編碼之後傳送給服務端,而查詢引數中的中文部分使用系統預設字符集進行Url編碼。為了保證最大互操作性,建議所有放到Url中的元件全部顯式指定某個字符集進行Url編碼,而不依賴於瀏覽器的預設實現。
另外,很多HTTP監視工具或者瀏覽器位址列等在顯示Url的時候會自動將Url進行一次解碼(使用UTF-8字符集),這就是為什麼當你在Firefox中訪問Google搜尋中文的時候,位址列顯示的Url包含中文的緣故。但實際上傳送給服務端的原始Url還是經過編碼的。你可以在位址列上使用Javascript訪問location.href就可以看出來了。在研究Url編解碼的時候千萬別被這些假象給迷惑了。
URL 與 URI
很多人會混淆這兩個名詞。
URL:(Uniform/Universal Resource Locator 的縮寫,統一資源定位符)。
URI:(Uniform Resource Identifier 的縮寫,統一資源識別符號)。
關係:
URI 屬於 URL 更低層次的抽象,一種字串文字標準。
就是說,URI 屬於父類,而 URL 屬於 URI 的子類。URL 是 URI 的一個子集。
二者的區別:
URI 表示請求伺服器的路徑,定義這麼一個資源。而 URL 同時說明要如何訪問這個資源(http://)。
埠 與 URL 標準格式
何為埠?埠(Port),相當於一種資料的傳輸通道。用於接受某些資料,然後傳輸給相應的服務,而電腦將這些資料處理後,再將相應的回覆通過開啟的埠傳給對方。
埠的作用:因為 IP 地址與網路服務的關係是一對多的關係。所以實際上因特網上是通過 IP 地址加上埠號來區分不同的服務的。
埠是通過埠號來標記的,埠號只有整數,範圍是從 0 到 65535。
URL 標準格式
通常而言,我們所熟悉的 URL 的常見定義格式為:
scheme://host[:port#]/path/.../[;url-params][?query-string][#anchor]
scheme //有我們很熟悉的http、https、ftp以及著名的ed2k,迅雷的thunder等。
host //HTTP伺服器的IP地址或者域名
port# //HTTP伺服器的預設埠是80,這種情況下埠號可以省略。如果使用了別的埠,必須指明,例如tomcat的預設埠是8080 http://localhost:8080/
path //訪問資源的路徑
url-params //所帶引數
query-string //傳送給http伺服器的資料
anchor //錨點定位利用 <a> 標籤自動解析 url
開發當中一個很常見的場景是,需要從 URL 中提取一些需要的元素,譬如 host 、 請求引數等等。
通常的做法是寫正則去匹配相應的欄位,當然,這裡要安利下述這種方法,來自 James 的 blog,原理是動態建立一個 a 標籤,利用瀏覽器的一些原生方法及一些正則(為了健壯性正則還是要的),完美解析 URL ,獲取我們想要的任意一個部分。
程式碼如下:
// This function creates a new anchor element and uses location
// properties (inherent) to get the desired URL data. Some String
// operations are used (to normalize results across browsers).
function parseURL(url) {
var a = document.createElement('a');
a.href = url;
return {
source: url,
protocol: a.protocol.replace(':',''),
host: a.hostname,
port: a.port,
query: a.search,
params: (function(){
var ret = {},
seg = a.search.replace(/^\?/,'').split('&'),
len = seg.length, i = 0, s;
for (;i<len;i++) {
if (!seg[i]) { continue; }
s = seg[i].split('=');
ret[s[0]] = s[1];
}
return ret;
})(),
file: (a.pathname.match(/([^/?#]+)$/i) || [,''])[1],
hash: a.hash.replace('#',''),
path: a.pathname.replace(/^([^/])/,'/$1'),
relative: (a.href.match(/tps?:\/[^/]+(.+)/) || [,''])[1],
segments: a.pathname.replace(/^\//,'').split('/')
};
}Usage 使用方法:
var myURL = parseURL('http://abc.com:8080/dir/index.html?id=255&m=hello#top');
myURL.file; // = 'index.html'
myURL.hash; // = 'top'
myURL.host; // = 'abc.com'
myURL.query; // = '?id=255&m=hello'
myURL.params; // = Object = { id: 255, m: hello }
myURL.path; // = '/dir/index.html'
myURL.segments; // = Array = ['dir', 'index.html']
myURL.port; // = '8080'
myURL.protocol; // = 'http'
myURL.source; // = 'http://abc.com:8080/dir/index.html?id=255&m=hello#top'利用上述方法,即可解析得到 URL 的任意部分。
URL 編碼
為什麼要進行URL編碼?通常如果一樣東西需要編碼,說明這樣東西並不適合直接進行傳輸。
1、會引起歧義:例如 URL 引數字串中使用 key=value 這樣的鍵值對形式來傳參,鍵值對之間以 & 符號分隔,如 ?postid=5038412&t=1450591802326,伺服器會根據引數串的 & 和 = 對引數進行解析,如果 value 字串中包含了 = 或者 & ,如寶潔公司的簡稱為P&G,假設需要當做引數去傳遞,那麼可能URL所帶引數可能會是這樣 ?name=P&G&t=1450591802326,因為引數中多了一個&勢必會造成接收 URL 的伺服器解析錯誤,因此必須將引起歧義的 & 和 = 符號進行轉義, 也就是對其進行編碼。
2、非法字元:又如,URL 的編碼格式採用的是 ASCII 碼,而不是 Unicode,這也就是說你不能在 URL 中包含任何非 ASCII 字元,例如中文。否則如果客戶端瀏覽器和服務端瀏覽器支援的字符集不同的情況下,中文可能會造成問題。
那麼如何編碼?如下:
escape 、 encodeURI 、encodeURIComponent
escape()
首先想宣告的是,W3C把這個函式廢棄了,身為一名前端如果還用這個函式是要打臉的。
escape只是對字串進行編碼(而其餘兩種是對URL進行編碼),與URL編碼無關。編碼之後的效果是以 %XX 或者 %uXXXX 這種形式呈現的。它不會對 ASCII字元、數字 以及 @ * / + 進行編碼。
根據 MDN 的說明,escape 應當換用為 encodeURI 或 encodeURIComponent;unescape 應當換用為 decodeURI 或 decodeURIComponent。escape 應該避免使用。舉例如下:
encodeURI('https://www.baidu.com/ a b c')
// "https://www.baidu.com/%20a%20b%20c"
encodeURIComponent('https://www.baidu.com/ a b c')
// "https%3A%2F%2Fwww.baidu.com%2F%20a%20b%20c"
//而 escape 會編碼成下面這樣,eocode 了冒號卻沒 encode 斜槓,十分怪異,故廢棄之
escape('https://www.baidu.com/ a b c')
// "https%3A//www.baidu.com/%20a%20b%20c" encodeURI()
encodeURI() 是 Javascript 中真正用來對 URL 編碼的函式。它著眼於對整個URL進行編碼。
encodeURI("http://www.cnblogs.com/season-huang/some other thing");
//"http://www.cnblogs.com/season-huang/some%20other%20thing";編碼後變為上述結果,可以看到空格被編碼成了%20,而斜槓 / ,冒號 : 並沒有被編碼。是的,它用於對整個 URL 直接編碼,不會對 ASCII字母 、數字 、 ~ ! @ # $ & * ( ) = : / , ; ? + ' 進行編碼。
encodeURI("[email protected]#$&*()=:/,;?+'")
// [email protected]#$&*()=:/,;?+'encodeURIComponent()
嘿,有的時候,我們的 URL 長這樣子,請求引數中帶了另一個 URL :
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";直接進行 encodeURI 顯然是不行的。因為 encodeURI 不會對冒號 : 及斜槓 / 進行轉義,那麼就會出現上述所說的伺服器接受到之後解析會有歧義。
encodeURI(URL)
// "http://www.a.com?foo=http://www.b.com?t=123&b=456"這個時候,就該用到 encodeURIComponent() 。它的作用是對 URL 中的引數進行編碼,記住是對引數,而不是對整個 URL 進行編碼。
因為它僅僅不對 ASCII字母、數字 ~ ! * ( ) ' 進行編碼。
錯誤的用法:
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";
encodeURIComponent(URL);
// "http%3A%2F%2Fwww.a.com%3Ffoo%3Dhttp%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"
// 錯誤的用法,看到第一個 http 的冒號及斜槓也被 encode 了正確的用法:encodeURIComponent() 著眼於對單個的引數進行編碼:
var param = "http://www.b.com?t=123&s=456"; // 要被編碼的引數
URL = "http://www.a.com?foo="+encodeURIComponent(param);
//"http://www.a.com?foo=http%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"利用上述的使用<a>標籤解析 URL 以及根據業務場景配合 encodeURI() 與 encodeURIComponent() 便能夠很好的處理 URL 的編碼問題。
應用場景最常見的一個是手工拼接 URL 的時候,對每對 key-value 用 encodeURIComponent 進行轉義,再進行傳輸。
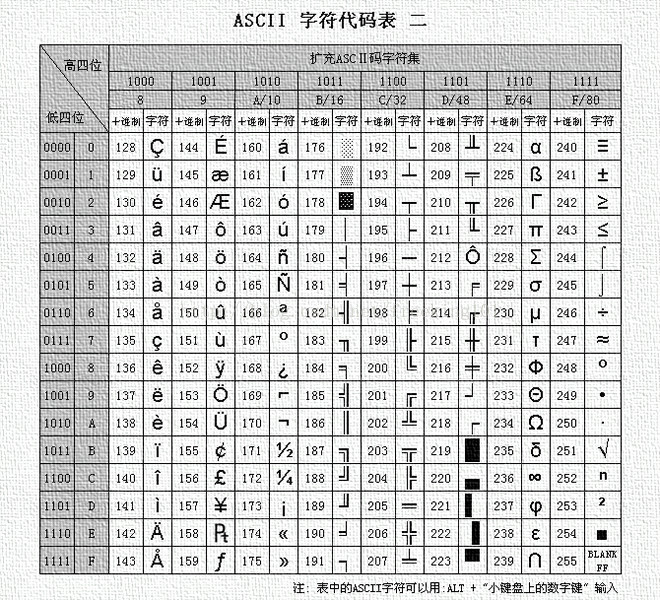
ASCII碼錶可以看成由三部分組成:
第一部分:非列印的控制字元。由00H到1FH共32個,一般用來通訊或作為控制之用。有些可以顯示在螢幕上,有些則不能顯示,但能看到其效果(如換行、退格).如下表:
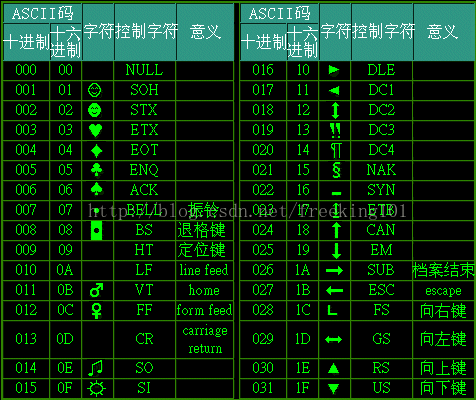
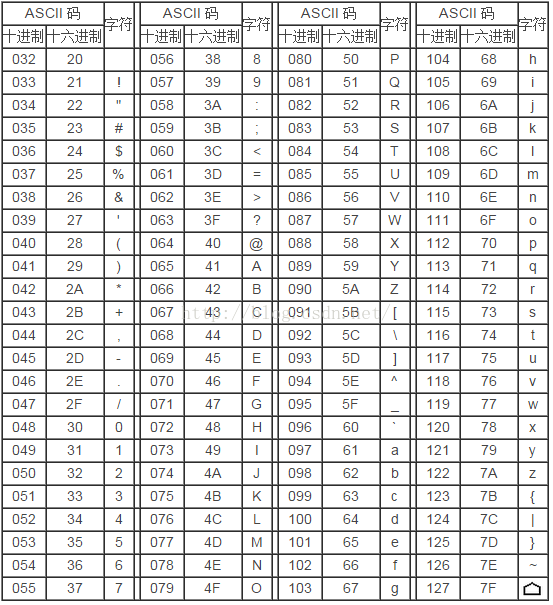
第二部分:列印字元。由20H到7FH共96個,這95個字元是用來表示阿拉伯數字、英文字母大小寫和下劃線、括號等符號,都可以顯示在螢幕上.如下表:
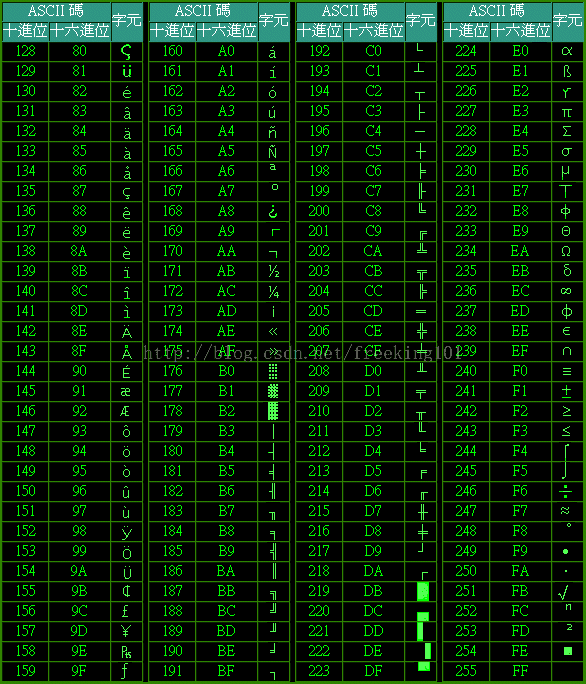
第三部分:擴充套件 ASCII 列印字元。由80H到0FFH共128個字元,一般稱為"擴充字元",這128個擴充字元是由IBM制定的,並非標準的ASCII碼.這些字元是用來表示框線、音標和其它歐洲非英語系的字母。
ASCII 表 1
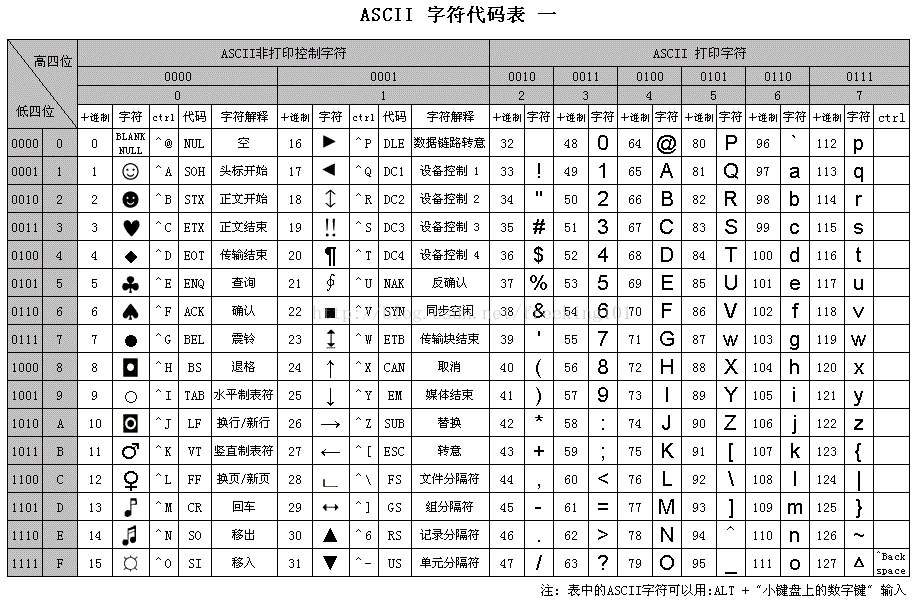
ASCII 表 2
一、問題的由來
問題:當url地址中包含&、+、%等特殊字元(主要是傳遞引數時,引數的內容中包含這些字元)時,地址無效。比如http://10.190.0.0:108/doc/test+desc2.bmp,若檔名中出現+/&等特殊字元,後臺報404錯誤,即web伺服器找不到頁面或者資源。
-------------------------------------------------------------------------------------------------------------------------------------
URL就是網址,只要上網,就一定會用到。

一般來說,URL只能使用英文字母、阿拉伯數字和某些標點符號,不能使用其他文字和符號。比如,世界上有英文字母的網址“http://www.abc.com”,但是沒有希臘字母的網址“http://www.aβγ.com”(讀作阿爾法-貝塔-伽瑪.com)。這是因為網路標準RFC 1738做了硬性規定:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
“只有字母和數字[0-9a-zA-Z]、一些特殊符號“$-_.+!*'(),”[不包括雙引號]、以及某些保留字,才可以不經過編碼直接用於URL。”
這意味著,如果URL中有漢字,就必須編碼後使用。但是麻煩的是,RFC 1738沒有規定具體的編碼方法,而是交給應用程式(瀏覽器)自己決定。這導致“URL編碼”成為了一個混亂的領域。
在使用url進行引數傳遞時,經常會傳遞一些中文名(或含有特殊字元)的引數或URL地址,在後臺處理時會發生轉換錯誤。這些特殊符號在URL中是不能直接傳遞的,如果要在URL中傳遞這些特殊符號,那麼就要使用他們的編碼了。編碼的格式為:%加字元的ASCII碼,即一個百分號%,後面跟對應字元的ASCII(16進位制)碼值。例如空格的編碼值是"%20"。下表中列出了一些URL特殊符號及編碼。
| 序號 | 特殊字元 | 含義 | 十六進位制值 |
| 1. | + | URL 中+號表示空格 | %2B |
| 2. | 空格 | URL中的空格可以用+號或者編碼 | %20 |
| 3. | / | 分隔目錄和子目錄 | %2F |
| 4. | ? | 分隔實際的 URL 和引數 | %3F |
| 5. | % | 指定特殊字元 | %25 |
| 6. | # | 表示書籤 | %23 |
| 7. | & | URL 中指定的引數間的分隔符 | %26 |
| 8. | = | URL 中指定引數的值 | %3D |
例:要傳遞字串“this%is#te=st&o k?+/”作為引數t傳給te.asp,則URL可以是:
te.asp?t=this%is#te=st&o k?+/ 或者
te.asp?t=this%is#te=st&o+k?+/ (空格可以用 或+代替)
java中URL 的編碼和解碼函式
java.net.URLEncoder.encode(String s)和java.net.URLDecoder.decode(String s);
在javascript 中URL 的編碼和解碼函式
escape(String s)和(String s) ;
如果使用escape()函式,漢字也會轉為亂碼。後來就寫了一段js重新實現escape()的功能,這裡拿#為例子來說明一下:(其他符號同)
function encodeValue(objValue)
{
if(objValue.indexOf("#")!= -1)
{
objValue=objValue.replace("#","#");
objValue=encodeValue(objValue);
}
return objValue;
}最後說一點:在url中中如果得遇到#會自動轉成#,這樣 request.getParameter("引數")就可以得到正確的結果。
下面就讓我們看看,“URL編碼”到底有多混亂。我會依次分析四種不同的情況,在每一種情況中,瀏覽器的URL編碼方法都不一樣。把它們的差異解釋清楚之後,我再說如何用JavaScript找到一個統一的編碼方法。
二、情況1:網址路徑中包含漢字
開啟IE(我用的是8.0版),輸入網址“http://zh.wikipedia.org/wiki/春節”。注意,“春節”這兩個字此時是網址路徑的一部分。

檢視HTTP請求的頭資訊,會發現IE實際查詢的網址是“http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82”。也就是說,IE自動將“春節”編碼成了“%E6%98%A5%E8%8A%82”。
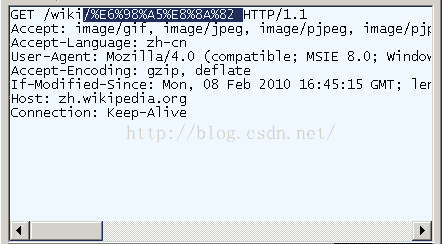
我們知道,“春”和“節”的utf-8編碼分別是“E6 98 A5”和“E8 8A 82”,因此,“%E6%98%A5%E8%8A%82”就是按照順序,在每個位元組前加上%而得到的。
在Firefox中測試,也得到了同樣的結果。所以,結論1就是,網址路徑的編碼,用的是utf-8編碼。
三、情況2:查詢字串包含漢字
在IE中輸入網址“http://www.baidu.com/s?wd=春節”。注意,“春節”這兩個字此時屬於查詢字串,不屬於網址路徑,不要與情況1混淆。

檢視HTTP請求的頭資訊,會發現IE將“春節”轉化成了一個亂碼。
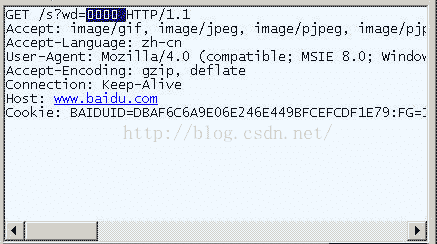
切換到十六進位制方式,才能清楚地看到,“春節”被轉成了“B4 BA BD DA”。
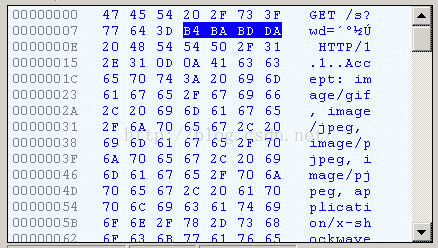
我們知道,“春”和“節”的GB2312編碼(我的作業系統“Windows XP”中文版的預設編碼)分別是“B4 BA”和“BD DA”。因此,IE實際上就是將查詢字串,以GB2312編碼的格式傳送出去。
Firefox的處理方法,略有不同。它傳送的HTTP Head是“wd=%B4%BA%BD%DA”。也就是說,同樣採用GB2312編碼,但是在每個位元組前加上了%。
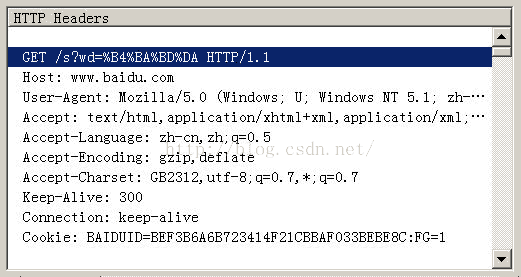
所以,結論2就是,查詢字串的編碼,用的是作業系統的預設編碼。
四、情況3:Get方法生成的URL包含漢字
前面說的是直接輸入網址的情況,但是更常見的情況是,在已開啟的網頁上,直接用Get或Post方法發出HTTP請求。
根據臺灣中興大學呂瑞麟老師的試驗,這時的編碼方法由網頁的編碼決定,也就是由HTML原始碼中字符集的設定決定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
如果上面這一行最後的charset是UTF-8,則URL就以UTF-8編碼;如果是GB2312,URL 就以GB2312編碼。
舉例來說,百度是GB2312編碼,Google是UTF-8編碼。因此,從它們的搜尋框中搜索同一個詞“春節”,生成的查詢字串是不一樣的。
百度生成的是%B4%BA%BD%DA,這是GB2312編碼。
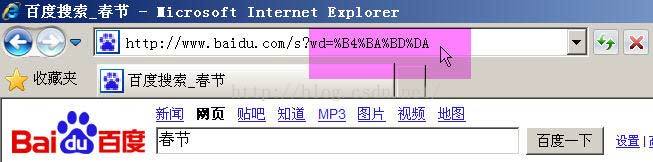
Google生成的是%E6%98%A5%E8%8A%82,這是UTF-8編碼。
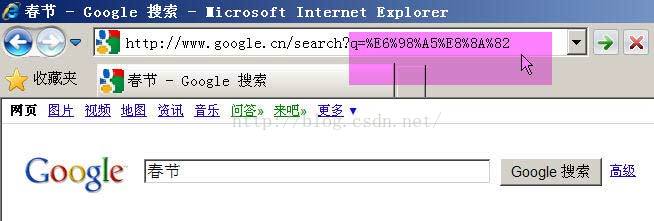
所以,結論3就是,GET和POST方法的編碼,用的是網頁的編碼。
五、情況4:Ajax呼叫的URL包含漢字
前面三種情況都是由瀏覽器發出HTTP請求,最後一種情況則是由Javascript生成HTTP請求,也就是Ajax呼叫。還是根據呂瑞麟老師的文章,在這種情況下,IE和Firefox的處理方式完全不一樣。
舉例來說,有這樣兩行程式碼:
url = url + "?q=" +document.myform.elements[0].value; // 假定使用者在表單中提交的值是“春節”這兩個字
http_request.open('GET', url, true);
那麼,無論網頁使用什麼字符集,IE傳送給伺服器的總是“q=%B4%BA%BD%DA”,而Firefox傳送給伺服器的總是“q=%E6%98%A5%E8%8A%82”。也就是說,在Ajax呼叫中,IE總是採用GB2312編碼(作業系統的預設編碼),而Firefox總是採用utf-8編碼。這就是我們的結論4。
六、Javascript函式:escape()
好了,到此為止,四種情況都說完了。
假定前面你都看懂了,那麼此時你應該會感到很頭痛。因為,實在太混亂了。不同的作業系統、不同的瀏覽器、不同的網頁字符集,將導致完全不同的編碼結果。如果程式設計師要把每一種結果都考慮進去,是不是太恐怖了?有沒有辦法,能夠保證客戶端只用一種編碼方法向伺服器發出請求?
回答是有的,就是使用Javascript先對URL編碼,然後再向伺服器提交,不要給瀏覽器插手的機會。因為Javascript的輸出總是一致的,所以就保證了伺服器得到的資料是格式統一的。
Javascript語言用於編碼的函式,一共有三個,最古老的一個就是escape()。雖然這個函式現在已經不提倡使用了,但是由於歷史原因,很多地方還在使用它,所以有必要先從它講起。
實際上,escape()不能直接用於URL編碼,它的真正作用是返回一個字元的Unicode編碼值。比如“春節”的返回結果是%u6625%u8282,也就是說在Unicode字符集中,“春”是第6625個(十六進位制)字元,“節”是第8282個(十六進位制)字元。

它的具體規則是,除了ASCII字母、數字、標點符號“@ * _ + - . /”以外,對其他所有字元進行編碼。在\u0000到\u00ff之間的符號被轉成%xx的形式,其餘符號被轉成%uxxxx的形式。對應的解碼函式是unescape()。
所以,“Hello World”的escape()編碼就是“Hello%20World”。因為空格的Unicode值是20(十六進位制)。

還有兩個地方需要注意。
首先,無論網頁的原始編碼是什麼,一旦被Javascript編碼,就都變為unicode字元。也就是說,Javascipt函式的輸入和輸出,預設都是Unicode字元。這一點對下面兩個函式也適用。

其次,escape()不對“+”編碼。但是我們知道,網頁在提交表單的時候,如果有空格,則會被轉化為+字元。伺服器處理資料的時候,會把+號處理成空格。所以,使用的時候要小心。
七、Javascript函式:encodeURI()
encodeURI()是Javascript中真正用來對URL編碼的函式。
它著眼於對整個URL進行編碼,因此除了常見的符號以外,對其他一些在網址中有特殊含義的符號“; / ? : @ & = + $ , #”,也不進行編碼。編碼後,它輸出符號的utf-8形式,並且在每個位元組前加上%。
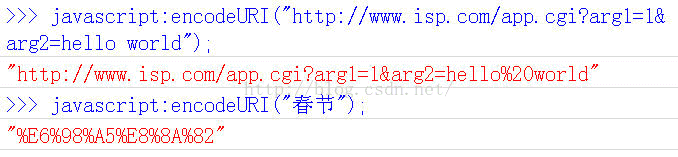
它對應的解碼函式是decodeURI()。

需要注意的是,它不對單引號'編碼。
八、Javascript函式:encodeURIComponent()
最後一個Javascript編碼函式是encodeURIComponent()。與encodeURI()的區別是,它用於對URL的組成部分進行個別編碼,而不用於對整個URL進行編碼。
因此,“; / ? : @ & = + $ , #”,這些在encodeURI()中不被編碼的符號,在encodeURIComponent()中統統會被編碼。至於具體的編碼方法,兩者是一樣。

它對應的解碼函式是decodeURIComponent()。
相關推薦
linux 下URL中 UTF-8編碼、GB2312編碼與漢字之間的轉換
下面是UTF-8編碼的轉換程式碼 #include <string.h> #include <stdio.h> #include <stdlib.h> /* 16進位制字元表 */ static const char c2x_table[] = "0
所有的字符編碼由System.Text.Encoding類獲取所有的字符編碼如Unicode編碼、 GB18030編碼、(UTF-8) 簡體中文(GB2312)
mac net 挪威 head sun -m abi cal 篩選 本頁列出來目前window下所有支持的字符編碼 ---通過 System.Text.Encoding.GetEncodings()獲取,裏面可以對其進行查詢,篩選,對同一個字符,在不同編碼進行查看和分
python中的字符串編碼問題——2.理解ASCII碼、ANSI碼、Unicode編碼、UTF-8編碼
unicode編碼 統一 col 簡單 utf 文字 stand 二進制 pan ASCII碼:全名是American Standard Code for Information Interchange,ASCII碼中,一個英文字母(不分大小寫)占一個字節的空間,範圍0x0
ASP.NET Core 編碼、web編碼、網頁編碼 System.Text.Encodings.Web
System.Text.Encodings.Web 空間包含表示 Web 編碼器的基類、表示 HTML、JavaScript 和 Url 字元編碼的子類,以及表示僅允許編碼特定字元、字元範圍或碼位的篩選器的類。 [ 定義來自 microsoft ] 該名稱空間有五個類,用於不同物件的編碼處理。
Java基礎知識-不會的 day07-練習、ASCII編碼、逆序、排序
1.for迴圈的“末尾迴圈體"可以不是i++,可以每次增長2或者其它數 for(int i=1;i<100;i+=2){}2.java語言中乘除和取餘先執行哪個?強制型別轉換和乘除先執行哪個? %和*/優先順序是相同的。 從左往右執行。強制型別轉換先執行,乘除後執
[Servlet]HttpServletResponse設定響應標頭、緩衝區、語系編碼、MIME
1. 設定響應標頭: 1) 標頭中的內容也是以鍵值對的形式出現,一行一個鍵值對,格式是"鍵:值列表",標頭允許一個鍵可以有多個值; 2) 在這裡羅列一下常用的HttpServletResponse裡關於響應標頭設定的方法; 3) setHeader和
mysql建立遠端使用者、mysql使用者授權、mysql編碼、mysql備份和mysql快捷登入
mysql和ubuntu版本Server version: 5.7.21-0ubuntu0.16.04.1 (Ubuntu) #mysql使用者建立和授權 ## 1.使用root使用者登入,檢視資料庫: mysql> select Host,User from mys
ASCII碼、Unicode編碼對照表 —— ASCII控制字元 Unicode編碼 字元編碼的前世今生
ASCII控制字元 Unicode編碼ASCII(American Standard Code for Information Interchange,美國資訊互換標準程式碼,ASCⅡ)是基於拉丁字母的一套電腦編碼系統。它主要用於顯示現代英語和其他西歐語言。它是現今最通用的
URL原理、URL編碼、URL特殊字元
通常如果一樣東西需要編碼,說明這樣東西並不適合傳輸。原因多種多樣,如Size過大,包含隱私資料,對於Url來說,之所以要進行編碼,是因為Url中有些字元會引起歧義。 例如,Url引數字串中使用key=value鍵值對這樣的形式來傳參,鍵值
code 128編碼中的特殊字元
code 128碼中有特殊控制字元,在程式中用字元無法表示,怎樣處理? 編寫條碼列印時,需要處理這些控制字元,查閱了不少資料但始終無法知道這些控制字元的用途。我在程式中是使用資料字典的方式進行控制,轉換輸入字串進行編碼,
Web的基本工作原理、HTTP協議和URL說明
發送 agen mes servlet img 設置 encoding 各類 doc Web工作原理 客戶端和Web服務器通過HTTP協議進行通信。Web服務器有是也叫HTTP服務器或Web容器。HTTP協議采用的是請求/響應模式。即客戶端發起HTTP請求,web服務器接
url參數中有+、空格、=、%、&、#等特殊符號的問題解決
amp 其它 分隔符 url參數 表示 轉化 無法 編碼 轉義 url出現了有+,空格,/,?,%,#,&,=等特殊符號的時候,可能在服務器端無法獲得正確的參數值,如何是好?解決辦法將這些字符轉化成服務器可以識別的字符,對應關系如下:URL字符轉義 用其它字符替代
Tomcat6.0下,請求url帶特殊字元|、\等導致解析出錯
Tomcat6.0下,請求url帶特殊字元|、\等導致解析出錯 背景 由於人力問題,最近被叫去搞下Java web ,幫忙做公司的一個老系統,用的是jdk6 和tomcat6,而我自己電腦之前裝的是jdk1.7和tomcat7 ,覺得應該沒什麼關係就懶得去換。但是前兩天遇
javascript處理url中有特殊字元的情況如“{、#、}...”
JavaScript中有三個可以對字串編碼的函式, 分別是: escape(),encodeURI(),encodeURIComponent(), 相應3個解碼函式: unescape(),decodeURI(),decodeURIComponent() 。 下面
ios-day21-01(對URL中的中文或特殊字元新增百分號轉義、把經過百分號轉義的URL還原)
NSString *urlStr = [NSString stringWithFormat:@"http://localhost/login.php?username=張三&password=1234"]; // 如果URL中包含中文字串或者特殊字元(例如空格),需要給URL新增百分號轉義
微信支付配置參數:支付授權目錄、回調支付URL
相關 分配 必須 申請 電腦 cas 主域名 最小 配置 一、開通微信支付的首要條件是:認證服務號或政府媒體類認證訂閱號(一般認證訂閱號無法申請微信支付) 二、微信支付分為老版支付和新版支付,除了較早期申請的用戶為老版支付,現均為新版微信支付。 三、公眾平臺微信支付開發配
防火墻(ASA)高級配置之URL過濾、日誌管理、透明模式
防火墻 url過濾 透明模式 楊書凡 asa日誌管理 對於防火墻產品來說,最重要的一個功能就是對事件進行日誌記錄。本篇博客將介紹如何對ASA進行日誌管理與分析、ASA透明模式的原理與配置、利用ASA防火墻的IOS特性實施URL過濾。一、URL過濾 利用ASA防火墻IOS的特性
七天學會ASP.NET MVC (六)——線程問題、異常處理、自定義URL
d+ mit nes 如何 bus blog edi default 繼續 本節又帶了一些常用的,卻很難理解的問題,本節從文件上傳功能的實現引出了線程使用,介紹了線程饑餓的解決方法,異常處理方法,了解RouteTable自定義路徑 。 目錄 實驗27—
項目一:第十二天 1、常見權限控制方式 2、基於shiro提供url攔截方式驗證權限 3、在realm中授權 5、總結驗證權限方式(四種) 6、用戶註銷7、基於treegrid實現菜單展示
eal 重復數 規則 認證通過 delete get 數據庫 filter 登陸 1 課程計劃 1、 常見權限控制方式 2、 基於shiro提供url攔截方式驗證權限 3、 在realm中授權 4、 基於shiro提供註解方式驗證權限 5、 總結驗證權限方式(四種) 6、
網站url路徑優化方法完全講解 (url優化、基於tp5、API接口開發)
dex 接下來 filename 配置文件 實現 tar 接口 官方 找到 url優化可是網站開發的必備高階技能,先看本實例優化前後效果比較: (同為調用前臺模塊下的index控制器下的index方法) 優化前:www.tp5.com/tp5/public/index.ph