
python機器學習入門到精通--實戰分析(三)
利用sklearn分析鳶尾花
前面兩篇文章提到了機器學習的入門的幾個基礎庫及拓展練習,現在我們就對前面知識點進行彙總進行一個簡單的機器學習應用,並構建模型。
練習即假定一名植物專家收集了每一朵鳶尾花的測量資料:花瓣的長度和寬度以及花萼的長度和寬度,所有測量結果的單位都是釐米。這些資料經過植物學專家分類成三個種類:setosa、versicolor、virginica。然後根據測量資料,確定每朵鳶尾花所屬的品種,在這裡我們將構建一個機器學習模型,從已知的品種進行學習,從而能夠預測新的品種。
在這篇部落格裡面,我們以鳶尾花資料集來測試,這個資料集包含在scikit-learn的datasets模組中,我們可以呼叫load_iris函式來載入資料:
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print("Keys of iris_dataset:\n{}".format(iris_dataset.keys()))
# load_iris返回的iris物件是一個Bunch物件,與字典非常相似,裡面包含鍵和值
Out[]:
Keys of iris_dataset:
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])DESCR鍵對應的值是資料集的簡要說明,比如:
print(iris_dataset['DESCR'][:193] + "\n...")
Out[]:
Iris Plants Database
====================
Notes
-----
Data Set Characteristics:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive att
...而我們列印iris_dataset可以看到,target_get鍵對應的是一個字串陣列,裡面包含我們需要預測的花的品種。
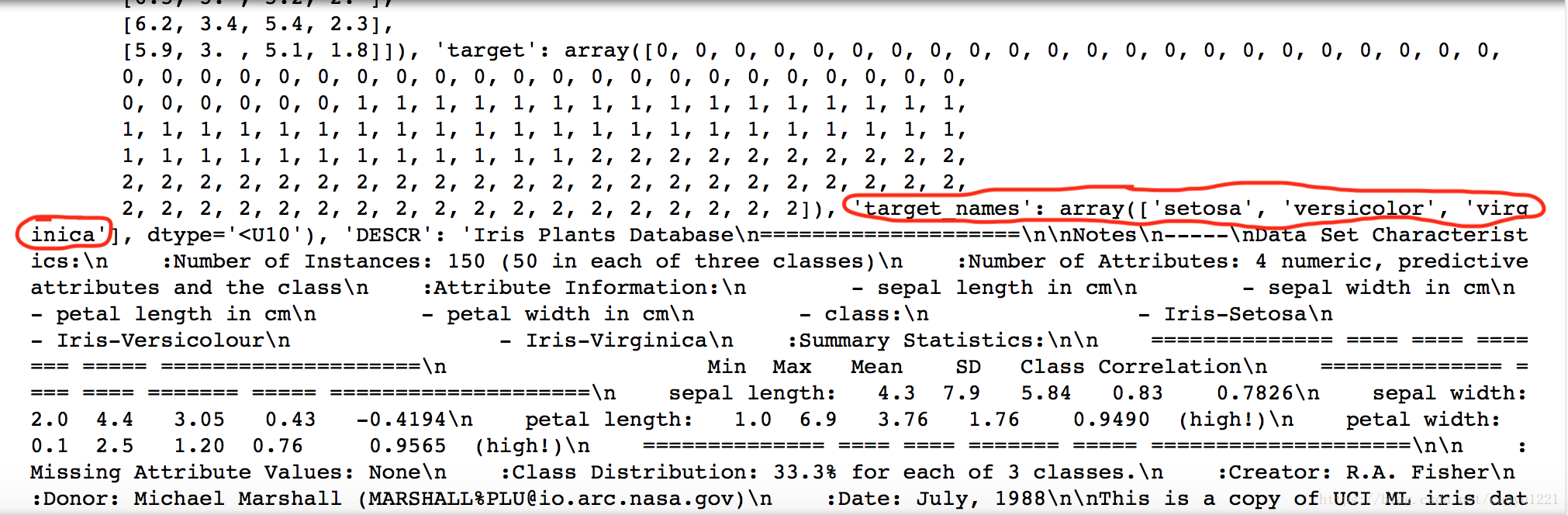
feature_names鍵對應的值是一個字串列表,對每一個特徵進行了說明:
print("Feature names:\n{}".format(iris_dataset['feature_names']))
Out[]:
Feature names:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']資料包含在target和data欄位中。data裡面是花萼長度、花萼寬度、花瓣長度、花瓣寬度的測量資料,格式為NumPy陣列。
data陣列的每一行對應一朵花,列代表每朵花的四個測量資料:
print("Shape of data:{}".format(iris_dataset['data'].shape))
Out[]:
# 陣列中包含150朵不同的花的測量資料,機器學習中的個體叫做樣本,屬性叫作特徵,data陣列的形狀(shape)是樣本數乘以特徵數
Shape of data:(150, 4)我們可以輸出前五個樣本的特徵數值:
print("First five rows of data:\n{}".format(iris_dataset['data'][:5]))
Out[]:
First five rows of data:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]我們還可以從target看到品種被轉換成0到2的整數:
print("Target:\n{}".format(iris_dataset['target']))
Out[]:
# 0-setosa, 1-versicolor, 2-virginica
Target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]在弄清資料模型裡每個鍵的含義後,我們開始利用資料構建一個機器模型,用於預測欣測量的品種,通常來說,我們在測量新資料之前,要知道這個模型是否有效,而我們不能直接將構建的模型去判定新的問題,因為我們的模型會一直記住整個訓練集,所以對於訓練集中的任何資料點總會預測正確的標籤。這種記憶無法告訴我們模型的泛化能力如何(新資料上能否正確預測)。
所以我們要用欣資料來評估模型的效能,新資料即之前沒有出現過的資料,而我們有這些新資料的標籤。通常的做法是將收集好的帶標籤的資料(150朵花的測量資料)分成兩部分。一部分資料用於構建機器學習模型,叫作訓練資料或訓練集。其餘資料用來評估模型效能,腳測試資料、測試集或留出集。
scikit-learn種的train_test_split函式可以打亂資料集並進行拆分。這個函式將75%的行資料及對應標籤作為訓練集,剩下25%的資料及其標籤作為測試集。訓練集與測試集分配比例可以隨意分配。
scikit-learn種的資料通常用大寫X表示,而標籤用小寫的y去表示。即我們數學函式裡面f(x)=y, x是函式的輸入,y是輸出。我們用大寫的X是因為資料是一個二維陣列,用小寫的y是因為目標是一個以為陣列(向量)。
現在我們開始拆分資料:
# 對資料進行拆分之前,用train_test_split函式利用偽隨機數生成器將資料集打亂。
#因為如果將最後25%的資料作為測試集,那麼所有資料點的標籤都是2(因為資料點是按順序排的)
#所以打亂順序確保測試集包含所有類別資料
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)為了確保多次運行同一函式能夠得到相同的輸出,我們利用random_state引數指定來隨機數生成種子。這樣函式輸出是固定不變的,所以這行程式碼的輸出始終相同。
train_test_split函式的輸出為X_train、X_test、y_train、y_test,它們都是NumPy陣列。X_train包含75%的行資料,X_test包含剩下25%:
#訓練集
print("X_train shape:{}".format(X_train.shape))
print("y_train shape:{}".format(y_train.shape))
Out[]:
X_train shape:(112, 4)
y_train shape:(112,)# 測試集
print("X_test shape:{}".format(X_test.shape))
print("y_test shape:{}".format(y_test.shape))
Out[]:
X_test shape:(38, 4)
y_test shape:(38,)在劃分好資料後,我們開始檢查一下資料,檢查資料的最佳方法之一就是將其視覺化,一種視覺化方法是繪製散點圖。為了繪製這張圖,我們首先將NumPy陣列轉化成pandas DataFrame。pandas有一個繪製散點圖矩陣的函式,scatter_matrix。
#利用X_train中的資料建立DataFrame
# 利用iris_dataset.fearure_names中的字串對資料列進行標記
import numpy as np
import pandas as pd
import mglearn
from pandas import DataFrame
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# 利用DataFrame建立散點圖矩陣,按y_train著色
grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15,15), marker='o',
hist_kwds={'bins':20}, s=60, alpha=.8, cmap=mglearn.cm3)
grr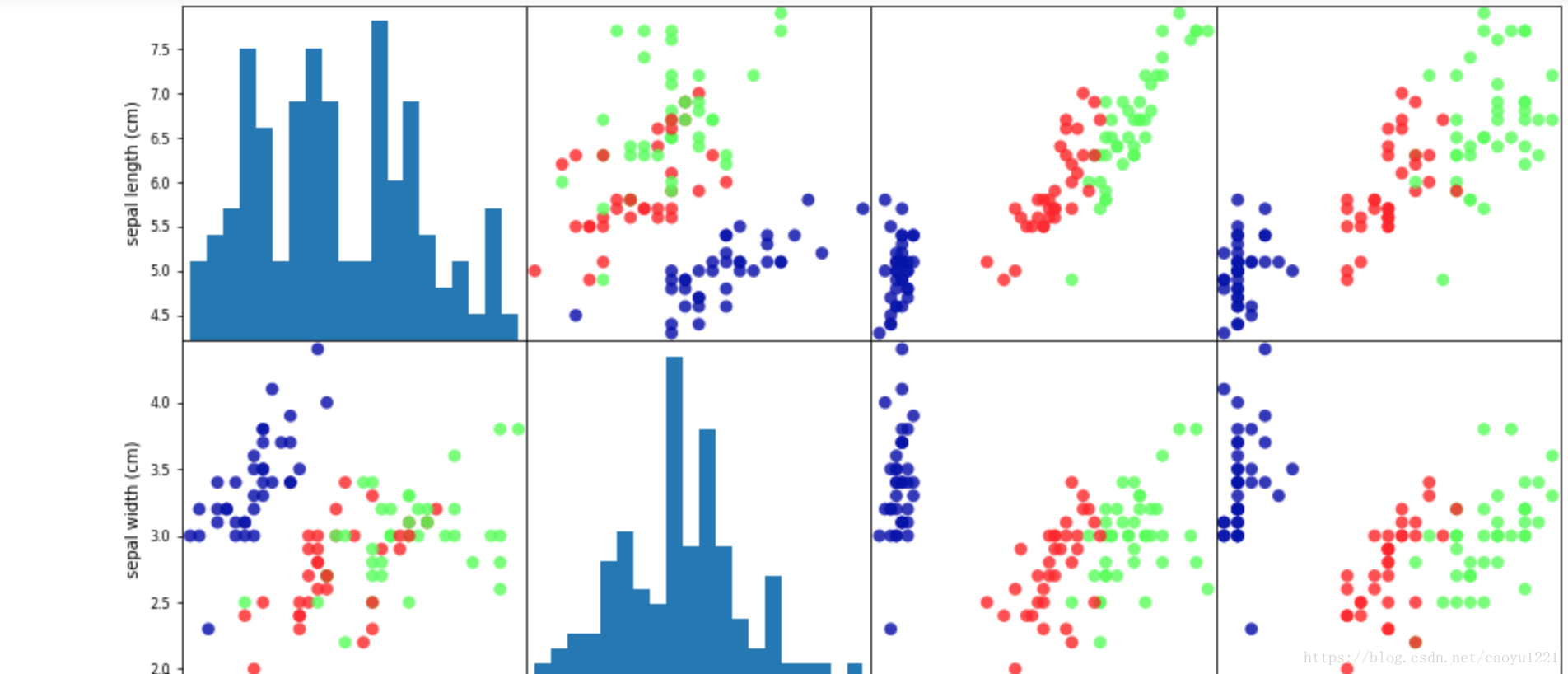
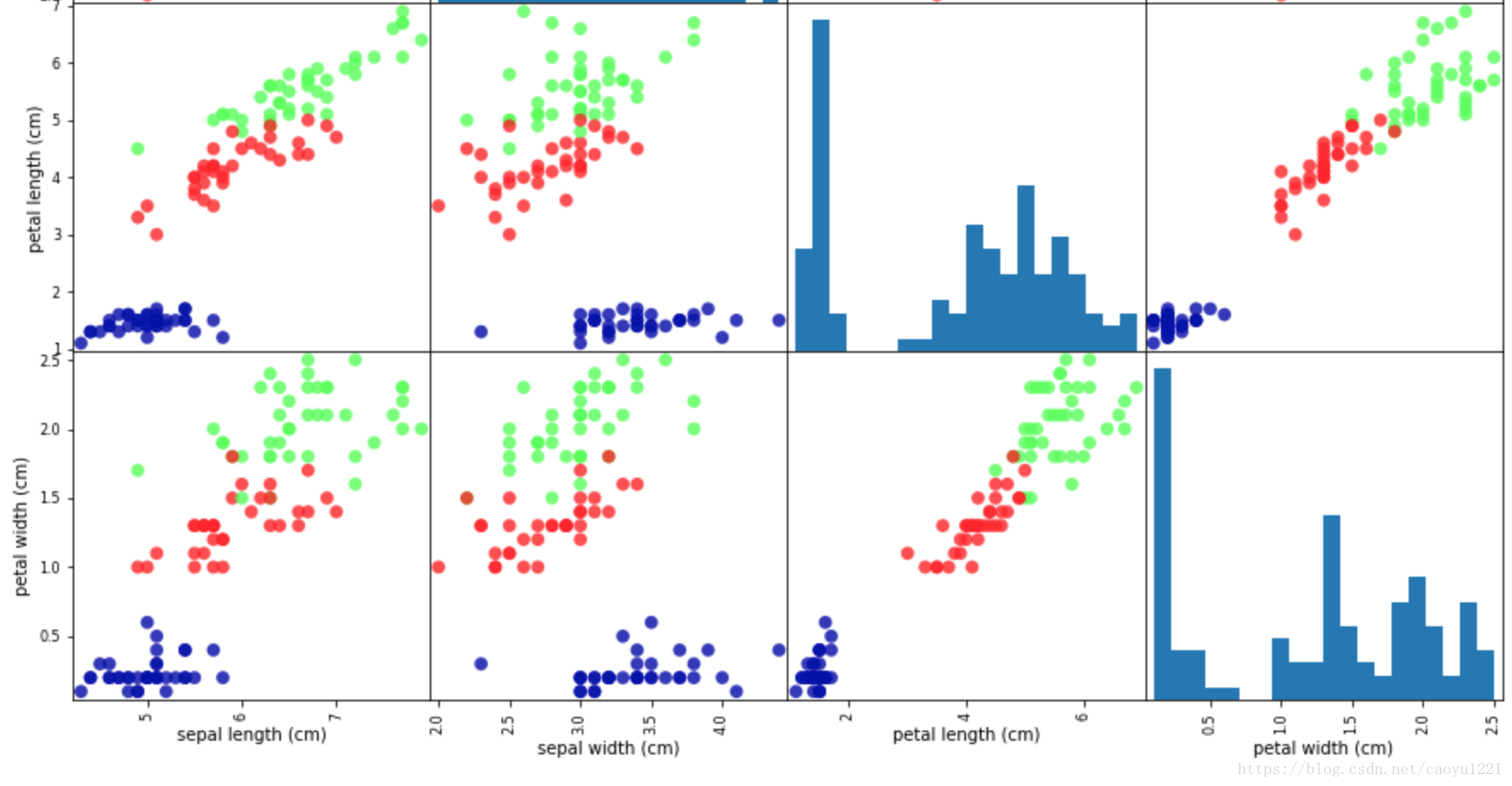
我們可以看到資料集的散點圖矩陣,按類別標籤著色,花瓣和花萼的測量資料基本可以將三個類別區別開。
構建模型–K近鄰演算法
現在可以開始構建真實的機器學習模型了。scikit-learn中有許多可用的分類演算法,這裡我們使用k近鄰分類器。構建此模型只需要儲存訓練集即可,要對一個新的資料點做出預測,演算法會在訓練集中尋找與這個新資料點距離最近的資料點,然後將找到的資料點的標籤賦值給這個新資料點。
k鄰近演算法中k的含義是,我們可以考慮訓練集中與新資料點最近的任意k個鄰居(比如說,距離最近的3個或5個鄰居),而不是隻考慮最近的哪一個。然後我們可以用這些鄰居中數量最多的類別做出預測。k鄰近分類演算法實在neighbors模組的KNeighborsClassifier類中實現的。我們需要將這個類實力化為一個物件,然後才能使用這個模型。這時我們需要設定模型的引數。KNeighborsClassifier最重要的引數就是鄰居的樹木,這裡我們設為1:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)knn物件對演算法進行了封裝,既包括用訓練資料構建模型的演算法,也包括對新資料點進行預測演算法。它還包括演算法從訓練資料中提取的資訊。對於KNeighborsClassifier來說,裡面只儲存了訓練集。
想要基於訓練集來構建模型,需要呼叫knn物件的fit方法,輸入引數為X_train和y_train, 二者都是NumPy陣列,前者包含訓練資料,後者保護相應的訓練標籤:
knn.fit(X_train, y_train)
Out[]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')從這裡我們可以看到,fit方法返回的是knn物件本身並做原處修改,因此我們得到了分類器的字串表示。從中我們可以看出構建模型時用到的引數。幾乎所有引數都是預設值,但我們可以看到n_neighbors=1,這是我們傳入的引數。
現在我們可以用這個模型對新資料進行預測了,我們可能並不知道這些新資料的正確標籤。想象一下,我們在野外發現了鳶尾花,花萼長5cm,寬2.9cm,花瓣長1cm,寬0.2cm。這朵鳶尾花屬於哪個品種?
我們可以將這些資料放在一個numpy陣列中,再次計算形狀,陣列形狀為樣本數(1)乘以特徵數(4):
X_new = np.array([[5, 2.9, 1, 0.2]])
print("X_new.shap:{}".format(X_new.shape))
Out[]:
X_new.shap:(1, 4)【注意】我們這朵花的測量資料轉換為二維numpy陣列的一行,這是因為scikit-learn的輸入資料必須是二維陣列。
接著我們呼叫knn物件的predict方法來進行預測:
prediction = knn.predict(X_new)
print("Predicition{}".format(prediction))
print("Predicition target name:{}".format(
iris_dataset['target_names'][prediction]))
Out[]:
Predicition[0]
Predicition target name:['setosa']根據模型的預測,我們可以看到這朵新的鳶尾花屬於類別0,也就是說它屬於setosa的品種。但是我們不知道能不能相信這個模型,也不知道這個樣本實際品種。
所以這裡就需要我們之前建立的測試集。這些資料沒有用於構建模型,但我們知道測試集中每朵鳶尾花的實際品種。因此,我們可以對測試資料中的每朵鳶尾花進行預測,並將預測結果與標籤(已知品種)進行對比。我們可以通過計算精度來衡量模型的準確,精度就是品種預測正確的花所佔比例:
y_pred = knn.predict(X_test)
print("Test set predictions:\n{}".format(y_pred))
Out[]:
Test set predictions:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]print("Test set score:{:.2f}".format(np.mean(y_pred==y_test)))
Out[]:
Test set score:0.97或者,我們可以用knn物件的score方法來計算測試集的準確度:
print("Test set score:{:.2f}".format(knn.score(X_test, y_test)))
Out[]:
Test set score:0.97測試中我們可以看到,精度為97%,也就是說97%的正確率。至此,我們就完成來所有的對鳶尾花的分析、計算及預測。
相關推薦
python機器學習入門到精通--實戰分析(三)
利用sklearn分析鳶尾花 前面兩篇文章提到了機器學習的入門的幾個基礎庫及拓展練習,現在我們就對前面知識點進行彙總進行一個簡單的機器學習應用,並構建模型。 練習即假定一名植物專家收集了每一朵鳶尾花的測量資料:花瓣的長度和寬度以及花萼的長度和寬度,所有測量結
python機器學習入門(3)——裝飾器和元類
記住這幾句話: 萬物皆物件 裝飾器(decorator):函式亦物件 元類(meta class):類亦物件 物件意味著可以被賦值給變數,通過變數也能呼叫此物件 兩個簡單的程式: 裝飾器例程:實現對函式func的計時 元類例程: 實
Python機器學習入門1.4《邏輯斯蒂高階優化》
options = optimset('GradObj','on','MaxIter','100'); initialTheta = zeros(2,1); [optTheta,functionVa
Python機器學習入門1.8《使用整合模型預測泰坦尼克號乘客的生還情況預測》
# -*- coding: utf-8 -*- """ Created on Fri Oct 19 08:11:26 2018 @author: asus """ import pandas as pd titanic=pd.read_csv('http://biosta
Python-機器學習 入門及技巧總結
隨著這兩年人工智慧的快速發展,機器學習與深度學習行業炙手可熱,對於那些想進入這個行業的同學們,小編在這裡給大家介紹一下自己的心得體會以及利用Python的一些小技巧,希望對大家有所幫助。 在機器學習方面,對於想入門的新手,首先不得不提就是斯坦福大學的Andrew Ng-
Python機器學習入門(1)之導學+無監督學習
預處理 全部 install 無監督學習 分類 png ins class 簡單 Python Scikit-learn *一組簡單有效的工具集 *依賴Python的NumPy,SciPy和matplotlib庫 *開源 可復用 sklearn庫的安裝 DOS
python機器學習實戰(三)
方法 baidu classes getter 全部 ken array數組 app 產生 python機器學習實戰(三) 版權聲明:本文為博主原創文章,轉載請指明轉載地址 www.cnblogs.com/fydeblog/p/7277205.html 前言 這篇博客是
針對python機器學習與實戰程式碼在python3上執行出現的錯誤分析和warning的修改程式碼34—38
#匯入model_selection進行資料分割 from sklearn.model_selection import train_test_split import numpy as np x = boston.data y = boston.target x_tra
Python機器學習之XGBoost從入門到實戰(基本理論說明)
Xgboost從基礎到實戰 XGBoost:eXtreme Gradient Boosting * 應用機器學習領域的一個強有力的工具 * Gradient Booting Machines(GBM)的優化表現,快速有效 —深盟
『Python』MachineLearning機器學習入門_效率對比
cnblogs 新的 arange 學習 nump 部分 運行 orm blog 效率對比: 老生常談了,不過這次用了個新的模塊, 運行時間測試模塊timeti: 1 import timeit 2 3 normal = timeit.timeit(‘sum(x*
『Python』MachineLearning機器學習入門_極小的機器學習應用
highlight 保存 數值 out 有意思 port del ear 解方程 一個小知識: 有意思的是,scipy囊括了numpy的命名空間,也就是說所有np.func都可以通過sp.func等價調用。 簡介: 本部分對一個互聯網公司的流量進行擬合處理,學習最基本的機器
Elasticsearch學習之深入聚合分析三---案例實戰
引用 實戰 avg buck oba core 電視 針對 過濾 1. 統計指定品牌下每個顏色的銷量 任何的聚合,都必須在搜索出來的結果數據中進行,搜索結果,就是聚合分析操作的scope GET /tvs/sales/_search { "size": 0, "
python機器學習實戰(四)
畫畫 import 測試數據 trac 1+n read dex 缺失值 類型 python機器學習實戰(四) 版權聲明:本文為博主原創文章,轉載請指明轉載地址
機器學習入門之python實現圖片簡單分類
numbers org 路徑 圖片分類 jpg animal 入門 res windows 小任務:實現圖片分類 1.圖片素材 python批量壓縮jpg圖片: PIL庫 resize http://blog.csdn.net/u012234115/article/
《python機器學習—預測分析核心算法》:理解數據
變量 body 因子 需要 ont 行數 數量 數據規模 分布 參見原書2.1-2.2節 新數據集就像一個包裝好的禮物,它充滿了承諾和希望! 但是直到你打開前,它都保持神秘! 一、基礎問題的架構、術語,機器學習數據集的特性 通常,行代表實例,列代表屬性特征
《python機器學習—預測分析核心算法》:構建預測模型的一般流程
定性 標識 貢獻 任務 表現 style 工程 重要 提取 參見原書1.5節 構建預測模型的一般流程 問題的日常語言表述->問題的數學語言重述重述問題、提取特征、訓練算法、評估算法 熟悉不同算法的輸入數據結構:1.提取或組合預測所需的特征2.設定訓練目標3.訓練模型4
[python機器學習及實踐(6)]Sklearn實現主成分分析(PCA)
相關性 hit 變量 gray tran total 空間 mach show 1.PCA原理 主成分分析(Principal Component Analysis,PCA), 是一種統計方法。通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量,轉換後的這組
python機器學習-sklearn挖掘乳腺癌細胞(三)
質量 mat spl tcl pytho 不同 區別 工具 state python機器學習-sklearn挖掘乳腺癌細胞( 博主親自錄制) 網易雲觀看地址 https://study.163.com/course/introduction.htm?courseId=10
python入門到實戰--第三章
第三章 列表簡介 列表 由一系列按特定順序排列的元素組成。 在Python中, 用方括號([] ) 來表示列表, 並用逗號來分隔其中的元素。 可以將任何東西加入列表中, 其中的元素之間可以沒有任何關係 。msg = ['abc',123,'erfgg']訪問列表元素:只需要將元素位置或所引告訴p
分享《Python機器學習—預測分析核心演算法》高清中文版PDF+高清英文版PDF+原始碼
下載:https://pan.baidu.com/s/1sfaOZmuRj14FWNumGQ5ahw 更多資料分享:http://blog.51cto.com/3215120 《Python機器學習—預測分析核心演算法》高清中文版PDF+高清英文版PDF+原始碼高清中文版,338頁,帶目錄和書籤,文字能夠